 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
EAG-RS: A Novel Explainability-guided ROI-Selection Framework for ASD Diagnosis via Inter-regional Relation Learning
Oct 05, 2023
Deep learning models based on resting-state functional magnetic resonance imaging (rs-fMRI) have been widely used to diagnose brain diseases, particularly autism spectrum disorder (ASD). Existing studies have leveraged the functional connectivity (FC) of rs-fMRI, achieving notable classification performance. However, they have significant limitations, including the lack of adequate information while using linear low-order FC as inputs to the model, not considering individual characteristics (i.e., different symptoms or varying stages of severity) among patients with ASD, and the non-explainability of the decision process. To cover these limitations, we propose a novel explainability-guided region of interest (ROI) selection (EAG-RS) framework that identifies non-linear high-order functional associations among brain regions by leveraging an explainable artificial intelligence technique and selects class-discriminative regions for brain disease identification. The proposed framework includes three steps: (i) inter-regional relation learning to estimate non-linear relations through random seed-based network masking, (ii) explainable connection-wise relevance score estimation to explore high-order relations between functional connections, and (iii) non-linear high-order FC-based diagnosis-informative ROI selection and classifier learning to identify ASD. We validated the effectiveness of our proposed method by conducting experiments using the Autism Brain Imaging Database Exchange (ABIDE) dataset, demonstrating that the proposed method outperforms other comparative methods in terms of various evaluation metrics. Furthermore, we qualitatively analyzed the selected ROIs and identified ASD subtypes linked to previous neuroscientific studies.
U-Style: Cascading U-nets with Multi-level Speaker and Style Modeling for Zero-Shot Voice Cloning
Oct 06, 2023Zero-shot speaker cloning aims to synthesize speech for any target speaker unseen during TTS system building, given only a single speech reference of the speaker at hand. Although more practical in real applications, the current zero-shot methods still produce speech with undesirable naturalness and speaker similarity. Moreover, endowing the target speaker with arbitrary speaking styles in the zero-shot setup has not been considered. This is because the unique challenge of zero-shot speaker and style cloning is to learn the disentangled speaker and style representations from only short references representing an arbitrary speaker and an arbitrary style. To address this challenge, we propose U-Style, which employs Grad-TTS as the backbone, particularly cascading a speaker-specific encoder and a style-specific encoder between the text encoder and the diffusion decoder. Thus, leveraging signal perturbation, U-Style is explicitly decomposed into speaker- and style-specific modeling parts, achieving better speaker and style disentanglement. To improve unseen speaker and style modeling ability, these two encoders conduct multi-level speaker and style modeling by skip-connected U-nets, incorporating the representation extraction and information reconstruction process. Besides, to improve the naturalness of synthetic speech, we adopt mean-based instance normalization and style adaptive layer normalization in these encoders to perform representation extraction and condition adaptation, respectively. Experiments show that U-Style significantly surpasses the state-of-the-art methods in unseen speaker cloning regarding naturalness and speaker similarity. Notably, U-Style can transfer the style from an unseen source speaker to another unseen target speaker, achieving flexible combinations of desired speaker timbre and style in zero-shot voice cloning.
Vehicle Motion Forecasting using Prior Information and Semantic-assisted Occupancy Grid Maps
Aug 08, 2023
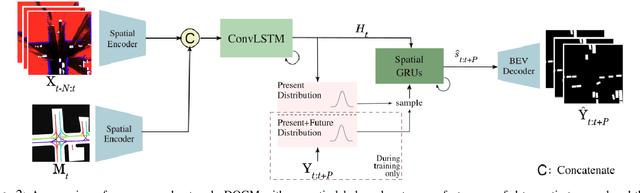

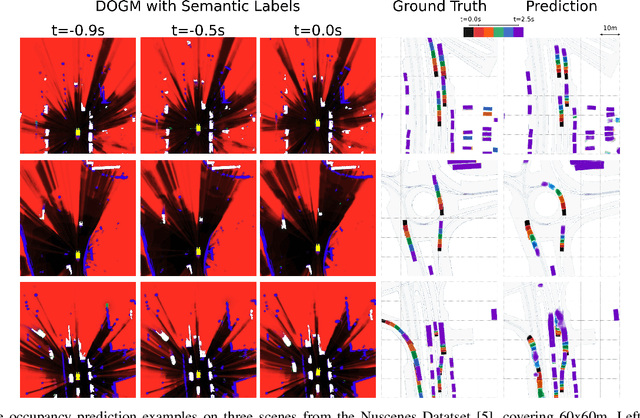
Motion prediction is a challenging task for autonomous vehicles due to uncertainty in the sensor data, the non-deterministic nature of future, and complex behavior of agents. In this paper, we tackle this problem by representing the scene as dynamic occupancy grid maps (DOGMs), associating semantic labels to the occupied cells and incorporating map information. We propose a novel framework that combines deep-learning-based spatio-temporal and probabilistic approaches to predict vehicle behaviors.Contrary to the conventional OGM prediction methods, evaluation of our work is conducted against the ground truth annotations. We experiment and validate our results on real-world NuScenes dataset and show that our model shows superior ability to predict both static and dynamic vehicles compared to OGM predictions. Furthermore, we perform an ablation study and assess the role of semantic labels and map in the architecture.
