 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Memory-Efficient Continual Learning Object Segmentation for Long Video
Sep 26, 2023
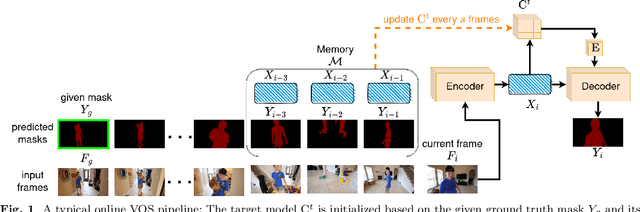
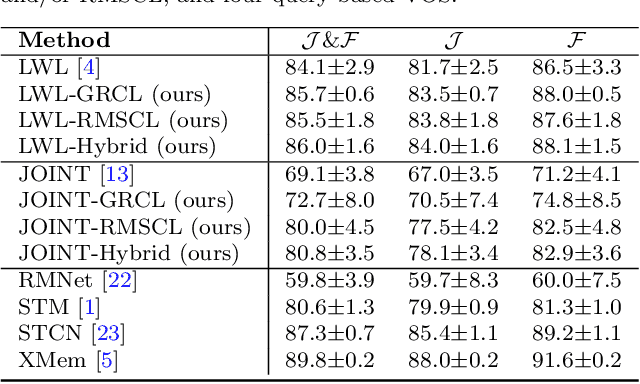
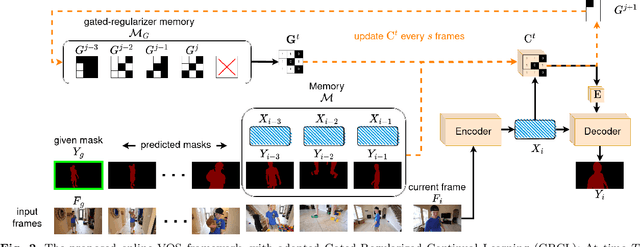
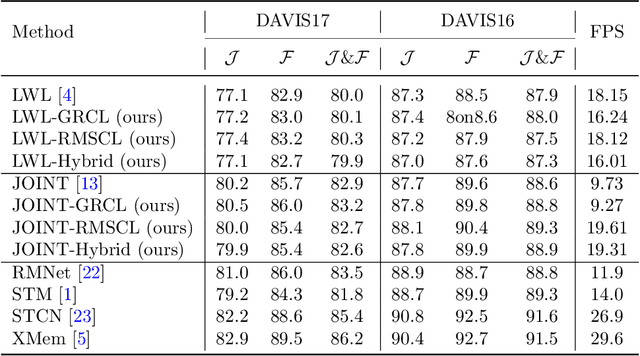
Recent state-of-the-art semi-supervised Video Object Segmentation (VOS) methods have shown significant improvements in target object segmentation accuracy when information from preceding frames is used in undertaking segmentation on the current frame. In particular, such memory-based approaches can help a model to more effectively handle appearance changes (representation drift) or occlusions. Ideally, for maximum performance, online VOS methods would need all or most of the preceding frames (or their extracted information) to be stored in memory and be used for online learning in consecutive frames. Such a solution is not feasible for long videos, as the required memory size would grow without bound. On the other hand, these methods can fail when memory is limited and a target object experiences repeated representation drifts throughout a video. We propose two novel techniques to reduce the memory requirement of online VOS methods while improving modeling accuracy and generalization on long videos. Motivated by the success of continual learning techniques in preserving previously-learned knowledge, here we propose Gated-Regularizer Continual Learning (GRCL), which improves the performance of any online VOS subject to limited memory, and a Reconstruction-based Memory Selection Continual Learning (RMSCL) which empowers online VOS methods to efficiently benefit from stored information in memory. Experimental results show that the proposed methods improve the performance of online VOS models up to 10 %, and boosts their robustness on long-video datasets while maintaining comparable performance on short-video datasets DAVIS16 and DAVIS17.
Can pre-trained models assist in dataset distillation?
