 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Poisoning Fair Representations
Sep 28, 2023
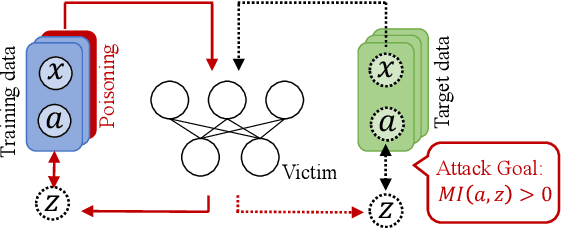
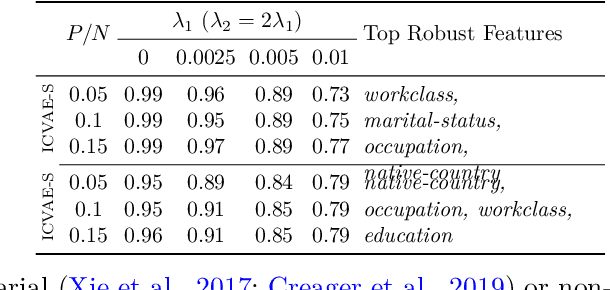
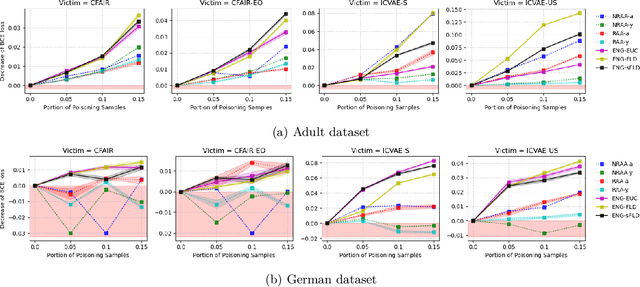
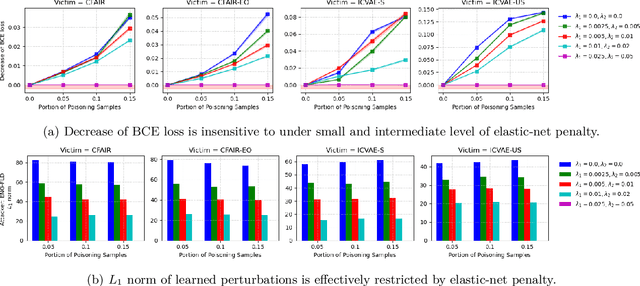
Fair machine learning seeks to mitigate model prediction bias against certain demographic subgroups such as elder and female. Recently, fair representation learning (FRL) trained by deep neural networks has demonstrated superior performance, whereby representations containing no demographic information are inferred from the data and then used as the input to classification or other downstream tasks. Despite the development of FRL methods, their vulnerability under data poisoning attack, a popular protocol to benchmark model robustness under adversarial scenarios, is under-explored. Data poisoning attacks have been developed for classical fair machine learning methods which incorporate fairness constraints into shallow-model classifiers. Nonetheless, these attacks fall short in FRL due to notably different fairness goals and model architectures. This work proposes the first data poisoning framework attacking FRL. We induce the model to output unfair representations that contain as much demographic information as possible by injecting carefully crafted poisoning samples into the training data. This attack entails a prohibitive bilevel optimization, wherefore an effective approximated solution is proposed. A theoretical analysis on the needed number of poisoning samples is derived and sheds light on defending against the attack. Experiments on benchmark fairness datasets and state-of-the-art fair representation learning models demonstrate the superiority of our attack.
