 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Neural architecture impact on identifying temporally extended Reinforcement Learning tasks
Oct 04, 2023
Inspired by recent developments in attention models for image classification and natural language processing, we present various Attention based architectures in reinforcement learning (RL) domain, capable of performing well on OpenAI Gym Atari-2600 game suite. In spite of the recent success of Deep Reinforcement learning techniques in various fields like robotics, gaming and healthcare, they suffer from a major drawback that neural networks are difficult to interpret. We try to get around this problem with the help of Attention based models. In Attention based models, extracting and overlaying of attention map onto images allows for direct observation of information used by agent to select actions and easier interpretation of logic behind the chosen actions. Our models in addition to playing well on gym-Atari environments, also provide insights on how agent perceives its environment. In addition, motivated by recent developments in attention based video-classification models using Vision Transformer, we come up with an architecture based on Vision Transformer, for image-based RL domain too. Compared to previous works in Vision Transformer, our model is faster to train and requires fewer computational resources. 3
Non-parametric Ensemble Empirical Mode Decomposition for extracting weak features to identify bearing defects
Oct 02, 2023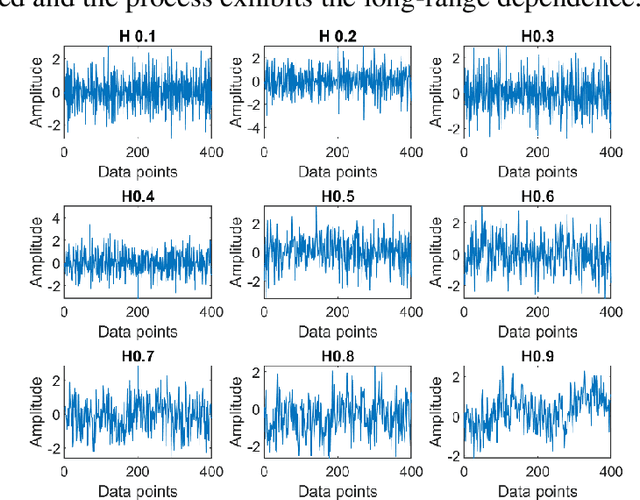
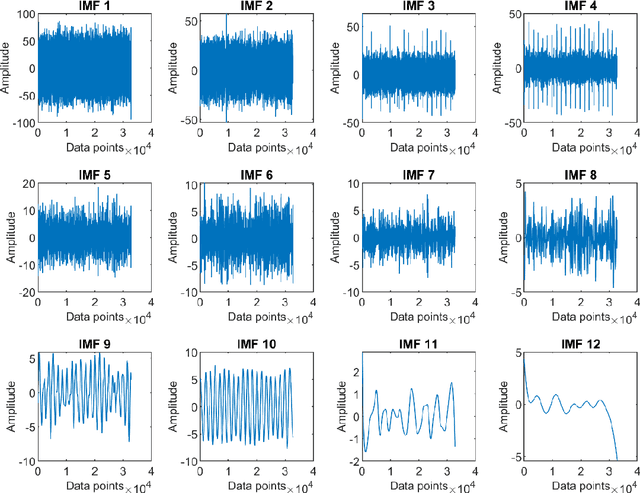
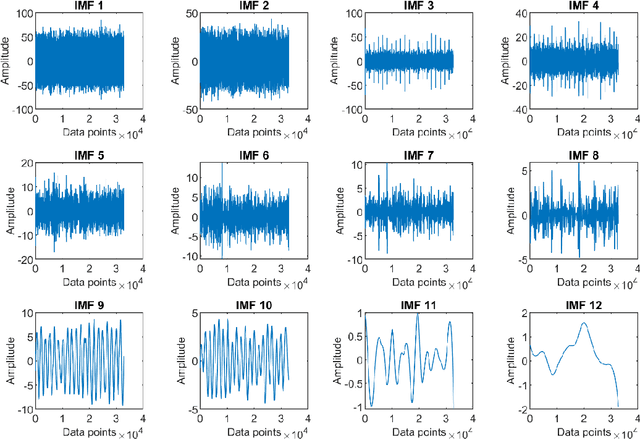
A non-parametric complementary ensemble empirical mode decomposition (NPCEEMD) is proposed for identifying bearing defects using weak features. NPCEEMD is non-parametric because, unlike existing decomposition methods such as ensemble empirical mode decomposition, it does not require defining the ideal SNR of noise and the number of ensembles, every time while processing the signals. The simulation results show that mode mixing in NPCEEMD is less than the existing decomposition methods. After conducting in-depth simulation analysis, the proposed method is applied to experimental data. The proposed NPCEEMD method works in following steps. First raw signal is obtained. Second, the obtained signal is decomposed. Then, the mutual information (MI) of the raw signal with NPCEEMD-generated IMFs is computed. Further IMFs with MI above 0.1 are selected and combined to form a resulting signal. Finally, envelope spectrum of resulting signal is computed to confirm the presence of defect.
