 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Content-Driven Micro-Video Recommendation Dataset at Scale
Sep 27, 2023




Micro-videos have recently gained immense popularity, sparking critical research in micro-video recommendation with significant implications for the entertainment, advertising, and e-commerce industries. However, the lack of large-scale public micro-video datasets poses a major challenge for developing effective recommender systems. To address this challenge, we introduce a very large micro-video recommendation dataset, named "MicroLens", consisting of one billion user-item interaction behaviors, 34 million users, and one million micro-videos. This dataset also contains various raw modality information about videos, including titles, cover images, audio, and full-length videos. MicroLens serves as a benchmark for content-driven micro-video recommendation, enabling researchers to utilize various modalities of video information for recommendation, rather than relying solely on item IDs or off-the-shelf video features extracted from a pre-trained network. Our benchmarking of multiple recommender models and video encoders on MicroLens has yielded valuable insights into the performance of micro-video recommendation. We believe that this dataset will not only benefit the recommender system community but also promote the development of the video understanding field. Our datasets and code are available at https://github.com/westlake-repl/MicroLens.
In-Hand Re-grasp Manipulation with Passive Dynamic Actions via Imitation Learning
Sep 27, 2023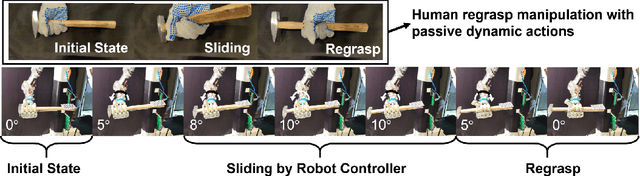
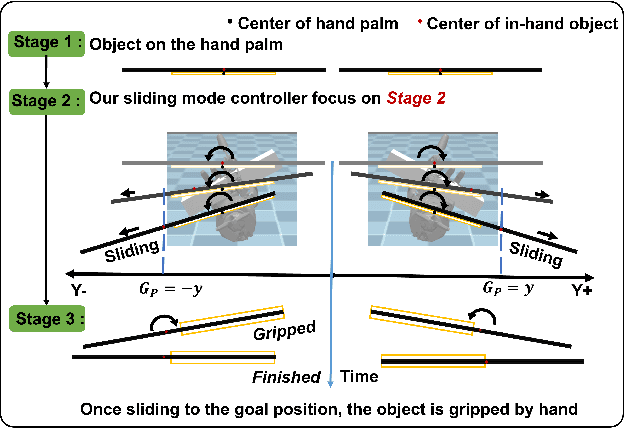
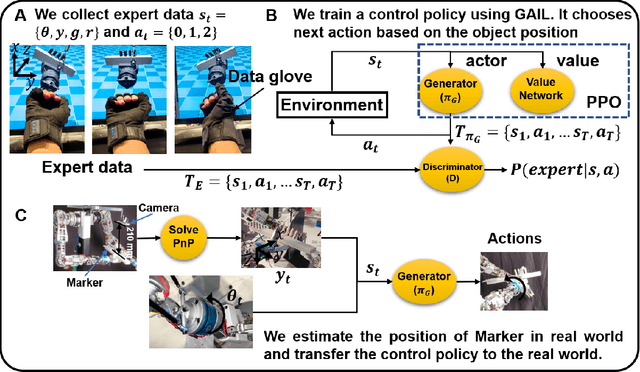
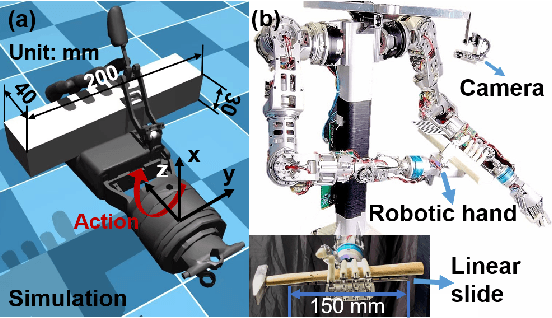
Re-grasp manipulation leverages on ergonomic tools to assist humans in accomplishing diverse tasks. In certain scenarios, humans often employ external forces to effortlessly and precisely re-grasp tools like a hammer. Previous development on controllers for in-grasp sliding motion using passive dynamic actions (e.g.,gravity) relies on apprehension of finger-object contact information, and requires customized design for individual objects with varied geometry and weight distribution. It limits their adaptability to diverse objects. In this paper, we propose an end-to-end sliding motion controller based on imitation learning (IL) that necessitates minimal prior knowledge of object mechanics, relying solely on object position information. To expedite training convergence, we utilize a data glove to collect expert data trajectories and train the policy through Generative Adversarial Imitation Learning (GAIL). Simulation results demonstrate the controller's versatility in performing in-hand sliding tasks with objects of varying friction coefficients, geometric shapes, and masses. By migrating to a physical system using visual position estimation, the controller demonstrated an average success rate of 86%, surpassing the baseline algorithm's success rate of 35% of Behavior Cloning(BC) and 20% of Proximal Policy Optimization (PPO).
