 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DeepHGCN: Toward Deeper Hyperbolic Graph Convolutional Networks
Oct 04, 2023
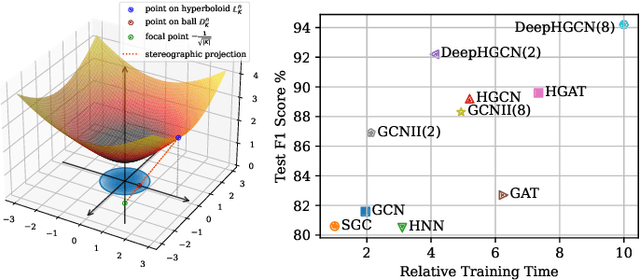
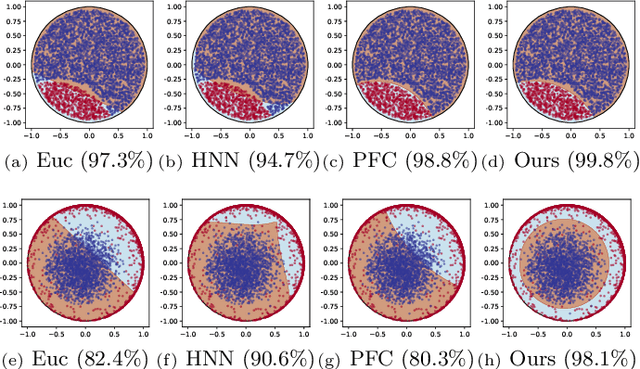
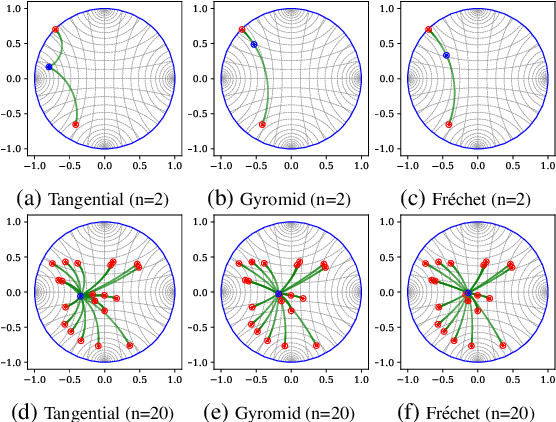
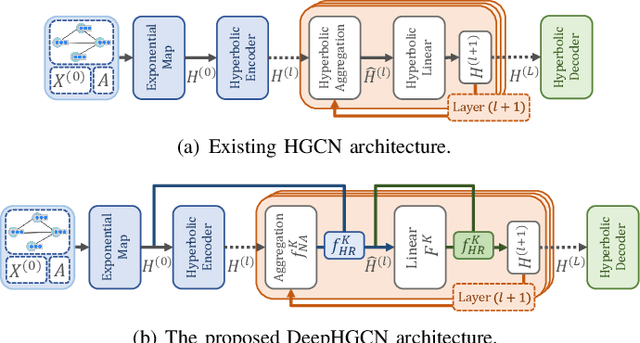
Hyperbolic graph convolutional networks (HGCN) have demonstrated significant potential in extracting information from hierarchical graphs. However, existing HGCNs are limited to shallow architectures, due to the expensive hyperbolic operations and the over-smoothing issue as depth increases. Although in GCNs, treatments have been applied to alleviate over-smoothing, developing a hyperbolic therapy presents distinct challenges since operations should be carefully designed to fit the hyperbolic nature. Addressing the above challenges, in this work, we propose DeepHGCN, the first deep multi-layer HGCN architecture with dramatically improved computational efficiency and substantially alleviated over-smoothing effect. DeepHGCN presents two key enablers of deep HGCNs: (1) a novel hyperbolic feature transformation layer that enables fast and accurate linear maps; and (2) Techniques such as hyperbolic residual connections and regularization for both weights and features facilitated by an efficient hyperbolic midpoint method. Extensive experiments demonstrate that DeepHGCN obtains significant improvements in link prediction and node classification tasks compared to both Euclidean and shallow hyperbolic GCN variants.
