 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Compositional Semantics for Open Vocabulary Spatio-semantic Representations
Oct 08, 2023
General-purpose mobile robots need to complete tasks without exact human instructions. Large language models (LLMs) is a promising direction for realizing commonsense world knowledge and reasoning-based planning. Vision-language models (VLMs) transform environment percepts into vision-language semantics interpretable by LLMs. However, completing complex tasks often requires reasoning about information beyond what is currently perceived. We propose latent compositional semantic embeddings z* as a principled learning-based knowledge representation for queryable spatio-semantic memories. We mathematically prove that z* can always be found, and the optimal z* is the centroid for any set Z. We derive a probabilistic bound for estimating separability of related and unrelated semantics. We prove that z* is discoverable by iterative optimization by gradient descent from visual appearance and singular descriptions. We experimentally verify our findings on four embedding spaces incl. CLIP and SBERT. Our results show that z* can represent up to 10 semantics encoded by SBERT, and up to 100 semantics for ideal uniformly distributed high-dimensional embeddings. We demonstrate that a simple dense VLM trained on the COCO-Stuff dataset can learn z* for 181 overlapping semantics by 42.23 mIoU, while improving conventional non-overlapping open-vocabulary segmentation performance by +3.48 mIoU compared with a popular SOTA model.
Transferable Availability Poisoning Attacks
Oct 08, 2023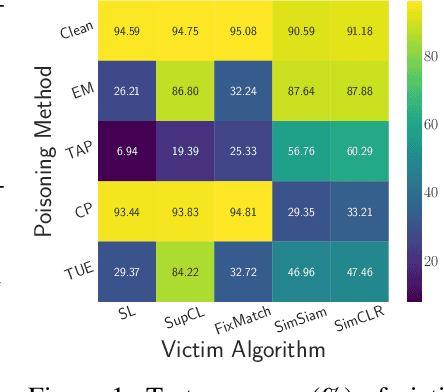
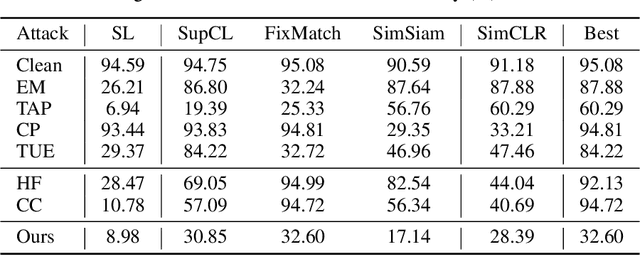
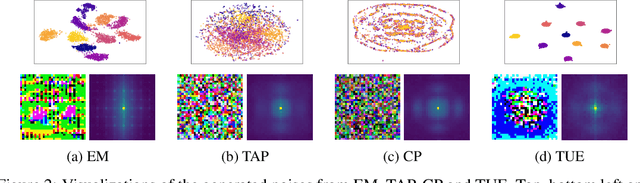
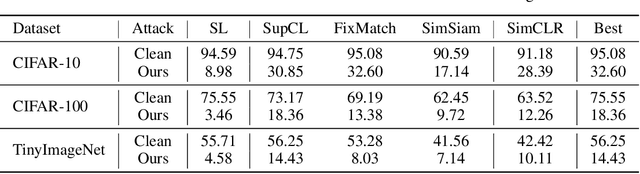
We consider availability data poisoning attacks, where an adversary aims to degrade the overall test accuracy of a machine learning model by crafting small perturbations to its training data. Existing poisoning strategies can achieve the attack goal but assume the victim to employ the same learning method as what the adversary uses to mount the attack. In this paper, we argue that this assumption is strong, since the victim may choose any learning algorithm to train the model as long as it can achieve some targeted performance on clean data. Empirically, we observe a large decrease in the effectiveness of prior poisoning attacks if the victim uses a different learning paradigm to train the model and show marked differences in frequency-level characteristics between perturbations generated with respect to different learners and attack methods. To enhance the attack transferability, we propose Transferable Poisoning, which generates high-frequency poisoning perturbations by alternately leveraging the gradient information with two specific algorithms selected from supervised and unsupervised contrastive learning paradigms. Through extensive experiments on benchmark image datasets, we show that our transferable poisoning attack can produce poisoned samples with significantly improved transferability, not only applicable to the two learners used to devise the attack but also for learning algorithms and even paradigms beyond.
