 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
OCU-Net: A Novel U-Net Architecture for Enhanced Oral Cancer Segmentation
Oct 03, 2023
Accurate detection of oral cancer is crucial for improving patient outcomes. However, the field faces two key challenges: the scarcity of deep learning-based image segmentation research specifically targeting oral cancer and the lack of annotated data. Our study proposes OCU-Net, a pioneering U-Net image segmentation architecture exclusively designed to detect oral cancer in hematoxylin and eosin (H&E) stained image datasets. OCU-Net incorporates advanced deep learning modules, such as the Channel and Spatial Attention Fusion (CSAF) module, a novel and innovative feature that emphasizes important channel and spatial areas in H&E images while exploring contextual information. In addition, OCU-Net integrates other innovative components such as Squeeze-and-Excite (SE) attention module, Atrous Spatial Pyramid Pooling (ASPP) module, residual blocks, and multi-scale fusion. The incorporation of these modules showed superior performance for oral cancer segmentation for two datasets used in this research. Furthermore, we effectively utilized the efficient ImageNet pre-trained MobileNet-V2 model as a backbone of our OCU-Net to create OCU-Netm, an enhanced version achieving state-of-the-art results. Comprehensive evaluation demonstrates that OCU-Net and OCU-Netm outperformed existing segmentation methods, highlighting their precision in identifying cancer cells in H&E images from OCDC and ORCA datasets.
MUTEX: Learning Unified Policies from Multimodal Task Specifications
Sep 25, 2023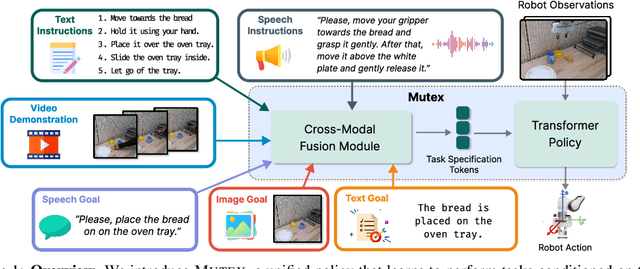
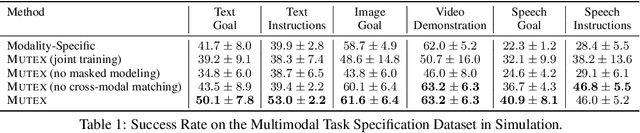
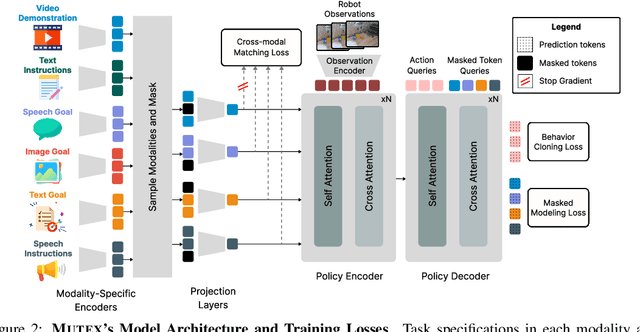
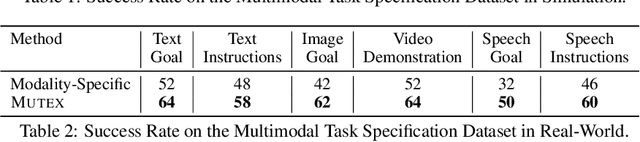
Humans use different modalities, such as speech, text, images, videos, etc., to communicate their intent and goals with teammates. For robots to become better assistants, we aim to endow them with the ability to follow instructions and understand tasks specified by their human partners. Most robotic policy learning methods have focused on one single modality of task specification while ignoring the rich cross-modal information. We present MUTEX, a unified approach to policy learning from multimodal task specifications. It trains a transformer-based architecture to facilitate cross-modal reasoning, combining masked modeling and cross-modal matching objectives in a two-stage training procedure. After training, MUTEX can follow a task specification in any of the six learned modalities (video demonstrations, goal images, text goal descriptions, text instructions, speech goal descriptions, and speech instructions) or a combination of them. We systematically evaluate the benefits of MUTEX in a newly designed dataset with 100 tasks in simulation and 50 tasks in the real world, annotated with multiple instances of task specifications in different modalities, and observe improved performance over methods trained specifically for any single modality. More information at https://ut-austin-rpl.github.io/MUTEX/
Learned Contextual LiDAR Informed Visual Search in Unseen Environments
Sep 25, 2023This paper presents LIVES: LiDAR Informed Visual Search, an autonomous planner for unknown environments. We consider the pixel-wise environment perception problem where one is given 2D range data from LiDAR scans and must label points contextually as map or non-map in the surroundings for visual planning. LIVES classifies incoming 2D scans from the wide Field of View (FoV) LiDAR in unseen environments without prior map information. The map-generalizable classifier is trained from expert data collected using a simple cart platform equipped with a map-based classifier in real environments. A visual planner takes contextual data from scans and uses this information to plan viewpoints more likely to yield detection of the search target. While conventional frontier based methods for LiDAR and multi sensor exploration effectively map environments, they are not tailored to search for people indoors, which we investigate in this paper. LIVES is baselined against several existing exploration methods in simulation to verify its performance. Finally, it is validated in real-world experiments with a Spot robot in a 20x30m indoor apartment setting. Videos of experimental validation can be found on our project website at https://sites.google.com/view/lives-icra-2024/home.