Data Efficient Training of a U-Net Based Architecture for Structured Documents Localization
Oct 02, 2023
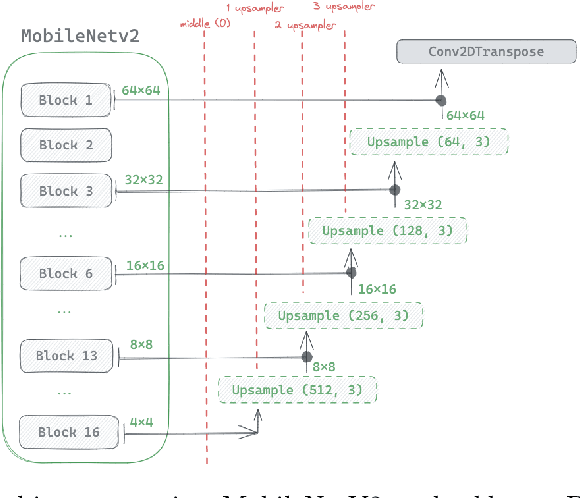


Structured documents analysis and recognition are essential for modern online on-boarding processes, and document localization is a crucial step to achieve reliable key information extraction. While deep-learning has become the standard technique used to solve document analysis problems, real-world applications in industry still face the limited availability of labelled data and of computational resources when training or fine-tuning deep-learning models. To tackle these challenges, we propose SDL-Net: a novel U-Net like encoder-decoder architecture for the localization of structured documents. Our approach allows pre-training the encoder of SDL-Net on a generic dataset containing samples of various document classes, and enables fast and data-efficient fine-tuning of decoders to support the localization of new document classes. We conduct extensive experiments on a proprietary dataset of structured document images to demonstrate the effectiveness and the generalization capabilities of the proposed approach.
CommIN: Semantic Image Communications as an Inverse Problem with INN-Guided Diffusion Models
Oct 02, 2023Joint source-channel coding schemes based on deep neural networks (DeepJSCC) have recently achieved remarkable performance for wireless image transmission. However, these methods usually focus only on the distortion of the reconstructed signal at the receiver side with respect to the source at the transmitter side, rather than the perceptual quality of the reconstruction which carries more semantic information. As a result, severe perceptual distortion can be introduced under extreme conditions such as low bandwidth and low signal-to-noise ratio. In this work, we propose CommIN, which views the recovery of high-quality source images from degraded reconstructions as an inverse problem. To address this, CommIN combines Invertible Neural Networks (INN) with diffusion models, aiming for superior perceptual quality. Through experiments, we show that our CommIN significantly improves the perceptual quality compared to DeepJSCC under extreme conditions and outperforms other inverse problem approaches used in DeepJSCC.
