 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Knowledge Crosswords: Geometric Reasoning over Structured Knowledge with Large Language Models
Oct 02, 2023
Large language models (LLMs) are widely adopted in knowledge-intensive tasks and have achieved impressive performance thanks to their knowledge abilities. While LLMs have demonstrated outstanding performance on atomic or linear (multi-hop) QA tasks, whether they can reason in knowledge-rich scenarios with interweaving constraints remains an underexplored problem. In this work, we propose geometric reasoning over structured knowledge, where pieces of knowledge are connected in a graph structure and models need to fill in the missing information. Such geometric knowledge reasoning would require the ability to handle structured knowledge, reason with uncertainty, verify facts, and backtrack when an error occurs. We propose Knowledge Crosswords, a multi-blank QA dataset where each problem consists of a natural language question representing the geometric constraints of an incomplete entity network, where LLMs are tasked with working out the missing entities while meeting all factual constraints. Knowledge Crosswords contains 2,101 individual problems, covering various knowledge domains and further divided into three difficulty levels. We conduct extensive experiments to evaluate existing LLM prompting approaches on the Knowledge Crosswords benchmark. We additionally propose two new approaches, Staged Prompting and Verify-All, to augment LLMs' ability to backtrack and verify structured constraints. Our results demonstrate that while baseline approaches perform well on easier problems but struggle with hard ones, our proposed Verify-All outperforms other methods by a large margin and is more robust with hard problems. Further analysis reveals that LLMs' ability of geometric reasoning over structured knowledge is still far from robust or perfect, susceptible to confounders such as the order of options, certain structural patterns, assumption of existence of correct answer, and more.
Learn to Follow: Decentralized Lifelong Multi-agent Pathfinding via Planning and Learning
Oct 02, 2023Multi-agent Pathfinding (MAPF) problem generally asks to find a set of conflict-free paths for a set of agents confined to a graph and is typically solved in a centralized fashion. Conversely, in this work, we investigate the decentralized MAPF setting, when the central controller that posses all the information on the agents' locations and goals is absent and the agents have to sequientially decide the actions on their own without having access to a full state of the environment. We focus on the practically important lifelong variant of MAPF, which involves continuously assigning new goals to the agents upon arrival to the previous ones. To address this complex problem, we propose a method that integrates two complementary approaches: planning with heuristic search and reinforcement learning through policy optimization. Planning is utilized to construct and re-plan individual paths. We enhance our planning algorithm with a dedicated technique tailored to avoid congestion and increase the throughput of the system. We employ reinforcement learning to discover the collision avoidance policies that effectively guide the agents along the paths. The policy is implemented as a neural network and is effectively trained without any reward-shaping or external guidance. We evaluate our method on a wide range of setups comparing it to the state-of-the-art solvers. The results show that our method consistently outperforms the learnable competitors, showing higher throughput and better ability to generalize to the maps that were unseen at the training stage. Moreover our solver outperforms a rule-based one in terms of throughput and is an order of magnitude faster than a state-of-the-art search-based solver.
