 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Spherical Position Encoding for Transformers
Oct 04, 2023
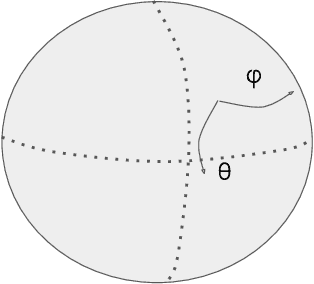
Position encoding is the primary mechanism which induces notion of sequential order for input tokens in transformer architectures. Even though this formulation in the original transformer paper has yielded plausible performance for general purpose language understanding and generation, several new frameworks such as Rotary Position Embedding (RoPE) are proposed for further enhancement. In this paper, we introduce the notion of "geotokens" which are input elements for transformer architectures, each representing an information related to a geological location. Unlike the natural language the sequential position is not important for the model but the geographical coordinates are. In order to induce the concept of relative position for such a setting and maintain the proportion between the physical distance and distance on embedding space, we formulate a position encoding mechanism based on RoPE architecture which is adjusted for spherical coordinates.
Causality-informed Rapid Post-hurricane Building Damage Detection in Large Scale from InSAR Imagery
Oct 02, 2023Timely and accurate assessment of hurricane-induced building damage is crucial for effective post-hurricane response and recovery efforts. Recently, remote sensing technologies provide large-scale optical or Interferometric Synthetic Aperture Radar (InSAR) imagery data immediately after a disastrous event, which can be readily used to conduct rapid building damage assessment. Compared to optical satellite imageries, the Synthetic Aperture Radar can penetrate cloud cover and provide more complete spatial coverage of damaged zones in various weather conditions. However, these InSAR imageries often contain highly noisy and mixed signals induced by co-occurring or co-located building damage, flood, flood/wind-induced vegetation changes, as well as anthropogenic activities, making it challenging to extract accurate building damage information. In this paper, we introduced an approach for rapid post-hurricane building damage detection from InSAR imagery. This approach encoded complex causal dependencies among wind, flood, building damage, and InSAR imagery using a holistic causal Bayesian network. Based on the causal Bayesian network, we further jointly inferred the large-scale unobserved building damage by fusing the information from InSAR imagery with prior physical models of flood and wind, without the need for ground truth labels. Furthermore, we validated our estimation results in a real-world devastating hurricane -- the 2022 Hurricane Ian. We gathered and annotated building damage ground truth data in Lee County, Florida, and compared the introduced method's estimation results with the ground truth and benchmarked it against state-of-the-art models to assess the effectiveness of our proposed method. Results show that our method achieves rapid and accurate detection of building damage, with significantly reduced processing time compared to traditional manual inspection methods.
Modality-aware Transformer for Time series Forecasting
Oct 02, 2023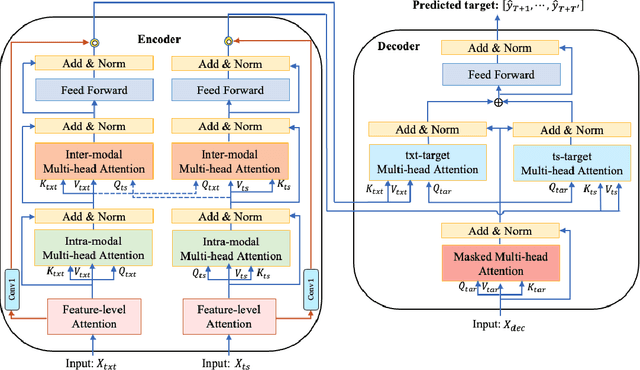

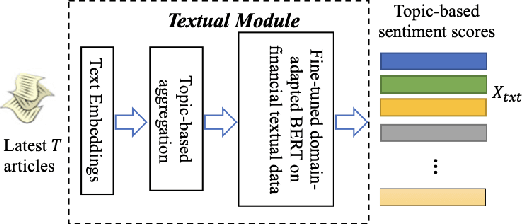
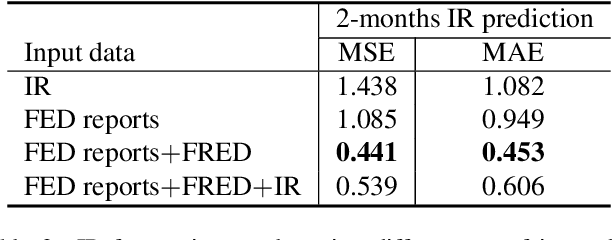
