 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Wavelet Scattering Transform for Improving Generalization in Low-Resourced Spoken Language Identification
Oct 03, 2023
Commonly used features in spoken language identification (LID), such as mel-spectrogram or MFCC, lose high-frequency information due to windowing. The loss further increases for longer temporal contexts. To improve generalization of the low-resourced LID systems, we investigate an alternate feature representation, wavelet scattering transform (WST), that compensates for the shortcomings. To our knowledge, WST is not explored earlier in LID tasks. We first optimize WST features for multiple South Asian LID corpora. We show that LID requires low octave resolution and frequency-scattering is not useful. Further, cross-corpora evaluations show that the optimal WST hyper-parameters depend on both train and test corpora. Hence, we develop fused ECAPA-TDNN based LID systems with different sets of WST hyper-parameters to improve generalization for unknown data. Compared to MFCC, EER is reduced upto 14.05% and 6.40% for same-corpora and blind VoxLingua107 evaluations, respectively.
An Improved Encoder-Decoder Framework for Food Energy Estimation
Sep 22, 2023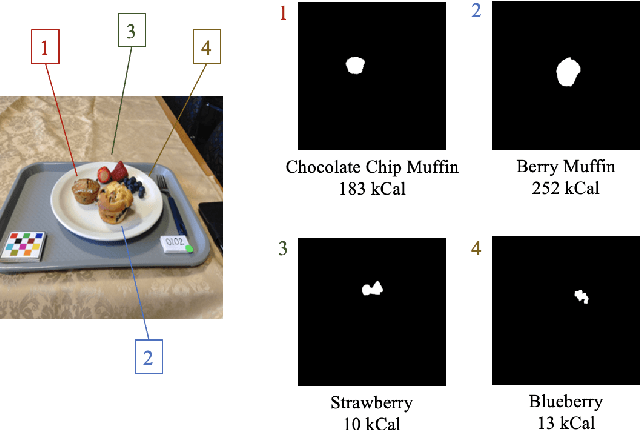

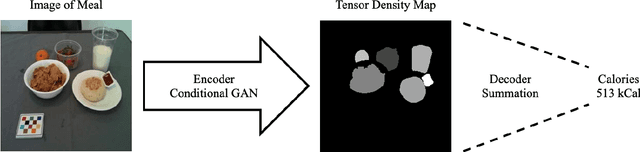

Dietary assessment is essential to maintaining a healthy lifestyle. Automatic image-based dietary assessment is a growing field of research due to the increasing prevalence of image capturing devices (e.g. mobile phones). In this work, we estimate food energy from a single monocular image, a difficult task due to the limited hard-to-extract amount of energy information present in an image. To do so, we employ an improved encoder-decoder framework for energy estimation; the encoder transforms the image into a representation embedded with food energy information in an easier-to-extract format, which the decoder then extracts the energy information from. To implement our method, we compile a high-quality food image dataset verified by registered dietitians containing eating scene images, food-item segmentation masks, and ground truth calorie values. Our method improves upon previous caloric estimation methods by over 10\% and 30 kCal in terms of MAPE and MAE respectively.
Recurrent Temporal Revision Graph Networks
Sep 22, 2023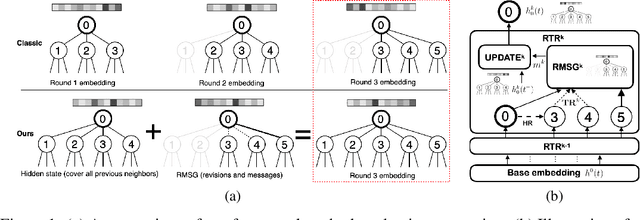

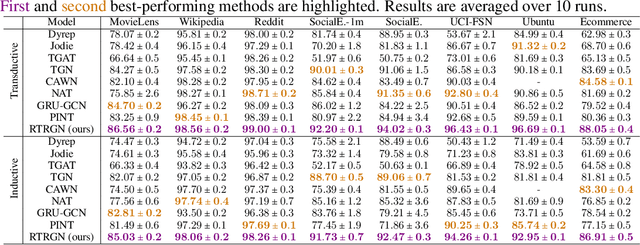
Temporal graphs offer more accurate modeling of many real-world scenarios than static graphs. However, neighbor aggregation, a critical building block of graph networks, for temporal graphs, is currently straightforwardly extended from that of static graphs. It can be computationally expensive when involving all historical neighbors during such aggregation. In practice, typically only a subset of the most recent neighbors are involved. However, such subsampling leads to incomplete and biased neighbor information. To address this limitation, we propose a novel framework for temporal neighbor aggregation that uses the recurrent neural network with node-wise hidden states to integrate information from all historical neighbors for each node to acquire the complete neighbor information. We demonstrate the superior theoretical expressiveness of the proposed framework as well as its state-of-the-art performance in real-world applications. Notably, it achieves a significant +9.6% improvement on averaged precision in a real-world Ecommerce dataset over existing methods on 2-layer models.
