 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fill in the Blank: Exploring and Enhancing LLM Capabilities for Backward Reasoning in Math Word Problems
Oct 03, 2023
While forward reasoning (i.e. find the answer given the question) has been explored extensively in the recent literature, backward reasoning is relatively unexplored. We examine the backward reasoning capabilities of LLMs on Math Word Problems (MWPs): given a mathematical question and its answer, with some details omitted from the question, can LLMs effectively retrieve the missing information? In this paper, we formally define the backward reasoning task on math word problems and modify three datasets to evaluate this task: GSM8k, SVAMP and MultiArith. Our findings show a significant drop in the accuracy of models on backward reasoning compared to forward reasoning across four SOTA LLMs (GPT4, GPT3.5, PaLM-2, and LLaMa-2). Utilizing the specific format of this task, we propose three novel techniques that improve performance: Rephrase reformulates the given problem into a forward reasoning problem, PAL-Tools combines the idea of Program-Aided LLMs to produce a set of equations that can be solved by an external solver, and Check your Work exploits the availability of natural verifier of high accuracy in the forward direction, interleaving solving and verification steps. Finally, realizing that each of our base methods correctly solves a different set of problems, we propose a novel Bayesian formulation for creating an ensemble over these base methods aided by a verifier to further boost the accuracy by a significant margin. Extensive experimentation demonstrates that our techniques successively improve the performance of LLMs on the backward reasoning task, with the final ensemble-based method resulting in a substantial performance gain compared to the raw LLMs with standard prompting techniques such as chain-of-thought.
Applying BioBERT to Extract Germline Gene-Disease Associations for Building a Knowledge Graph from the Biomedical Literature
Sep 30, 2023Published biomedical information has and continues to rapidly increase. The recent advancements in Natural Language Processing (NLP), have generated considerable interest in automating the extraction, normalization, and representation of biomedical knowledge about entities such as genes and diseases. Our study analyzes germline abstracts in the construction of knowledge graphs of the of the immense work that has been done in this area for genes and diseases. This paper presents SimpleGermKG, an automatic knowledge graph construction approach that connects germline genes and diseases. For the extraction of genes and diseases, we employ BioBERT, a pre-trained BERT model on biomedical corpora. We propose an ontology-based and rule-based algorithm to standardize and disambiguate medical terms. For semantic relationships between articles, genes, and diseases, we implemented a part-whole relation approach to connect each entity with its data source and visualize them in a graph-based knowledge representation. Lastly, we discuss the knowledge graph applications, limitations, and challenges to inspire the future research of germline corpora. Our knowledge graph contains 297 genes, 130 diseases, and 46,747 triples. Graph-based visualizations are used to show the results.
* 10 pages
Encouraging Inferable Behavior for Autonomy: Repeated Bimatrix Stackelberg Games with Observations
Sep 30, 2023When interacting with other non-competitive decision-making agents, it is critical for an autonomous agent to have inferable behavior: Their actions must convey their intention and strategy. For example, an autonomous car's strategy must be inferable by the pedestrians interacting with the car. We model the inferability problem using a repeated bimatrix Stackelberg game with observations where a leader and a follower repeatedly interact. During the interactions, the leader uses a fixed, potentially mixed strategy. The follower, on the other hand, does not know the leader's strategy and dynamically reacts based on observations that are the leader's previous actions. In the setting with observations, the leader may suffer from an inferability loss, i.e., the performance compared to the setting where the follower has perfect information of the leader's strategy. We show that the inferability loss is upper-bounded by a function of the number of interactions and the stochasticity level of the leader's strategy, encouraging the use of inferable strategies with lower stochasticity levels. As a converse result, we also provide a game where the required number of interactions is lower bounded by a function of the desired inferability loss.
Beyond Random Noise: Insights on Anonymization Strategies from a Latent Bandit Study
Sep 30, 2023This paper investigates the issue of privacy in a learning scenario where users share knowledge for a recommendation task. Our study contributes to the growing body of research on privacy-preserving machine learning and underscores the need for tailored privacy techniques that address specific attack patterns rather than relying on one-size-fits-all solutions. We use the latent bandit setting to evaluate the trade-off between privacy and recommender performance by employing various aggregation strategies, such as averaging, nearest neighbor, and clustering combined with noise injection. More specifically, we simulate a linkage attack scenario leveraging publicly available auxiliary information acquired by the adversary. Our results on three open real-world datasets reveal that adding noise using the Laplace mechanism to an individual user's data record is a poor choice. It provides the highest regret for any noise level, relative to de-anonymization probability and the ADS metric. Instead, one should combine noise with appropriate aggregation strategies. For example, using averages from clusters of different sizes provides flexibility not achievable by varying the amount of noise alone. Generally, no single aggregation strategy can consistently achieve the optimum regret for a given desired level of privacy.