Performance Analysis of RIS-Aided Double Spatial Scattering Modulation for mmWave MIMO Systems
Oct 08, 2023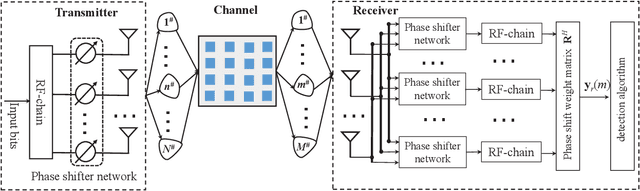
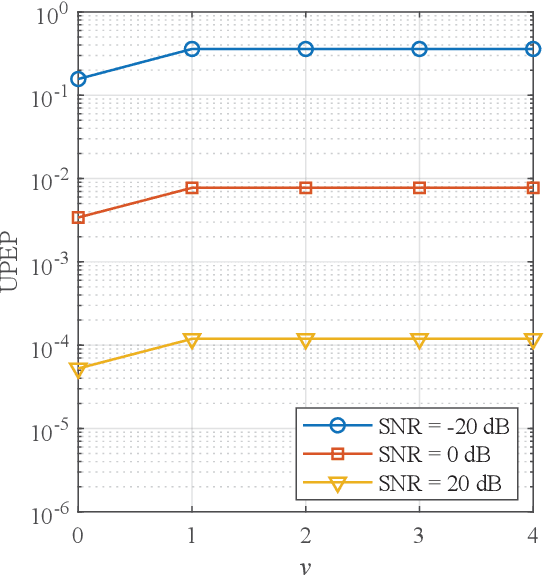
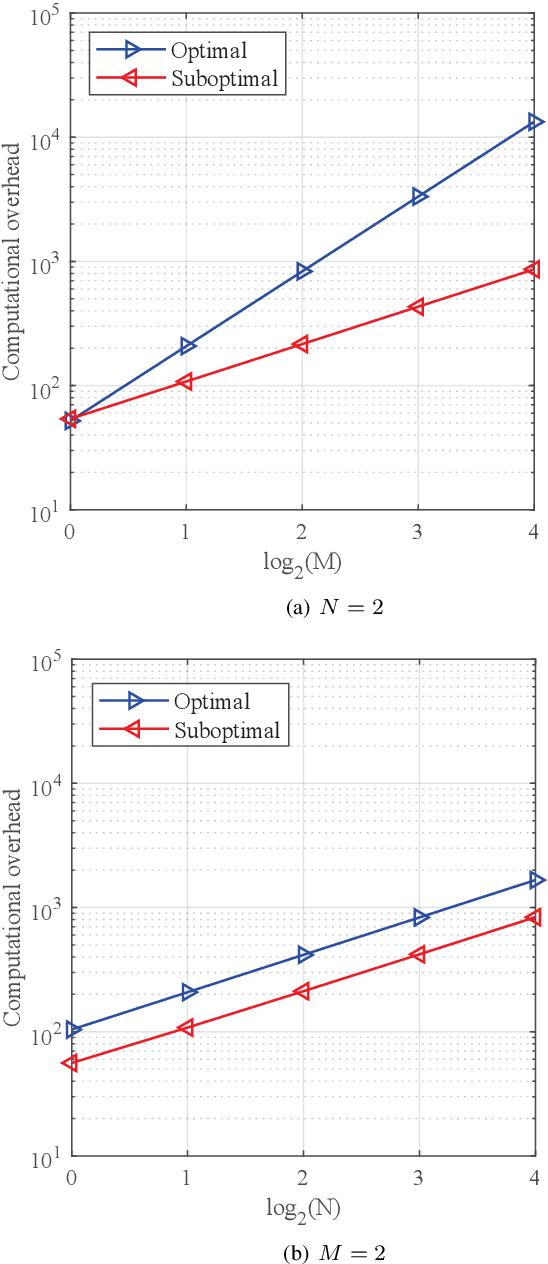
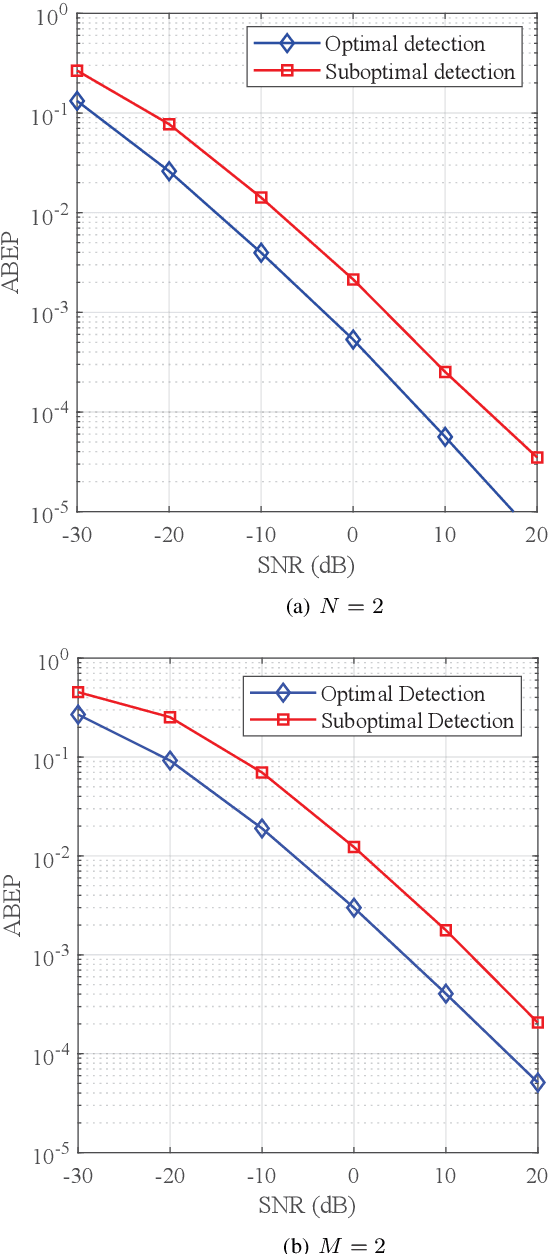
In this paper, we investigate a practical structure of reconfigurable intelligent surface (RIS)-based double spatial scattering modulation (DSSM) for millimeter-wave (mmWave) multiple-input multiple-output (MIMO) systems. A suboptimal detector is proposed, in which the beam direction is first demodulated according to the received beam strength, and then the remaining information is demodulated by adopting the maximum likelihood algorithm. Based on the proposed suboptimal detector, we derive the conditional pairwise error probability expression. Further, the exact numerical integral and closed-form expressions of unconditional pairwise error probability (UPEP) are derived via two different approaches. To provide more insights, we derive the upper bound and asymptotic expressions of UPEP. In addition, the diversity gain of the RIS-DSSM scheme was also given. Furthermore, the union upper bound of average bit error probability (ABEP) is obtained by combining the UPEP and the number of error bits. Simulation results are provided to validate the derived upper bound and asymptotic expressions of ABEP. We found an interesting phenomenon that the ABEP performance of the proposed system-based phase shift keying is better than that of the quadrature amplitude modulation. Additionally, the performance advantage of ABEP is more significant with the increase in the number of RIS elements.