Oct 05, 2023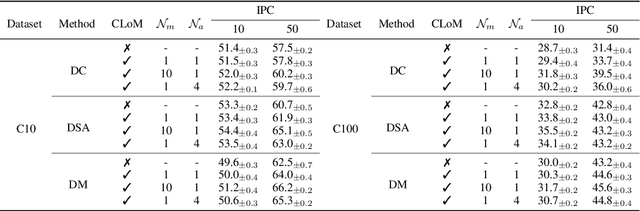
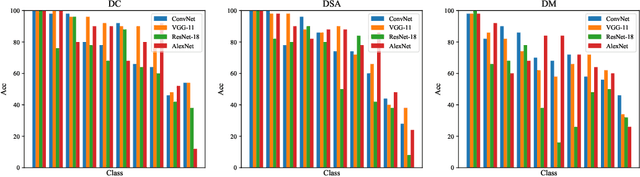
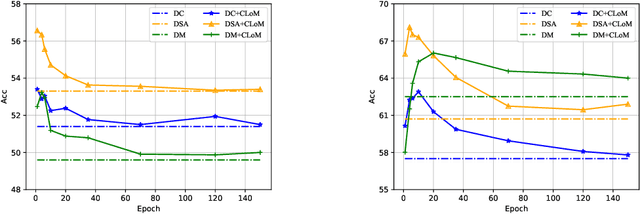
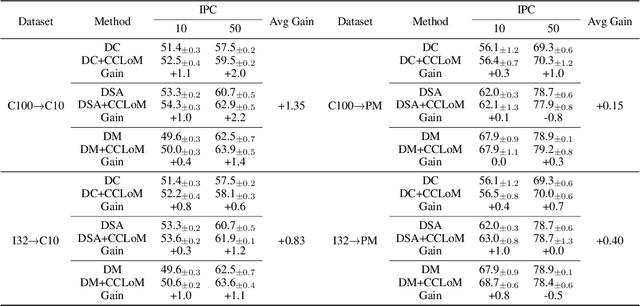
Dataset Distillation (DD) is a prominent technique that encapsulates knowledge from a large-scale original dataset into a small synthetic dataset for efficient training. Meanwhile, Pre-trained Models (PTMs) function as knowledge repositories, containing extensive information from the original dataset. This naturally raises a question: Can PTMs effectively transfer knowledge to synthetic datasets, guiding DD accurately? To this end, we conduct preliminary experiments, confirming the contribution of PTMs to DD. Afterwards, we systematically study different options in PTMs, including initialization parameters, model architecture, training epoch and domain knowledge, revealing that: 1) Increasing model diversity enhances the performance of synthetic datasets; 2) Sub-optimal models can also assist in DD and outperform well-trained ones in certain cases; 3) Domain-specific PTMs are not mandatory for DD, but a reasonable domain match is crucial. Finally, by selecting optimal options, we significantly improve the cross-architecture generalization over baseline DD methods. We hope our work will facilitate researchers to develop better DD techniques. Our code is available at https://github.com/yaolu-zjut/DDInterpreter.
Diffusion Models as Masked Audio-Video Learners
Oct 05, 2023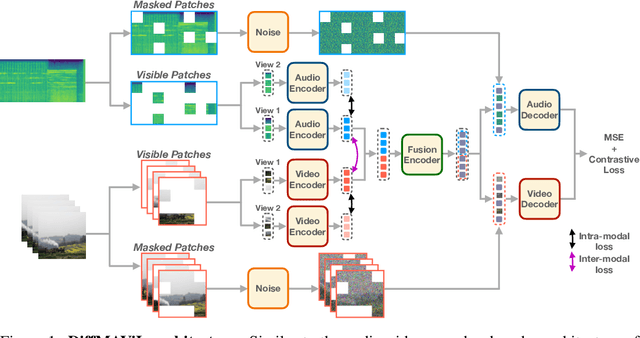



Over the past several years, the synchronization between audio and visual signals has been leveraged to learn richer audio-visual representations. Aided by the large availability of unlabeled videos, many unsupervised training frameworks have demonstrated impressive results in various downstream audio and video tasks. Recently, Masked Audio-Video Learners (MAViL) has emerged as a state-of-the-art audio-video pre-training framework. MAViL couples contrastive learning with masked autoencoding to jointly reconstruct audio spectrograms and video frames by fusing information from both modalities. In this paper, we study the potential synergy between diffusion models and MAViL, seeking to derive mutual benefits from these two frameworks. The incorporation of diffusion into MAViL, combined with various training efficiency methodologies that include the utilization of a masking ratio curriculum and adaptive batch sizing, results in a notable 32% reduction in pre-training Floating-Point Operations (FLOPS) and an 18% decrease in pre-training wall clock time. Crucially, this enhanced efficiency does not compromise the model's performance in downstream audio-classification tasks when compared to MAViL's performance.