Joint Source-Channel Coding System for 6G Communication: Design, Prototype and Future Directions
Oct 02, 2023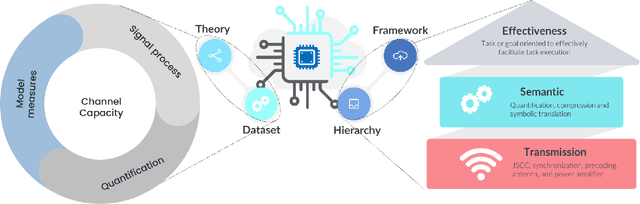
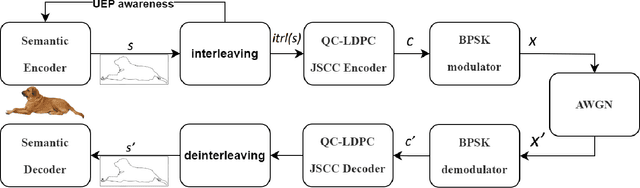
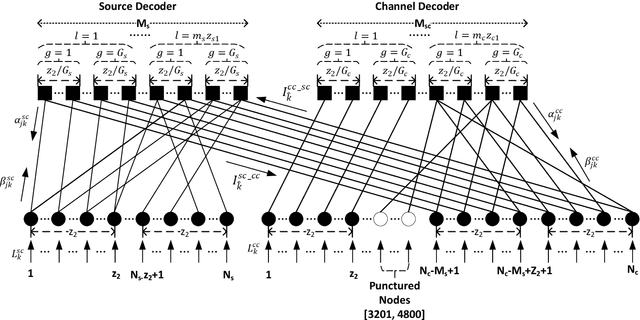
The goal of semantic communication is to surpass optimal Shannon's criterion regarding a notable problem for future communication which lies in the integration of collaborative efforts between the intelligence of the transmission source and the joint design of source coding and channel coding. The convergence of scholarly investigation and applicable products in the field of semantic communication is facilitated by the utilization of flexible structural hardware design, which is constrained by the computational capabilities of edge devices. This characteristic represents a significant benefit of joint source-channel coding (JSCC), as it enables the generation of source alphabets with diverse lengths and achieves a code rate of unity. Moreover, JSCC exhibits near-capacity performance while maintaining low complexity. Therefore, we leverage not only quasi-cyclic (QC) characteristics to propose a QC-LDPC code-based JSCC scheme but also Unequal Error Protection (UEP) to ensure the recovery of semantic importance. In this study, the feasibility for using a semantic encoder/decoder that is aware of UEP can be explored based on the existing JSCC system. This approach is aimed at protecting the significance of semantic task-oriented information. Additionally, the deployment of a JSCC system can be facilitated by employing Low-Density Parity-Check (LDPC) codes on a reconfigurable device. This is achieved by reconstructing the LDPC codes as QC-LDPC codes. The QC-LDPC layered decoding technique, which has been specifically optimized for hardware parallelism and tailored for channel decoding applications, can be suitably adapted to accommodate the JSCC system. The performance of the proposed system is evaluated by conducting BER measurements using both floating-point and 6-bit quantization.
A Robust Machine Learning Approach for Path Loss Prediction in 5G Networks with Nested Cross Validation