CCSPNet-Joint: Efficient Joint Training Method for Traffic Sign Detection Under Extreme Conditions
Sep 25, 2023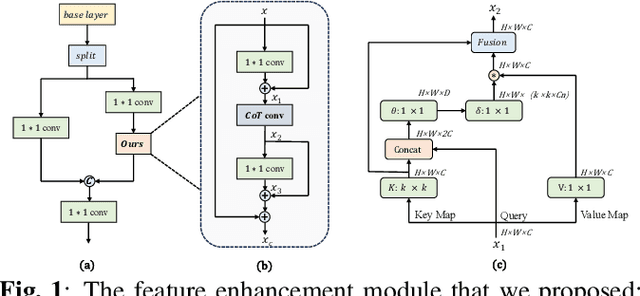
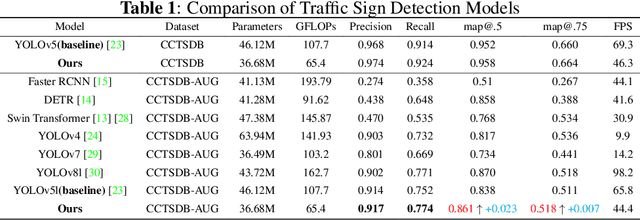
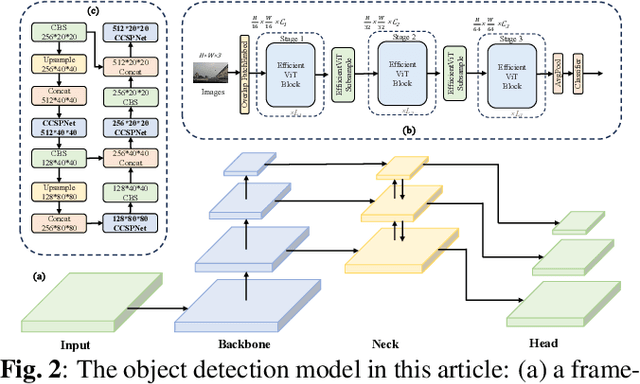
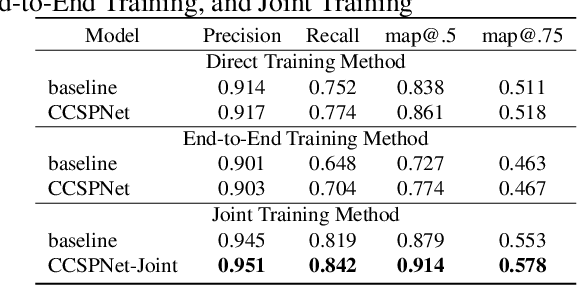
Traffic sign detection is an important research direction in intelligent driving. Unfortunately, existing methods often overlook extreme conditions such as fog, rain, and motion blur. Moreover, the end-to-end training strategy for image denoising and object detection models fails to utilize inter-model information effectively. To address these issues, we propose CCSPNet, an efficient feature extraction module based on Transformers and CNNs, which effectively leverages contextual information, achieves faster inference speed and provides stronger feature enhancement capabilities. Furthermore, we establish the correlation between object detection and image denoising tasks and propose a joint training model, CCSPNet-Joint, to improve data efficiency and generalization. Finally, to validate our approach, we create the CCTSDB-AUG dataset for traffic sign detection in extreme scenarios. Extensive experiments have shown that CCSPNet achieves state-of-the-art performance in traffic sign detection under extreme conditions. Compared to end-to-end methods, CCSPNet-Joint achieves a 5.32% improvement in precision and an 18.09% improvement in mAP@.5.