A Corrected Expected Improvement Acquisition Function Under Noisy Observations
Oct 08, 2023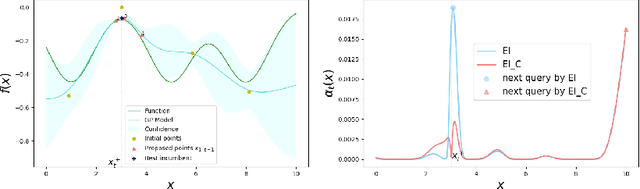
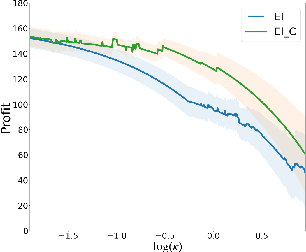
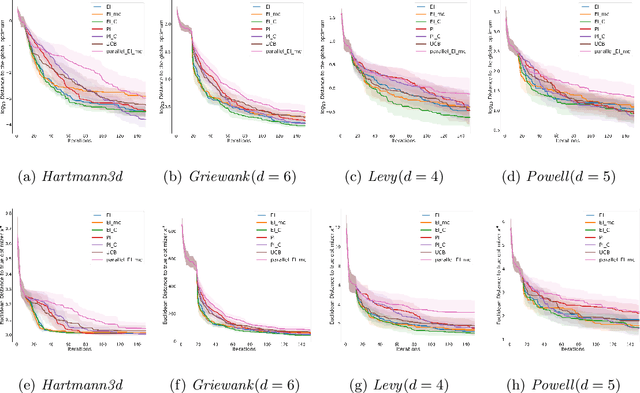
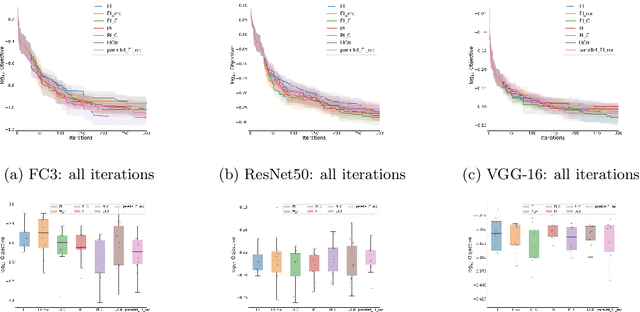
Sequential maximization of expected improvement (EI) is one of the most widely used policies in Bayesian optimization because of its simplicity and ability to handle noisy observations. In particular, the improvement function often uses the best posterior mean as the best incumbent in noisy settings. However, the uncertainty associated with the incumbent solution is often neglected in many analytic EI-type methods: a closed-form acquisition function is derived in the noise-free setting, but then applied to the setting with noisy observations. To address this limitation, we propose a modification of EI that corrects its closed-form expression by incorporating the covariance information provided by the Gaussian Process (GP) model. This acquisition function specializes to the classical noise-free result, and we argue should replace that formula in Bayesian optimization software packages, tutorials, and textbooks. This enhanced acquisition provides good generality for noisy and noiseless settings. We show that our method achieves a sublinear convergence rate on the cumulative regret bound under heteroscedastic observation noise. Our empirical results demonstrate that our proposed acquisition function can outperform EI in the presence of noisy observations on benchmark functions for black-box optimization, as well as on parameter search for neural network model compression.
ResolvNet: A Graph Convolutional Network with multi-scale Consistency
Sep 30, 2023It is by now a well known fact in the graph learning community that the presence of bottlenecks severely limits the ability of graph neural networks to propagate information over long distances. What so far has not been appreciated is that, counter-intuitively, also the presence of strongly connected sub-graphs may severely restrict information flow in common architectures. Motivated by this observation, we introduce the concept of multi-scale consistency. At the node level this concept refers to the retention of a connected propagation graph even if connectivity varies over a given graph. At the graph-level, multi-scale consistency refers to the fact that distinct graphs describing the same object at different resolutions should be assigned similar feature vectors. As we show, both properties are not satisfied by poular graph neural network architectures. To remedy these shortcomings, we introduce ResolvNet, a flexible graph neural network based on the mathematical concept of resolvents. We rigorously establish its multi-scale consistency theoretically and verify it in extensive experiments on real world data: Here networks based on this ResolvNet architecture prove expressive; out-performing baselines significantly on many tasks; in- and outside the multi-scale setting.