Oct 02, 2023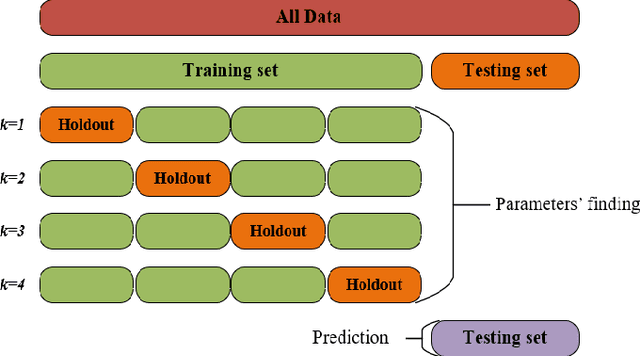
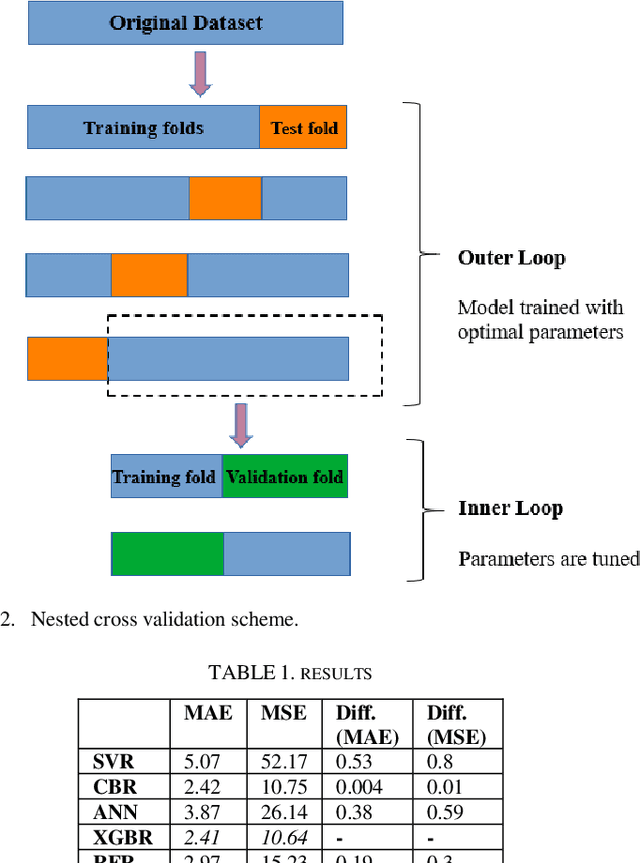
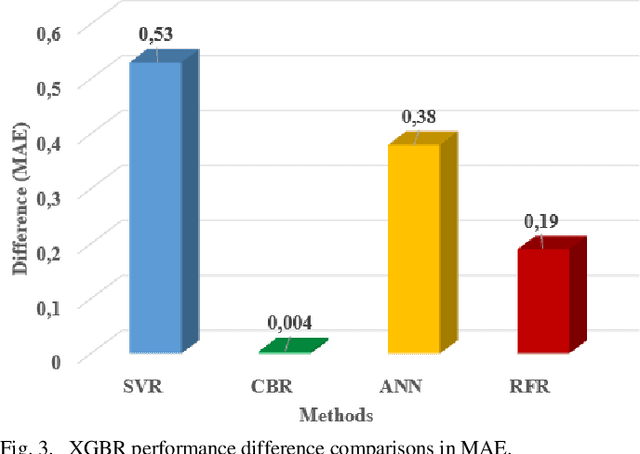
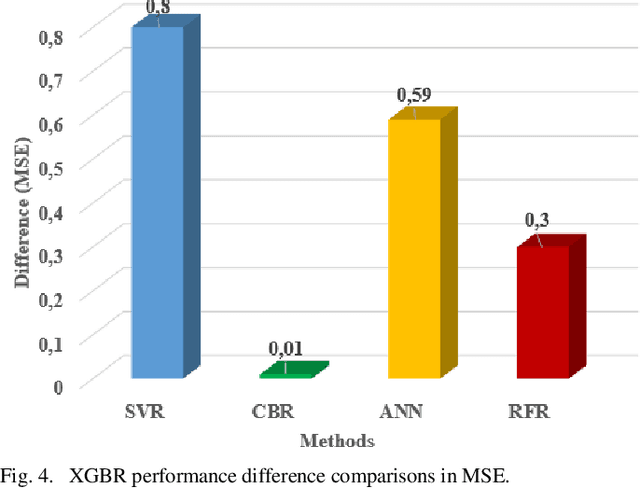
The design and deployment of fifth-generation (5G) wireless networks pose significant challenges due to the increasing number of wireless devices. Path loss has a landmark importance in network performance optimization, and accurate prediction of the path loss, which characterizes the attenuation of signal power during transmission, is critical for effective network planning, coverage estimation, and optimization. In this sense, we utilize machine learning (ML) methods, which overcome conventional path loss prediction models drawbacks, for path loss prediction in a 5G network system to facilitate more accurate network planning, resource optimization, and performance improvement in wireless communication systems. To this end, we utilize a novel approach, nested cross validation scheme, with ML to prevent overfitting, thereby getting better generalization error and stable results for ML deployment. First, we acquire a publicly available dataset obtained through a comprehensive measurement campaign conducted in an urban macro-cell scenario located in Beijing, China. The dataset includes crucial information such as longitude, latitude, elevation, altitude, clutter height, and distance, which are utilized as essential features to predict the path loss in the 5G network system. We deploy Support Vector Regression (SVR), CatBoost Regression (CBR), eXtreme Gradient Boosting Regression (XGBR), Artificial Neural Network (ANN), and Random Forest (RF) methods to predict the path loss, and compare the prediction results in terms of Mean Absolute Error (MAE) and Mean Square Error (MSE). As per obtained results, XGBR outperforms the rest of the methods. It outperforms CBR with a slight performance differences by 0.4 % and 1 % in terms of MAE and MSE metrics, respectively. On the other hand, it outperforms the rest of the methods with clear performance differences.
