 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Reinforcement learning adaptive fuzzy controller for lighting systems: application to aircraft cabin
Sep 30, 2023
The lighting requirements are subjective and one light setting cannot work for all. However, there is little work on developing smart lighting algorithms that can adapt to user preferences. To address this gap, this paper uses fuzzy logic and reinforcement learning to develop an adaptive lighting algorithm. In particular, we develop a baseline fuzzy inference system (FIS) using the domain knowledge. We use the existing literature to create a FIS that generates lighting setting recommendations based on environmental conditions i.e. daily glare index, and user information including age, activity, and chronotype. Through a feedback mechanism, the user interacts with the algorithm, correcting the algorithm output to their preferences. We interpret these corrections as rewards to a Q-learning agent, which tunes the FIS parameters online to match the user preferences. We implement the algorithm in an aircraft cabin mockup and conduct an extensive user study to evaluate the effectiveness of the algorithm and understand its learning behavior. Our implementation results demonstrate that the developed algorithm possesses the capability to learn user preferences while successfully adapting to a wide range of environmental conditions and user characteristics. and can deal with a diverse spectrum of environmental conditions and user characteristics. This underscores its viability as a potent solution for intelligent light management, featuring advanced learning capabilities.
Question-Answering Approach to Evaluate Legal Summaries
Sep 26, 2023


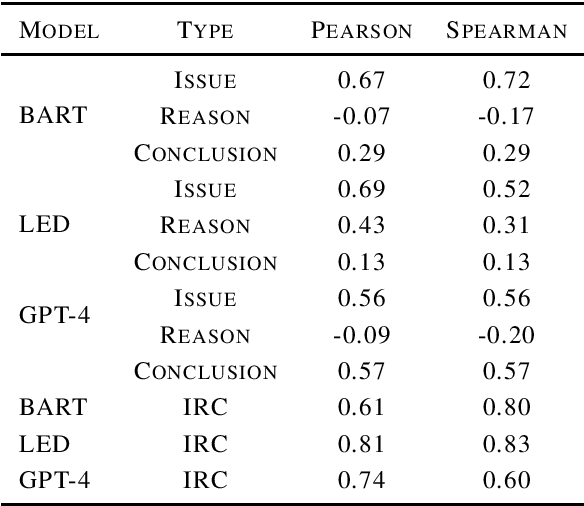
Traditional evaluation metrics like ROUGE compare lexical overlap between the reference and generated summaries without taking argumentative structure into account, which is important for legal summaries. In this paper, we propose a novel legal summarization evaluation framework that utilizes GPT-4 to generate a set of question-answer pairs that cover main points and information in the reference summary. GPT-4 is then used to generate answers based on the generated summary for the questions from the reference summary. Finally, GPT-4 grades the answers from the reference summary and the generated summary. We examined the correlation between GPT-4 grading with human grading. The results suggest that this question-answering approach with GPT-4 can be a useful tool for gauging the quality of the summary.
CAMERA: A Multimodal Dataset and Benchmark for Ad Text Generation
Sep 21, 2023In response to the limitations of manual online ad production, significant research has been conducted in the field of automatic ad text generation (ATG). However, comparing different methods has been challenging because of the lack of benchmarks encompassing the entire field and the absence of well-defined problem sets with clear model inputs and outputs. To address these challenges, this paper aims to advance the field of ATG by introducing a redesigned task and constructing a benchmark. Specifically, we defined ATG as a cross-application task encompassing various aspects of the Internet advertising. As part of our contribution, we propose a first benchmark dataset, CA Multimodal Evaluation for Ad Text GeneRAtion (CAMERA), carefully designed for ATG to be able to leverage multi-modal information and conduct an industry-wise evaluation. Furthermore, we demonstrate the usefulness of our proposed benchmark through evaluation experiments using multiple baseline models, which vary in terms of the type of pre-trained language model used and the incorporation of multi-modal information. We also discuss the current state of the task and the future challenges.