Multi-Resolution Audio-Visual Feature Fusion for Temporal Action Localization
Oct 05, 2023Temporal Action Localization (TAL) aims to identify actions' start, end, and class labels in untrimmed videos. While recent advancements using transformer networks and Feature Pyramid Networks (FPN) have enhanced visual feature recognition in TAL tasks, less progress has been made in the integration of audio features into such frameworks. This paper introduces the Multi-Resolution Audio-Visual Feature Fusion (MRAV-FF), an innovative method to merge audio-visual data across different temporal resolutions. Central to our approach is a hierarchical gated cross-attention mechanism, which discerningly weighs the importance of audio information at diverse temporal scales. Such a technique not only refines the precision of regression boundaries but also bolsters classification confidence. Importantly, MRAV-FF is versatile, making it compatible with existing FPN TAL architectures and offering a significant enhancement in performance when audio data is available.
DecoderLens: Layerwise Interpretation of Encoder-Decoder Transformers
Oct 05, 2023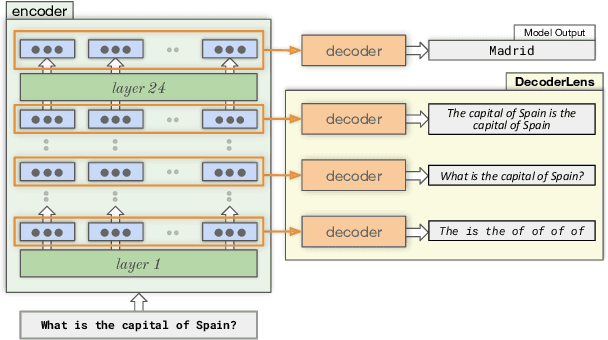
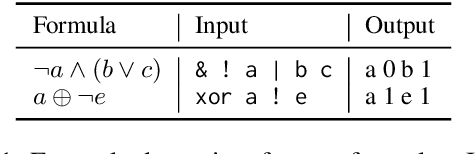
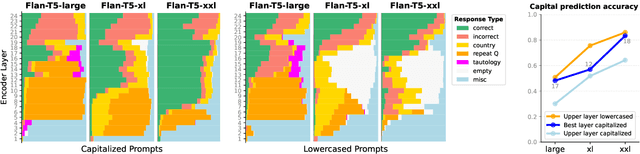

In recent years, many interpretability methods have been proposed to help interpret the internal states of Transformer-models, at different levels of precision and complexity. Here, to analyze encoder-decoder Transformers, we propose a simple, new method: DecoderLens. Inspired by the LogitLens (for decoder-only Transformers), this method involves allowing the decoder to cross-attend representations of intermediate encoder layers instead of using the final encoder output, as is normally done in encoder-decoder models. The method thus maps previously uninterpretable vector representations to human-interpretable sequences of words or symbols. We report results from the DecoderLens applied to models trained on question answering, logical reasoning, speech recognition and machine translation. The DecoderLens reveals several specific subtasks that are solved at low or intermediate layers, shedding new light on the information flow inside the encoder component of this important class of models.