Spatial-Temporal Transformer based Video Compression Framework
Sep 21, 2023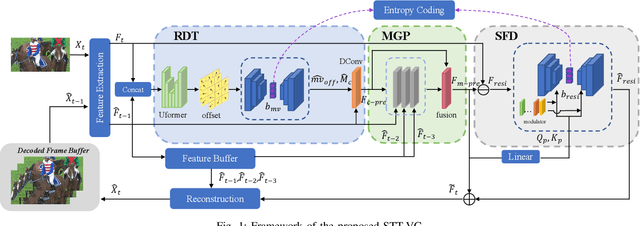
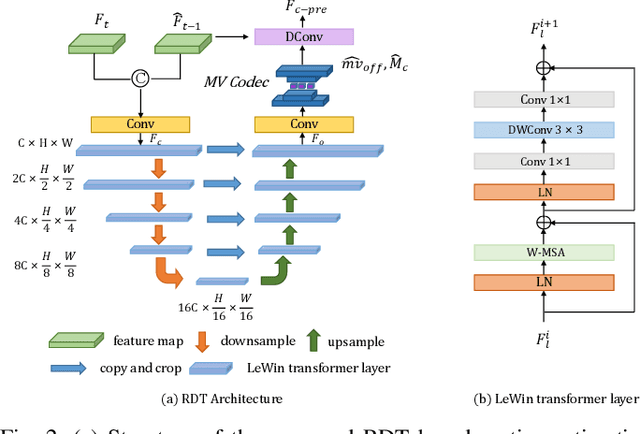
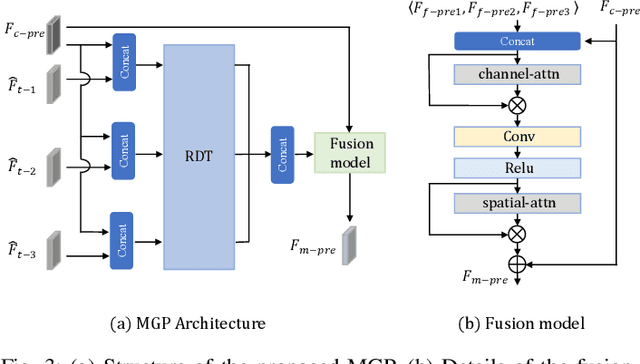
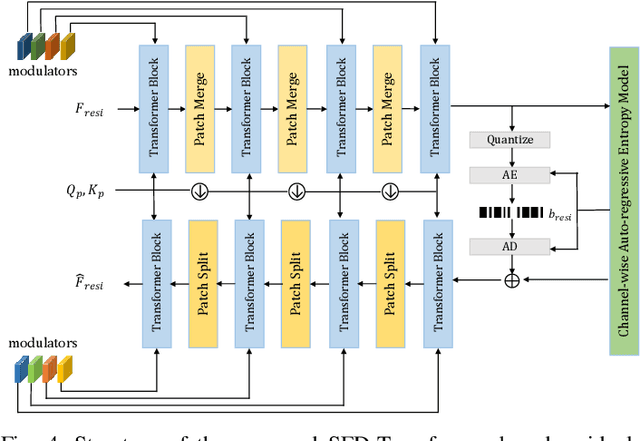
Learned video compression (LVC) has witnessed remarkable advancements in recent years. Similar as the traditional video coding, LVC inherits motion estimation/compensation, residual coding and other modules, all of which are implemented with neural networks (NNs). However, within the framework of NNs and its training mechanism using gradient backpropagation, most existing works often struggle to consistently generate stable motion information, which is in the form of geometric features, from the input color features. Moreover, the modules such as the inter-prediction and residual coding are independent from each other, making it inefficient to fully reduce the spatial-temporal redundancy. To address the above problems, in this paper, we propose a novel Spatial-Temporal Transformer based Video Compression (STT-VC) framework. It contains a Relaxed Deformable Transformer (RDT) with Uformer based offsets estimation for motion estimation and compensation, a Multi-Granularity Prediction (MGP) module based on multi-reference frames for prediction refinement, and a Spatial Feature Distribution prior based Transformer (SFD-T) for efficient temporal-spatial joint residual compression. Specifically, RDT is developed to stably estimate the motion information between frames by thoroughly investigating the relationship between the similarity based geometric motion feature extraction and self-attention. MGP is designed to fuse the multi-reference frame information by effectively exploring the coarse-grained prediction feature generated with the coded motion information. SFD-T is to compress the residual information by jointly exploring the spatial feature distributions in both residual and temporal prediction to further reduce the spatial-temporal redundancy. Experimental results demonstrate that our method achieves the best result with 13.5% BD-Rate saving over VTM.