Does fine-tuning GPT-3 with the OpenAI API leak personally-identifiable information?
Jul 31, 2023

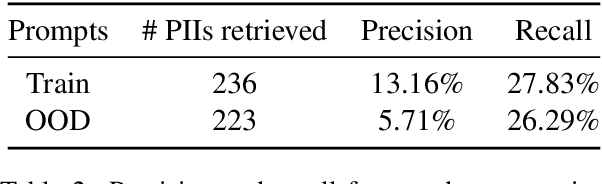
Machine learning practitioners often fine-tune generative pre-trained models like GPT-3 to improve model performance at specific tasks. Previous works, however, suggest that fine-tuned machine learning models memorize and emit sensitive information from the original fine-tuning dataset. Companies such as OpenAI offer fine-tuning services for their models, but no prior work has conducted a memorization attack on any closed-source models. In this work, we simulate a privacy attack on GPT-3 using OpenAI's fine-tuning API. Our objective is to determine if personally identifiable information (PII) can be extracted from this model. We (1) explore the use of naive prompting methods on a GPT-3 fine-tuned classification model, and (2) we design a practical word generation task called Autocomplete to investigate the extent of PII memorization in fine-tuned GPT-3 within a real-world context. Our findings reveal that fine-tuning GPT3 for both tasks led to the model memorizing and disclosing critical personally identifiable information (PII) obtained from the underlying fine-tuning dataset. To encourage further research, we have made our codes and datasets publicly available on GitHub at: https://github.com/albertsun1/gpt3-pii-attacks
Harmonic-NAS: Hardware-Aware Multimodal Neural Architecture Search on Resource-constrained Devices
Sep 28, 2023
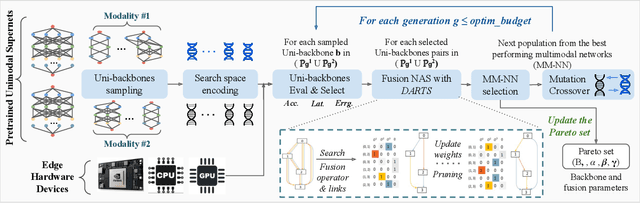
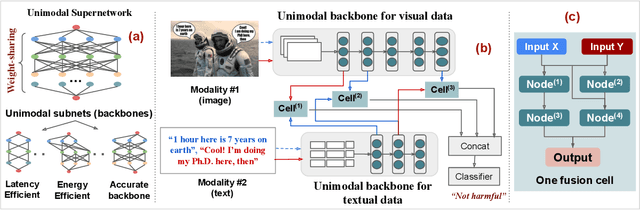

The recent surge of interest surrounding Multimodal Neural Networks (MM-NN) is attributed to their ability to effectively process and integrate multiscale information from diverse data sources. MM-NNs extract and fuse features from multiple modalities using adequate unimodal backbones and specific fusion networks. Although this helps strengthen the multimodal information representation, designing such networks is labor-intensive. It requires tuning the architectural parameters of the unimodal backbones, choosing the fusing point, and selecting the operations for fusion. Furthermore, multimodality AI is emerging as a cutting-edge option in Internet of Things (IoT) systems where inference latency and energy consumption are critical metrics in addition to accuracy. In this paper, we propose Harmonic-NAS, a framework for the joint optimization of unimodal backbones and multimodal fusion networks with hardware awareness on resource-constrained devices. Harmonic-NAS involves a two-tier optimization approach for the unimodal backbone architectures and fusion strategy and operators. By incorporating the hardware dimension into the optimization, evaluation results on various devices and multimodal datasets have demonstrated the superiority of Harmonic-NAS over state-of-the-art approaches achieving up to 10.9% accuracy improvement, 1.91x latency reduction, and 2.14x energy efficiency gain.