A Novel Approach for Machine Learning-based Load Balancing in High-speed Train System using Nested Cross Validation
Oct 02, 2023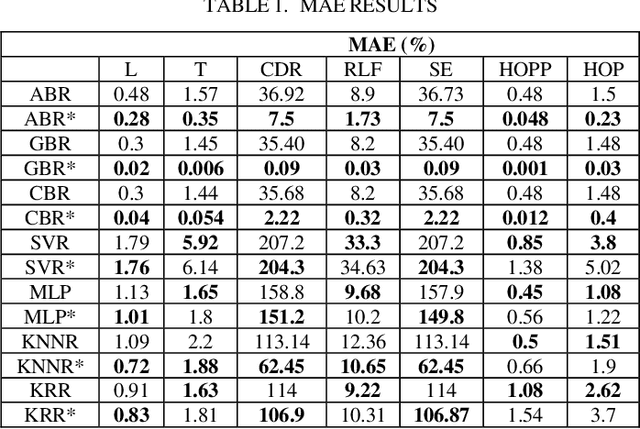
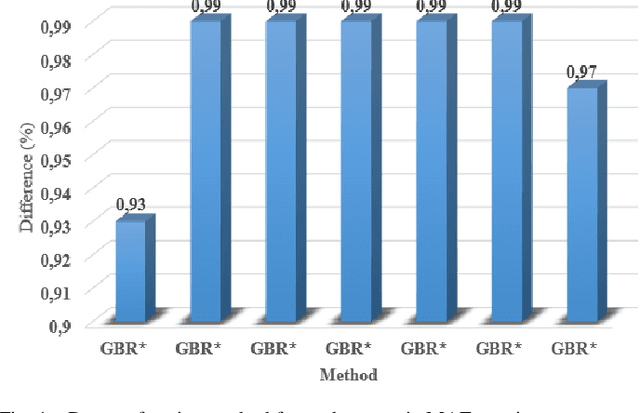
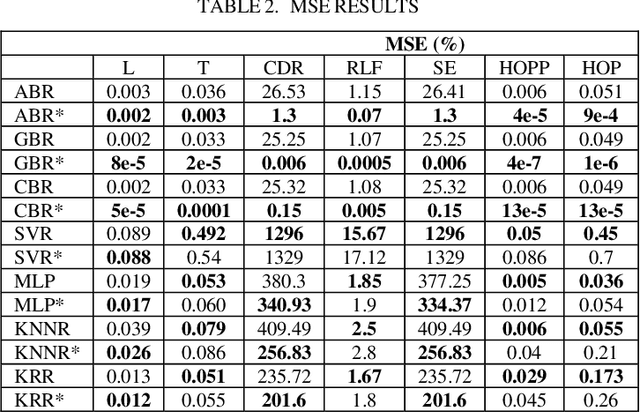
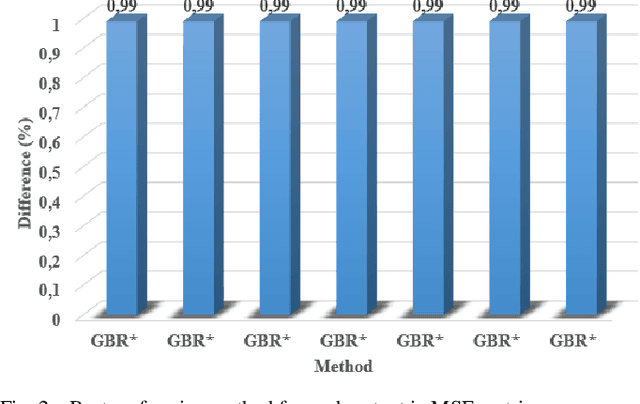
Fifth-generation (5G) mobile communication networks have recently emerged in various fields, including highspeed trains. However, the dense deployment of 5G millimeter wave (mmWave) base stations (BSs) and the high speed of moving trains lead to frequent handovers (HOs), which can adversely affect the Quality-of-Service (QoS) of mobile users. As a result, HO optimization and resource allocation are essential considerations for managing mobility in high-speed train systems. In this paper, we model system performance of a high-speed train system with a novel machine learning (ML) approach that is nested cross validation scheme that prevents information leakage from model evaluation into the model parameter tuning, thereby avoiding overfitting and resulting in better generalization error. To this end, we employ ML methods for the high-speed train system scenario. Handover Margin (HOM) and Time-to-Trigger (TTT) values are used as features, and several KPIs are used as outputs, and several ML methods including Gradient Boosting Regression (GBR), Adaptive Boosting (AdaBoost), CatBoost Regression (CBR), Artificial Neural Network (ANN), Kernel Ridge Regression (KRR), Support Vector Regression (SVR), and k-Nearest Neighbor Regression (KNNR) are employed for the problem. Finally, performance comparisons of the cross validation schemes with the methods are made in terms of mean absolute error (MAE) and mean square error (MSE) metrics are made. As per obtained results, boosting methods, ABR, CBR, GBR, with nested cross validation scheme superiorly outperforms conventional cross validation scheme results with the same methods. On the other hand, SVR, KNRR, KRR, ANN with the nested scheme produce promising results for prediction of some KPIs with respect to their conventional scheme employment.
Wavelet-based Topological Loss for Low-Light Image Denoising