Prompt-Enhanced Self-supervised Representation Learning for Remote Sensing Image Understanding
Sep 28, 2023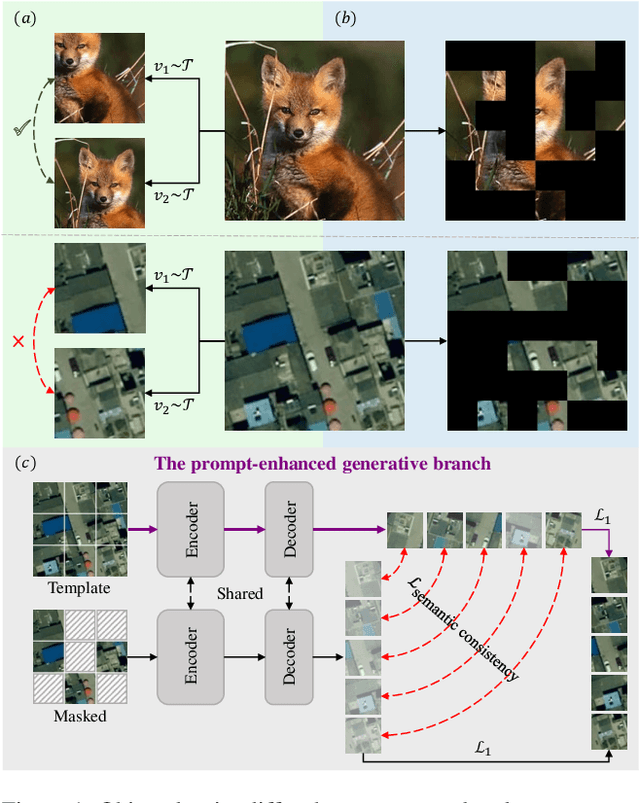
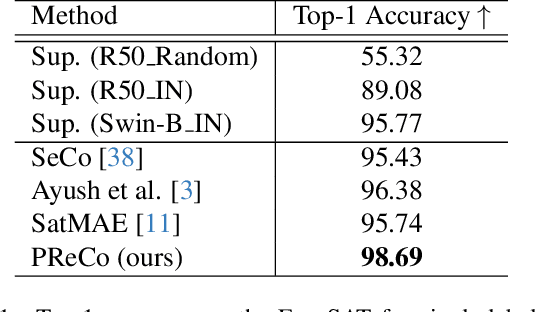
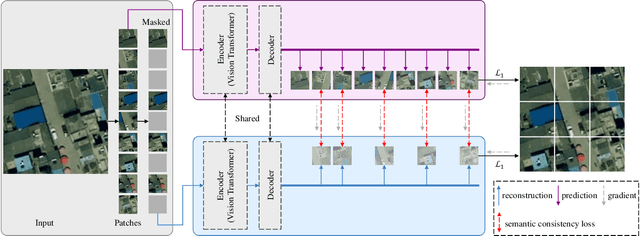
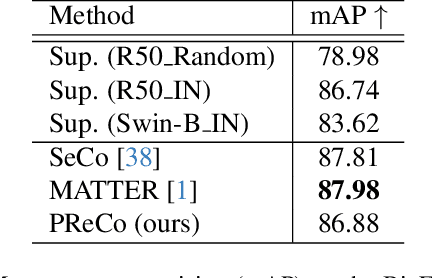
Learning representations through self-supervision on a large-scale, unlabeled dataset has proven to be highly effective for understanding diverse images, such as those used in remote sensing image analysis. However, remote sensing images often have complex and densely populated scenes, with multiple land objects and no clear foreground objects. This intrinsic property can lead to false positive pairs in contrastive learning, or missing contextual information in reconstructive learning, which can limit the effectiveness of existing self-supervised learning methods. To address these problems, we propose a prompt-enhanced self-supervised representation learning method that uses a simple yet efficient pre-training pipeline. Our approach involves utilizing original image patches as a reconstructive prompt template, and designing a prompt-enhanced generative branch that provides contextual information through semantic consistency constraints. We collected a dataset of over 1.28 million remote sensing images that is comparable to the popular ImageNet dataset, but without specific temporal or geographical constraints. Our experiments show that our method outperforms fully supervised learning models and state-of-the-art self-supervised learning methods on various downstream tasks, including land cover classification, semantic segmentation, object detection, and instance segmentation. These results demonstrate that our approach learns impressive remote sensing representations with high generalization and transferability.