Era Splitting -- Invariant Learning for Decision Trees
Sep 27, 2023Real life machine learning problems exhibit distributional shifts in the data from one time to another or from on place to another. This behavior is beyond the scope of the traditional empirical risk minimization paradigm, which assumes i.i.d. distribution of data over time and across locations. The emerging field of out-of-distribution (OOD) generalization addresses this reality with new theory and algorithms which incorporate environmental, or era-wise information into the algorithms. So far, most research has been focused on linear models and/or neural networks. In this research we develop two new splitting criteria for decision trees, which allow us to apply ideas from OOD generalization research to decision tree models, including random forest and gradient-boosting decision trees. The new splitting criteria use era-wise information associated with each data point to allow tree-based models to find split points that are optimal across all disjoint eras in the data, instead of optimal over the entire data set pooled together, which is the default setting. We describe the new splitting criteria in detail and develop unique experiments to showcase the benefits of these new criteria, which improve metrics in our experiments out-of-sample. The new criteria are incorporated into the a state-of-the-art gradient boosted decision tree model in the Scikit-Learn code base, which is made freely available.
Node-Aligned Graph-to-Graph Generation for Retrosynthesis Prediction
Sep 27, 2023Single-step retrosynthesis is a crucial task in organic chemistry and drug design, requiring the identification of required reactants to synthesize a specific compound. with the advent of computer-aided synthesis planning, there is growing interest in using machine-learning techniques to facilitate the process. Existing template-free machine learning-based models typically utilize transformer structures and represent molecules as ID sequences. However, these methods often face challenges in fully leveraging the extensive topological information of the molecule and aligning atoms between the production and reactants, leading to results that are not as competitive as those of semi-template models. Our proposed method, Node-Aligned Graph-to-Graph (NAG2G), also serves as a transformer-based template-free model but utilizes 2D molecular graphs and 3D conformation information. Furthermore, our approach simplifies the incorporation of production-reactant atom mapping alignment by leveraging node alignment to determine a specific order for node generation and generating molecular graphs in an auto-regressive manner node-by-node. This method ensures that the node generation order coincides with the node order in the input graph, overcoming the difficulty of determining a specific node generation order in an auto-regressive manner. Our extensive benchmarking results demonstrate that the proposed NAG2G can outperform the previous state-of-the-art baselines in various metrics.
Hierarchical Modeling of Spatial Cues via Spherical Harmonics for Multi-Channel Speech Enhancement
Sep 19, 2023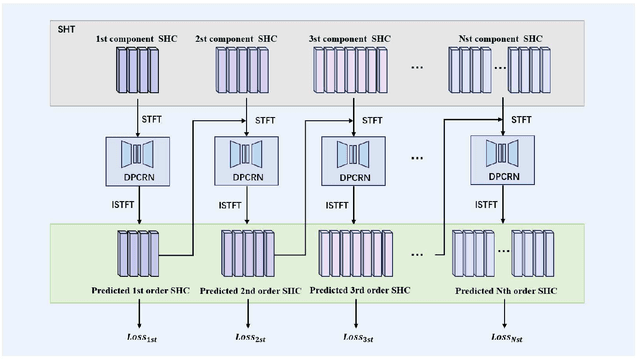



Multi-channel speech enhancement utilizes spatial information from multiple microphones to extract the target speech. However, most existing methods do not explicitly model spatial cues, instead relying on implicit learning from multi-channel spectra. To better leverage spatial information, we propose explicitly incorporating spatial modeling by applying spherical harmonic transforms (SHT) to the multi-channel input. In detail, a hierarchical framework is introduced whereby lower order harmonics capturing broader spatial patterns are estimated first, then combined with higher orders to recursively predict finer spatial details. Experiments on TIMIT demonstrate the proposed method can effectively recover target spatial patterns and achieve improved performance over baseline models, using fewer parameters and computations. Explicitly modeling spatial information hierarchically enables more effective multi-channel speech enhancement.