Sep 16, 2023Despite extensive research conducted in the field of image denoising, many algorithms still heavily depend on supervised learning and their effectiveness primarily relies on the quality and diversity of training data. It is widely assumed that digital image distortions are caused by spatially invariant Additive White Gaussian Noise (AWGN). However, the analysis of real-world data suggests that this assumption is invalid. Therefore, this paper tackles image corruption by real noise, providing a framework to capture and utilise the underlying structural information of an image along with the spatial information conventionally used for deep learning tasks. We propose a novel denoising loss function that incorporates topological invariants and is informed by textural information extracted from the image wavelet domain. The effectiveness of this proposed method was evaluated by training state-of-the-art denoising models on the BVI-Lowlight dataset, which features a wide range of real noise distortions. Adding a topological term to common loss functions leads to a significant increase in the LPIPS (Learned Perceptual Image Patch Similarity) metric, with the improvement reaching up to 25\%. The results indicate that the proposed loss function enables neural networks to learn noise characteristics better. We demonstrate that they can consequently extract the topological features of noise-free images, resulting in enhanced contrast and preserved textural information.
Few-Shot Domain Adaptation for Charge Prediction on Unprofessional Descriptions
Sep 29, 2023Recent works considering professional legal-linguistic style (PLLS) texts have shown promising results on the charge prediction task. However, unprofessional users also show an increasing demand on such a prediction service. There is a clear domain discrepancy between PLLS texts and non-PLLS texts expressed by those laypersons, which degrades the current SOTA models' performance on non-PLLS texts. A key challenge is the scarcity of non-PLLS data for most charge classes. This paper proposes a novel few-shot domain adaptation (FSDA) method named Disentangled Legal Content for Charge Prediction (DLCCP). Compared with existing FSDA works, which solely perform instance-level alignment without considering the negative impact of text style information existing in latent features, DLCCP (1) disentangles the content and style representations for better domain-invariant legal content learning with carefully designed optimization goals for content and style spaces and, (2) employs the constitutive elements knowledge of charges to extract and align element-level and instance-level content representations simultaneously. We contribute the first publicly available non-PLLS dataset named NCCP for developing layperson-friendly charge prediction models. Experiments on NCCP show the superiority of our methods over competitive baselines.