A Variational Auto-Encoder Enabled Multi-Band Channel Prediction Scheme for Indoor Localization
Sep 19, 2023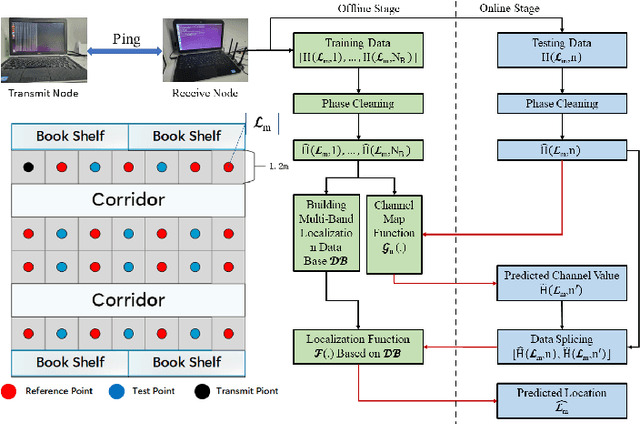
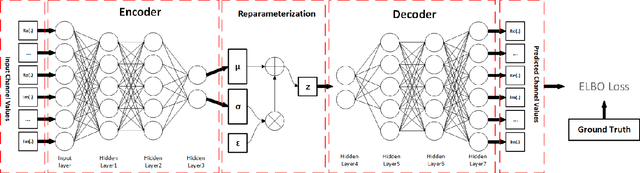
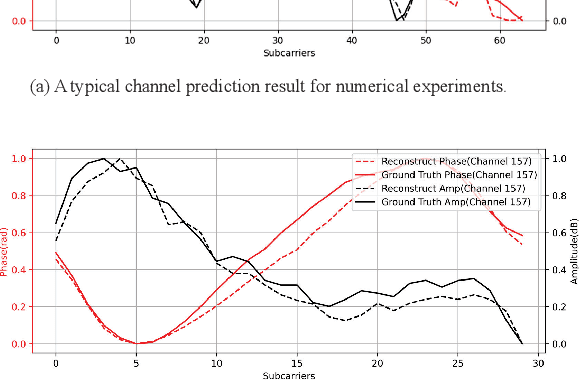
Indoor localization is getting increasing demands for various cutting-edged technologies, like Virtual/Augmented reality and smart home. Traditional model-based localization suffers from significant computational overhead, so fingerprint localization is getting increasing attention, which needs lower computation cost after the fingerprint database is built. However, the accuracy of indoor localization is limited by the complicated indoor environment which brings the multipath signal refraction. In this paper, we provided a scheme to improve the accuracy of indoor fingerprint localization from the frequency domain by predicting the channel state information (CSI) values from another transmitting channel and spliced the multi-band information together to get more precise localization results. We tested our proposed scheme on COST 2100 simulation data and real time orthogonal frequency division multiplexing (OFDM) WiFi data collected from an office scenario.
PDPCRN: Parallel Dual-Path CRN with Bi-directional Inter-Branch Interactions for Multi-Channel Speech Enhancement
Sep 19, 2023

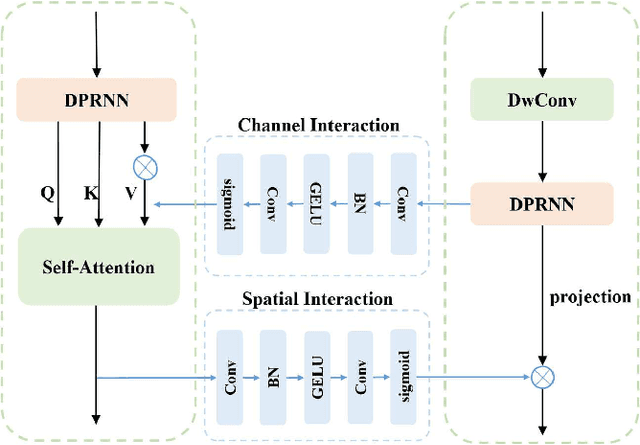

Multi-channel speech enhancement seeks to utilize spatial information to distinguish target speech from interfering signals. While deep learning approaches like the dual-path convolutional recurrent network (DPCRN) have made strides, challenges persist in effectively modeling inter-channel correlations and amalgamating multi-level information. In response, we introduce the Parallel Dual-Path Convolutional Recurrent Network (PDPCRN). This acoustic modeling architecture has two key innovations. First, a parallel design with separate branches extracts complementary features. Second, bi-directional modules enable cross-branch communication. Together, these facilitate diverse representation fusion and enhanced modeling. Experimental validation on TIMIT datasets underscores the prowess of PDPCRN. Notably, against baseline models like the standard DPCRN, PDPCRN not only outperforms in PESQ and STOI metrics but also boasts a leaner computational footprint with reduced parameters.