Improving and Evaluating the Detection of Fragmentation in News Recommendations with the Clustering of News Story Chains
Sep 18, 2023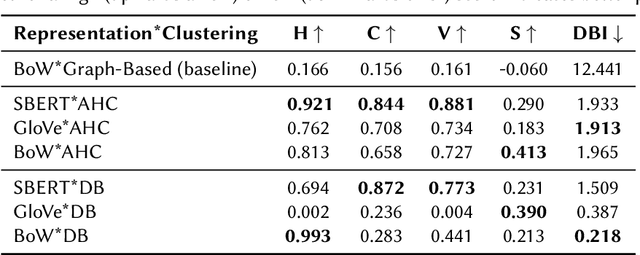
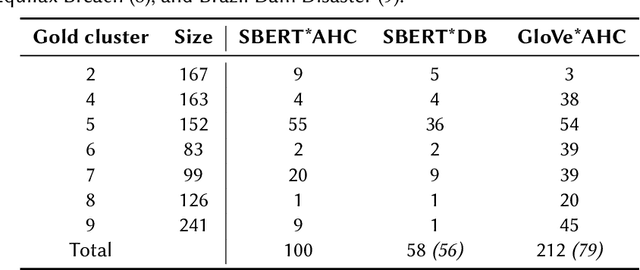
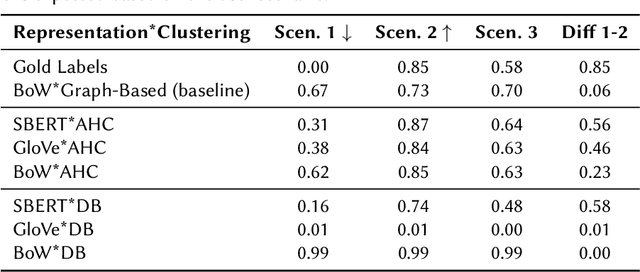
News recommender systems play an increasingly influential role in shaping information access within democratic societies. However, tailoring recommendations to users' specific interests can result in the divergence of information streams. Fragmented access to information poses challenges to the integrity of the public sphere, thereby influencing democracy and public discourse. The Fragmentation metric quantifies the degree of fragmentation of information streams in news recommendations. Accurate measurement of this metric requires the application of Natural Language Processing (NLP) to identify distinct news events, stories, or timelines. This paper presents an extensive investigation of various approaches for quantifying Fragmentation in news recommendations. These approaches are evaluated both intrinsically, by measuring performance on news story clustering, and extrinsically, by assessing the Fragmentation scores of different simulated news recommender scenarios. Our findings demonstrate that agglomerative hierarchical clustering coupled with SentenceBERT text representation is substantially better at detecting Fragmentation than earlier implementations. Additionally, the analysis of simulated scenarios yields valuable insights and recommendations for stakeholders concerning the measurement and interpretation of Fragmentation.
