 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LLM Based Multi-Document Summarization Exploiting Main-Event Biased Monotone Submodular Content Extraction
Oct 05, 2023
Multi-document summarization is a challenging task due to its inherent subjective bias, highlighted by the low inter-annotator ROUGE-1 score of 0.4 among DUC-2004 reference summaries. In this work, we aim to enhance the objectivity of news summarization by focusing on the main event of a group of related news documents and presenting it coherently with sufficient context. Our primary objective is to succinctly report the main event, ensuring that the summary remains objective and informative. To achieve this, we employ an extract-rewrite approach that incorporates a main-event biased monotone-submodular function for content selection. This enables us to extract the most crucial information related to the main event from the document cluster. To ensure coherence, we utilize a fine-tuned Language Model (LLM) for rewriting the extracted content into a coherent text. The evaluation using objective metrics and human evaluators confirms the effectiveness of our approach, as it surpasses potential baselines, demonstrating excellence in both content coverage, coherence, and informativeness.
HandMeThat: Human-Robot Communication in Physical and Social Environments
Oct 05, 2023
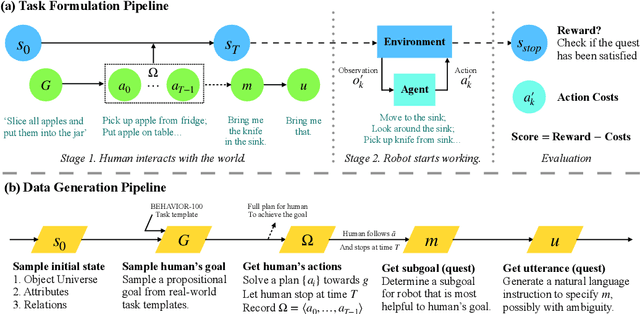
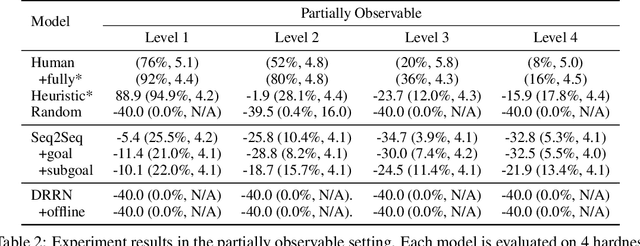
We introduce HandMeThat, a benchmark for a holistic evaluation of instruction understanding and following in physical and social environments. While previous datasets primarily focused on language grounding and planning, HandMeThat considers the resolution of human instructions with ambiguities based on the physical (object states and relations) and social (human actions and goals) information. HandMeThat contains 10,000 episodes of human-robot interactions. In each episode, the robot first observes a trajectory of human actions towards her internal goal. Next, the robot receives a human instruction and should take actions to accomplish the subgoal set through the instruction. In this paper, we present a textual interface for our benchmark, where the robot interacts with a virtual environment through textual commands. We evaluate several baseline models on HandMeThat, and show that both offline and online reinforcement learning algorithms perform poorly on HandMeThat, suggesting significant room for future work on physical and social human-robot communications and interactions.