Audio Event-Relational Graph Representation Learning for Acoustic Scene Classification
Oct 05, 2023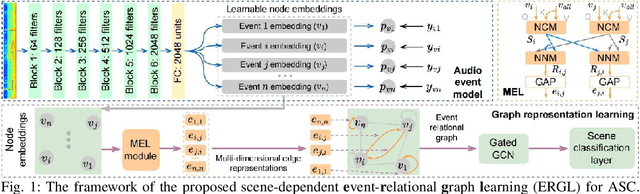
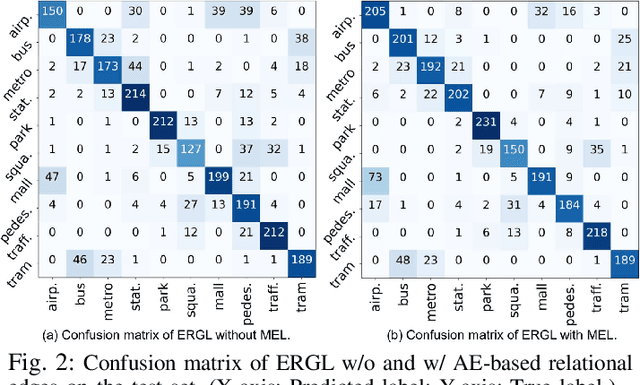
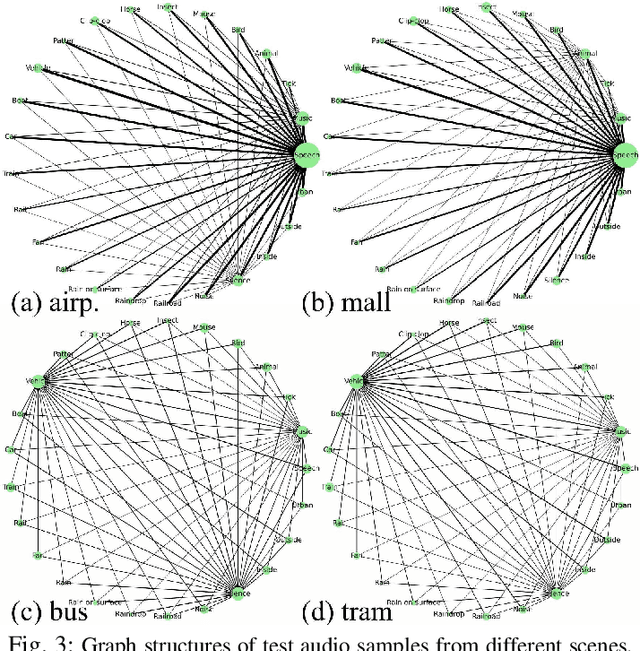

Most deep learning-based acoustic scene classification (ASC) approaches identify scenes based on acoustic features converted from audio clips containing mixed information entangled by polyphonic audio events (AEs). However, these approaches have difficulties in explaining what cues they use to identify scenes. This paper conducts the first study on disclosing the relationship between real-life acoustic scenes and semantic embeddings from the most relevant AEs. Specifically, we propose an event-relational graph representation learning (ERGL) framework for ASC to classify scenes, and simultaneously answer clearly and straightly which cues are used in classifying. In the event-relational graph, embeddings of each event are treated as nodes, while relationship cues derived from each pair of nodes are described by multi-dimensional edge features. Experiments on a real-life ASC dataset show that the proposed ERGL achieves competitive performance on ASC by learning embeddings of only a limited number of AEs. The results show the feasibility of recognizing diverse acoustic scenes based on the audio event-relational graph. Visualizations of graph representations learned by ERGL are available here (https://github.com/Yuanbo2020/ERGL).