Talk2Care: Facilitating Asynchronous Patient-Provider Communication with Large-Language-Model
Sep 22, 2023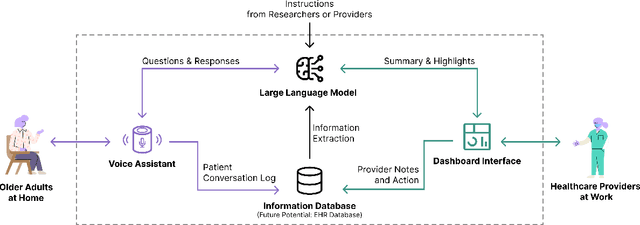
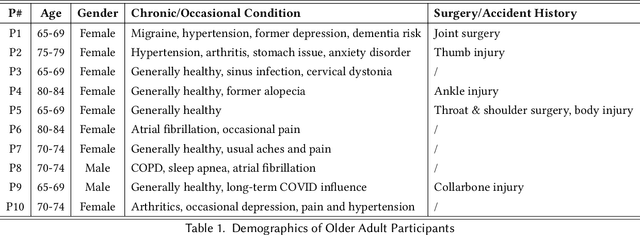
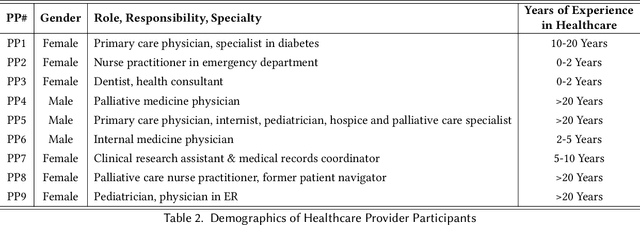
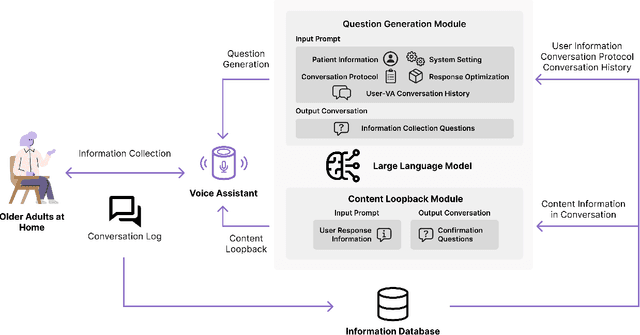
Despite the plethora of telehealth applications to assist home-based older adults and healthcare providers, basic messaging and phone calls are still the most common communication methods, which suffer from limited availability, information loss, and process inefficiencies. One promising solution to facilitate patient-provider communication is to leverage large language models (LLMs) with their powerful natural conversation and summarization capability. However, there is a limited understanding of LLMs' role during the communication. We first conducted two interview studies with both older adults (N=10) and healthcare providers (N=9) to understand their needs and opportunities for LLMs in patient-provider asynchronous communication. Based on the insights, we built an LLM-powered communication system, Talk2Care, and designed interactive components for both groups: (1) For older adults, we leveraged the convenience and accessibility of voice assistants (VAs) and built an LLM-powered VA interface for effective information collection. (2) For health providers, we built an LLM-based dashboard to summarize and present important health information based on older adults' conversations with the VA. We further conducted two user studies with older adults and providers to evaluate the usability of the system. The results showed that Talk2Care could facilitate the communication process, enrich the health information collected from older adults, and considerably save providers' efforts and time. We envision our work as an initial exploration of LLMs' capability in the intersection of healthcare and interpersonal communication.