DualToken-ViT: Position-aware Efficient Vision Transformer with Dual Token Fusion
Sep 21, 2023

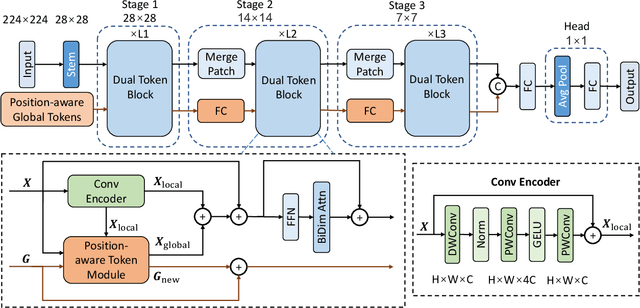
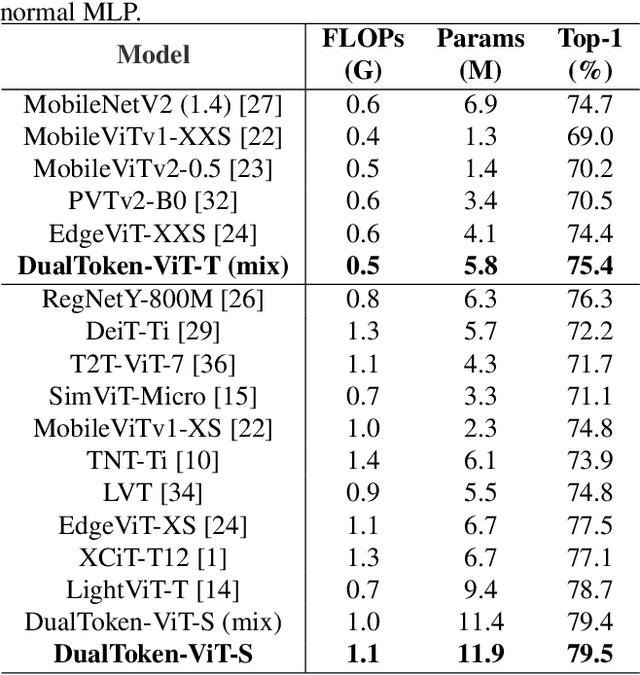
Self-attention-based vision transformers (ViTs) have emerged as a highly competitive architecture in computer vision. Unlike convolutional neural networks (CNNs), ViTs are capable of global information sharing. With the development of various structures of ViTs, ViTs are increasingly advantageous for many vision tasks. However, the quadratic complexity of self-attention renders ViTs computationally intensive, and their lack of inductive biases of locality and translation equivariance demands larger model sizes compared to CNNs to effectively learn visual features. In this paper, we propose a light-weight and efficient vision transformer model called DualToken-ViT that leverages the advantages of CNNs and ViTs. DualToken-ViT effectively fuses the token with local information obtained by convolution-based structure and the token with global information obtained by self-attention-based structure to achieve an efficient attention structure. In addition, we use position-aware global tokens throughout all stages to enrich the global information, which further strengthening the effect of DualToken-ViT. Position-aware global tokens also contain the position information of the image, which makes our model better for vision tasks. We conducted extensive experiments on image classification, object detection and semantic segmentation tasks to demonstrate the effectiveness of DualToken-ViT. On the ImageNet-1K dataset, our models of different scales achieve accuracies of 75.4% and 79.4% with only 0.5G and 1.0G FLOPs, respectively, and our model with 1.0G FLOPs outperforms LightViT-T using global tokens by 0.7%.
