 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TMac: Temporal Multi-Modal Graph Learning for Acoustic Event Classification
Sep 21, 2023
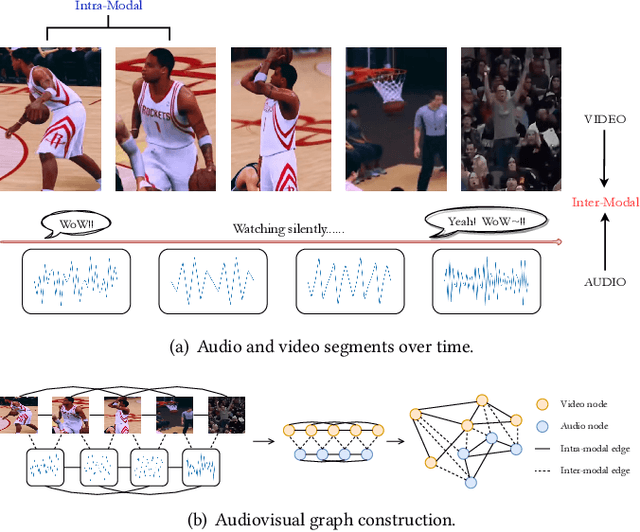

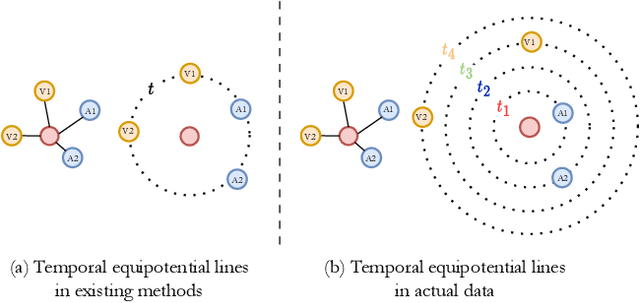
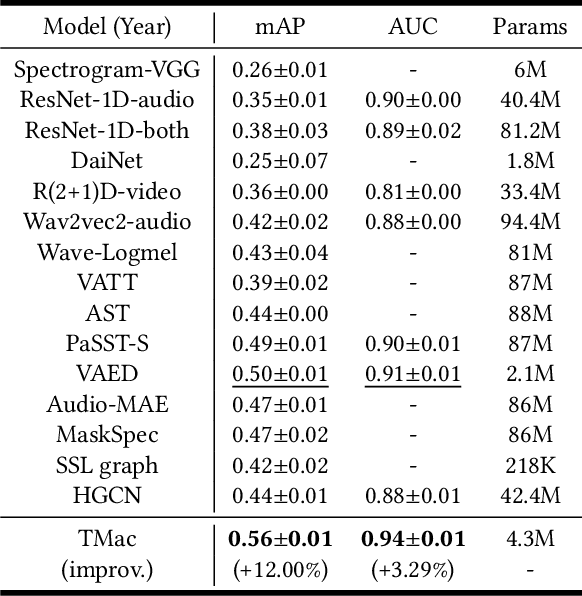
Audiovisual data is everywhere in this digital age, which raises higher requirements for the deep learning models developed on them. To well handle the information of the multi-modal data is the key to a better audiovisual modal. We observe that these audiovisual data naturally have temporal attributes, such as the time information for each frame in the video. More concretely, such data is inherently multi-modal according to both audio and visual cues, which proceed in a strict chronological order. It indicates that temporal information is important in multi-modal acoustic event modeling for both intra- and inter-modal. However, existing methods deal with each modal feature independently and simply fuse them together, which neglects the mining of temporal relation and thus leads to sub-optimal performance. With this motivation, we propose a Temporal Multi-modal graph learning method for Acoustic event Classification, called TMac, by modeling such temporal information via graph learning techniques. In particular, we construct a temporal graph for each acoustic event, dividing its audio data and video data into multiple segments. Each segment can be considered as a node, and the temporal relationships between nodes can be considered as timestamps on their edges. In this case, we can smoothly capture the dynamic information in intra-modal and inter-modal. Several experiments are conducted to demonstrate TMac outperforms other SOTA models in performance. Our code is available at https://github.com/MGitHubL/TMac.