Normality Learning-based Graph Anomaly Detection via Multi-Scale Contrastive Learning
Oct 01, 2023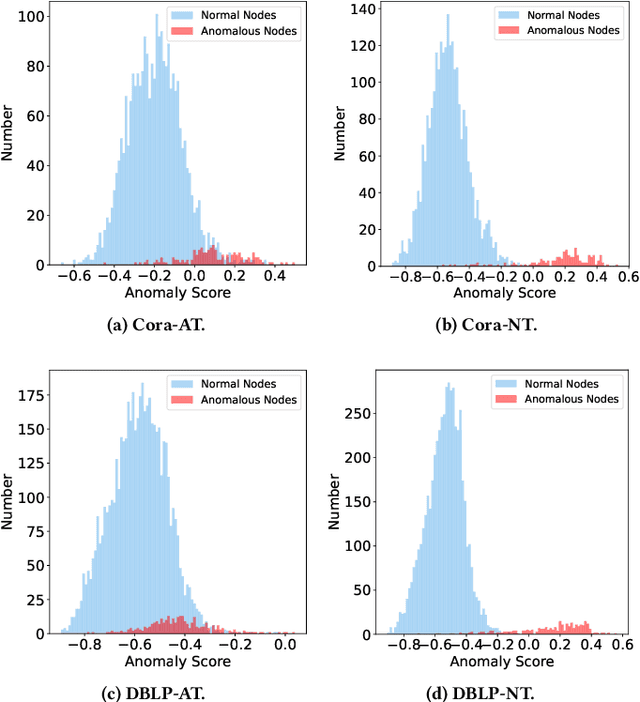
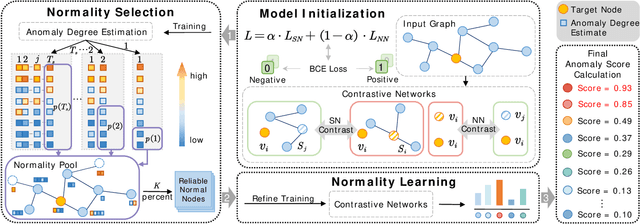
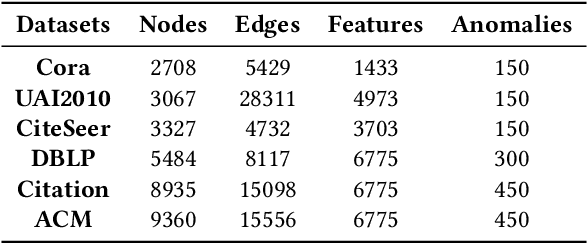
Graph anomaly detection (GAD) has attracted increasing attention in machine learning and data mining. Recent works have mainly focused on how to capture richer information to improve the quality of node embeddings for GAD. Despite their significant advances in detection performance, there is still a relative dearth of research on the properties of the task. GAD aims to discern the anomalies that deviate from most nodes. However, the model is prone to learn the pattern of normal samples which make up the majority of samples. Meanwhile, anomalies can be easily detected when their behaviors differ from normality. Therefore, the performance can be further improved by enhancing the ability to learn the normal pattern. To this end, we propose a normality learning-based GAD framework via multi-scale contrastive learning networks (NLGAD for abbreviation). Specifically, we first initialize the model with the contrastive networks on different scales. To provide sufficient and reliable normal nodes for normality learning, we design an effective hybrid strategy for normality selection. Finally, the model is refined with the only input of reliable normal nodes and learns a more accurate estimate of normality so that anomalous nodes can be more easily distinguished. Eventually, extensive experiments on six benchmark graph datasets demonstrate the effectiveness of our normality learning-based scheme on GAD. Notably, the proposed algorithm improves the detection performance (up to 5.89% AUC gain) compared with the state-of-the-art methods. The source code is released at https://github.com/FelixDJC/NLGAD.