Time series forecasting presents a significant challenge, particularly when its accuracy relies on external data sources rather than solely on historical values. This issue is prevalent in the financial sector, where the future behavior of time series is often intricately linked to information derived from various textual reports and a multitude of economic indicators. In practice, the key challenge lies in constructing a reliable time series forecasting model capable of harnessing data from diverse sources and extracting valuable insights to predict the target time series accurately. In this work, we tackle this challenging problem and introduce a novel multimodal transformer-based model named the Modality-aware Transformer. Our model excels in exploring the power of both categorical text and numerical timeseries to forecast the target time series effectively while providing insights through its neural attention mechanism. To achieve this, we develop feature-level attention layers that encourage the model to focus on the most relevant features within each data modality. By incorporating the proposed feature-level attention, we develop a novel Intra-modal multi-head attention (MHA), Inter-modal MHA and Modality-target MHA in a way that both feature and temporal attentions are incorporated in MHAs. This enables the MHAs to generate temporal attentions with consideration of modality and feature importance which leads to more informative embeddings. The proposed modality-aware structure enables the model to effectively exploit information within each modality as well as foster cross-modal understanding. Our extensive experiments on financial datasets demonstrate that Modality-aware Transformer outperforms existing methods, offering a novel and practical solution to the complex challenges of multi-modality time series forecasting.
SimVLG: Simple and Efficient Pretraining of Visual Language Generative Models
Oct 07, 2023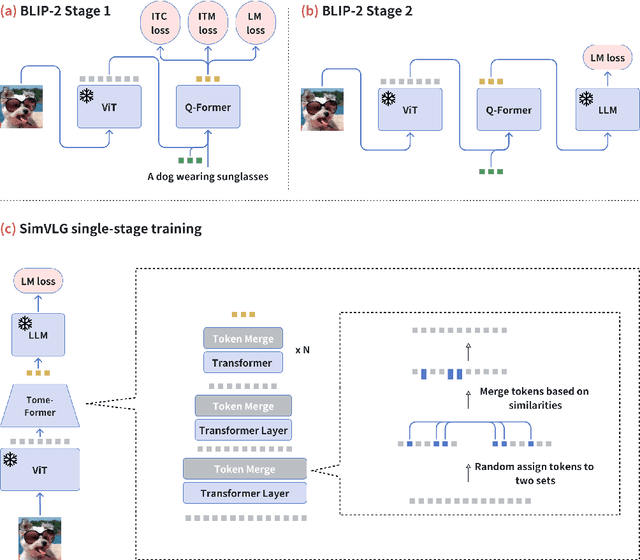
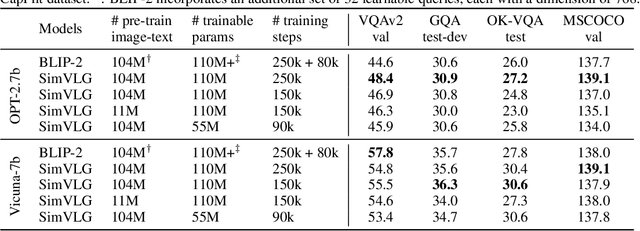
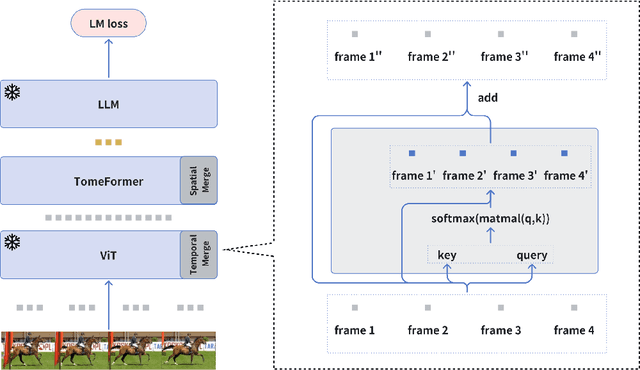

In this paper, we propose ``SimVLG'', a streamlined framework for the pre-training of computationally intensive vision-language generative models, leveraging frozen pre-trained large language models (LLMs). The prevailing paradigm in vision-language pre-training (VLP) typically involves a two-stage optimization process: an initial resource-intensive phase dedicated to general-purpose vision-language representation learning, aimed at extracting and consolidating pertinent visual features, followed by a subsequent phase focusing on end-to-end alignment between visual and linguistic modalities. Our one-stage, single-loss framework circumvents the aforementioned computationally demanding first stage of training by gradually merging similar visual tokens during training. This gradual merging process effectively compacts the visual information while preserving the richness of semantic content, leading to fast convergence without sacrificing performance. Our experiments show that our approach can speed up the training of vision-language models by a factor $\times 5$ without noticeable impact on the overall performance. Additionally, we show that our models can achieve comparable performance to current vision-language models with only $1/10$ of the data. Finally, we demonstrate how our image-text models can be easily adapted to video-language generative tasks through a novel soft attentive temporal token merging modules.