Natural revision is contingently-conditionalized revision
Sep 22, 2023Natural revision seems so natural: it changes beliefs as little as possible to incorporate new information. Yet, some counterexamples show it wrong. It is so conservative that it never fully believes. It only believes in the current conditions. This is right in some cases and wrong in others. Which is which? The answer requires extending natural revision from simple formulae expressing universal truths (something holds) to conditionals expressing conditional truth (something holds in certain conditions). The extension is based on the basic principles natural revision follows, identified as minimal change, indifference and naivety: change beliefs as little as possible; equate the likeliness of scenarios by default; believe all until contradicted. The extension says that natural revision restricts changes to the current conditions. A comparison with an unrestricting revision shows what exactly the current conditions are. It is not what currently considered true if it contradicts the new information. It includes something more and more unlikely until the new information is at least possible.
Understanding Transferable Representation Learning and Zero-shot Transfer in CLIP
Oct 02, 2023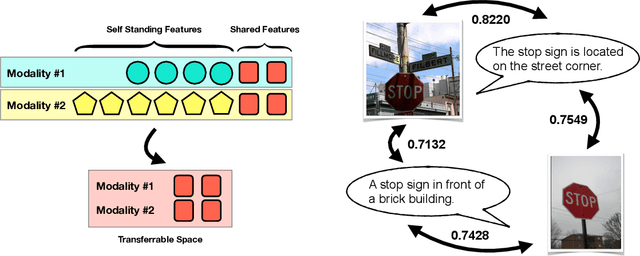

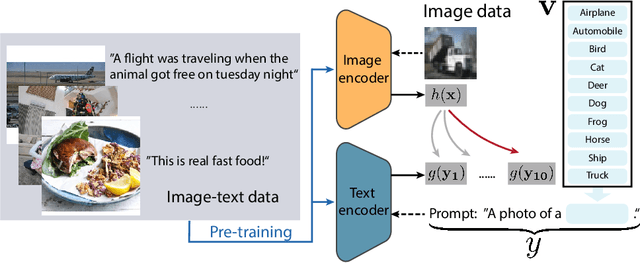

Multi-modal learning has become increasingly popular due to its ability to leverage information from different data sources (e.g., text and images) to improve the model performance. Recently, CLIP has emerged as an effective approach that employs vision-language contrastive pretraining to learn joint image and text representations and exhibits remarkable performance in zero-shot learning and text-guided natural image generation. Despite the huge practical success of CLIP, its theoretical understanding remains elusive. In this paper, we formally study transferrable representation learning underlying CLIP and demonstrate how features from different modalities get aligned. We also analyze its zero-shot transfer performance on the downstream tasks. Inspired by our analysis, we propose a new CLIP-type approach, which achieves better performance than CLIP and other state-of-the-art methods on benchmark datasets.