Challenges and Insights: Exploring 3D Spatial Features and Complex Networks on the MISP Dataset
Oct 05, 2023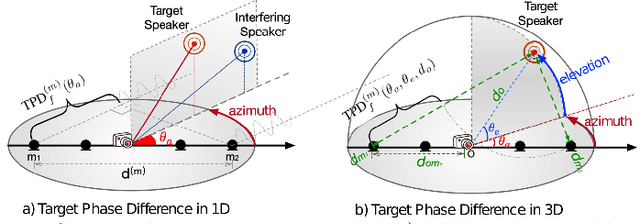


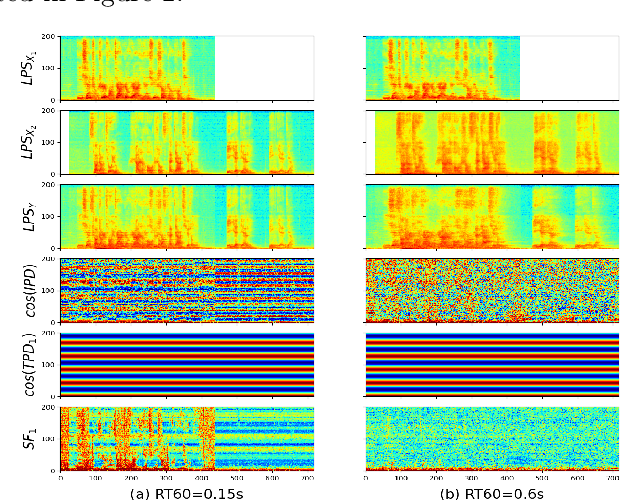
Multi-channel multi-talker speech recognition presents formidable challenges in the realm of speech processing, marked by issues such as background noise, reverberation, and overlapping speech. Overcoming these complexities requires leveraging contextual cues to separate target speech from a cacophonous mix, enabling accurate recognition. Among these cues, the 3D spatial feature has emerged as a cutting-edge solution, particularly when equipped with spatial information about the target speaker. Its exceptional ability to discern the target speaker within mixed audio, often rendering intermediate processing redundant, paves the way for the direct training of "All-in-one" ASR models. These models have demonstrated commendable performance on both simulated and real-world data. In this paper, we extend this approach to the MISP dataset to further validate its efficacy. We delve into the challenges encountered and insights gained when applying 3D spatial features to MISP, while also exploring preliminary experiments involving the replacement of these features with more complex input and models.
Superimposed RIS-phase Modulation for MIMO Communications: A Novel Paradigm of Information Transfer
Aug 10, 2023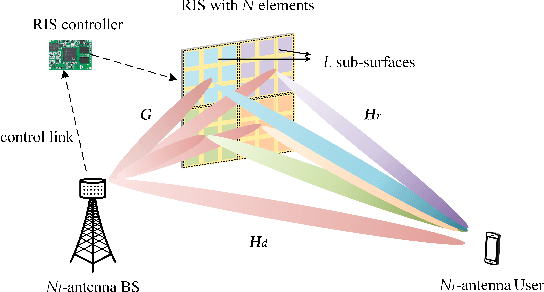
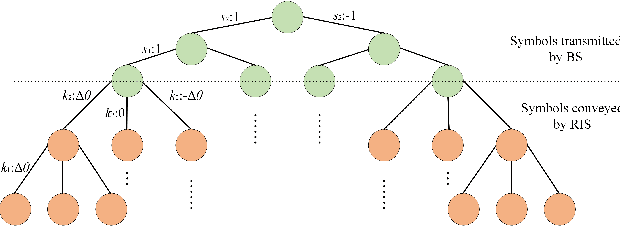
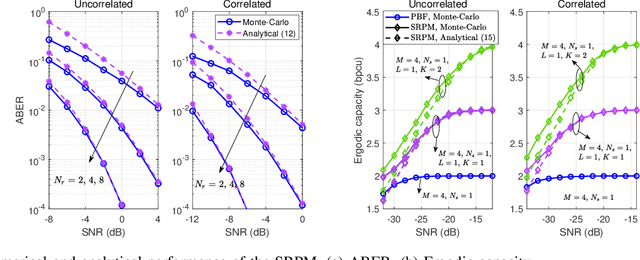
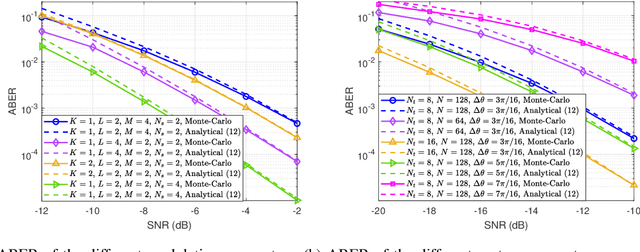
Reconfigurable intelligent surface (RIS) is regarded as an important enabling technology for the sixth-generation (6G) network. Recently, modulating information in reflection patterns of RIS, referred to as reflection modulation (RM), has been proven in theory to have the potential of achieving higher transmission rate than existing passive beamforming (PBF) schemes of RIS. To fully unlock this potential of RM, we propose a novel superimposed RIS-phase modulation (SRPM) scheme for multiple-input multiple-output (MIMO) systems, where tunable phase offsets are superimposed onto predetermined RIS phases to bear extra information messages. The proposed SRPM establishes a universal framework for RM, which retrieves various existing RM-based schemes as special cases. Moreover, the advantages and applicability of the SRPM in practice is also validated in