TMac: Temporal Multi-Modal Graph Learning for Acoustic Event Classification
Sep 21, 2023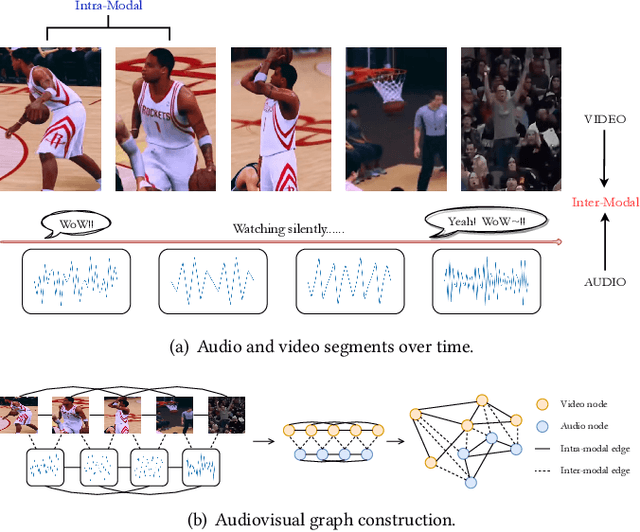

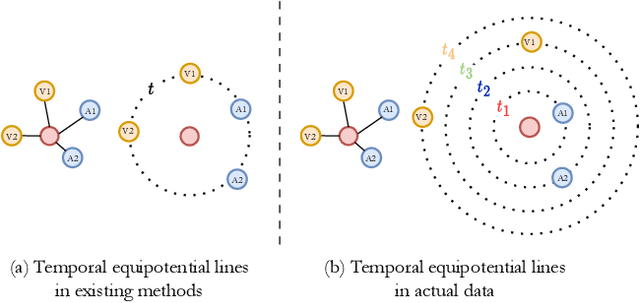
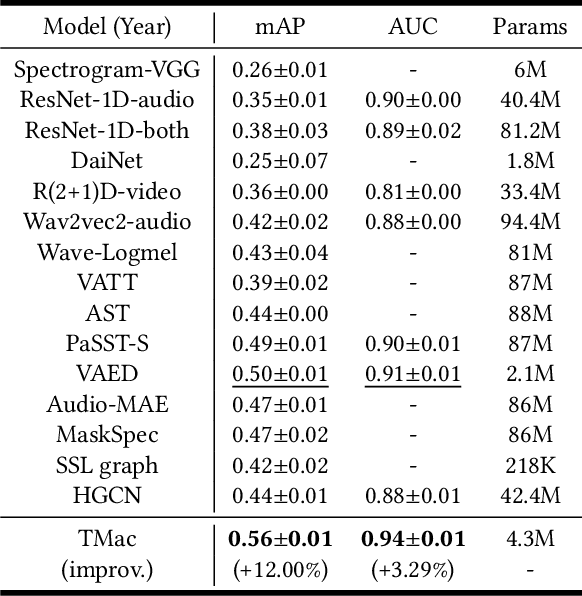
Audiovisual data is everywhere in this digital age, which raises higher requirements for the deep learning models developed on them. To well handle the information of the multi-modal data is the key to a better audiovisual modal. We observe that these audiovisual data naturally have temporal attributes, such as the time information for each frame in the video. More concretely, such data is inherently multi-modal according to both audio and visual cues, which proceed in a strict chronological order. It indicates that temporal information is important in multi-modal acoustic event modeling for both intra- and inter-modal. However, existing methods deal with each modal feature independently and simply fuse them together, which neglects the mining of temporal relation and thus leads to sub-optimal performance. With this motivation, we propose a Temporal Multi-modal graph learning method for Acoustic event Classification, called TMac, by modeling such temporal information via graph learning techniques. In particular, we construct a temporal graph for each acoustic event, dividing its audio data and video data into multiple segments. Each segment can be considered as a node, and the temporal relationships between nodes can be considered as timestamps on their edges. In this case, we can smoothly capture the dynamic information in intra-modal and inter-modal. Several experiments are conducted to demonstrate TMac outperforms other SOTA models in performance. Our code is available at https://github.com/MGitHubL/TMac.