Logical Bias Learning for Object Relation Prediction
Oct 01, 2023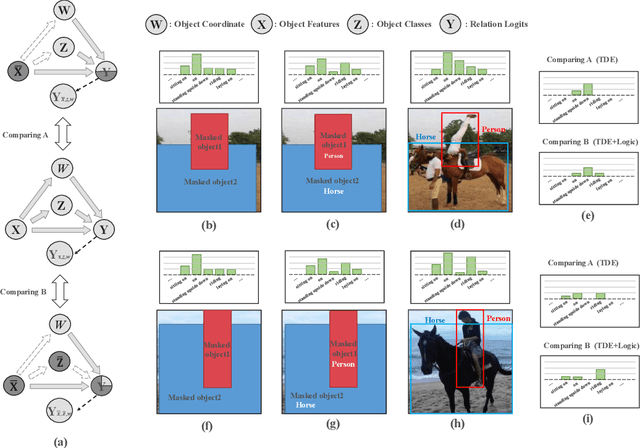
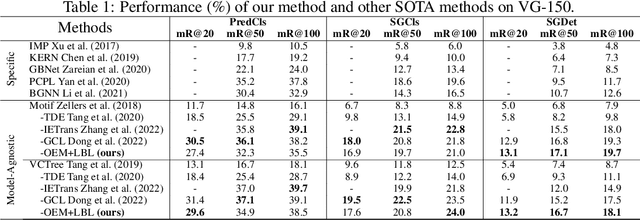
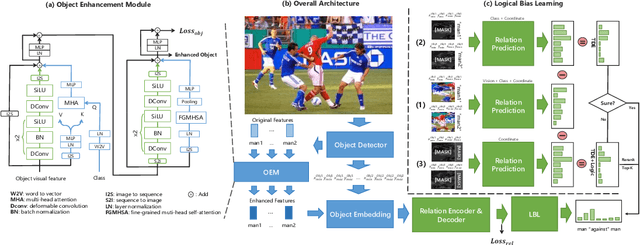
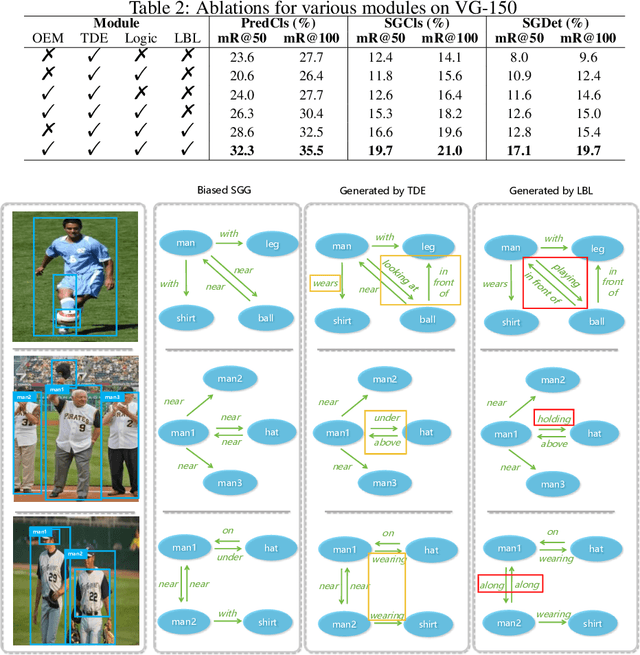
Scene graph generation (SGG) aims to automatically map an image into a semantic structural graph for better scene understanding. It has attracted significant attention for its ability to provide object and relation information, enabling graph reasoning for downstream tasks. However, it faces severe limitations in practice due to the biased data and training method. In this paper, we present a more rational and effective strategy based on causal inference for object relation prediction. To further evaluate the superiority of our strategy, we propose an object enhancement module to conduct ablation studies. Experimental results on the Visual Gnome 150 (VG-150) dataset demonstrate the effectiveness of our proposed method. These contributions can provide great potential for foundation models for decision-making.