* Cite published version: Polimeno et. al., Improving and Evaluating the Detection of Fragmentation in News Recommendations with the Clustering of News Story Chains, NORMalize 2023: The First Workshop on the Normative Design and Evaluation of Recommender Systems, September 19, 2023, co-located with the ACM Conference on Recommender Systems 2023 (RecSys 2023), Singapore
PAD-Phys: Exploiting Physiology for Presentation Attack Detection in Face Biometrics
Oct 03, 2023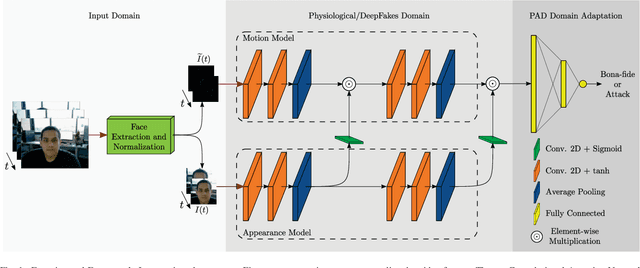
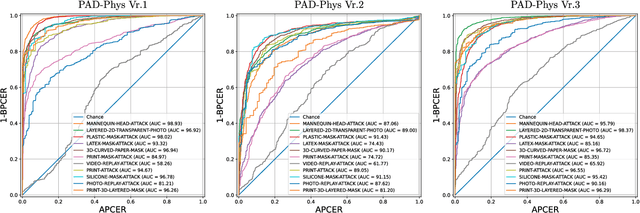
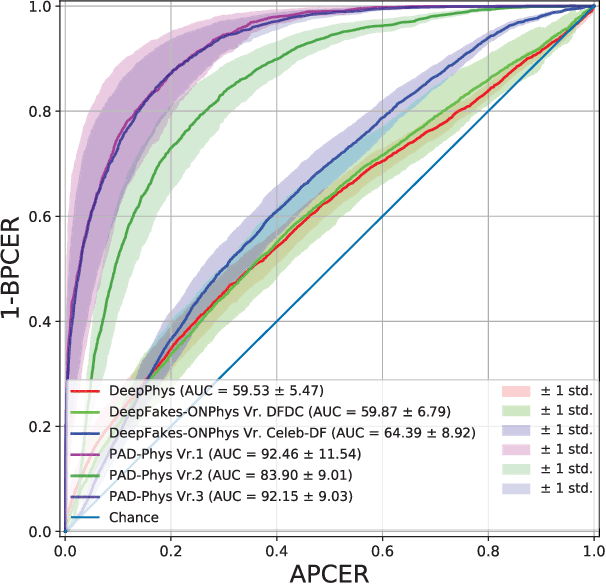
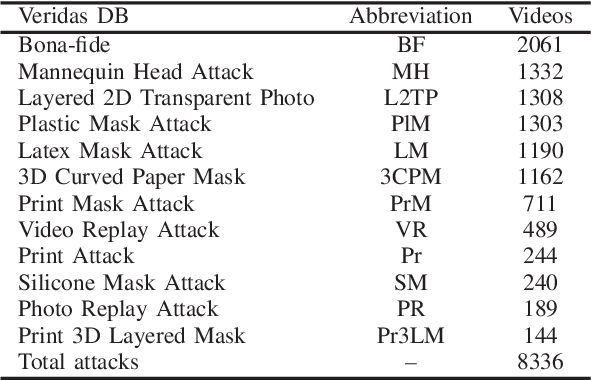
Presentation Attack Detection (PAD) is a crucial stage in facial recognition systems to avoid leakage of personal information or spoofing of identity to entities. Recently, pulse detection based on remote photoplethysmography (rPPG) has been shown to be effective in face presentation attack detection. This work presents three different approaches to the presentation attack detection based on rPPG: (i) The physiological domain, a domain using rPPG-based models, (ii) the Deepfakes domain, a domain where models were retrained from the physiological domain to specific Deepfakes detection tasks; and (iii) a new Presentation Attack domain was trained by applying transfer learning from the two previous domains to improve the capability to differentiate between bona-fides and attacks. The results show the efficiency of the rPPG-based models for presentation attack detection, evidencing a 21.70% decrease in average classification error rate (ACER) (from 41.03% to 19.32%) when the presentation attack domain is compared to the physiological and Deepfakes domains. Our experiments highlight the efficiency of transfer learning in rPPG-based models and perform well in presentation attack detection in instruments that do not allow copying of this physiological feature.