StructChart: Perception, Structuring, Reasoning for Visual Chart Understanding
Sep 20, 2023
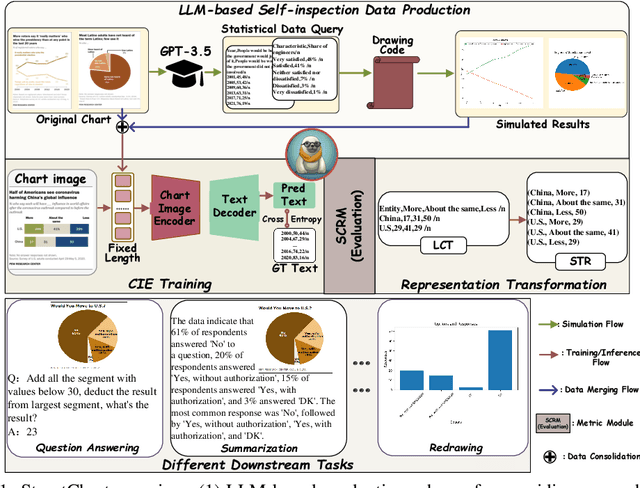
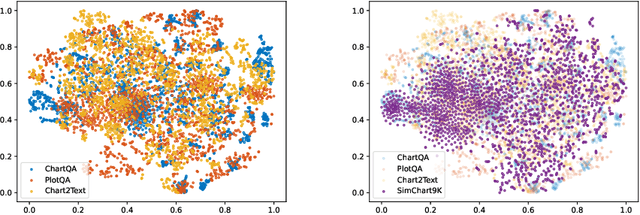
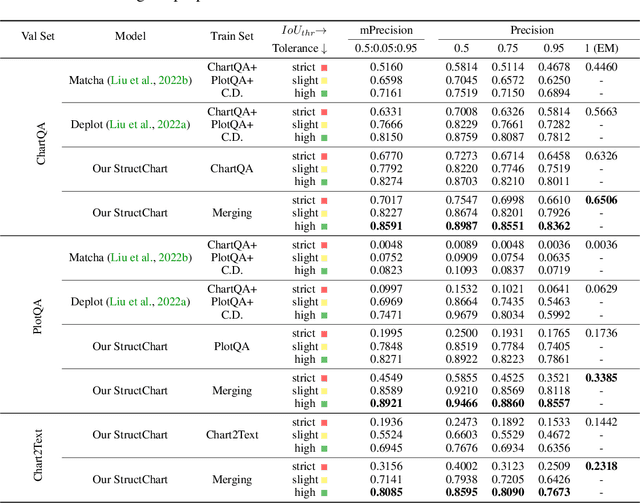
Charts are common in literature across different scientific fields, conveying rich information easily accessible to readers. Current chart-related tasks focus on either chart perception which refers to extracting information from the visual charts, or performing reasoning given the extracted data, e.g. in a tabular form. In this paper, we aim to establish a unified and label-efficient learning paradigm for joint perception and reasoning tasks, which can be generally applicable to different downstream tasks, beyond the question-answering task as specifically studied in peer works. Specifically, StructChart first reformulates the chart information from the popular tubular form (specifically linearized CSV) to the proposed Structured Triplet Representations (STR), which is more friendly for reducing the task gap between chart perception and reasoning due to the employed structured information extraction for charts. We then propose a Structuring Chart-oriented Representation Metric (SCRM) to quantitatively evaluate the performance for the chart perception task. To enrich the dataset for training, we further explore the possibility of leveraging the Large Language Model (LLM), enhancing the chart diversity in terms of both chart visual style and its statistical information. Extensive experiments are conducted on various chart-related tasks, demonstrating the effectiveness and promising potential for a unified chart perception-reasoning paradigm to push the frontier of chart understanding.