Contextualized Structural Self-supervised Learning for Ontology Matching
Oct 05, 2023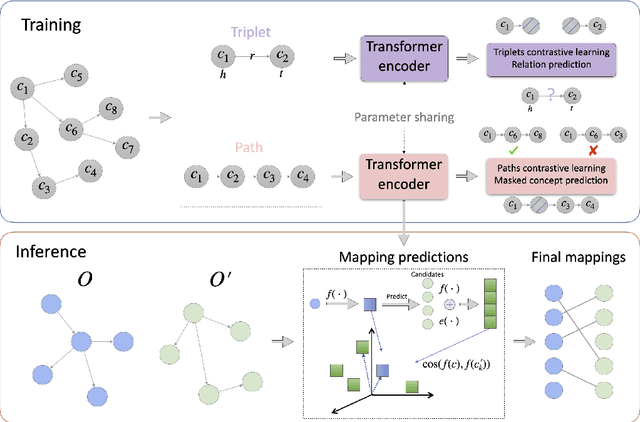
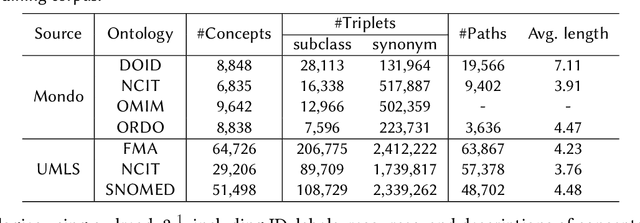
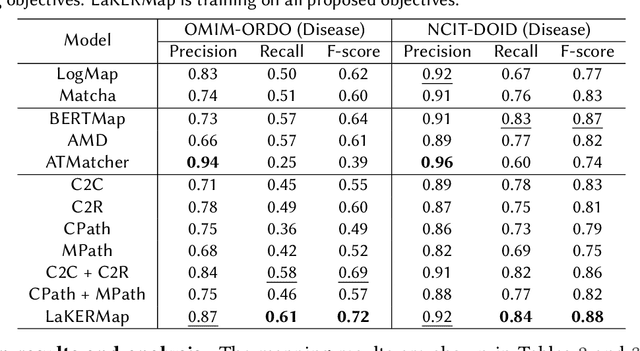
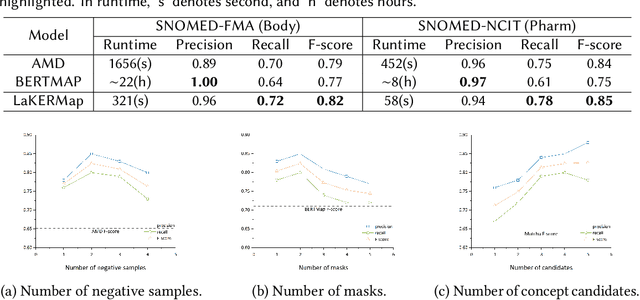
Ontology matching (OM) entails the identification of semantic relationships between concepts within two or more knowledge graphs (KGs) and serves as a critical step in integrating KGs from various sources. Recent advancements in deep OM models have harnessed the power of transformer-based language models and the advantages of knowledge graph embedding. Nevertheless, these OM models still face persistent challenges, such as a lack of reference alignments, runtime latency, and unexplored different graph structures within an end-to-end framework. In this study, we introduce a novel self-supervised learning OM framework with input ontologies, called LaKERMap. This framework capitalizes on the contextual and structural information of concepts by integrating implicit knowledge into transformers. Specifically, we aim to capture multiple structural contexts, encompassing both local and global interactions, by employing distinct training objectives. To assess our methods, we utilize the Bio-ML datasets and tasks. The findings from our innovative approach reveal that LaKERMap surpasses state-of-the-art systems in terms of alignment quality and inference time. Our models and codes are available here: https://github.com/ellenzhuwang/lakermap.
