 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Superpixel Transformers for Efficient Semantic Segmentation
Oct 02, 2023
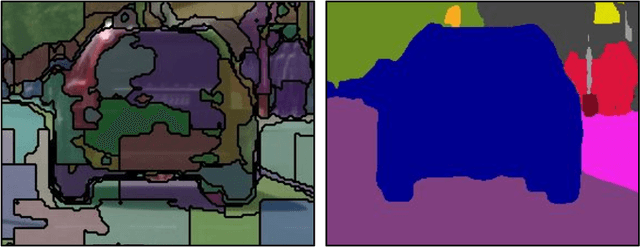
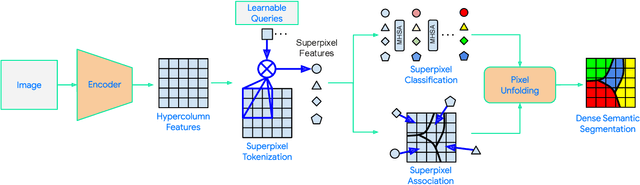


Semantic segmentation, which aims to classify every pixel in an image, is a key task in machine perception, with many applications across robotics and autonomous driving. Due to the high dimensionality of this task, most existing approaches use local operations, such as convolutions, to generate per-pixel features. However, these methods are typically unable to effectively leverage global context information due to the high computational costs of operating on a dense image. In this work, we propose a solution to this issue by leveraging the idea of superpixels, an over-segmentation of the image, and applying them with a modern transformer framework. In particular, our model learns to decompose the pixel space into a spatially low dimensional superpixel space via a series of local cross-attentions. We then apply multi-head self-attention to the superpixels to enrich the superpixel features with global context and then directly produce a class prediction for each superpixel. Finally, we directly project the superpixel class predictions back into the pixel space using the associations between the superpixels and the image pixel features. Reasoning in the superpixel space allows our method to be substantially more computationally efficient compared to convolution-based decoder methods. Yet, our method achieves state-of-the-art performance in semantic segmentation due to the rich superpixel features generated by the global self-attention mechanism. Our experiments on Cityscapes and ADE20K demonstrate that our method matches the state of the art in terms of accuracy, while outperforming in terms of model parameters and latency.
HOI4ABOT: Human-Object Interaction Anticipation for Human Intention Reading Collaborative roBOTs
Sep 28, 2023Robots are becoming increasingly integrated into our lives, assisting us in various tasks. To ensure effective collaboration between humans and robots, it is essential that they understand our intentions and anticipate our actions. In this paper, we propose a Human-Object Interaction (HOI) anticipation framework for collaborative robots. We propose an efficient and robust transformer-based model to detect and anticipate HOIs from videos. This enhanced anticipation empowers robots to proactively assist humans, resulting in more efficient and intuitive collaborations. Our model outperforms state-of-the-art results in HOI detection and anticipation in VidHOI dataset with an increase of 1.76% and 1.04% in mAP respectively while being 15.4 times faster. We showcase the effectiveness of our approach through experimental results in a real robot, demonstrating that the robot's ability to anticipate HOIs is key for better Human-Robot Interaction. More information can be found on our project webpage: https://evm7.github.io/HOI4ABOT_page/
Unsupervised Fact Verification by Language Model Distillation
Sep 28, 2023Unsupervised fact verification aims to verify a claim using evidence from a trustworthy knowledge base without any kind of data annotation. To address this challenge, algorithms must produce features for every claim that are both semantically meaningful, and compact enough to find a semantic alignment with the source information. In contrast to previous work, which tackled the alignment problem by learning over annotated corpora of claims and their corresponding labels, we propose SFAVEL (Self-supervised Fact Verification via Language Model Distillation), a novel unsupervised framework that leverages pre-trained language models to distil self-supervised features into high-quality claim-fact alignments without the need for annotations. This is enabled by a novel contrastive loss function that encourages features to attain high-quality claim and evidence alignments whilst preserving the semantic relationships across the corpora. Notably, we present results that achieve a new state-of-the-art on the standard FEVER fact verification benchmark (+8% accuracy) with linear evaluation.