A Brief History of Prompt: Leveraging Language Models
Sep 30, 2023This paper presents a comprehensive exploration of the evolution of prompt engineering and generation in the field of natural language processing (NLP). Starting from the early language models and information retrieval systems, we trace the key developments that have shaped prompt engineering over the years. The introduction of attention mechanisms in 2015 revolutionized language understanding, leading to advancements in controllability and context-awareness. Subsequent breakthroughs in reinforcement learning techniques further enhanced prompt engineering, addressing issues like exposure bias and biases in generated text. We examine the significant contributions in 2018 and 2019, focusing on fine-tuning strategies, control codes, and template-based generation. The paper also discusses the growing importance of fairness, human-AI collaboration, and low-resource adaptation. In 2020 and 2021, contextual prompting and transfer learning gained prominence, while 2022 and 2023 witnessed the emergence of advanced techniques like unsupervised pre-training and novel reward shaping. Throughout the paper, we reference specific research studies that exemplify the impact of various developments on prompt engineering. The journey of prompt engineering continues, with ethical considerations being paramount for the responsible and inclusive future of AI systems.
The Sem-Lex Benchmark: Modeling ASL Signs and Their Phonemes
Sep 30, 2023
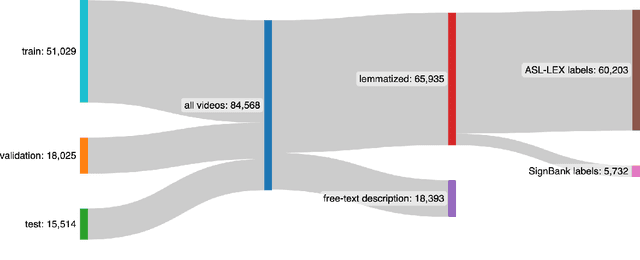
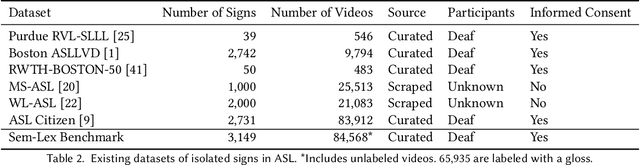
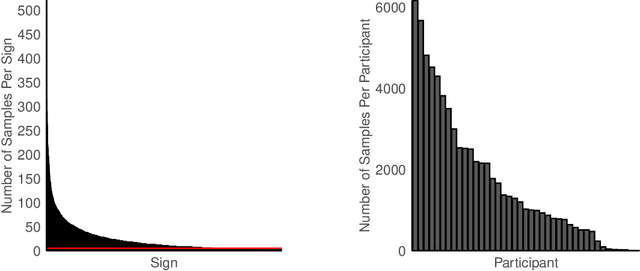
Sign language recognition and translation technologies have the potential to increase access and inclusion of deaf signing communities, but research progress is bottlenecked by a lack of representative data. We introduce a new resource for American Sign Language (ASL) modeling, the Sem-Lex Benchmark. The Benchmark is the current largest of its kind, consisting of over 84k videos of isolated sign productions from deaf ASL signers who gave informed consent and received compensation. Human experts aligned these videos with other sign language resources including ASL-LEX, SignBank, and ASL Citizen, enabling useful expansions for sign and phonological feature recognition. We present a suite of experiments which make use of the linguistic information in ASL-LEX, evaluating the practicality and fairness of the Sem-Lex Benchmark for isolated sign recognition (ISR). We use an SL-GCN model to show that the phonological features are recognizable with 85% accuracy, and that they are effective as an auxiliary target to ISR. Learning to recognize phonological features alongside gloss results in a 6% improvement for few-shot ISR accuracy and a 2% improvement for ISR accuracy overall. Instructions for downloading the data can be found at https://github.com/leekezar/SemLex.