GraphPatcher: Mitigating Degree Bias for Graph Neural Networks via Test-time Augmentation
Oct 01, 2023Recent studies have shown that graph neural networks (GNNs) exhibit strong biases towards the node degree: they usually perform satisfactorily on high-degree nodes with rich neighbor information but struggle with low-degree nodes. Existing works tackle this problem by deriving either designated GNN architectures or training strategies specifically for low-degree nodes. Though effective, these approaches unintentionally create an artificial out-of-distribution scenario, where models mainly or even only observe low-degree nodes during the training, leading to a downgraded performance for high-degree nodes that GNNs originally perform well at. In light of this, we propose a test-time augmentation framework, namely GraphPatcher, to enhance test-time generalization of any GNNs on low-degree nodes. Specifically, GraphPatcher iteratively generates virtual nodes to patch artificially created low-degree nodes via corruptions, aiming at progressively reconstructing target GNN's predictions over a sequence of increasingly corrupted nodes. Through this scheme, GraphPatcher not only learns how to enhance low-degree nodes (when the neighborhoods are heavily corrupted) but also preserves the original superior performance of GNNs on high-degree nodes (when lightly corrupted). Additionally, GraphPatcher is model-agnostic and can also mitigate the degree bias for either self-supervised or supervised GNNs. Comprehensive experiments are conducted over seven benchmark datasets and GraphPatcher consistently enhances common GNNs' overall performance by up to 3.6% and low-degree performance by up to 6.5%, significantly outperforming state-of-the-art baselines. The source code is publicly available at https://github.com/jumxglhf/GraphPatcher.
Reformulating Vision-Language Foundation Models and Datasets Towards Universal Multimodal Assistants
Oct 01, 2023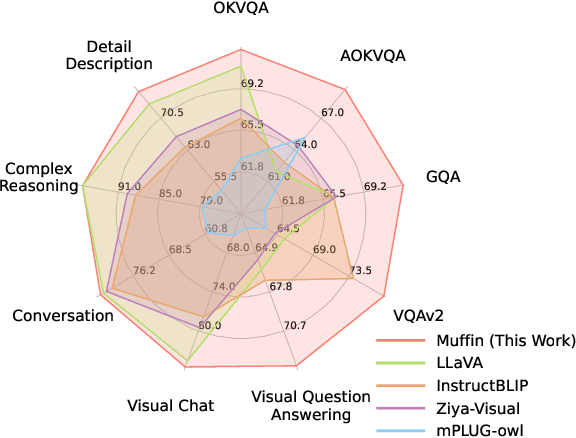
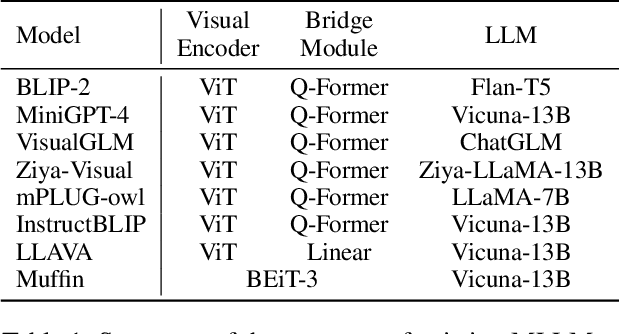
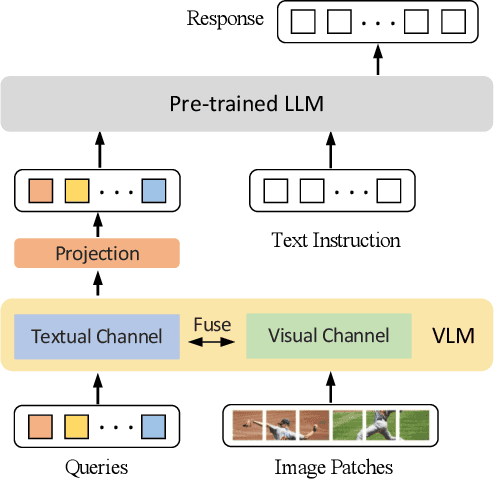
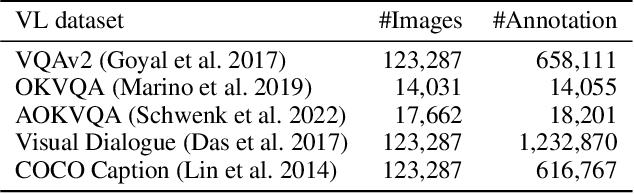
Recent Multimodal Large Language Models (MLLMs) exhibit impressive abilities to perceive images and follow open-ended instructions. The capabilities of MLLMs depend on two crucial factors: the model architecture to facilitate the feature alignment of visual modules and large language models; the multimodal instruction tuning datasets for human instruction following. (i) For the model architecture, most existing models introduce an external bridge module to connect vision encoders with language models, which needs an additional feature-alignment pre-training. In this work, we discover that compact pre-trained vision language models can inherently serve as ``out-of-the-box'' bridges between vision and language. Based on this, we propose Muffin framework, which directly employs pre-trained vision-language models to act as providers of visual signals. (ii) For the multimodal instruction tuning datasets, existing methods omit the complementary relationship between different datasets and simply mix datasets from different tasks. Instead, we propose UniMM-Chat dataset which explores the complementarities of datasets to generate 1.1M high-quality and diverse multimodal instructions. We merge information describing the same image from diverse datasets and transforms it into more knowledge-intensive conversation data. Experimental results demonstrate the effectiveness of the Muffin framework and UniMM-Chat dataset. Muffin achieves state-of-the-art performance on a wide range of vision-language tasks, significantly surpassing state-of-the-art models like LLaVA and InstructBLIP. Our model and dataset are all accessible at https://github.com/thunlp/muffin.