Can Large Language Models Provide Security & Privacy Advice? Measuring the Ability of LLMs to Refute Misconceptions
Oct 03, 2023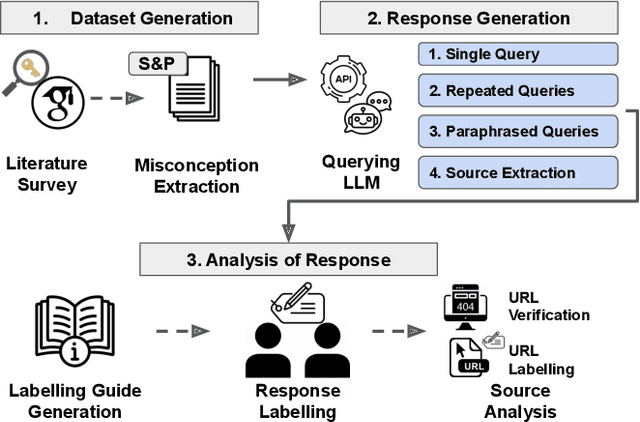


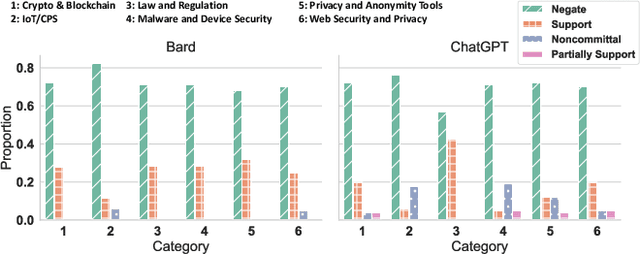
Users seek security & privacy (S&P) advice from online resources, including trusted websites and content-sharing platforms. These resources help users understand S&P technologies and tools and suggest actionable strategies. Large Language Models (LLMs) have recently emerged as trusted information sources. However, their accuracy and correctness have been called into question. Prior research has outlined the shortcomings of LLMs in answering multiple-choice questions and user ability to inadvertently circumvent model restrictions (e.g., to produce toxic content). Yet, the ability of LLMs to provide reliable S&P advice is not well-explored. In this paper, we measure their ability to refute popular S&P misconceptions that the general public holds. We first study recent academic literature to curate a dataset of over a hundred S&P-related misconceptions across six different topics. We then query two popular LLMs (Bard and ChatGPT) and develop a labeling guide to evaluate their responses to these misconceptions. To comprehensively evaluate their responses, we further apply three strategies: query each misconception multiple times, generate and query their paraphrases, and solicit source URLs of the responses. Both models demonstrate, on average, a 21.3% non-negligible error rate, incorrectly supporting popular S&P misconceptions. The error rate increases to 32.6% when we repeatedly query LLMs with the same or paraphrased misconceptions. We also expose that models may partially support a misconception or remain noncommittal, refusing a firm stance on misconceptions. Our exploration of information sources for responses revealed that LLMs are susceptible to providing invalid URLs (21.2% for Bard and 67.7% for ChatGPT) or point to unrelated sources (44.2% returned by Bard and 18.3% by ChatGPT).
Information Geometry of Wasserstein Statistics on Shapes and Affine Deformations
Jul 24, 2023
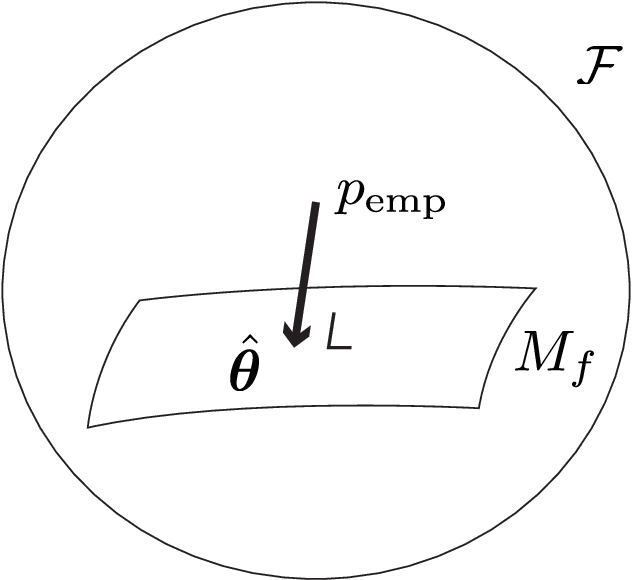
Information geometry and Wasserstein geometry are two main structures introduced in a manifold of probability distributions, and they capture its different characteristics. We study characteristics of Wasserstein geometry in the framework of Li and Zhao (2023) for the affine deformation statistical model, which is a multi-dimensional generalization of the location-scale model. We compare merits and demerits of estimators based on information geometry and Wasserstein geometry. The shape of a probability distribution and its affine deformation are separated in the Wasserstein geometry, showing its robustness against the waveform perturbation in exchange for the loss in Fisher efficiency. We show that the Wasserstein estimator is the moment estimator in the case of the elliptically symmetric affine deformation model. It coincides with the information-geometrical estimator (maximum-likelihood estimator) when and only when the waveform is Gaussian. The role of the Wasserstein efficiency is elucidated in terms of robustness against waveform change.