EdgeFD: An Edge-Friendly Drift-Aware Fault Diagnosis System for Industrial IoT
Oct 07, 2023Recent transfer learning (TL) approaches in industrial intelligent fault diagnosis (FD) mostly follow the "pre-train and fine-tuning" paradigm to address data drift, which emerges from variable working conditions. However, we find that this approach is prone to the phenomenon known as catastrophic forgetting. Furthermore, performing frequent models fine-tuning on the resource-constrained edge nodes can be computationally expensive and unnecessary, given the excellent transferability demonstrated by existing models. In this work, we propose the Drift-Aware Weight Consolidation (DAWC), a method optimized for edge deployments, mitigating the challenges posed by frequent data drift in the industrial Internet of Things (IIoT). DAWC efficiently manages multiple data drift scenarios, minimizing the need for constant model fine-tuning on edge devices, thereby conserving computational resources. By detecting drift using classifier confidence and estimating parameter importance with the Fisher Information Matrix, a tool that measures parameter sensitivity in probabilistic models, we introduce a drift detection module and a continual learning module to gradually equip the FD model with powerful generalization capabilities. Experimental results demonstrate that our proposed DAWC achieves superior performance compared to existing techniques while also ensuring compatibility with edge computing constraints. Additionally, we have developed a comprehensive diagnosis and visualization platform.
SeeDS: Semantic Separable Diffusion Synthesizer for Zero-shot Food Detection
Oct 07, 2023
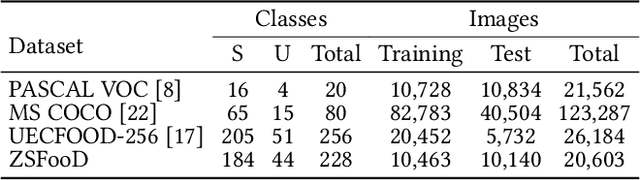
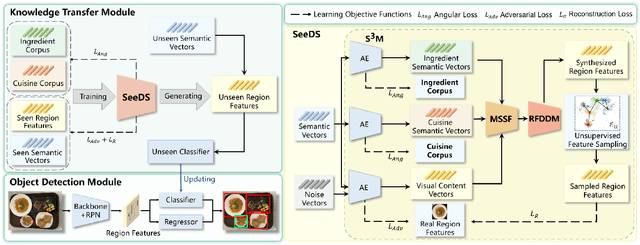
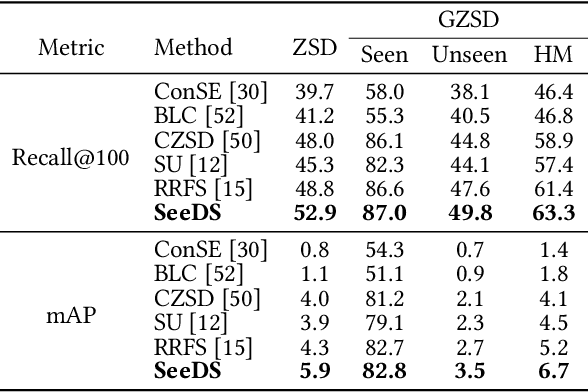
Food detection is becoming a fundamental task in food computing that supports various multimedia applications, including food recommendation and dietary monitoring. To deal with real-world scenarios, food detection needs to localize and recognize novel food objects that are not seen during training, demanding Zero-Shot Detection (ZSD). However, the complexity of semantic attributes and intra-class feature diversity poses challenges for ZSD methods in distinguishing fine-grained food classes. To tackle this, we propose the Semantic Separable Diffusion Synthesizer (SeeDS) framework for Zero-Shot Food Detection (ZSFD). SeeDS consists of two modules: a Semantic Separable Synthesizing Module (S$^3$M) and a Region Feature Denoising Diffusion Model (RFDDM). The S$^3$M learns the disentangled semantic representation for complex food attributes from ingredients and cuisines, and synthesizes discriminative food features via enhanced semantic information. The RFDDM utilizes a novel diffusion model to generate diversified region features and enhances ZSFD via fine-grained synthesized features. Extensive experiments show the state-of-the-art ZSFD performance of our proposed method on two food datasets, ZSFooD and UECFOOD-256. Moreover, SeeDS also maintains effectiveness on general ZSD datasets, PASCAL VOC and MS COCO. The code and dataset can be found at https://github.com/LanceZPF/SeeDS.