"AI enhances our performance, I have no doubt this one will do the same": The Placebo effect is robust to negative descriptions of AI
Sep 28, 2023Heightened AI expectations facilitate performance in human-AI interactions through placebo effects. While lowering expectations to control for placebo effects is advisable, overly negative expectations could induce nocebo effects. In a letter discrimination task, we informed participants that an AI would either increase or decrease their performance by adapting the interface, but in reality, no AI was present in any condition. A Bayesian analysis showed that participants had high expectations and performed descriptively better irrespective of the AI description when a sham-AI was present. Using cognitive modeling, we could trace this advantage back to participants gathering more information. A replication study verified that negative AI descriptions do not alter expectations, suggesting that performance expectations with AI are biased and robust to negative verbal descriptions. We discuss the impact of user expectations on AI interactions and evaluation and provide a behavioral placebo marker for human-AI interaction
Constructing Synthetic Treatment Groups without the Mean Exchangeability Assumption
Sep 28, 2023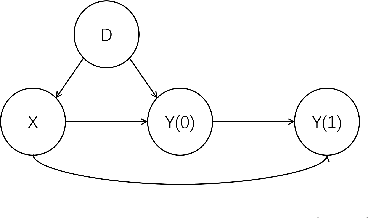


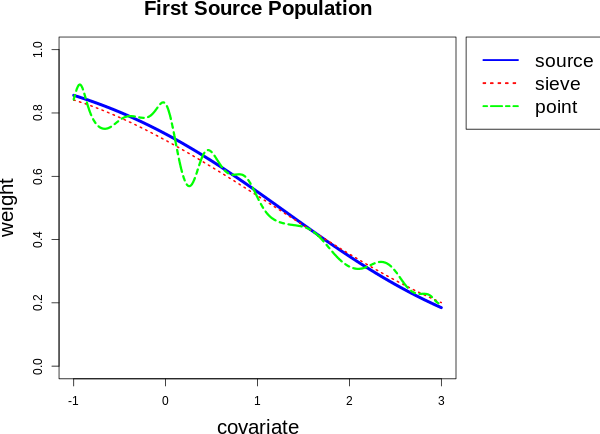
The purpose of this work is to transport the information from multiple randomized controlled trials to the target population where we only have the control group data. Previous works rely critically on the mean exchangeability assumption. However, as pointed out by many current studies, the mean exchangeability assumption might be violated. Motivated by the synthetic control method, we construct a synthetic treatment group for the target population by a weighted mixture of treatment groups of source populations. We estimate the weights by minimizing the conditional maximum mean discrepancy between the weighted control groups of source populations and the target population. We establish the asymptotic normality of the synthetic treatment group estimator based on the sieve semiparametric theory. Our method can serve as a novel complementary approach when the mean exchangeability assumption is violated. Experiments are conducted on synthetic and real-world datasets to demonstrate the effectiveness of our methods.
Forgetting Private Textual Sequences in Language Models via Leave-One-Out Ensemble
Sep 28, 2023Recent research has shown that language models have a tendency to memorize rare or unique token sequences in the training corpus. After deploying a model, practitioners might be asked to delete any personal information from the model by individuals' requests. Re-training the underlying model every time individuals would like to practice their rights to be forgotten is computationally expensive. We employ a teacher-student framework and propose a novel leave-one-out ensemble method to unlearn the targeted textual sequences that need to be forgotten from the model. In our approach, multiple teachers are trained on disjoint sets; for each targeted sequence to be removed, we exclude the teacher trained on the set containing this sequence and aggregate the predictions from remaining teachers to provide supervision during fine-tuning. Experiments on LibriSpeech and WikiText-103 datasets show that the proposed method achieves superior privacy-utility trade-offs than other counterparts.
Cross-Dataset Experimental Study of Radar-Camera Fusion in Bird's-Eye View
Sep 27, 2023By exploiting complementary sensor information, radar and camera fusion systems have the potential to provide a highly robust and reliable perception system for advanced driver assistance systems and automated driving functions. Recent advances in camera-based object detection offer new radar-camera fusion possibilities with bird's eye view feature maps. In this work, we propose a novel and flexible fusion network and evaluate its performance on two datasets: nuScenes and View-of-Delft. Our experiments reveal that while the camera branch needs large and diverse training data, the radar branch benefits more from a high-performance radar. Using transfer learning, we improve the camera's performance on the smaller dataset. Our results further demonstrate that the radar-camera fusion approach significantly outperforms the camera-only and radar-only baselines.