An Evaluation of ChatGPT-4's Qualitative Spatial Reasoning Capabilities in RCC-8
Sep 27, 2023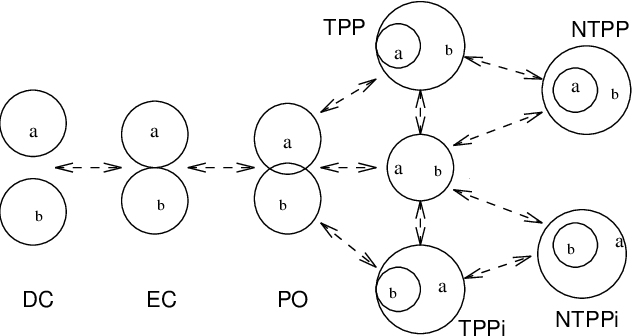
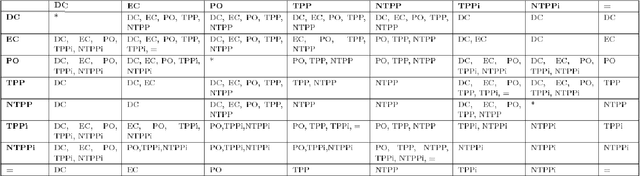
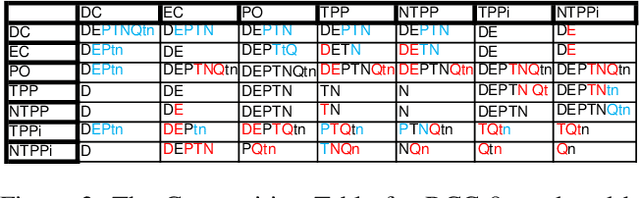
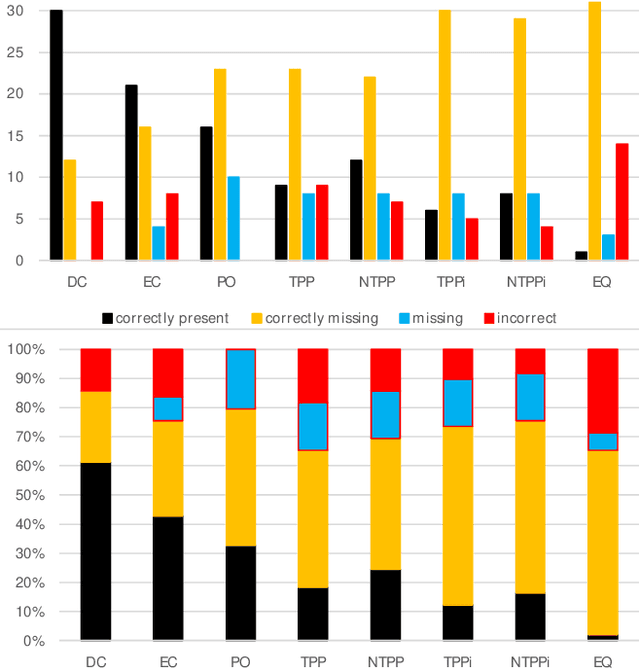
Qualitative Spatial Reasoning (QSR) is well explored area of Commonsense Reasoning and has multiple applications ranging from Geographical Information Systems to Robotics and Computer Vision. Recently many claims have been made for the capabilities of Large Language Models (LLMs). In this paper we investigate the extent to which one particular LLM can perform classical qualitative spatial reasoning tasks on the mereotopological calculus, RCC-8.