Statistical CSI Based Beamforming for Reconfigurable Intelligent Surface Aided MISO Systems with Channel Correlation
Sep 27, 2023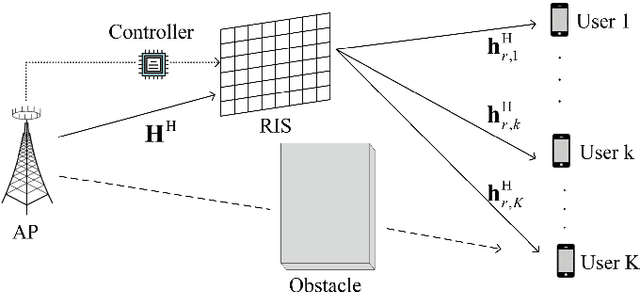
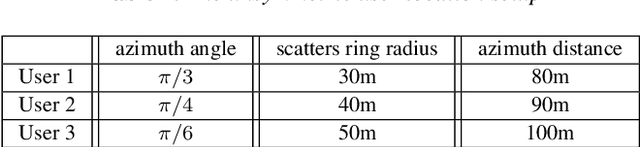
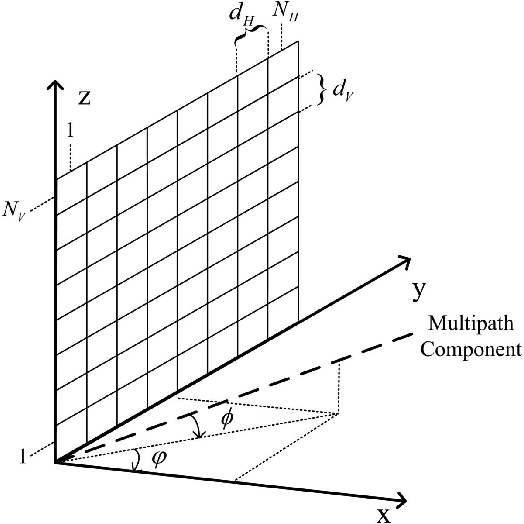
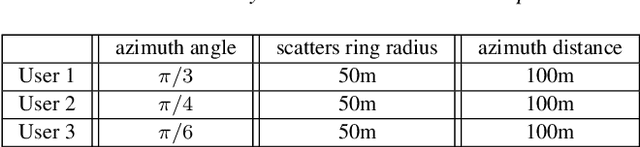
Reconfigurable intelligent surface (RIS) is a promising candidate technology of the upcoming Sixth Generation (6G) communication system for its ability to provide unprecedented spectral and energy efficiency increment through passive beamforming. However, it is challenging to obtain instantaneous channel state information (I-CSI) for RIS, which obliges us to use statistical channel state information (S-CSI) to achieve passive beamforming. In this paper, RIS-aided multiple-input single-output (MISO) multi-user downlink communication system with correlated channels is investigated. Then, we formulate the problem of joint beamforming design at the AP and RIS to maximize the sum ergodic spectral efficiency (ESE) of all users to improve the network capacity. Since it is too hard to compute sum ESE, an ESE approximation is adopted to reformulate the problem into a more tractable form. Then, we present two joint beamforming algorithms, namely the singular value decomposition-gradient descent (SVD-GD) algorithm and the fractional programming-gradient descent (FP-GD) algorithm. Simulation results show the effectiveness of our proposed algorithms and validate that 2-bits quantizer is enough for RIS phase shifts implementation.
Wavelet Scattering Transform for Improving Generalization in Low-Resourced Spoken Language Identification
Oct 03, 2023Commonly used features in spoken language identification (LID), such as mel-spectrogram or MFCC, lose high-frequency information due to windowing. The loss further increases for longer temporal contexts. To improve generalization of the low-resourced LID systems, we investigate an alternate feature representation, wavelet scattering transform (WST), that compensates for the shortcomings. To our knowledge, WST is not explored earlier in LID tasks. We first optimize WST features for multiple South Asian LID corpora. We show that LID requires low octave resolution and frequency-scattering is not useful. Further, cross-corpora evaluations show that the optimal WST hyper-parameters depend on both train and test corpora. Hence, we develop fused ECAPA-TDNN based LID systems with different sets of WST hyper-parameters to improve generalization for unknown data. Compared to MFCC, EER is reduced upto 14.05% and 6.40% for same-corpora and blind VoxLingua107 evaluations, respectively.