RTDK-BO: High Dimensional Bayesian Optimization with Reinforced Transformer Deep kernels
Oct 05, 2023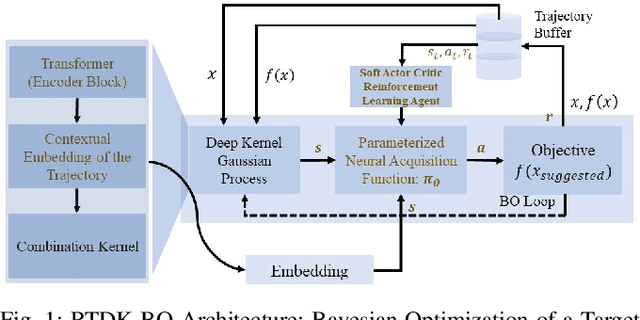
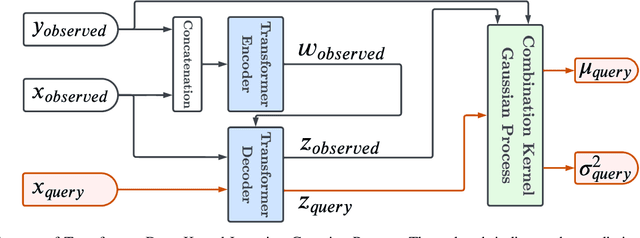
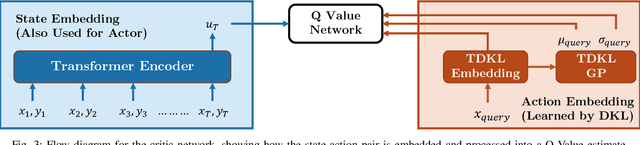
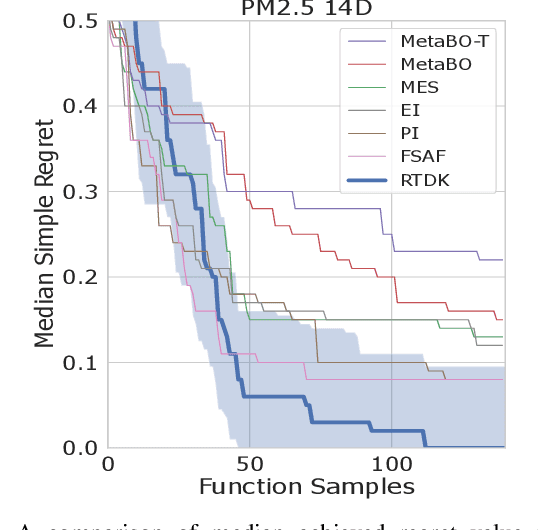
Bayesian Optimization (BO), guided by Gaussian process (GP) surrogates, has proven to be an invaluable technique for efficient, high-dimensional, black-box optimization, a critical problem inherent to many applications such as industrial design and scientific computing. Recent contributions have introduced reinforcement learning (RL) to improve the optimization performance on both single function optimization and \textit{few-shot} multi-objective optimization. However, even few-shot techniques fail to exploit similarities shared between closely related objectives. In this paper, we combine recent developments in Deep Kernel Learning (DKL) and attention-based Transformer models to improve the modeling powers of GP surrogates with meta-learning. We propose a novel method for improving meta-learning BO surrogates by incorporating attention mechanisms into DKL, empowering the surrogates to adapt to contextual information gathered during the BO process. We combine this Transformer Deep Kernel with a learned acquisition function trained with continuous Soft Actor-Critic Reinforcement Learning to aid in exploration. This Reinforced Transformer Deep Kernel (RTDK-BO) approach yields state-of-the-art results in continuous high-dimensional optimization problems.
GRAPES: Learning to Sample Graphs for Scalable Graph Neural Networks
Oct 05, 2023Graph neural networks (GNNs) learn the representation of nodes in a graph by aggregating the neighborhood information in various ways. As these networks grow in depth, their receptive field grows exponentially due to the increase in neighborhood sizes, resulting in high memory costs. Graph sampling solves memory issues in GNNs by sampling a small ratio of the nodes in the graph. This way, GNNs can scale to much larger graphs. Most sampling methods focus on fixed sampling heuristics, which may not generalize to different structures or tasks. We introduce GRAPES, an adaptive graph sampling method that learns to identify sets of influential nodes for training a GNN classifier. GRAPES uses a GFlowNet to learn node sampling probabilities given the classification objectives. We evaluate GRAPES across several small- and large-scale graph benchmarks and demonstrate its effectiveness in accuracy and scalability. In contrast to existing sampling methods, GRAPES maintains high accuracy even with small sample sizes and, therefore, can scale to very large graphs. Our code is publicly available at https://github.com/dfdazac/grapes.