SPOTS: Stable Placement of Objects with Reasoning in Semi-Autonomous Teleoperation Systems
Sep 25, 2023Pick-and-place is one of the fundamental tasks in robotics research. However, the attention has been mostly focused on the ``pick'' task, leaving the ``place'' task relatively unexplored. In this paper, we address the problem of placing objects in the context of a teleoperation framework. Particularly, we focus on two aspects of the place task: stability robustness and contextual reasonableness of object placements. Our proposed method combines simulation-driven physical stability verification via real-to-sim and the semantic reasoning capability of large language models. In other words, given place context information (e.g., user preferences, object to place, and current scene information), our proposed method outputs a probability distribution over the possible placement candidates, considering the robustness and reasonableness of the place task. Our proposed method is extensively evaluated in two simulation and one real world environments and we show that our method can greatly increase the physical plausibility of the placement as well as contextual soundness while considering user preferences.
Dynamic Scene Graph Representation for Surgical Video
Sep 25, 2023Surgical videos captured from microscopic or endoscopic imaging devices are rich but complex sources of information, depicting different tools and anatomical structures utilized during an extended amount of time. Despite containing crucial workflow information and being commonly recorded in many procedures, usage of surgical videos for automated surgical workflow understanding is still limited. In this work, we exploit scene graphs as a more holistic, semantically meaningful and human-readable way to represent surgical videos while encoding all anatomical structures, tools, and their interactions. To properly evaluate the impact of our solutions, we create a scene graph dataset from semantic segmentations from the CaDIS and CATARACTS datasets. We demonstrate that scene graphs can be leveraged through the use of graph convolutional networks (GCNs) to tackle surgical downstream tasks such as surgical workflow recognition with competitive performance. Moreover, we demonstrate the benefits of surgical scene graphs regarding the explainability and robustness of model decisions, which are crucial in the clinical setting.
Vehicle Motion Forecasting using Prior Information and Semantic-assisted Occupancy Grid Maps
Aug 08, 2023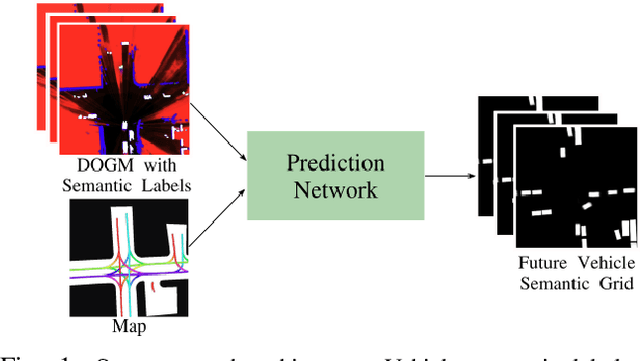
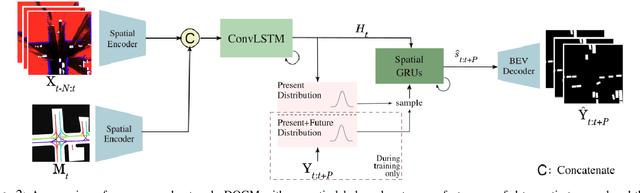

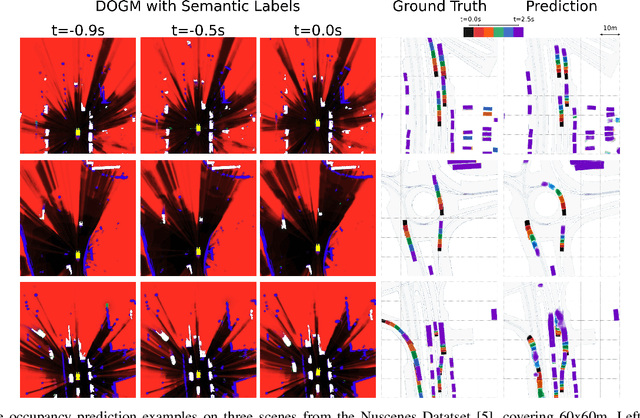
Motion prediction is a challenging task for autonomous vehicles due to uncertainty in the sensor data, the non-deterministic nature of future, and complex behavior of agents. In this paper, we tackle this problem by representing the scene as dynamic occupancy grid maps (DOGMs), associating semantic labels to the occupied cells and incorporating map information. We propose a novel framework that combines deep-learning-based spatio-temporal and probabilistic approaches to predict vehicle behaviors.Contrary to the conventional OGM prediction methods, evaluation of our work is conducted against the ground truth annotations. We experiment and validate our results on real-world NuScenes dataset and show that our model shows superior ability to predict both static and dynamic vehicles compared to OGM predictions. Furthermore, we perform an ablation study and assess the role of semantic labels and map in the architecture.