Towards Poisoning Fair Representations
Sep 28, 2023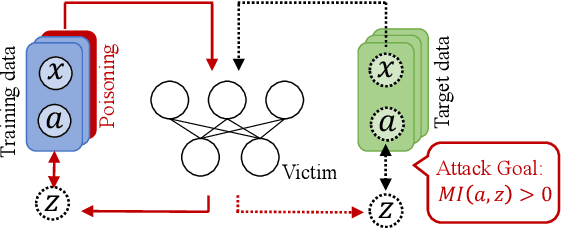
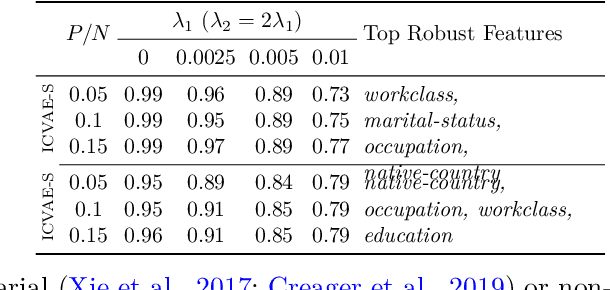
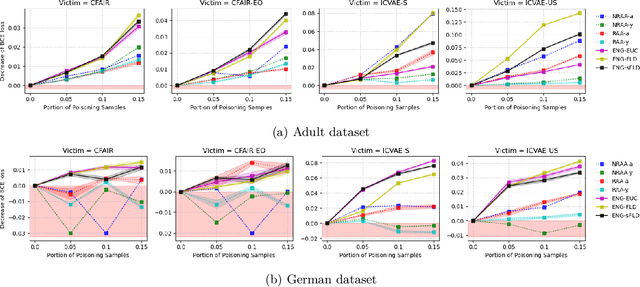
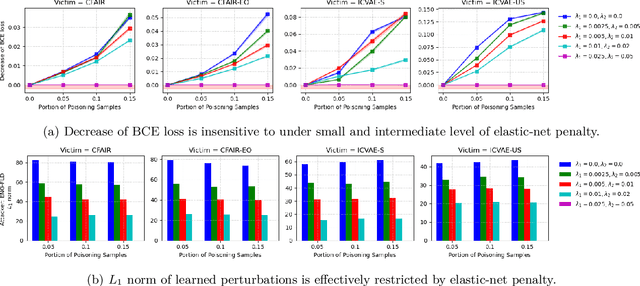
Fair machine learning seeks to mitigate model prediction bias against certain demographic subgroups such as elder and female. Recently, fair representation learning (FRL) trained by deep neural networks has demonstrated superior performance, whereby representations containing no demographic information are inferred from the data and then used as the input to classification or other downstream tasks. Despite the development of FRL methods, their vulnerability under data poisoning attack, a popular protocol to benchmark model robustness under adversarial scenarios, is under-explored. Data poisoning attacks have been developed for classical fair machine learning methods which incorporate fairness constraints into shallow-model classifiers. Nonetheless, these attacks fall short in FRL due to notably different fairness goals and model architectures. This work proposes the first data poisoning framework attacking FRL. We induce the model to output unfair representations that contain as much demographic information as possible by injecting carefully crafted poisoning samples into the training data. This attack entails a prohibitive bilevel optimization, wherefore an effective approximated solution is proposed. A theoretical analysis on the needed number of poisoning samples is derived and sheds light on defending against the attack. Experiments on benchmark fairness datasets and state-of-the-art fair representation learning models demonstrate the superiority of our attack.
Prompt-Enhanced Self-supervised Representation Learning for Remote Sensing Image Understanding
Sep 28, 2023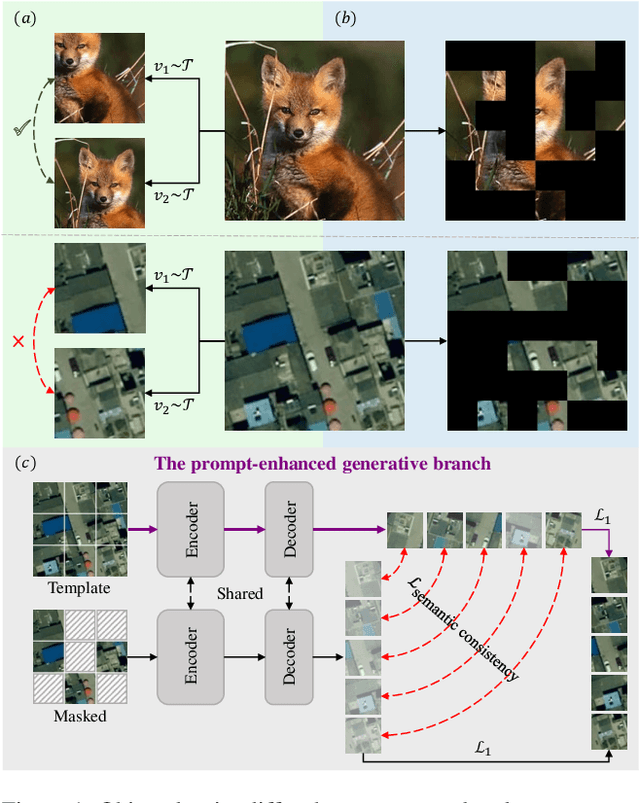
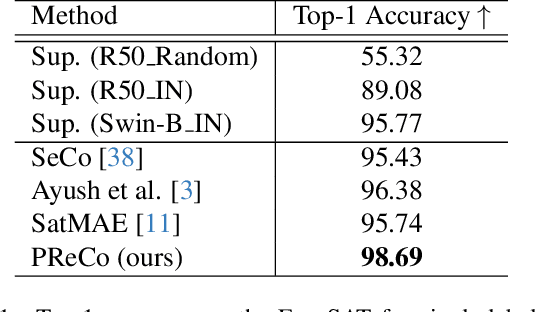
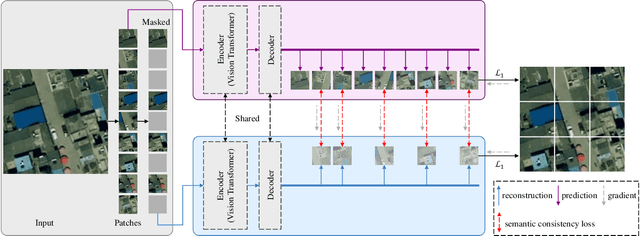
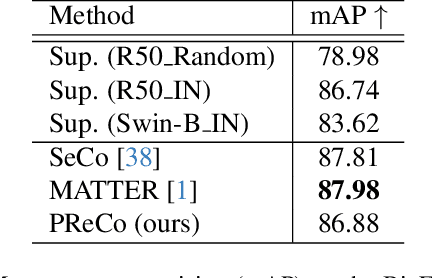