Newton Method-based Subspace Support Vector Data Description
Sep 25, 2023In this paper, we present an adaptation of Newton's method for the optimization of Subspace Support Vector Data Description (S-SVDD). The objective of S-SVDD is to map the original data to a subspace optimized for one-class classification, and the iterative optimization process of data mapping and description in S-SVDD relies on gradient descent. However, gradient descent only utilizes first-order information, which may lead to suboptimal results. To address this limitation, we leverage Newton's method to enhance data mapping and data description for an improved optimization of subspace learning-based one-class classification. By incorporating this auxiliary information, Newton's method offers a more efficient strategy for subspace learning in one-class classification as compared to gradient-based optimization. The paper discusses the limitations of gradient descent and the advantages of using Newton's method in subspace learning for one-class classification tasks. We provide both linear and nonlinear formulations of Newton's method-based optimization for S-SVDD. In our experiments, we explored both the minimization and maximization strategies of the objective. The results demonstrate that the proposed optimization strategy outperforms the gradient-based S-SVDD in most cases.
Information Theoretically Optimal Sample Complexity of Learning Dynamical Directed Acyclic Graphs
Aug 31, 2023In this article, the optimal sample complexity of learning the underlying interaction/dependencies of a Linear Dynamical System (LDS) over a Directed Acyclic Graph (DAG) is studied. The sample complexity of learning a DAG's structure is well-studied for static systems, where the samples of nodal states are independent and identically distributed (i.i.d.). However, such a study is less explored for DAGs with dynamical systems, where the nodal states are temporally correlated. We call such a DAG underlying an LDS as \emph{dynamical} DAG (DDAG). In particular, we consider a DDAG where the nodal dynamics are driven by unobserved exogenous noise sources that are wide-sense stationary (WSS) in time but are mutually uncorrelated, and have the same {power spectral density (PSD)}. Inspired by the static settings, a metric and an algorithm based on the PSD matrix of the observed time series are proposed to reconstruct the DDAG. The equal noise PSD assumption can be relaxed such that identifiability conditions for DDAG reconstruction are not violated. For the LDS with WSS (sub) Gaussian exogenous noise sources, it is shown that the optimal sample complexity (or length of state trajectory) needed to learn the DDAG is $n=\Theta(q\log(p/q))$, where $p$ is the number of nodes and $q$ is the maximum number of parents per node. To prove the sample complexity upper bound, a concentration bound for the PSD estimation is derived, under two different sampling strategies. A matching min-max lower bound using generalized Fano's inequality also is provided, thus showing the order optimality of the proposed algorithm.