Reinforced UI Instruction Grounding: Towards a Generic UI Task Automation API
Oct 07, 2023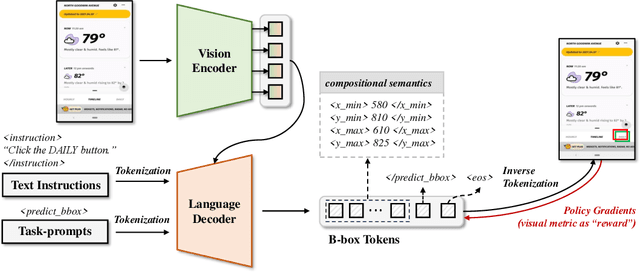


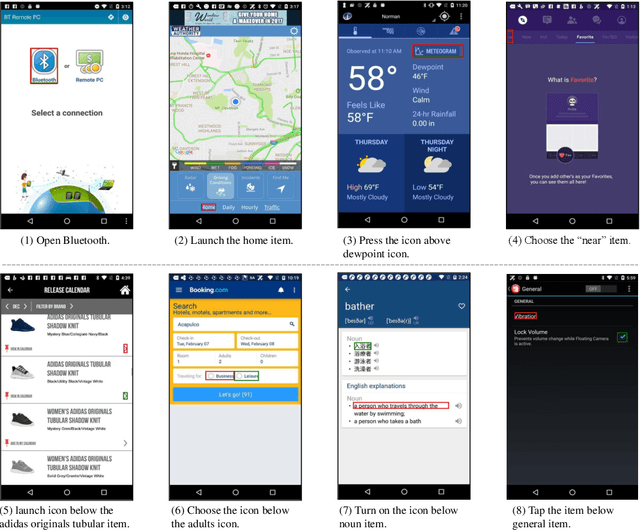
Recent popularity of Large Language Models (LLMs) has opened countless possibilities in automating numerous AI tasks by connecting LLMs to various domain-specific models or APIs, where LLMs serve as dispatchers while domain-specific models or APIs are action executors. Despite the vast numbers of domain-specific models/APIs, they still struggle to comprehensively cover super diverse automation demands in the interaction between human and User Interfaces (UIs). In this work, we build a multimodal model to ground natural language instructions in given UI screenshots as a generic UI task automation executor. This metadata-free grounding model, consisting of a visual encoder and a language decoder, is first pretrained on well studied document understanding tasks and then learns to decode spatial information from UI screenshots in a promptable way. To facilitate the exploitation of image-to-text pretrained knowledge, we follow the pixel-to-sequence paradigm to predict geometric coordinates in a sequence of tokens using a language decoder. We further propose an innovative Reinforcement Learning (RL) based algorithm to supervise the tokens in such sequence jointly with visually semantic metrics, which effectively strengthens the spatial decoding capability of the pixel-to-sequence paradigm. Extensive experiments demonstrate our proposed reinforced UI instruction grounding model outperforms the state-of-the-art methods by a clear margin and shows the potential as a generic UI task automation API.