Learning representations through self-supervision on a large-scale, unlabeled dataset has proven to be highly effective for understanding diverse images, such as those used in remote sensing image analysis. However, remote sensing images often have complex and densely populated scenes, with multiple land objects and no clear foreground objects. This intrinsic property can lead to false positive pairs in contrastive learning, or missing contextual information in reconstructive learning, which can limit the effectiveness of existing self-supervised learning methods. To address these problems, we propose a prompt-enhanced self-supervised representation learning method that uses a simple yet efficient pre-training pipeline. Our approach involves utilizing original image patches as a reconstructive prompt template, and designing a prompt-enhanced generative branch that provides contextual information through semantic consistency constraints. We collected a dataset of over 1.28 million remote sensing images that is comparable to the popular ImageNet dataset, but without specific temporal or geographical constraints. Our experiments show that our method outperforms fully supervised learning models and state-of-the-art self-supervised learning methods on various downstream tasks, including land cover classification, semantic segmentation, object detection, and instance segmentation. These results demonstrate that our approach learns impressive remote sensing representations with high generalization and transferability.
Reversing Deep Face Embeddings with Probable Privacy Protection
Oct 04, 2023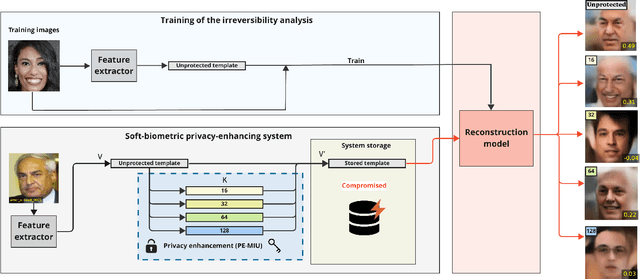
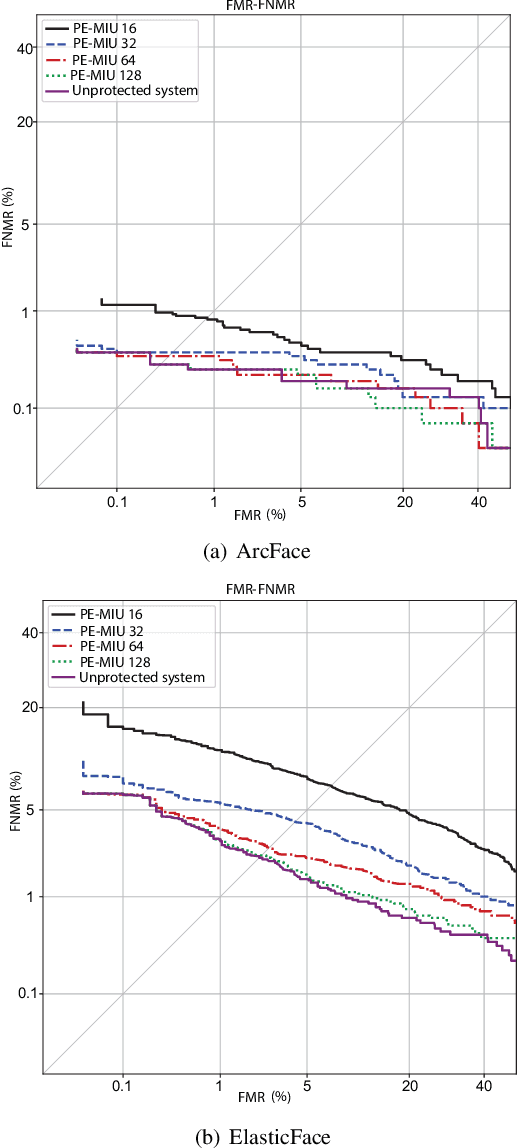

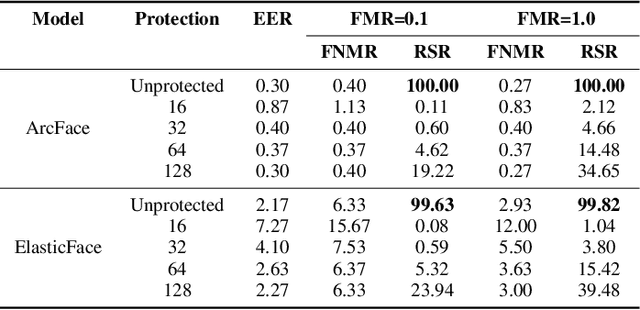
Generally, privacy-enhancing face recognition systems are designed to offer permanent protection of face embeddings. Recently, so-called soft-biometric privacy-enhancement approaches have been introduced with the aim of canceling soft-biometric attributes. These methods limit the amount of soft-biometric information (gender or skin-colour) that can be inferred from face embeddings. Previous work has underlined the need for research into rigorous evaluations and standardised evaluation protocols when assessing privacy protection