SweetDreamer: Aligning Geometric Priors in 2D Diffusion for Consistent Text-to-3D
Oct 04, 2023

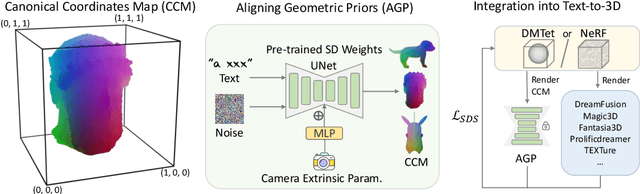
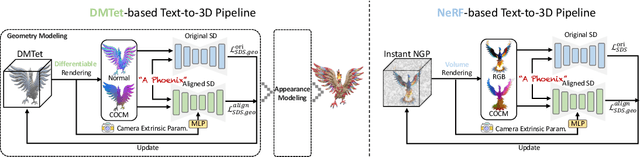
It is inherently ambiguous to lift 2D results from pre-trained diffusion models to a 3D world for text-to-3D generation. 2D diffusion models solely learn view-agnostic priors and thus lack 3D knowledge during the lifting, leading to the multi-view inconsistency problem. We find that this problem primarily stems from geometric inconsistency, and avoiding misplaced geometric structures substantially mitigates the problem in the final outputs. Therefore, we improve the consistency by aligning the 2D geometric priors in diffusion models with well-defined 3D shapes during the lifting, addressing the vast majority of the problem. This is achieved by fine-tuning the 2D diffusion model to be viewpoint-aware and to produce view-specific coordinate maps of canonically oriented 3D objects. In our process, only coarse 3D information is used for aligning. This "coarse" alignment not only resolves the multi-view inconsistency in geometries but also retains the ability in 2D diffusion models to generate detailed and diversified high-quality objects unseen in the 3D datasets. Furthermore, our aligned geometric priors (AGP) are generic and can be seamlessly integrated into various state-of-the-art pipelines, obtaining high generalizability in terms of unseen shapes and visual appearance while greatly alleviating the multi-view inconsistency problem. Our method represents a new state-of-the-art performance with an 85+% consistency rate by human evaluation, while many previous methods are around 30%. Our project page is https://sweetdreamer3d.github.io/
Knowledge Sanitization of Large Language Models
Sep 21, 2023
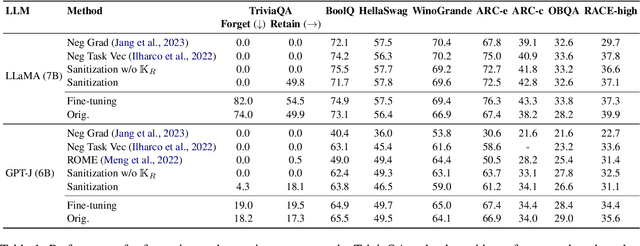
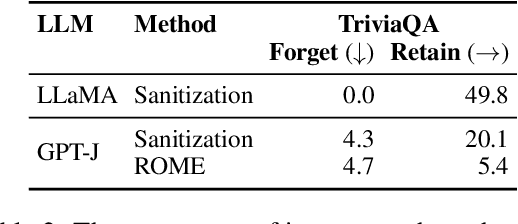

We explore a knowledge sanitization approach to mitigate the privacy concerns associated with large language models (LLMs). LLMs trained on a large corpus of Web data can memorize and potentially reveal sensitive or confidential information, raising critical security concerns. Our technique fine-tunes these models, prompting them to generate harmless responses such as ``I don't know'' when queried about specific information. Experimental results in a closed-book question-answering task show that our straightforward method not only minimizes particular knowledge leakage but also preserves the overall performance of LLM. These two advantages strengthen the defense against extraction attacks and reduces the emission of harmful content such as hallucinations.
Understanding Pose and Appearance Disentanglement in 3D Human Pose Estimation
Sep 20, 2023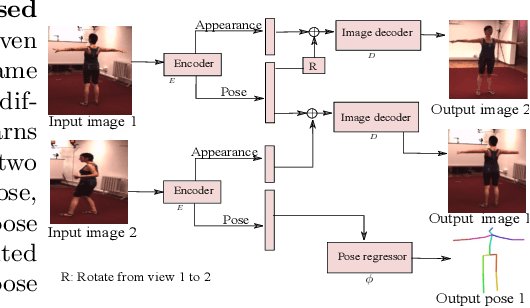


As 3D human pose estimation can now be achieved with very high accuracy in the supervised learning scenario, tackling the case where 3D pose annotations are not available has received increasing attention. In particular, several methods have proposed to learn image representations in a self-supervised fashion so as to disentangle the appearance information from the pose one. The methods then only need a small amount of supervised data to train a pose regressor using the pose-related latent vector as input, as it should be free of appearance information. In this paper, we carry out in-depth analysis to understand to what degree the state-of-the-art disentangled representation learning methods truly separate the appearance information from the pose one. First, we study disentanglement from the perspective of the self-supervised network, via diverse image synthesis experiments. Second, we investigate disentanglement with respect to the 3D pose regressor following an adversarial attack perspective. Specifically, we design an adversarial strategy focusing on generating natural appearance changes of the subject, and against which we could expect a disentangled network to be robust. Altogether, our analyses show that disentanglement in the three state-of-the-art disentangled representation learning frameworks if far from complete, and that their pose codes contain significant appearance information. We believe that our approach provides a valuable testbed to evaluate the degree of disentanglement of pose from appearance in self-supervised 3D human pose estimation.