Spatially Guiding Unsupervised Semantic Segmentation Through Depth-Informed Feature Distillation and Sampling
Sep 21, 2023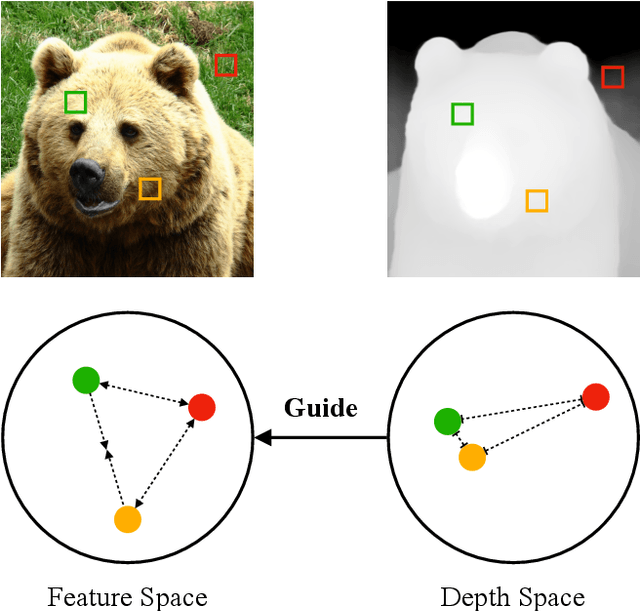
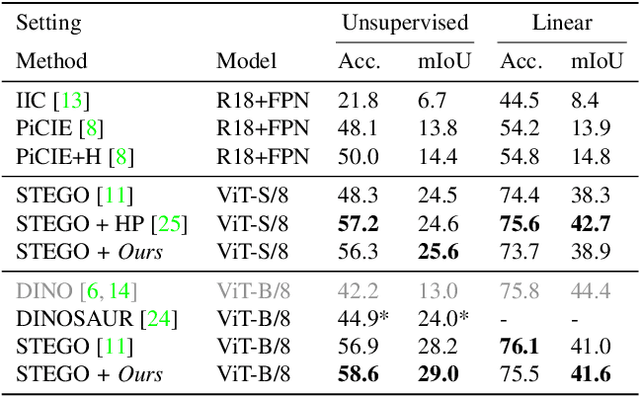
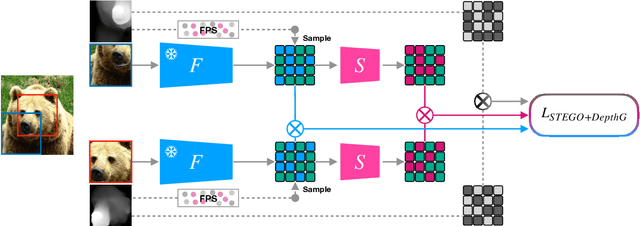
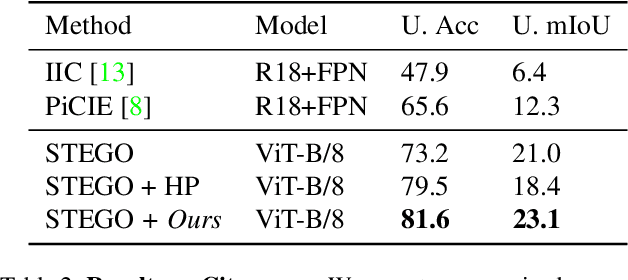
Traditionally, training neural networks to perform semantic segmentation required expensive human-made annotations. But more recently, advances in the field of unsupervised learning have made significant progress on this issue and towards closing the gap to supervised algorithms. To achieve this, semantic knowledge is distilled by learning to correlate randomly sampled features from images across an entire dataset. In this work, we build upon these advances by incorporating information about the structure of the scene into the training process through the use of depth information. We achieve this by (1) learning depth-feature correlation by spatially correlate the feature maps with the depth maps to induce knowledge about the structure of the scene and (2) implementing farthest-point sampling to more effectively select relevant features by utilizing 3D sampling techniques on depth information of the scene. Finally, we demonstrate the effectiveness of our technical contributions through extensive experimentation and present significant improvements in performance across multiple benchmark datasets.