Reversing Deep Face Embeddings with Probable Privacy Protection
Oct 04, 2023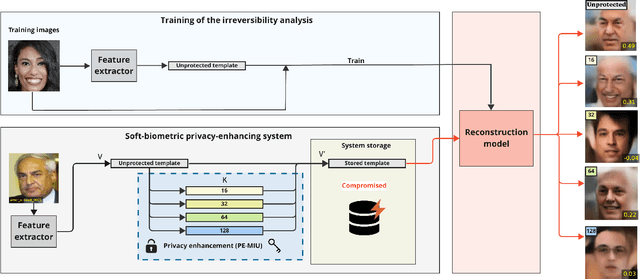
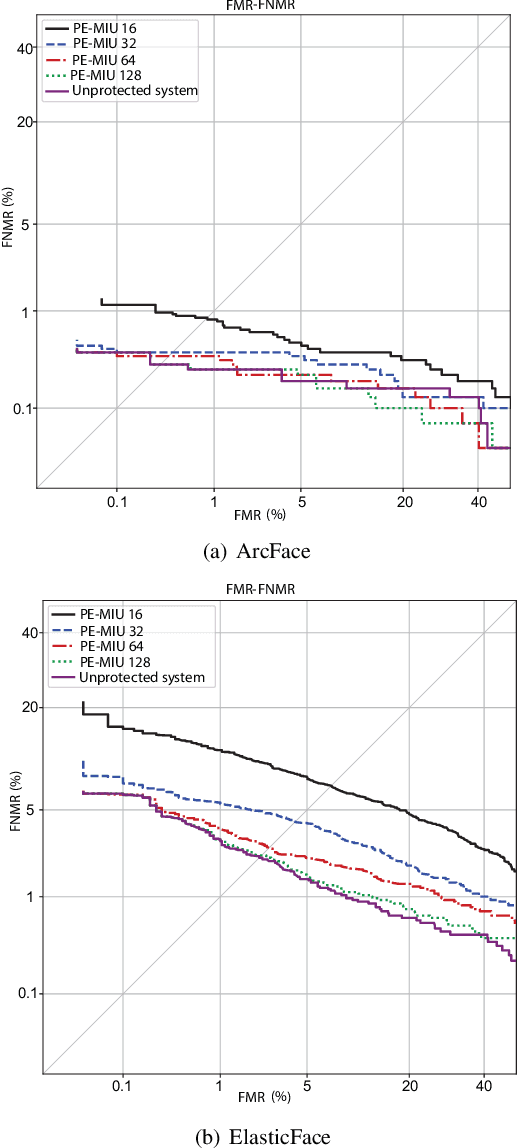

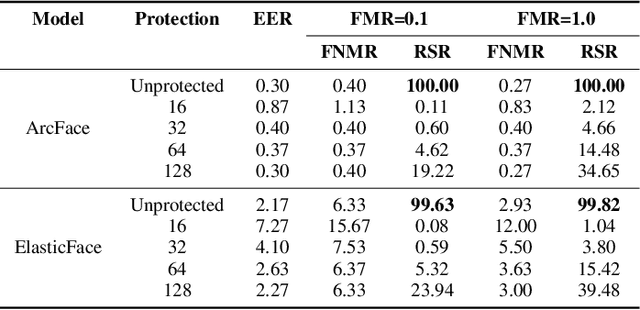
Generally, privacy-enhancing face recognition systems are designed to offer permanent protection of face embeddings. Recently, so-called soft-biometric privacy-enhancement approaches have been introduced with the aim of canceling soft-biometric attributes. These methods limit the amount of soft-biometric information (gender or skin-colour) that can be inferred from face embeddings. Previous work has underlined the need for research into rigorous evaluations and standardised evaluation protocols when assessing privacy protection capabilities. Motivated by this fact, this paper explores to what extent the non-invertibility requirement can be met by methods that claim to provide soft-biometric privacy protection. Additionally, a detailed vulnerability assessment of state-of-the-art face embedding extractors is analysed in terms of the transformation complexity used for privacy protection. In this context, a well-known state-of-the-art face image reconstruction approach has been evaluated on protected face embeddings to break soft biometric privacy protection. Experimental results show that biometric privacy-enhanced face embeddings can be reconstructed with an accuracy of up to approximately 98%, depending on the complexity of the protection algorithm.
R-LGP: A Reachability-guided Logic-geometric Programming Framework for Optimal Task and Motion Planning on Mobile Manipulators
Oct 04, 2023This paper presents an optimization-based solution to task and motion planning (TAMP) on mobile manipulators. Logic-geometric programming (LGP) has shown promising capabilities for optimally dealing with hybrid TAMP problems that involve abstract and geometric constraints. However, LGP does not scale well to high-dimensional systems (e.g. mobile manipulators) and can suffer from obstacle avoidance issues. In this work, we extend LGP with a sampling-based reachability graph to enable solving optimal TAMP on high-DoF mobile manipulators. The proposed reachability graph can incorporate environmental information (obstacles) to provide the planner with sufficient geometric constraints. This reachability-aware heuristic efficiently prunes infeasible sequences of actions in the continuous domain, hence, it reduces replanning by securing feasibility at the final full trajectory optimization. Our framework proves to be time-efficient in computing optimal and collision-free solutions, while outperforming the current state of the art on metrics of success rate, planning time, path length and number of steps. We validate our framework on the physical Toyota HSR robot and report comparisons on a series of mobile manipulation tasks of increasing difficulty.