Linearization of ReLU Activation Function for Neural Network-Embedded Optimization:Optimal Day-Ahead Energy Scheduling
Oct 03, 2023Neural networks have been widely applied in the power system area. They can be used for better predicting input information and modeling system performance with increased accuracy. In some applications such as battery degradation neural network-based microgrid day-ahead energy scheduling, the input features of the trained learning model are variables to be solved in optimization models that enforce limits on the output of the same learning model. This will create a neural network-embedded optimization problem; the use of nonlinear activation functions in the neural network will make such problems extremely hard to solve if not unsolvable. To address this emerging challenge, this paper investigated different methods for linearizing the nonlinear activation functions with a particular focus on the widely used rectified linear unit (ReLU) function. Four linearization methods tailored for the ReLU activation function are developed, analyzed and compared in this paper. Each method employs a set of linear constraints to replace the ReLU function, effectively linearizing the optimization problem, which can overcome the computational challenges associated with the nonlinearity of the neural network model. These proposed linearization methods provide valuable tools for effectively solving optimization problems that integrate neural network models with ReLU activation functions.
FedLPA: Personalized One-shot Federated Learning with Layer-Wise Posterior Aggregation
Oct 03, 2023
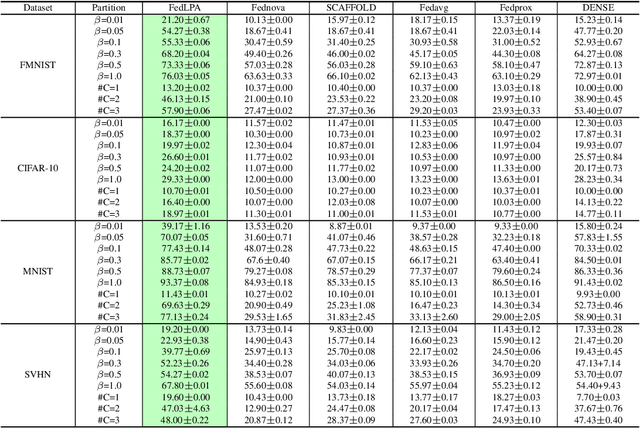
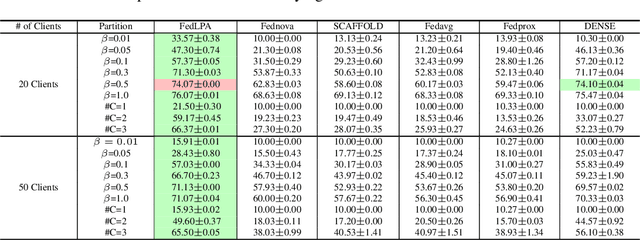
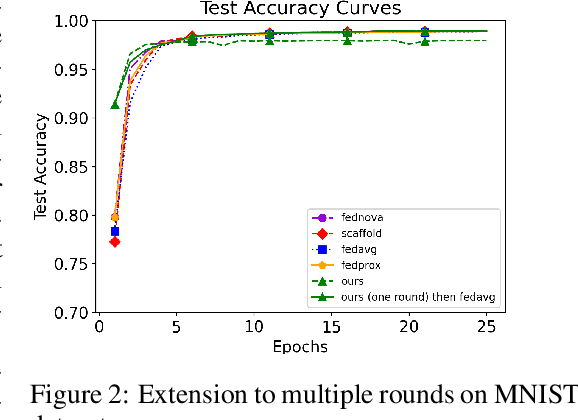
Efficiently aggregating trained neural networks from local clients into a global model on a server is a widely researched topic in federated learning. Recently, motivated by diminishing privacy concerns, mitigating potential attacks, and reducing the overhead of communication, one-shot federated learning (i.e., limiting client-server communication into a single round) has gained popularity among researchers. However, the one-shot aggregation performances are sensitively affected by the non-identical training data distribution, which exhibits high statistical heterogeneity in some real-world scenarios. To address this issue, we propose a novel one-shot aggregation method with Layer-wise Posterior Aggregation, named FedLPA. FedLPA aggregates local models to obtain a more accurate global model without requiring extra auxiliary datasets or exposing any confidential local information, e.g., label distributions. To effectively capture the statistics maintained in the biased local datasets in the practical non-IID scenario, we efficiently infer the posteriors of each layer in each local model using layer-wise Laplace approximation and aggregate them to train the global parameters. Extensive experimental results demonstrate that FedLPA significantly improves learning performance over state-of-the-art methods across several metrics.