Information Retrieval Meets Large Language Models: A Strategic Report from Chinese IR Community
Jul 27, 2023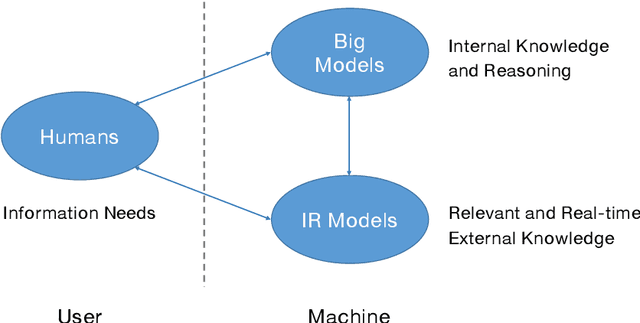
The research field of Information Retrieval (IR) has evolved significantly, expanding beyond traditional search to meet diverse user information needs. Recently, Large Language Models (LLMs) have demonstrated exceptional capabilities in text understanding, generation, and knowledge inference, opening up exciting avenues for IR research. LLMs not only facilitate generative retrieval but also offer improved solutions for user understanding, model evaluation, and user-system interactions. More importantly, the synergistic relationship among IR models, LLMs, and humans forms a new technical paradigm that is more powerful for information seeking. IR models provide real-time and relevant information, LLMs contribute internal knowledge, and humans play a central role of demanders and evaluators to the reliability of information services. Nevertheless, significant challenges exist, including computational costs, credibility concerns, domain-specific limitations, and ethical considerations. To thoroughly discuss the transformative impact of LLMs on IR research, the Chinese IR community conducted a strategic workshop in April 2023, yielding valuable insights. This paper provides a summary of the workshop's outcomes, including the rethinking of IR's core values, the mutual enhancement of LLMs and IR, the proposal of a novel IR technical paradigm, and open challenges.
Pursuing Counterfactual Fairness via Sequential Autoencoder Across Domains
Sep 22, 2023
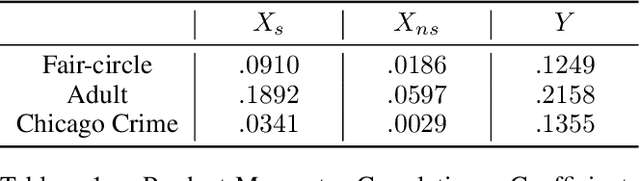
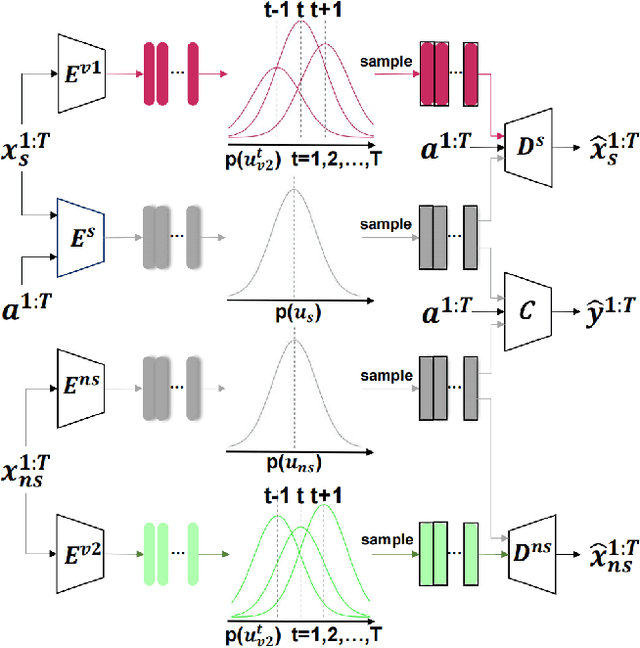
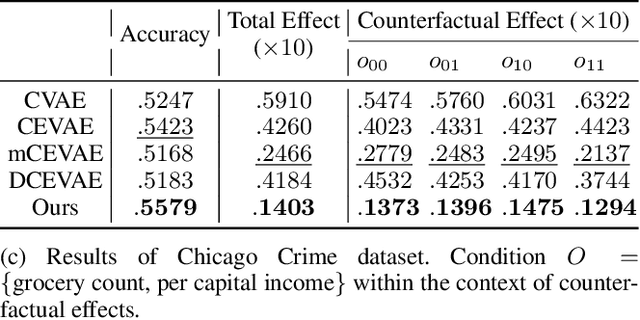
Recognizing the prevalence of domain shift as a common challenge in machine learning, various domain generalization (DG) techniques have been developed to enhance the performance of machine learning systems when dealing with out-of-distribution (OOD) data. Furthermore, in real-world scenarios, data distributions can gradually change across a sequence of sequential domains. While current methodologies primarily focus on improving model effectiveness within these new domains, they often overlook fairness issues throughout the learning process. In response, we introduce an innovative framework called Counterfactual Fairness-Aware Domain Generalization with Sequential Autoencoder (CDSAE). This approach effectively separates environmental information and sensitive attributes from the embedded representation of classification features. This concurrent separation not only greatly improves model generalization across diverse and unfamiliar domains but also effectively addresses challenges related to unfair classification. Our strategy is rooted in the principles of causal inference to tackle these dual issues. To examine the intricate relationship between semantic