Towards Free Data Selection with General-Purpose Models
Sep 29, 2023

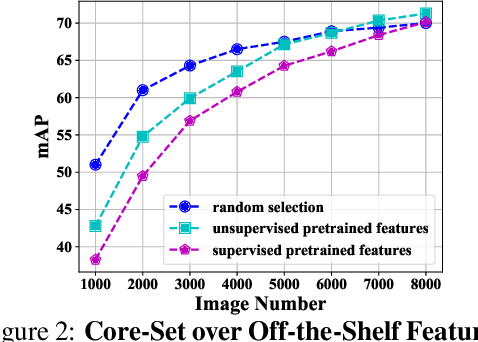
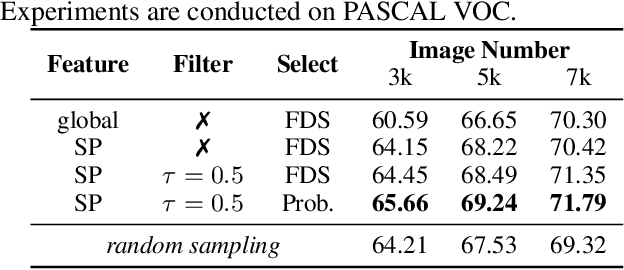
A desirable data selection algorithm can efficiently choose the most informative samples to maximize the utility of limited annotation budgets. However, current approaches, represented by active learning methods, typically follow a cumbersome pipeline that iterates the time-consuming model training and batch data selection repeatedly. In this paper, we challenge this status quo by designing a distinct data selection pipeline that utilizes existing general-purpose models to select data from various datasets with a single-pass inference without the need for additional training or supervision. A novel free data selection (FreeSel) method is proposed following this new pipeline. Specifically, we define semantic patterns extracted from inter-mediate features of the general-purpose model to capture subtle local information in each image. We then enable the selection of all data samples in a single pass through distance-based sampling at the fine-grained semantic pattern level. FreeSel bypasses the heavy batch selection process, achieving a significant improvement in efficiency and being 530x faster than existing active learning methods. Extensive experiments verify the effectiveness of FreeSel on various computer vision tasks. Our code is available at https://github.com/yichen928/FreeSel.
Reconstruction of Patient-Specific Confounders in AI-based Radiologic Image Interpretation using Generative Pretraining
Sep 29, 2023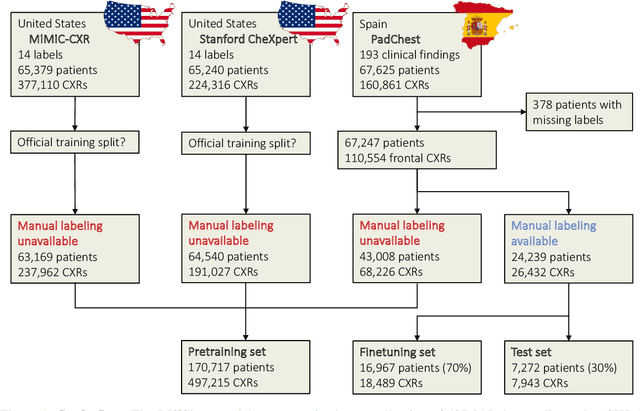

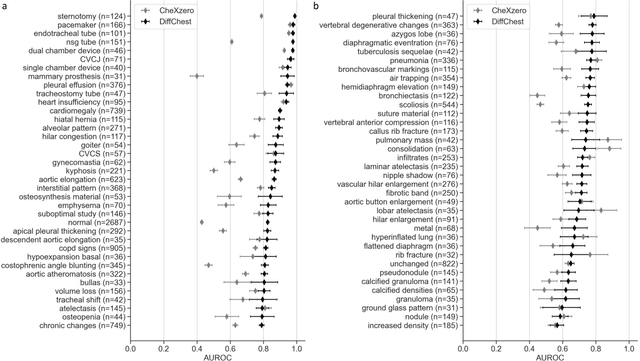

Detecting misleading patterns in automated diagnostic assistance systems, such as those powered by Artificial Intelligence, is critical to ensuring their reliability, particularly in healthcare. Current techniques for evaluating deep learning models cannot visualize confounding factors at a diagnostic level. Here, we propose a self-conditioned diffusion model termed DiffChest and train it on a dataset of 515,704 chest radiographs from 194,956 patients from multiple healthcare centers in the United States and Europe. DiffChest explains classifications on a patient-specific level and visualizes the confounding factors that may mislead the model. We found high inter-reader agreement when evaluating DiffChest's capability to identify treatment-related confounders, with Fleiss' Kappa values of 0.8 or higher across most imaging findings. Confounders were accurately captured with 11.1% to 100% prevalence rates. Furthermore, our pretraining process optimized the model to capture the most relevant information from the input radiographs. DiffChest achieved excellent diagnostic accuracy when diagnosing 11 chest conditions, such as pleural effusion and cardiac insufficiency, and at least sufficient diagnostic accuracy for the remaining conditions. Our findings highlight the potential of pretraining based on diffusion models in medical image classification, specifically in providing insights into confounding factors and model robustness.