FGFusion: Fine-Grained Lidar-Camera Fusion for 3D Object Detection
Sep 21, 2023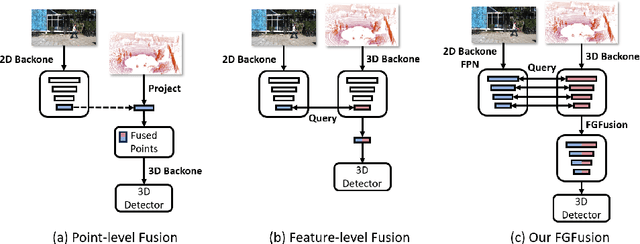
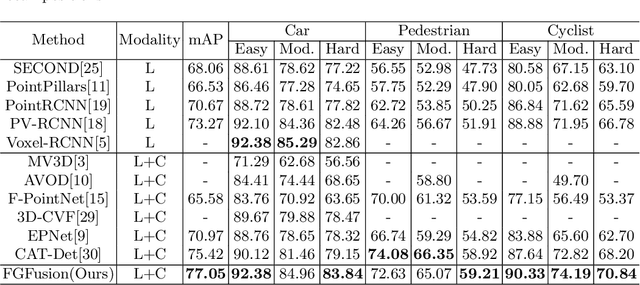
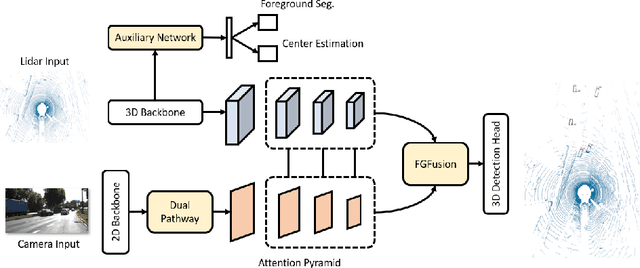
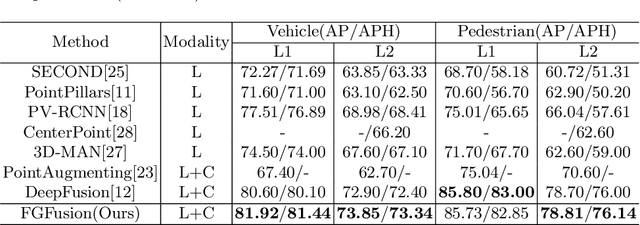
Lidars and cameras are critical sensors that provide complementary information for 3D detection in autonomous driving. While most prevalent methods progressively downscale the 3D point clouds and camera images and then fuse the high-level features, the downscaled features inevitably lose low-level detailed information. In this paper, we propose Fine-Grained Lidar-Camera Fusion (FGFusion) that make full use of multi-scale features of image and point cloud and fuse them in a fine-grained way. First, we design a dual pathway hierarchy structure to extract both high-level semantic and low-level detailed features of the image. Second, an auxiliary network is introduced to guide point cloud features to better learn the fine-grained spatial information. Finally, we propose multi-scale fusion (MSF) to fuse the last N feature maps of image and point cloud. Extensive experiments on two popular autonomous driving benchmarks, i.e. KITTI and Waymo, demonstrate the effectiveness of our method.