Gradient Descent Provably Solves Nonlinear Tomographic Reconstruction
Oct 06, 2023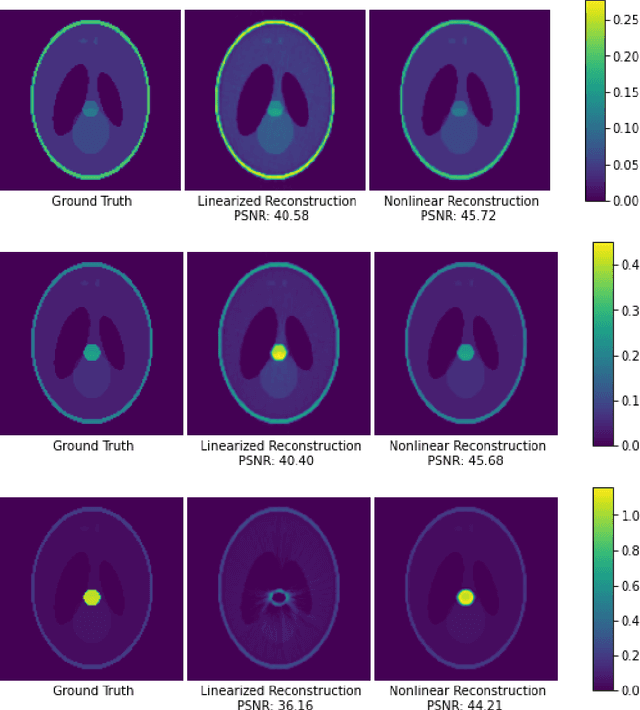
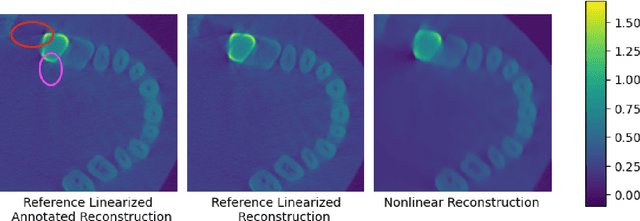
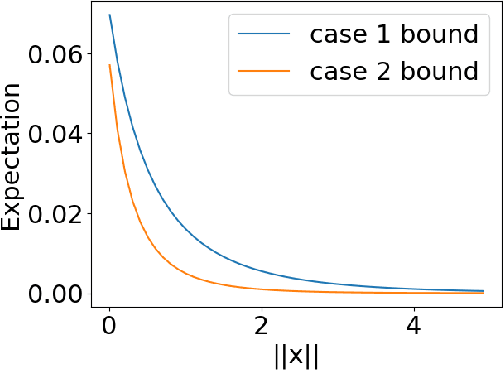
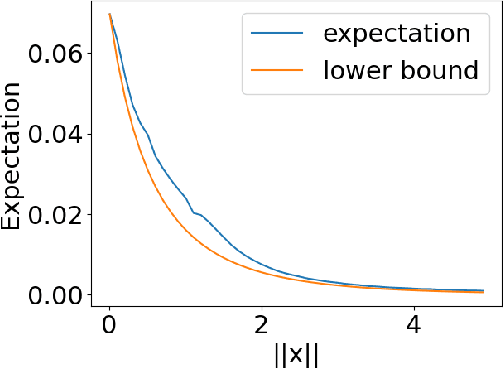
In computed tomography (CT), the forward model consists of a linear Radon transform followed by an exponential nonlinearity based on the attenuation of light according to the Beer-Lambert Law. Conventional reconstruction often involves inverting this nonlinearity as a preprocessing step and then solving a convex inverse problem. However, this nonlinear measurement preprocessing required to use the Radon transform is poorly conditioned in the vicinity of high-density materials, such as metal. This preprocessing makes CT reconstruction methods numerically sensitive and susceptible to artifacts near high-density regions. In this paper, we study a technique where the signal is directly reconstructed from raw measurements through the nonlinear forward model. Though this optimization is nonconvex, we show that gradient descent provably converges to the global optimum at a geometric rate, perfectly reconstructing the underlying signal with a near minimal number of random measurements. We also prove similar results in the under-determined setting where the number of measurements is significantly smaller than the dimension of the signal. This is achieved by enforcing prior structural information about the signal through constraints on the optimization variables. We illustrate the benefits of direct nonlinear CT reconstruction with cone-beam CT experiments on synthetic and real 3D volumes. We show that this approach reduces metal artifacts compared to a commercial reconstruction of a human skull with metal dental crowns.