A Learnable Counter-condition Analysis Framework for Functional Connectivity-based Neurological Disorder Diagnosis
Oct 06, 2023To understand the biological characteristics of neurological disorders with functional connectivity (FC), recent studies have widely utilized deep learning-based models to identify the disease and conducted post-hoc analyses via explainable models to discover disease-related biomarkers. Most existing frameworks consist of three stages, namely, feature selection, feature extraction for classification, and analysis, where each stage is implemented separately. However, if the results at each stage lack reliability, it can cause misdiagnosis and incorrect analysis in afterward stages. In this study, we propose a novel unified framework that systemically integrates diagnoses (i.e., feature selection and feature extraction) and explanations. Notably, we devised an adaptive attention network as a feature selection approach to identify individual-specific disease-related connections. We also propose a functional network relational encoder that summarizes the global topological properties of FC by learning the inter-network relations without pre-defined edges between functional networks. Last but not least, our framework provides a novel explanatory power for neuroscientific interpretation, also termed counter-condition analysis. We simulated the FC that reverses the diagnostic information (i.e., counter-condition FC): converting a normal brain to be abnormal and vice versa. We validated the effectiveness of our framework by using two large resting-state functional magnetic resonance imaging (fMRI) datasets, Autism Brain Imaging Data Exchange (ABIDE) and REST-meta-MDD, and demonstrated that our framework outperforms other competing methods for disease identification. Furthermore, we analyzed the disease-related neurological patterns based on counter-condition analysis.
Generalized Robust Test-Time Adaptation in Continuous Dynamic Scenarios
Oct 07, 2023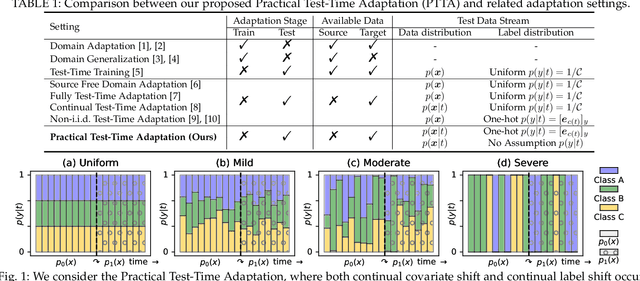
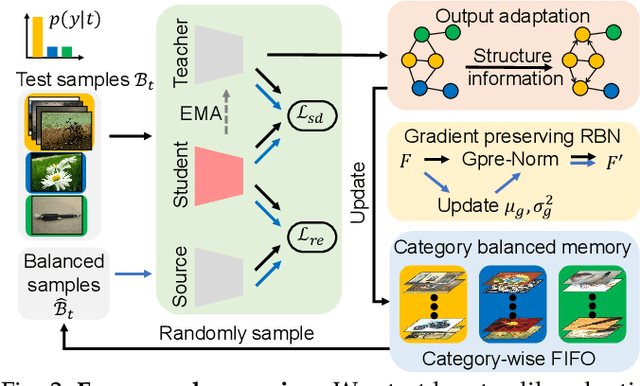
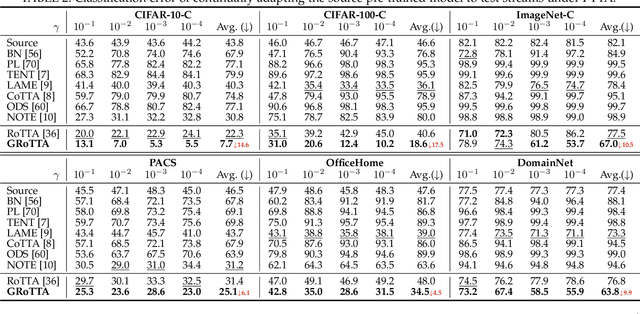

Test-time adaptation (TTA) adapts the pre-trained models to test distributions during the inference phase exclusively employing unlabeled test data streams, which holds great value for the deployment of models in real-world applications. Numerous studies have achieved promising performance on simplistic test streams, characterized by independently and uniformly sampled test data originating from a fixed target data distribution. However, these methods frequently prove ineffective in practical scenarios, where both continual covariate shift and continual label shift occur simultaneously, i.e., data and label distributions change concurrently and continually over time. In this study, a more challenging Practical Test-Time Adaptation (PTTA) setup is introduced, which takes into account the concurrent presence of continual covariate shift and continual label shift, and we propose a Generalized Robust Test-Time Adaptation (GRoTTA) method to effectively address the difficult problem. We start by steadily adapting the model through Robust Parameter Adaptation to make balanced predictions for test samples. To be specific, firstly, the effects of continual label shift are eliminated by enforcing the model to learn from a uniform label distribution and introducing recalibration of batch normalization to ensure stability. Secondly, the continual covariate shift is alleviated by employing a source knowledge regularization with the teacher-student model to update parameters. Considering the potential information in the test stream, we further refine the balanced predictions by Bias-Guided Output Adaptation, which exploits latent structure in the feature space and is adaptive to the imbalanced label distribution. Extensive experiments demonstrate GRoTTA outperforms the existing competitors by a large margin under PTTA setting, rendering it highly conducive for adoption in real-world applications.