The ARRT of Language-Models-as-a-Service: Overview of a New Paradigm and its Challenges
Sep 28, 2023Some of the most powerful language models currently are proprietary systems, accessible only via (typically restrictive) web or software programming interfaces. This is the Language-Models-as-a-Service (LMaaS) paradigm. Contrasting with scenarios where full model access is available, as in the case of open-source models, such closed-off language models create specific challenges for evaluating, benchmarking, and testing them. This paper has two goals: on the one hand, we delineate how the aforementioned challenges act as impediments to the accessibility, replicability, reliability, and trustworthiness (ARRT) of LMaaS. We systematically examine the issues that arise from a lack of information about language models for each of these four aspects. We shed light on current solutions, provide some recommendations, and highlight the directions for future advancements. On the other hand, it serves as a one-stop-shop for the extant knowledge about current, major LMaaS, offering a synthesized overview of the licences and capabilities their interfaces offer.
Hallucination Reduction in Long Input Text Summarization
Sep 28, 2023Hallucination in text summarization refers to the phenomenon where the model generates information that is not supported by the input source document. Hallucination poses significant obstacles to the accuracy and reliability of the generated summaries. In this paper, we aim to reduce hallucinated outputs or hallucinations in summaries of long-form text documents. We have used the PubMed dataset, which contains long scientific research documents and their abstracts. We have incorporated the techniques of data filtering and joint entity and summary generation (JAENS) in the fine-tuning of the Longformer Encoder-Decoder (LED) model to minimize hallucinations and thereby improve the quality of the generated summary. We have used the following metrics to measure factual consistency at the entity level: precision-source, and F1-target. Our experiments show that the fine-tuned LED model performs well in generating the paper abstract. Data filtering techniques based on some preprocessing steps reduce entity-level hallucinations in the generated summaries in terms of some of the factual consistency metrics.
Novel Deep Learning Pipeline for Automatic Weapon Detection
Sep 28, 2023Weapon and gun violence have recently become a pressing issue today. The degree of these crimes and activities has risen to the point of being termed as an epidemic. This prevalent misuse of weapons calls for an automatic system that detects weapons in real-time. Real-time surveillance video is captured and recorded in almost all public forums and places. These videos contain abundant raw data which can be extracted and processed into meaningful information. This paper proposes a novel pipeline consisting of an ensemble of convolutional neural networks with distinct architectures. Each neural network is trained with a unique mini-batch with little to no overlap in the training samples. This paper will present several promising results using multiple datasets associated with comparing the proposed architecture and state-of-the-art (SoA) models. The proposed pipeline produced an average increase of 5% in accuracy, specificity, and recall compared to the SoA systems.
Propagation and Attribution of Uncertainty in Medical Imaging Pipelines
Sep 28, 2023Uncertainty estimation, which provides a means of building explainable neural networks for medical imaging applications, have mostly been studied for single deep learning models that focus on a specific task. In this paper, we propose a method to propagate uncertainty through cascades of deep learning models in medical imaging pipelines. This allows us to aggregate the uncertainty in later stages of the pipeline and to obtain a joint uncertainty measure for the predictions of later models. Additionally, we can separately report contributions of the aleatoric, data-based, uncertainty of every component in the pipeline. We demonstrate the utility of our method on a realistic imaging pipeline that reconstructs undersampled brain and knee magnetic resonance (MR) images and subsequently predicts quantitative information from the images, such as the brain volume, or knee side or patient's sex. We quantitatively show that the propagated uncertainty is correlated with input uncertainty and compare the proportions of contributions of pipeline stages to the joint uncertainty measure.
Information Retrieval Meets Large Language Models: A Strategic Report from Chinese IR Community
Jul 19, 2023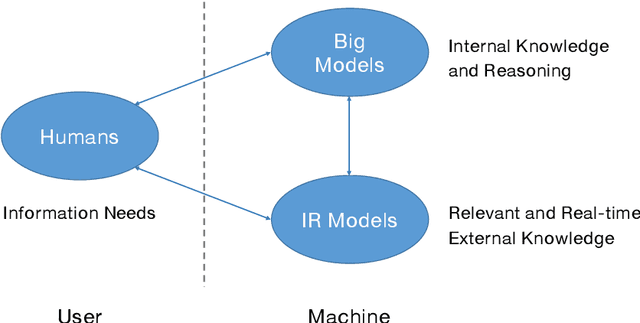
The research field of Information Retrieval (IR) has evolved significantly, expanding beyond traditional search to meet diverse user information needs. Recently, Large Language Models (LLMs) have demonstrated exceptional capabilities in text understanding, generation, and knowledge inference, opening up exciting avenues for IR research. LLMs not only facilitate generative retrieval but also offer improved solutions for user understanding, model evaluation, and user-system interactions. More importantly, the synergistic relationship among IR models, LLMs, and humans forms a new technical paradigm that is more powerful for information seeking. IR models provide real-time and relevant information, LLMs contribute internal knowledge, and humans play a central role of demanders and evaluators to the reliability of information services. Nevertheless, significant challenges exist, including computational costs, credibility concerns, domain-specific limitations, and ethical considerations. To thoroughly discuss the transformative impact of LLMs on IR research, the Chinese IR community conducted a strategic workshop in April 2023, yielding valuable insights. This paper provides a summary of the workshop's outcomes, including the rethinking of IR's core values, the mutual enhancement of LLMs and IR, the proposal of a novel IR technical paradigm, and open challenges.