From Zero to Hero: Detecting Leaked Data through Synthetic Data Injection and Model Querying
Oct 06, 2023
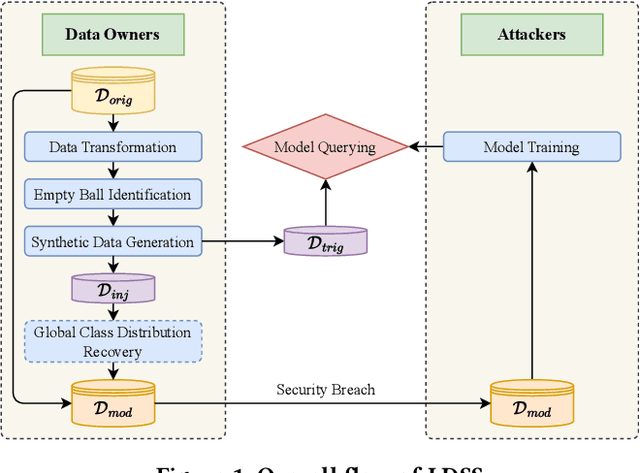
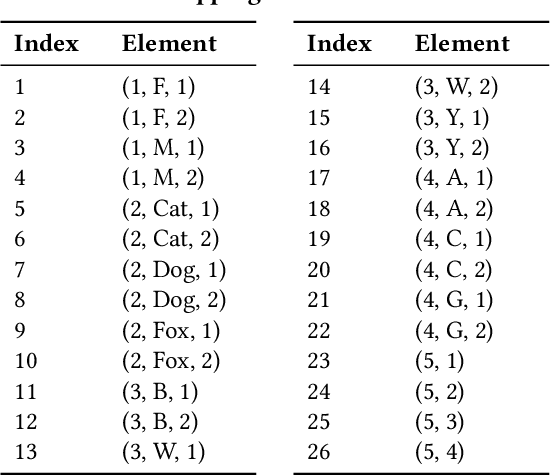
Safeguarding the Intellectual Property (IP) of data has become critically important as machine learning applications continue to proliferate, and their success heavily relies on the quality of training data. While various mechanisms exist to secure data during storage, transmission, and consumption, fewer studies have been developed to detect whether they are already leaked for model training without authorization. This issue is particularly challenging due to the absence of information and control over the training process conducted by potential attackers. In this paper, we concentrate on the domain of tabular data and introduce a novel methodology, Local Distribution Shifting Synthesis (\textsc{LDSS}), to detect leaked data that are used to train classification models. The core concept behind \textsc{LDSS} involves injecting a small volume of synthetic data--characterized by local shifts in class distribution--into the owner's dataset. This enables the effective identification of models trained on leaked data through model querying alone, as the synthetic data injection results in a pronounced disparity in the predictions of models trained on leaked and modified datasets. \textsc{LDSS} is \emph{model-oblivious} and hence compatible with a diverse range of classification models, such as Naive Bayes, Decision Tree, and Random Forest. We have conducted extensive experiments on seven types of classification models across five real-world datasets. The comprehensive results affirm the reliability, robustness, fidelity, security, and efficiency of \textsc{LDSS}.