Towards General-Purpose Text-Instruction-Guided Voice Conversion
Sep 25, 2023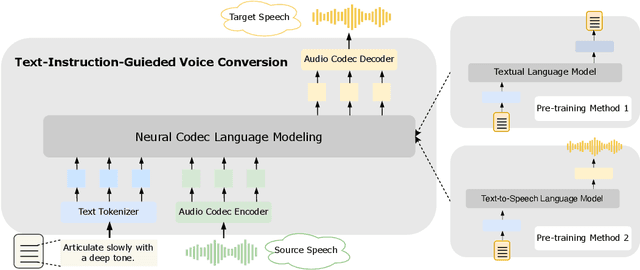
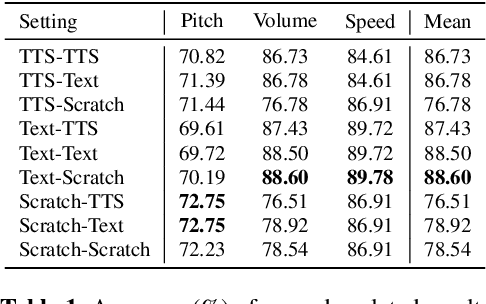
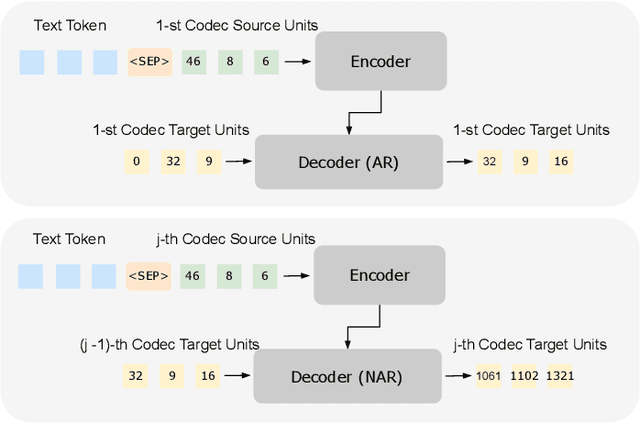
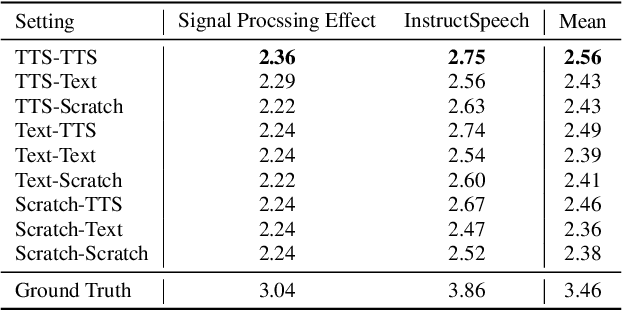
This paper introduces a novel voice conversion (VC) model, guided by text instructions such as "articulate slowly with a deep tone" or "speak in a cheerful boyish voice". Unlike traditional methods that rely on reference utterances to determine the attributes of the converted speech, our model adds versatility and specificity to voice conversion. The proposed VC model is a neural codec language model which processes a sequence of discrete codes, resulting in the code sequence of converted speech. It utilizes text instructions as style prompts to modify the prosody and emotional information of the given speech. In contrast to previous approaches, which often rely on employing separate encoders like prosody and content encoders to handle different aspects of the source speech, our model handles various information of speech in an end-to-end manner. Experiments have demonstrated the impressive capabilities of our model in comprehending instructions and delivering reasonable results.