PC-Adapter: Topology-Aware Adapter for Efficient Domain Adaption on Point Clouds with Rectified Pseudo-label
Sep 29, 2023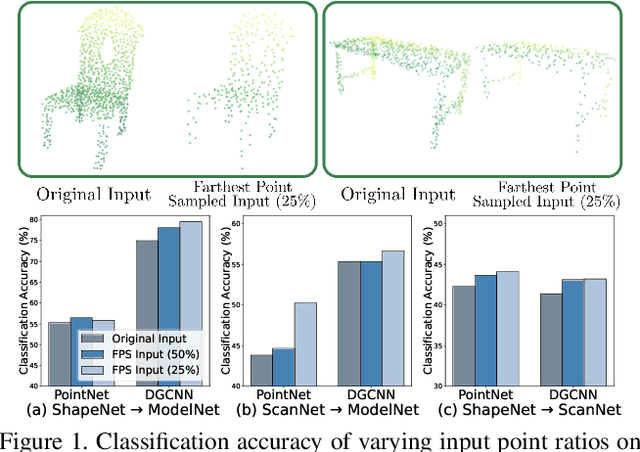
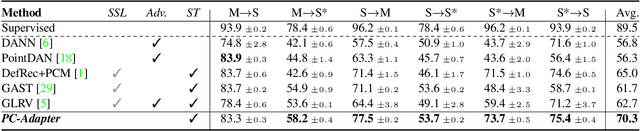
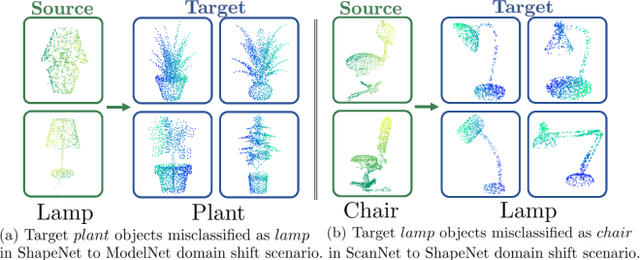
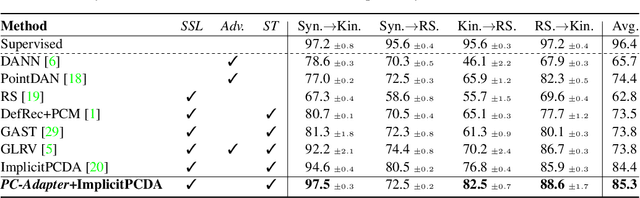
Understanding point clouds captured from the real-world is challenging due to shifts in data distribution caused by varying object scales, sensor angles, and self-occlusion. Prior works have addressed this issue by combining recent learning principles such as self-supervised learning, self-training, and adversarial training, which leads to significant computational overhead.Toward succinct yet powerful domain adaptation for point clouds, we revisit the unique challenges of point cloud data under domain shift scenarios and discover the importance of the global geometry of source data and trends of target pseudo-labels biased to the source label distribution. Motivated by our observations, we propose an adapter-guided domain adaptation method, PC-Adapter, that preserves the global shape information of the source domain using an attention-based adapter, while learning the local characteristics of the target domain via another adapter equipped with graph convolution. Additionally, we propose a novel pseudo-labeling strategy resilient to the classifier bias by adjusting confidence scores using their class-wise confidence distributions to consider relative confidences. Our method demonstrates superiority over baselines on various domain shift settings in benchmark datasets - PointDA, GraspNetPC, and PointSegDA.