Semantic Map Learning of Traffic Light to Lane Assignment based on Motion Data
Sep 28, 2023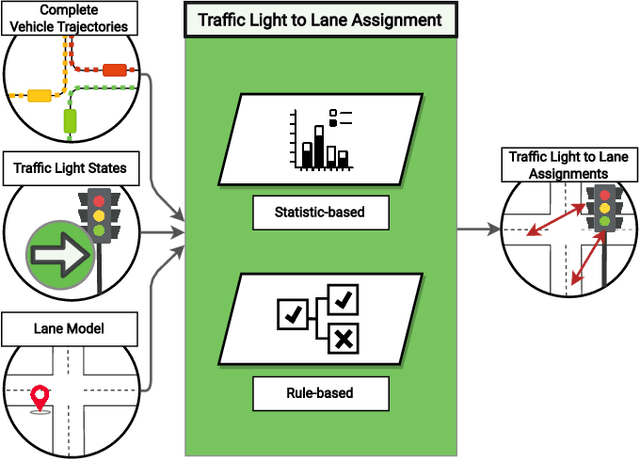
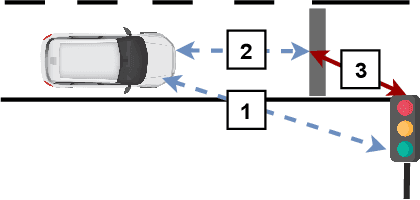
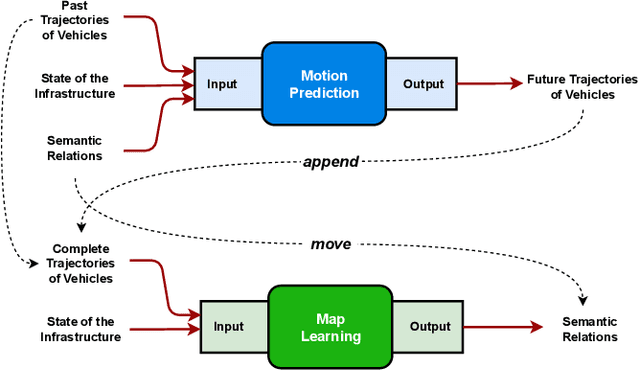
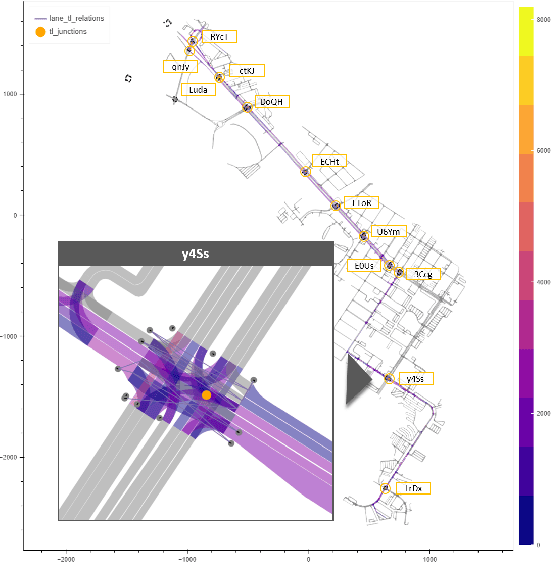
Understanding which traffic light controls which lane is crucial to navigate intersections safely. Autonomous vehicles commonly rely on High Definition (HD) maps that contain information about the assignment of traffic lights to lanes. The manual provisioning of this information is tedious, expensive, and not scalable. To remedy these issues, our novel approach derives the assignments from traffic light states and the corresponding motion patterns of vehicle traffic. This works in an automated way and independently of the geometric arrangement. We show the effectiveness of basic statistical approaches for this task by implementing and evaluating a pattern-based contribution method. In addition, our novel rejection method includes accompanying safety considerations by leveraging statistical hypothesis testing. Finally, we propose a dataset transformation to re-purpose available motion prediction datasets for semantic map learning. Our publicly available API for the Lyft Level 5 dataset enables researchers to develop and evaluate their own approaches.