Multi-level feature fusion network combining attention mechanisms for polyp segmentation
Sep 24, 2023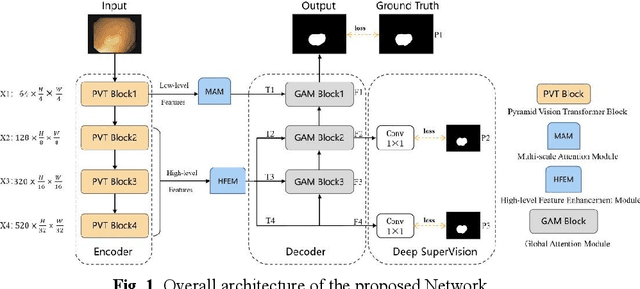
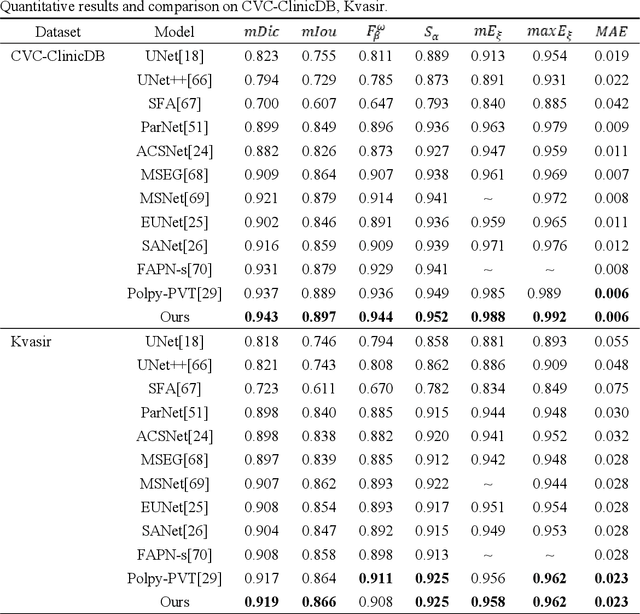
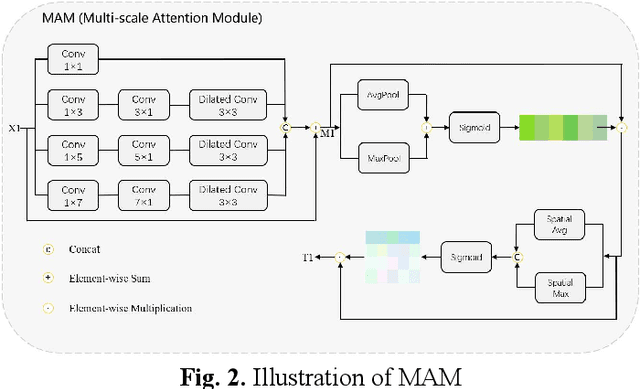
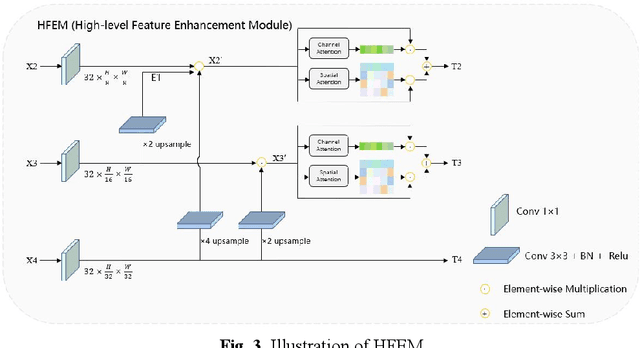
Clinically, automated polyp segmentation techniques have the potential to significantly improve the efficiency and accuracy of medical diagnosis, thereby reducing the risk of colorectal cancer in patients. Unfortunately, existing methods suffer from two significant weaknesses that can impact the accuracy of segmentation. Firstly, features extracted by encoders are not adequately filtered and utilized. Secondly, semantic conflicts and information redundancy caused by feature fusion are not attended to. To overcome these limitations, we propose a novel approach for polyp segmentation, named MLFF-Net, which leverages multi-level feature fusion and attention mechanisms. Specifically, MLFF-Net comprises three modules: Multi-scale Attention Module (MAM), High-level Feature Enhancement Module (HFEM), and Global Attention Module (GAM). Among these, MAM is used to extract multi-scale information and polyp details from the shallow output of the encoder. In HFEM, the deep features of the encoders complement each other by aggregation. Meanwhile, the attention mechanism redistributes the weight of the aggregated features, weakening the conflicting redundant parts and highlighting the information useful to the task. GAM combines features from the encoder and decoder features, as well as computes global dependencies to prevent receptive field locality. Experimental results on five public datasets show that the proposed method not only can segment multiple types of polyps but also has advantages over current state-of-the-art methods in both accuracy and generalization ability.