Investigating Alternative Feature Extraction Pipelines For Clinical Note Phenotyping
Oct 05, 2023A common practice in the medical industry is the use of clinical notes, which consist of detailed patient observations. However, electronic health record systems frequently do not contain these observations in a structured format, rendering patient information challenging to assess and evaluate automatically. Using computational systems for the extraction of medical attributes offers many applications, including longitudinal analysis of patients, risk assessment, and hospital evaluation. Recent work has constructed successful methods for phenotyping: extracting medical attributes from clinical notes. BERT-based models can be used to transform clinical notes into a series of representations, which are then condensed into a single document representation based on their CLS embeddings and passed into an LSTM (Mulyar et al., 2020). Though this pipeline yields a considerable performance improvement over previous results, it requires extensive convergence time. This method also does not allow for predicting attributes not yet identified in clinical notes. Considering the wide variety of medical attributes that may be present in a clinical note, we propose an alternative pipeline utilizing ScispaCy (Neumann et al., 2019) for the extraction of common diseases. We then train various supervised learning models to associate the presence of these conditions with patient attributes. Finally, we replicate a ClinicalBERT (Alsentzer et al., 2019) and LSTM-based approach for purposes of comparison. We find that alternative methods moderately underperform the replicated LSTM approach. Yet, considering a complex tradeoff between accuracy and runtime, in addition to the fact that the alternative approach also allows for the detection of medical conditions that are not already present in a clinical note, its usage may be considered as a supplement to established methods.
Realistic Speech-to-Face Generation with Speech-Conditioned Latent Diffusion Model with Face Prior
Oct 05, 2023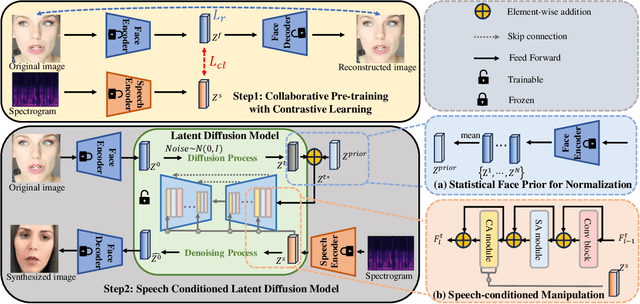

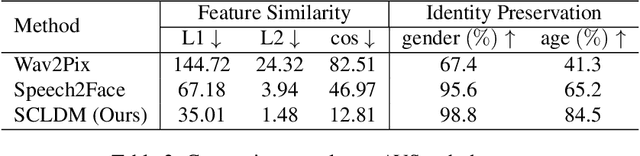
Speech-to-face generation is an intriguing area of research that focuses on generating realistic facial images based on a speaker's audio speech. However, state-of-the-art methods employing GAN-based architectures lack stability and cannot generate realistic face images. To fill this gap, we propose a novel speech-to-face generation framework, which leverages a Speech-Conditioned Latent Diffusion Model, called SCLDM. To the best of our knowledge, this is the first work to harness the exceptional modeling capabilities of diffusion models for speech-to-face generation. Preserving the shared identity information between speech and face is crucial in generating realistic results. Therefore, we employ contrastive pre-training for both the speech encoder and the face encoder. This pre-training strategy facilitates effective alignment between the attributes of speech, such as age and gender, and the corresponding facial characteristics in the face images. Furthermore, we tackle the challenge posed by excessive diversity in the synthesis process caused by the diffusion model. To overcome this challenge, we introduce the concept of residuals by integrating a statistical face prior to the diffusion process. This addition helps to eliminate the shared component across the faces and enhances the subtle variations captured by the speech condition. Extensive quantitative, qualitative, and user study experiments demonstrate that our method can produce more realistic face images while preserving the identity of the speaker better than state-of-the-art methods. Highlighting the notable enhancements, our method demonstrates significant gains in all metrics on the AVSpeech dataset and Voxceleb dataset, particularly noteworthy are the improvements of 32.17 and 32.72 on the cosine distance metric for the two datasets, respectively.