Perfect Alignment May be Poisonous to Graph Contrastive Learning
Oct 06, 2023Graph Contrastive Learning (GCL) aims to learn node representations by aligning positive pairs and separating negative ones. However, limited research has been conducted on the inner law behind specific augmentations used in graph-based learning. What kind of augmentation will help downstream performance, how does contrastive learning actually influence downstream tasks, and why the magnitude of augmentation matters? This paper seeks to address these questions by establishing a connection between augmentation and downstream performance, as well as by investigating the generalization of contrastive learning. Our findings reveal that GCL contributes to downstream tasks mainly by separating different classes rather than gathering nodes of the same class. So perfect alignment and augmentation overlap which draw all intra-class samples the same can not explain the success of contrastive learning. Then in order to comprehend how augmentation aids the contrastive learning process, we conduct further investigations into its generalization, finding that perfect alignment that draw positive pair the same could help contrastive loss but is poisonous to generalization, on the contrary, imperfect alignment enhances the model's generalization ability. We analyse the result by information theory and graph spectrum theory respectively, and propose two simple but effective methods to verify the theories. The two methods could be easily applied to various GCL algorithms and extensive experiments are conducted to prove its effectiveness.
A privacy-preserving method using secret key for convolutional neural network-based speech classification
Oct 06, 2023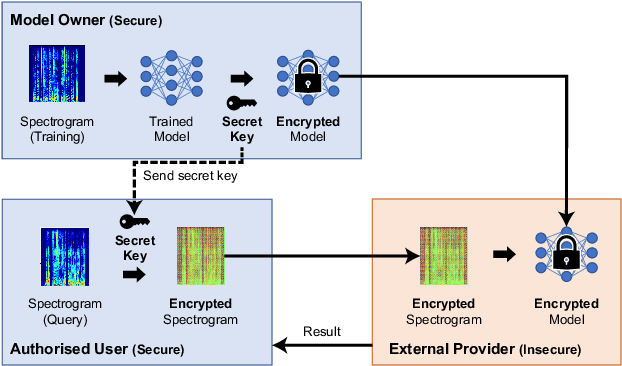
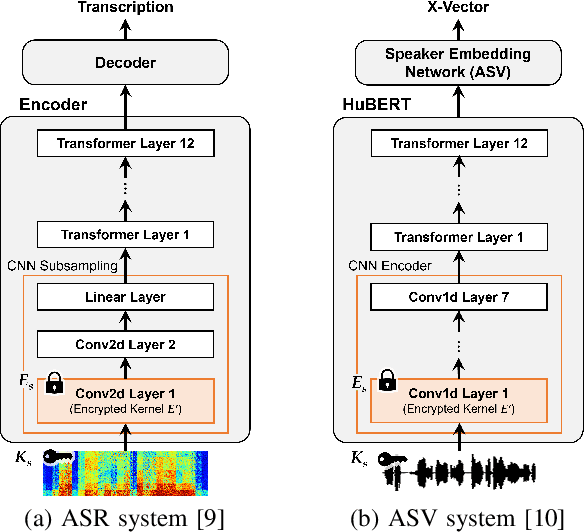
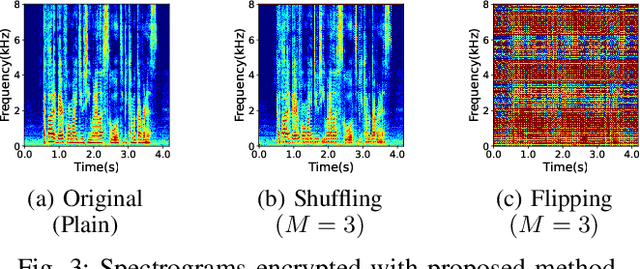
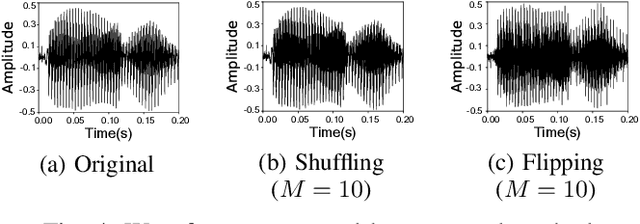
In this paper, we propose a privacy-preserving method with a secret key for convolutional neural network (CNN)-based speech classification tasks. Recently, many methods related to privacy preservation have been developed in image classification research fields. In contrast, in speech classification research fields, little research has considered these risks. To promote research on privacy preservation for speech classification, we provide an encryption method with a secret key in CNN-based speech classification systems. The encryption method is based on a random matrix with an invertible inverse. The encrypted speech data with a correct key can be accepted by a model with an encrypted kernel generated using an inverse matrix of a random matrix. Whereas the encrypted speech data is strongly distorted, the classification tasks can be correctly performed when a correct key is provided. Additionally, in this paper, we evaluate the difficulty of reconstructing the original information from the encrypted spectrograms and waveforms. In our experiments, the proposed encryption methods are performed in automatic speech recognition~(ASR) and automatic speaker verification~(ASV) tasks. The results show that the encrypted data can be used completely the same as the original data when a correct secret key is provided in the transformer-based ASR and x-vector-based ASV with self-supervised front-end systems. The robustness of the encrypted data against reconstruction attacks is also illustrated.