When Large Language Models Meet Citation: A Survey
Sep 18, 2023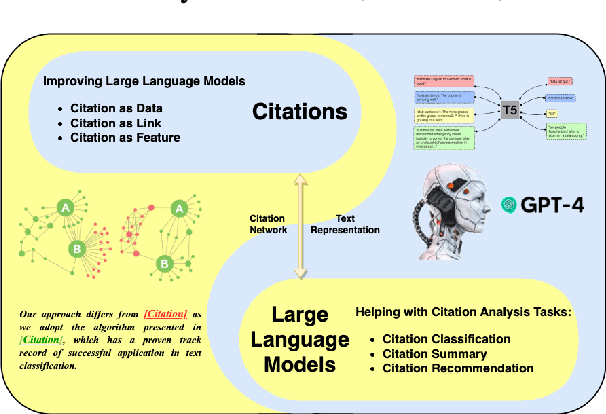


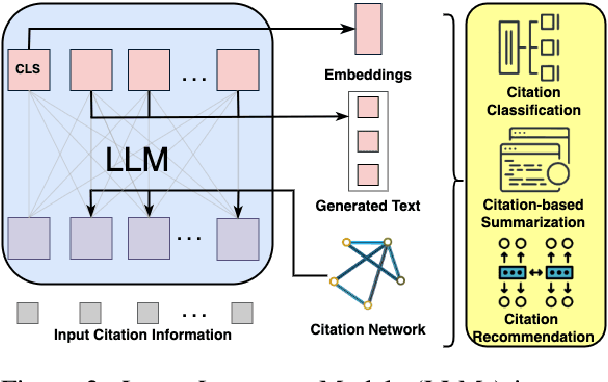
Citations in scholarly work serve the essential purpose of acknowledging and crediting the original sources of knowledge that have been incorporated or referenced. Depending on their surrounding textual context, these citations are used for different motivations and purposes. Large Language Models (LLMs) could be helpful in capturing these fine-grained citation information via the corresponding textual context, thereby enabling a better understanding towards the literature. Furthermore, these citations also establish connections among scientific papers, providing high-quality inter-document relationships and human-constructed knowledge. Such information could be incorporated into LLMs pre-training and improve the text representation in LLMs. Therefore, in this paper, we offer a preliminary review of the mutually beneficial relationship between LLMs and citation analysis. Specifically, we review the application of LLMs for in-text citation analysis tasks, including citation classification, citation-based summarization, and citation recommendation. We then summarize the research pertinent to leveraging citation linkage knowledge to improve text representations of LLMs via citation prediction, network structure information, and inter-document relationship. We finally provide an overview of these contemporary methods and put forth potential promising avenues in combining LLMs and citation analysis for further investigation.
Improved Factorized Neural Transducer Model For text-only Domain Adaptation
Sep 18, 2023End-to-end models, such as the neural Transducer, have been successful in integrating acoustic and linguistic information jointly to achieve excellent recognition performance. However, adapting these models with text-only data is challenging. Factorized neural Transducer (FNT) aims to address this issue by introducing a separate vocabulary decoder to predict the vocabulary, which can effectively perform traditional text data adaptation. Nonetheless, this approach has limitations in fusing acoustic and language information seamlessly. Moreover, a degradation in word error rate (WER) on the general test sets was also observed, leading to doubts about its overall performance. In response to this challenge, we present an improved factorized neural Transducer (IFNT) model structure designed to comprehensively integrate acoustic and language information while enabling effective text adaptation. We evaluate the performance of our proposed methods through in-domain experiments on GigaSpeech and out-of-domain experiments adapting to EuroParl, TED-LIUM, and Medical datasets. After text-only adaptation, IFNT yields 7.9% to 28.5% relative WER improvements over the standard neural Transducer with shallow fusion, and relative WER reductions ranging from 1.6% to 8.2% on the three test sets compared to the FNT model.