Multi-view Fuzzy Representation Learning with Rules based Model
Sep 20, 2023
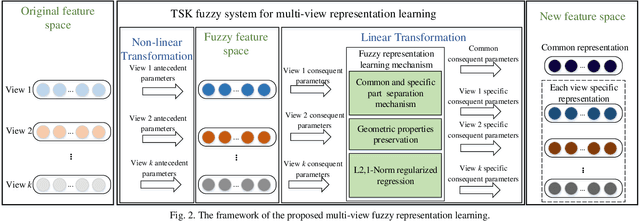
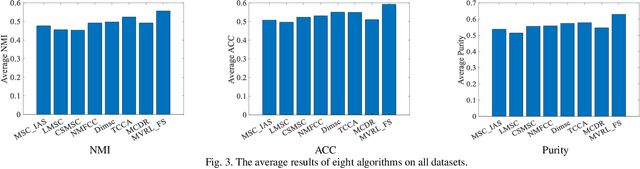
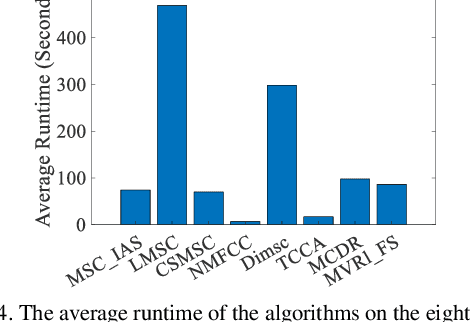
Unsupervised multi-view representation learning has been extensively studied for mining multi-view data. However, some critical challenges remain. On the one hand, the existing methods cannot explore multi-view data comprehensively since they usually learn a common representation between views, given that multi-view data contains both the common information between views and the specific information within each view. On the other hand, to mine the nonlinear relationship between data, kernel or neural network methods are commonly used for multi-view representation learning. However, these methods are lacking in interpretability. To this end, this paper proposes a new multi-view fuzzy representation learning method based on the interpretable Takagi-Sugeno-Kang (TSK) fuzzy system (MVRL_FS). The method realizes multi-view representation learning from two aspects. First, multi-view data are transformed into a high-dimensional fuzzy feature space, while the common information between views and specific information of each view are explored simultaneously. Second, a new regularization method based on L_(2,1)-norm regression is proposed to mine the consistency information between views, while the geometric structure of the data is preserved through the Laplacian graph. Finally, extensive experiments on many benchmark multi-view datasets are conducted to validate the superiority of the proposed method.
A 5' UTR Language Model for Decoding Untranslated Regions of mRNA and Function Predictions
Oct 06, 2023The 5' UTR, a regulatory region at the beginning of an mRNA molecule, plays a crucial role in regulating the translation process and impacts the protein expression level. Language models have showcased their effectiveness in decoding the functions of protein and genome sequences. Here, we introduced a language model for 5' UTR, which we refer to as the UTR-LM. The UTR-LM is pre-trained on endogenous 5' UTRs from multiple species and is further augmented with supervised information including secondary structure and minimum free energy. We fine-tuned the UTR-LM in a variety of downstream tasks. The model outperformed the best-known benchmark by up to 42% for predicting the Mean Ribosome Loading, and by up to 60% for predicting the Translation Efficiency and the mRNA Expression Level. The model also applies to identifying unannotated Internal Ribosome Entry Sites within the untranslated region and improves the AUPR from 0.37 to 0.52 compared to the best baseline. Further, we designed a library of 211 novel 5' UTRs with high predicted values of translation efficiency and evaluated them via a wet-lab assay. Experiment results confirmed that our top designs achieved a 32.5% increase in protein production level relative to well-established 5' UTR optimized for therapeutics.
On the Error-Propagation of Inexact Deflation for Principal Component Analysis
Oct 06, 2023Principal Component Analysis (PCA) is a popular tool in data analysis, especially when the data is high-dimensional. PCA aims to find subspaces, spanned by the so-called \textit{principal components}, that best explain the variance in the dataset. The deflation method is a popular meta-algorithm -- used to discover such subspaces -- that sequentially finds individual principal components, starting from the most important one and working its way towards the less important ones. However, due to its sequential nature, the numerical error introduced by not estimating principal components exactly -- e.g., due to numerical approximations through this process -- propagates, as deflation proceeds. To the best of our knowledge, this is the first work that mathematically characterizes the error propagation of the inexact deflation method, and this is the key contribution of this paper. We provide two main results: $i)$ when the sub-routine for finding the leading eigenvector is generic, and $ii)$ when power iteration is used as the sub-routine. In the latter case, the additional directional information from power iteration allows us to obtain a tighter error bound than the analysis of the sub-routine agnostic case. As an outcome, we provide explicit characterization on how the error progresses and affects subsequent principal component estimations for this fundamental problem.