SlotGNN: Unsupervised Discovery of Multi-Object Representations and Visual Dynamics
Oct 06, 2023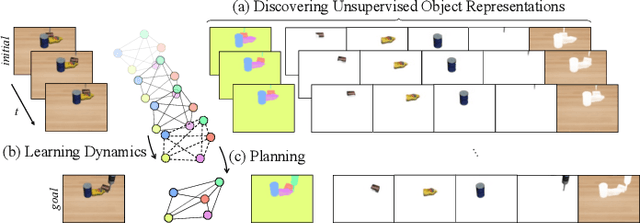

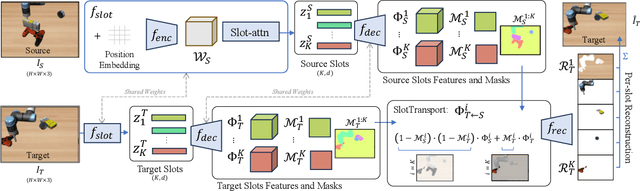
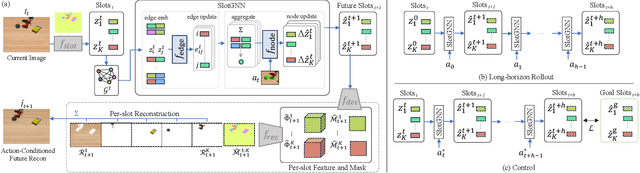
Learning multi-object dynamics from visual data using unsupervised techniques is challenging due to the need for robust, object representations that can be learned through robot interactions. This paper presents a novel framework with two new architectures: SlotTransport for discovering object representations from RGB images and SlotGNN for predicting their collective dynamics from RGB images and robot interactions. Our SlotTransport architecture is based on slot attention for unsupervised object discovery and uses a feature transport mechanism to maintain temporal alignment in object-centric representations. This enables the discovery of slots that consistently reflect the composition of multi-object scenes. These slots robustly bind to distinct objects, even under heavy occlusion or absence. Our SlotGNN, a novel unsupervised graph-based dynamics model, predicts the future state of multi-object scenes. SlotGNN learns a graph representation of the scene using the discovered slots from SlotTransport and performs relational and spatial reasoning to predict the future appearance of each slot conditioned on robot actions. We demonstrate the effectiveness of SlotTransport in learning object-centric features that accurately encode both visual and positional information. Further, we highlight the accuracy of SlotGNN in downstream robotic tasks, including challenging multi-object rearrangement and long-horizon prediction. Finally, our unsupervised approach proves effective in the real world. With only minimal additional data, our framework robustly predicts slots and their corresponding dynamics in real-world control tasks.
Higher-Order DeepTrails: Unified Approach to *Trails
Oct 06, 2023Analyzing, understanding, and describing human behavior is advantageous in different settings, such as web browsing or traffic navigation. Understanding human behavior naturally helps to improve and optimize the underlying infrastructure or user interfaces. Typically, human navigation is represented by sequences of transitions between states. Previous work suggests to use hypotheses, representing different intuitions about the navigation to analyze these transitions. To mathematically grasp this setting, first-order Markov chains are used to capture the behavior, consequently allowing to apply different kinds of graph comparisons, but comes with the inherent drawback of losing information about higher-order dependencies within the sequences. To this end, we propose to analyze entire sequences using autoregressive language models, as they are traditionally used to model higher-order dependencies in sequences. We show that our approach can be easily adapted to model different settings introduced in previous work, namely HypTrails, MixedTrails and even SubTrails, while at the same time bringing unique advantages: 1. Modeling higher-order dependencies between state transitions, while 2. being able to identify short comings in proposed hypotheses, and 3. naturally introducing a unified approach to model all settings. To show the expressiveness of our approach, we evaluate our approach on different synthetic datasets and conclude with an exemplary analysis of a real-world dataset, examining the behavior of users who interact with voice assistants.