capabilities. Motivated by this fact, this paper explores to what extent the non-invertibility requirement can be met by methods that claim to provide soft-biometric privacy protection. Additionally, a detailed vulnerability assessment of state-of-the-art face embedding extractors is analysed in terms of the transformation complexity used for privacy protection. In this context, a well-known state-of-the-art face image reconstruction approach has been evaluated on protected face embeddings to break soft biometric privacy protection. Experimental results show that biometric privacy-enhanced face embeddings can be reconstructed with an accuracy of up to approximately 98%, depending on the complexity of the protection algorithm.
R-LGP: A Reachability-guided Logic-geometric Programming Framework for Optimal Task and Motion Planning on Mobile Manipulators
Oct 04, 2023This paper presents an optimization-based solution to task and motion planning (TAMP) on mobile manipulators. Logic-geometric programming (LGP) has shown promising capabilities for optimally dealing with hybrid TAMP problems that involve abstract and geometric constraints. However, LGP does not scale well to high-dimensional systems (e.g. mobile manipulators) and can suffer from obstacle avoidance issues. In this work, we extend LGP with a sampling-based reachability graph to enable solving optimal TAMP on high-DoF mobile manipulators. The proposed reachability graph can incorporate environmental information (obstacles) to provide the planner with sufficient geometric constraints. This reachability-aware heuristic efficiently prunes infeasible sequences of actions in the continuous domain, hence, it reduces replanning by securing feasibility at the final full trajectory optimization. Our framework proves to be time-efficient in computing optimal and collision-free solutions, while outperforming the current state of the art on metrics of success rate, planning time, path length and number of steps. We validate our framework on the physical Toyota HSR robot and report comparisons on a series of mobile manipulation tasks of increasing difficulty.