DISCO Might Not Be Funky: Random Intelligent Reflective Surface Configurations That Attack
Oct 01, 2023Emerging intelligent reflective surfaces (IRSs) significantly improve system performance, but also pose a signifcant risk for physical layer security (PLS). Unlike the extensive research on legitimate IRS-enhanced communications, in this article we present an adversarial IRS-based fully-passive jammer (FPJ). We describe typical application scenarios for Disco IRS (DIRS)-based FPJ, where an illegitimate IRS with random, time-varying reflection properties acts like a "disco ball" to randomly change the propagation environment. We introduce the principles of DIRS-based FPJ and overview existing investigations of the technology, including a design example employing one-bit phase shifters. The DIRS-based FPJ can be implemented without either jamming power or channel state information (CSI) for the legitimate users (LUs). It does not suffer from the energy constraints of traditional active jammers, nor does it require any knowledge of the LU channels. In addition to the proposed jamming attack, we also propose an anti-jamming strategy that requires only statistical rather than instantaneous CSI. Furthermore, we present a data frame structure that enables the legitimate access point (AP) to estimate the statistical CSI in the presence of the DIRS jamming. Typical cases are discussed to show the impact of the DIRS-based FPJ and the feasibility of the anti-jamming precoder. Moreover, we outline future research directions and challenges for the DIRS-based FPJ and its anti-jamming precoding to stimulate this line of research and pave the way for practical applications.
Wavelet-based Topological Loss for Low-Light Image Denoising
Sep 16, 2023Despite extensive research conducted in the field of image denoising, many algorithms still heavily depend on supervised learning and their effectiveness primarily relies on the quality and diversity of training data. It is widely assumed that digital image distortions are caused by spatially invariant Additive White Gaussian Noise (AWGN). However, the analysis of real-world data suggests that this assumption is invalid. Therefore, this paper tackles image corruption by real noise, providing a framework to capture and utilise the underlying structural information of an image along with the spatial information conventionally used for deep learning tasks. We propose a novel denoising loss function that incorporates topological invariants and is informed by textural information extracted from the image wavelet domain. The effectiveness of this proposed method was evaluated by training state-of-the-art denoising models on the BVI-Lowlight dataset, which features a wide range of real noise distortions. Adding a topological term to common loss functions leads to a significant increase in the LPIPS (Learned Perceptual Image Patch Similarity) metric, with the improvement reaching up to 25\%. The results indicate that the proposed loss function enables neural networks to learn noise characteristics better. We demonstrate that they can consequently extract the topological features of noise-free images, resulting in enhanced contrast and preserved textural information.