theory by analytical characterization of its performance in terms of average bit error rate (ABER) and ergodic capacity. To maximize the performance gain, we formulate a general precoding optimization at the base station (BS) for a single-stream case with uncorrelated channels and obtain the optimal SRPM design via the semidefinite relaxation (SDR) technique. Furthermore, to avoid extremely high complexity in maximum likelihood (ML) detection for the SRPM, we propose a sphere decoding (SD)-based layered detection method with near-ML performance and much lower complexity. Numerical results demonstrate the effectiveness of SRPM, precoding optimization, and detection design. It is verified that the proposed SRPM achieves a higher diversity order than that of existing RM-based schemes and outperforms PBF significantly especially when the transmitter is equipped with limited radio-frequency (RF) chains.
Information Retrieval Meets Large Language Models: A Strategic Report from Chinese IR Community
Jul 27, 2023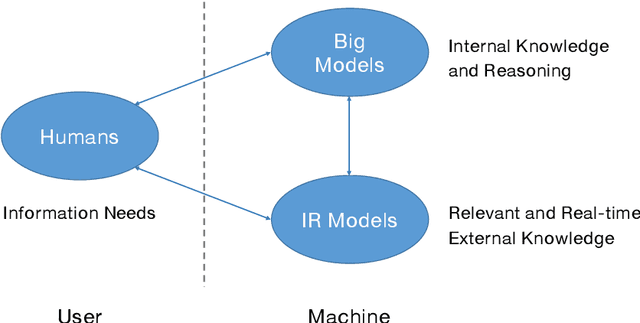
The research field of Information Retrieval (IR) has evolved significantly, expanding beyond traditional search to meet diverse user information needs. Recently, Large Language Models (LLMs) have demonstrated exceptional capabilities in text understanding, generation, and knowledge inference, opening up exciting avenues for IR research. LLMs not only facilitate generative retrieval but also offer improved solutions for user understanding, model evaluation, and user-system interactions. More importantly, the synergistic relationship among IR models, LLMs, and humans forms a new technical paradigm that is more powerful for information seeking. IR models provide real-time and relevant information, LLMs contribute internal knowledge, and humans play a central role of demanders and evaluators to the reliability of information services. Nevertheless, significant challenges exist, including computational costs, credibility concerns, domain-specific limitations, and ethical considerations. To thoroughly discuss the transformative impact of LLMs on IR research, the Chinese IR community conducted a strategic workshop in April 2023, yielding valuable insights. This paper provides a summary of the workshop's outcomes, including the rethinking of IR's core values, the mutual enhancement of LLMs and IR, the proposal of a novel IR technical paradigm, and open challenges.