information, sensitive attributes, and environmental cues, we systematically categorize exogenous uncertainty factors into four latent variables: 1) semantic information influenced by sensitive attributes, 2) semantic information unaffected by sensitive attributes, 3) environmental cues influenced by sensitive attributes, and 4) environmental cues unaffected by sensitive attributes. By incorporating fairness regularization, we exclusively employ semantic information for classification purposes. Empirical validation on synthetic and real-world datasets substantiates the effectiveness of our approach, demonstrating improved accuracy levels while ensuring the preservation of fairness in the evolving landscape of continuous domains.
An Exploration of Optimal Parameters for Efficient Blind Source Separation of EEG Recordings Using AMICA
Sep 27, 2023EEG continues to find a multitude of uses in both neuroscience research and medical practice, and independent component analysis (ICA) continues to be an important tool for analyzing EEG. A multitude of ICA algorithms for EEG decomposition exist, and in the past, their relative effectiveness has been studied. AMICA is considered the benchmark against which to compare the performance of other ICA algorithms for EEG decomposition. AMICA exposes many parameters to the user to allow for precise control of the decomposition. However, several of the parameters currently tend to be set according to "rules of thumb" shared in the EEG community. Here, AMICA decompositions are run on data from a collection of subjects while varying certain key parameters. The running time and quality of decompositions are analyzed based on two metrics: Pairwise Mutual Information (PMI) and Mutual Information Reduction (MIR). Recommendations for selecting starting values for parameters are presented.
Impact of architecture on robustness and interpretability of multispectral deep neural networks
Sep 27, 2023Including information from additional spectral bands (e.g., near-infrared) can improve deep learning model performance for many vision-oriented tasks. There are many possible ways to incorporate this additional information into a deep learning model, but the optimal fusion strategy has not yet been determined and can vary between applications. At one extreme, known as "early fusion," additional bands are stacked as extra channels to obtain an input image with more than three channels. At the other extreme, known as "late fusion," RGB and non-RGB bands are passed through separate branches of a deep learning model and merged immediately before a final classification or segmentation layer. In this work, we characterize the performance of a suite of multispectral deep learning models with different fusion approaches, quantify their relative reliance on different input bands and evaluate their robustness to naturalistic image corruptions affecting one or more input channels.