Improving Neural Radiance Field using Near-Surface Sampling with Point Cloud Generation
Oct 06, 2023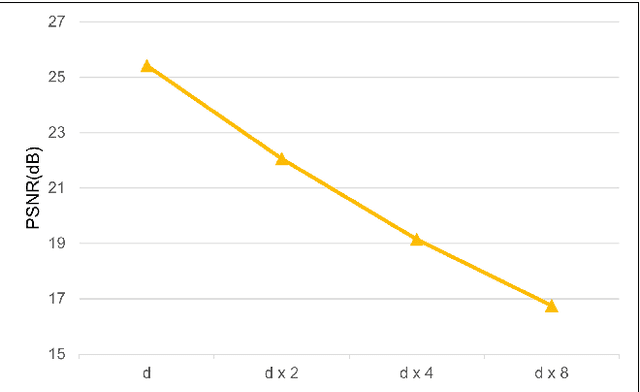
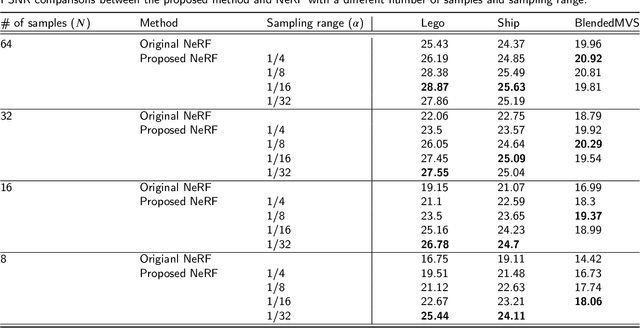
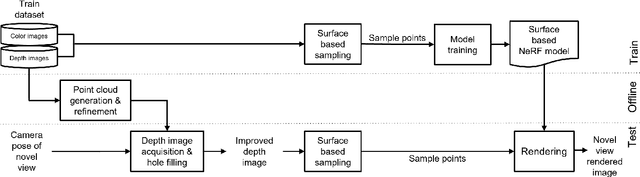
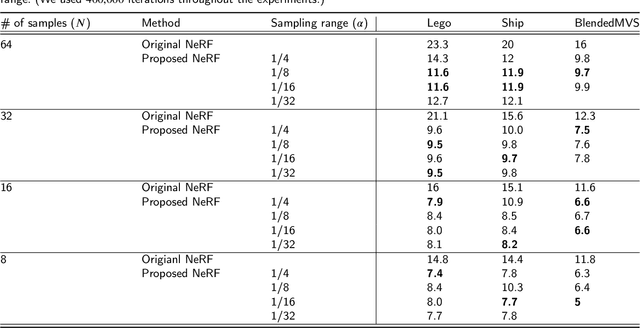
Neural radiance field (NeRF) is an emerging view synthesis method that samples points in a three-dimensional (3D) space and estimates their existence and color probabilities. The disadvantage of NeRF is that it requires a long training time since it samples many 3D points. In addition, if one samples points from occluded regions or in the space where an object is unlikely to exist, the rendering quality of NeRF can be degraded. These issues can be solved by estimating the geometry of 3D scene. This paper proposes a near-surface sampling framework to improve the rendering quality of NeRF. To this end, the proposed method estimates the surface of a 3D object using depth images of the training set and sampling is performed around there only. To obtain depth information on a novel view, the paper proposes a 3D point cloud generation method and a simple refining method for projected depth from a point cloud. Experimental results show that the proposed near-surface sampling NeRF framework can significantly improve the rendering quality, compared to the original NeRF and a state-of-the-art depth-based NeRF method. In addition, one can significantly accelerate the training time of a NeRF model with the proposed near-surface sampling framework.