On the Energy Efficiency of THz-NOMA enhanced UAV Cooperative Network with SWIPT
Sep 25, 2023This paper considers the energy efficiency (EE) maximization of a simultaneous wireless information and power transfer (SWIPT)-assisted unmanned aerial vehicles (UAV) cooperative network operating at TeraHertz (THz) frequencies. The source performs SWIPT enabling the UAV to receive both power and information while also transmitting the information to a designated destination node. Subsequently, the UAV utilizes the harvested energy to relay the data to the intended destination node effectively. Specifically, we maximize EE by optimizing the non-orthogonal multiple access (NOMA) power allocation coefficients, SWIPT power splitting (PS) ratio, and UAV trajectory. The main problem is broken down into a two-stage optimization problem and solved using an alternating optimization approach. In the first stage, optimization of the PS ratio and trajectory is performed by employing successive convex approximation using a lower bound on the exponential factor in the THz channel model. In the second phase, the NOMA power coefficients are optimized using a quadratic transform approach. Numerical results demonstrate the effectiveness of our proposed resource allocation algorithm compared to the baselines where there is no trajectory optimization or no NOMA power or PS optimization.
TBD Pedestrian Data Collection: Towards Rich, Portable, and Large-Scale Natural Pedestrian Data
Sep 29, 2023
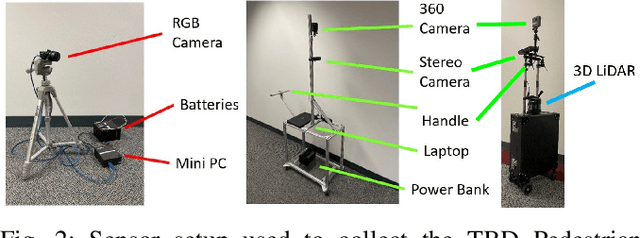


Social navigation and pedestrian behavior research has shifted towards machine learning-based methods and converged on the topic of modeling inter-pedestrian interactions and pedestrian-robot interactions. For this, large-scale datasets that contain rich information are needed. We describe a portable data collection system, coupled with a semi-autonomous labeling pipeline. As part of the pipeline, we designed a label correction web app that facilitates human verification of automated pedestrian tracking outcomes. Our system enables large-scale data collection in diverse environments and fast trajectory label production. Compared with existing pedestrian data collection methods, our system contains three components: a combination of top-down and ego-centric views, natural human behavior in the presence of a socially appropriate "robot", and human-verified labels grounded in the metric space. To the best of our knowledge, no prior data collection system has a combination of all three components. We further introduce our ever-expanding dataset from the ongoing data collection effort -- the TBD Pedestrian Dataset and show that our collected data is larger in scale, contains richer information when compared to prior datasets with human-verified labels, and supports new research opportunities.
Causality-informed Rapid Post-hurricane Building Damage Detection in Large Scale from InSAR Imagery
Oct 02, 2023Timely and accurate assessment of hurricane-induced building damage is crucial for effective post-hurricane response and recovery efforts. Recently, remote sensing technologies provide large-scale optical or Interferometric Synthetic Aperture Radar (InSAR) imagery data immediately after a disastrous event, which can be readily used to conduct rapid building damage assessment. Compared to optical satellite imageries, the Synthetic Aperture Radar can penetrate cloud cover and provide more complete spatial coverage of damaged zones in various weather conditions. However, these InSAR imageries often contain highly noisy and mixed signals induced by co-occurring or co-located building damage, flood, flood/wind-induced vegetation changes, as well as anthropogenic activities, making it challenging to extract accurate building damage information. In this paper, we introduced an approach for rapid post-hurricane building damage detection from InSAR imagery. This approach encoded complex causal dependencies among wind, flood, building damage, and InSAR imagery using a holistic causal Bayesian network. Based on the causal Bayesian network, we further jointly inferred the large-scale unobserved building damage by fusing the information from InSAR imagery with prior physical models of flood and wind, without the need for ground truth labels. Furthermore, we validated our estimation results in a real-world devastating hurricane -- the 2022 Hurricane Ian. We gathered and annotated building damage ground truth data in Lee County, Florida, and compared the introduced method's estimation results with the ground truth and benchmarked it against state-of-the-art models to assess the effectiveness of our proposed method. Results show that our method achieves rapid and accurate detection of building damage, with significantly reduced processing time compared to traditional manual inspection methods.