Gradient Descent Provably Solves Nonlinear Tomographic Reconstruction
Oct 06, 2023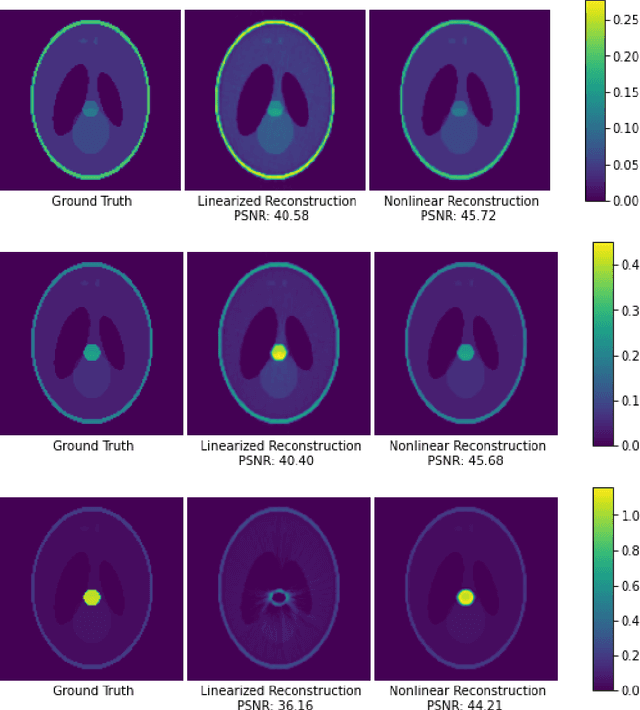
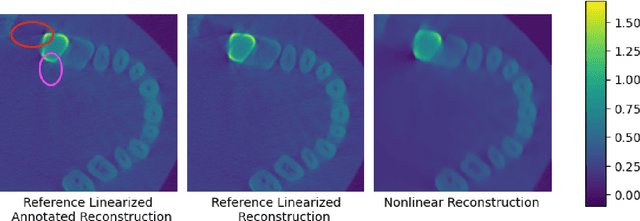
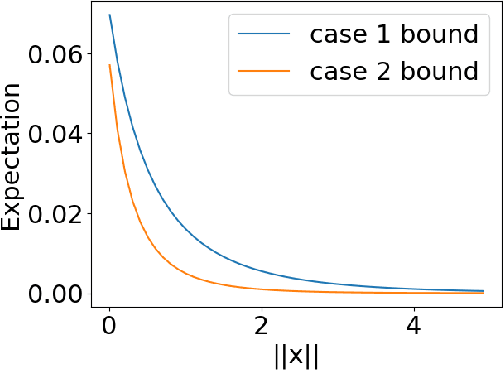
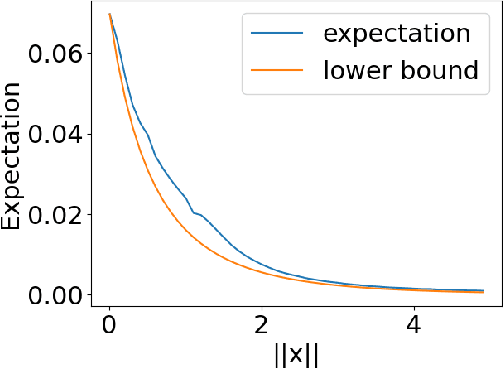
In computed tomography (CT), the forward model consists of a linear Radon transform followed by an exponential nonlinearity based on the attenuation of light according to the Beer-Lambert Law. Conventional reconstruction often involves inverting this nonlinearity as a preprocessing step and then solving a convex inverse problem. However, this nonlinear measurement preprocessing required to use the Radon transform is poorly conditioned in the vicinity of high-density materials, such as metal. This preprocessing makes CT reconstruction methods numerically sensitive and susceptible to artifacts near high-density regions. In this paper, we study a technique where the signal is directly reconstructed from raw measurements through the nonlinear forward model. Though this optimization is nonconvex, we show that gradient descent provably converges to the global optimum at a geometric rate, perfectly reconstructing the underlying signal with a near minimal number of random measurements. We also prove similar results in the under-determined setting where the number of measurements is significantly smaller than the dimension of the signal. This is achieved by enforcing prior structural information about the signal through constraints on the optimization variables. We illustrate the benefits of direct nonlinear CT reconstruction with cone-beam CT experiments on synthetic and real 3D volumes. We show that this approach reduces metal artifacts compared to a commercial reconstruction of a human skull with metal dental crowns.