Reliable Test-Time Adaptation via Agreement-on-the-Line
Oct 07, 2023Test-time adaptation (TTA) methods aim to improve robustness to distribution shifts by adapting models using unlabeled data from the shifted test distribution. However, there remain unresolved challenges that undermine the reliability of TTA, which include difficulties in evaluating TTA performance, miscalibration after TTA, and unreliable hyperparameter tuning for adaptation. In this work, we make a notable and surprising observation that TTAed models strongly show the agreement-on-the-line phenomenon (Baek et al., 2022) across a wide range of distribution shifts. We find such linear trends occur consistently in a wide range of models adapted with various hyperparameters, and persist in distributions where the phenomenon fails to hold in vanilla models (i.e., before adaptation). We leverage these observations to make TTA methods more reliable in three perspectives: (i) estimating OOD accuracy (without labeled data) to determine when TTA helps and when it hurts, (ii) calibrating TTAed models without label information, and (iii) reliably determining hyperparameters for TTA without any labeled validation data. Through extensive experiments, we demonstrate that various TTA methods can be precisely evaluated, both in terms of their improvements and degradations. Moreover, our proposed methods on unsupervised calibration and hyperparameters tuning for TTA achieve results close to the ones assuming access to ground-truth labels, in terms of both OOD accuracy and calibration error.
Improving the Reliability of Large Language Models by Leveraging Uncertainty-Aware In-Context Learning
Oct 07, 2023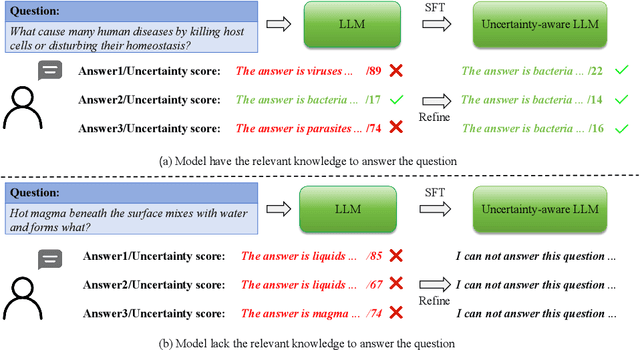
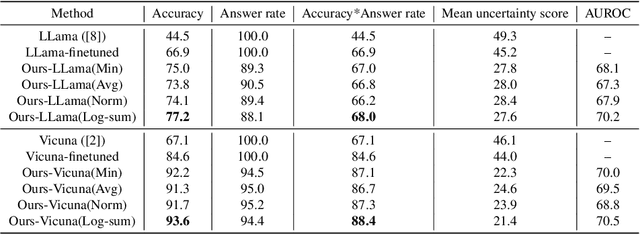
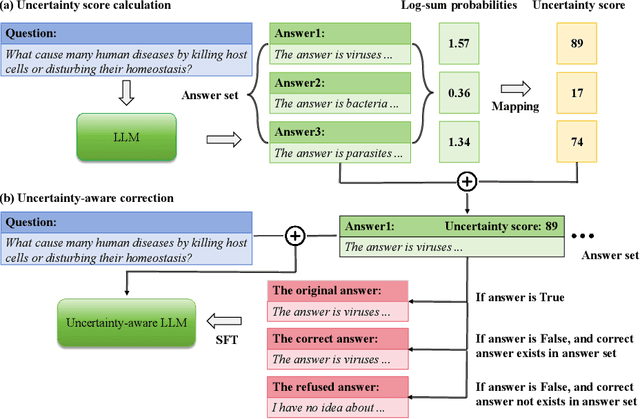

In recent years, large-scale language models (LLMs) have gained attention for their impressive text generation capabilities. However, these models often face the challenge of "hallucination," which undermines their reliability. In this study, we introduce an uncertainty-aware in-context learning framework to empower the model to enhance or reject its output in response to uncertainty. Human-defined methods for estimating uncertainty typically assume that "uncertainty is lower when the model's response is correct compared to when it is incorrect." However, setting a precise threshold to distinguish correctness is challenging. Therefore, we introduce uncertainty information as an intermediary variable that implicitly influences the model's behavior. Our innovative uncertainty-aware in-context learning framework involves fine-tuning the LLM using a calibration dataset. Our aim is to improve the model's responses by filtering out answers with high uncertainty while considering the model's knowledge limitations. We evaluate the model's knowledge by examining multiple responses to the same question for the presence of a correct answer. When the model lacks relevant knowledge, the response should indicate that the question cannot be answered. Conversely, when the model has relevant knowledge, the response should provide the correct answer. Extensive experiments confirm the effectiveness of our framework, leading to two key findings. First, the logit output values of the LLM partly reflect inherent uncertainty. Second, our model autonomously recognizes uncertainty, resulting in improved responses.