Modality-aware Transformer for Time series Forecasting
Oct 02, 2023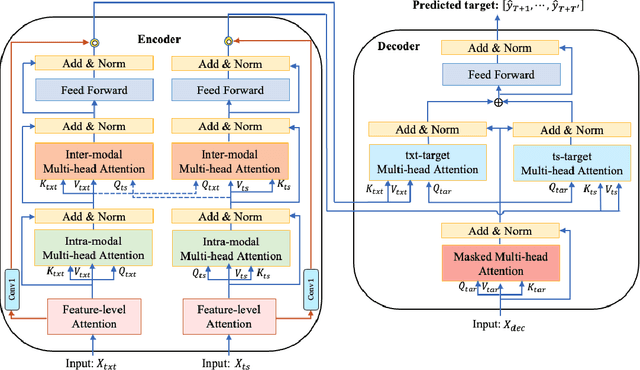

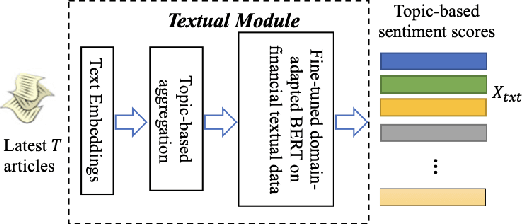
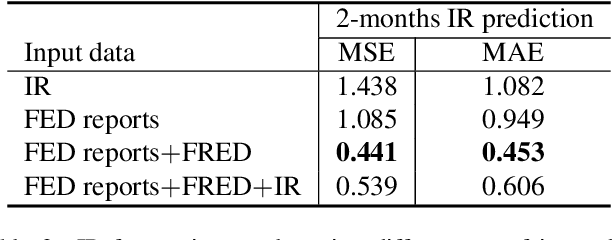
Time series forecasting presents a significant challenge, particularly when its accuracy relies on external data sources rather than solely on historical values. This issue is prevalent in the financial sector, where the future behavior of time series is often intricately linked to information derived from various textual reports and a multitude of economic indicators. In practice, the key challenge lies in constructing a reliable time series forecasting model capable of harnessing data from diverse sources and extracting valuable insights to predict the target time series accurately. In this work, we tackle this challenging problem and introduce a novel multimodal transformer-based model named the Modality-aware Transformer. Our model excels in exploring the power of both categorical text and numerical timeseries to forecast the target time series effectively while providing insights through its neural attention mechanism. To achieve this, we develop feature-level attention layers that encourage the model to focus on the most relevant features within each data modality. By incorporating the proposed feature-level attention, we develop a novel Intra-modal multi-head attention (MHA), Inter-modal MHA and Modality-target MHA in a way that both feature and temporal attentions are incorporated in MHAs. This enables the MHAs to generate temporal attentions with consideration of modality and feature importance which leads to more informative embeddings. The proposed modality-aware structure enables the model to effectively exploit information within each modality as well as foster cross-modal understanding. Our extensive experiments on financial datasets demonstrate that Modality-aware Transformer outperforms existing methods, offering a novel and practical solution to the complex challenges of multi-modality time series forecasting.
Multi-resolution HuBERT: Multi-resolution Speech Self-Supervised Learning with Masked Unit Prediction
Oct 04, 2023Existing Self-Supervised Learning (SSL) models for speech typically process speech signals at a fixed resolution of 20 milliseconds. This approach overlooks the varying informational content present at different resolutions in speech signals. In contrast, this paper aims to incorporate multi-resolution information into speech self-supervised representation learning. We introduce a SSL model that leverages a hierarchical Transformer architecture, complemented by HuBERT-style masked prediction objectives, to process speech at multiple resolutions. Experimental results indicate that the proposed model not only achieves more efficient inference but also exhibits superior or comparable performance to the original HuBERT model over various tasks. Specifically, significant performance improvements over the original HuBERT have been observed in fine-tuning experiments on the LibriSpeech speech recognition benchmark as well as in evaluations using the Speech Universal PERformance Benchmark (SUPERB) and Multilingual SUPERB (ML-SUPERB).