Implementation of hyperspectral inversion algorithms on FPGA: Hardware comparison using High Level Synthesis
Oct 03, 2023
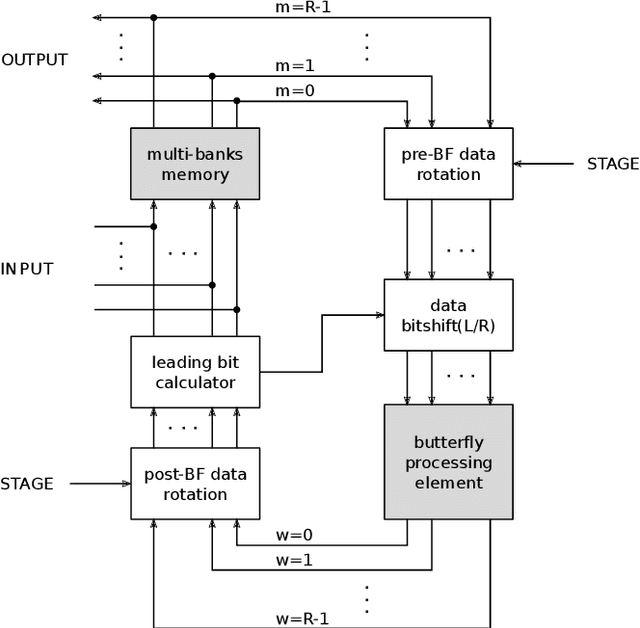
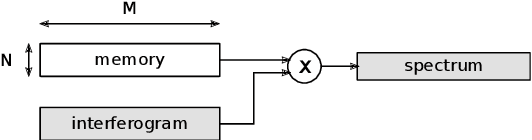
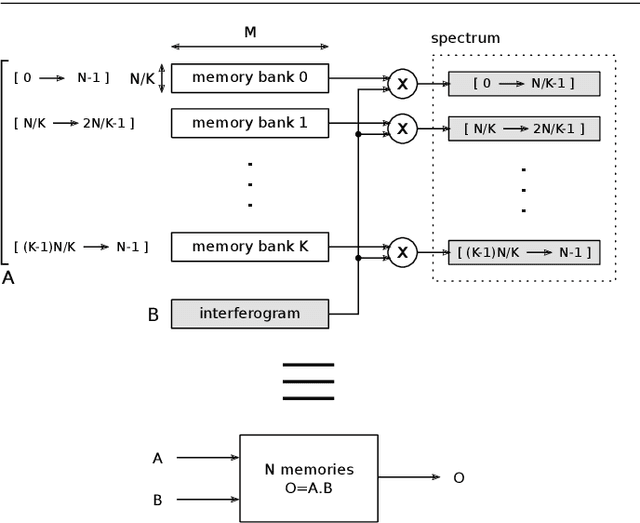
Hyperspectral imaging is gathering significant attention due to its potential in various domains such as geology, agriculture, ecology, and surveillance. However, the associated processing algorithms, which are essential for enhancing output quality and extracting relevant information, are often computationally intensive and have to deal with substantial data volumes. Our focus lies on reconfigurable hardware, particularly recent FPGAs. While FPGA design can be complex, High Level Synthesis (HLS) workflows have emerged as a solution, abstracting low-level design intricacies and enhancing productivity. Despite successful prior efforts using HLS for hyperspectral imaging acceleration, we lack a comprehensive research to benchmark various algorithms and architectures within a unified framework. This study aims to quantitatively evaluate performance across different inversion algorithms and design architectures, providing insights for optimal trade-offs for specific applications. We apply this analysis to the case study of spectrum reconstruction processed from interferometric acquisitions taken by Fourier transform spectrometers.
StructChart: Perception, Structuring, Reasoning for Visual Chart Understanding
Sep 20, 2023
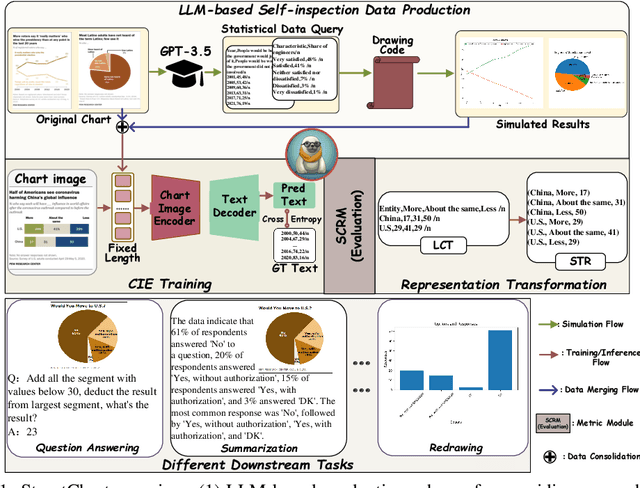
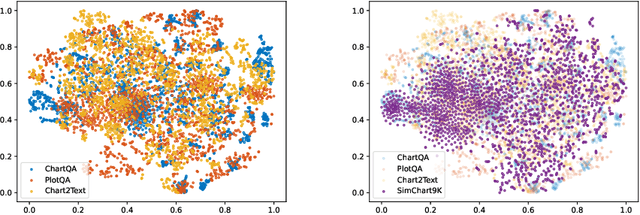
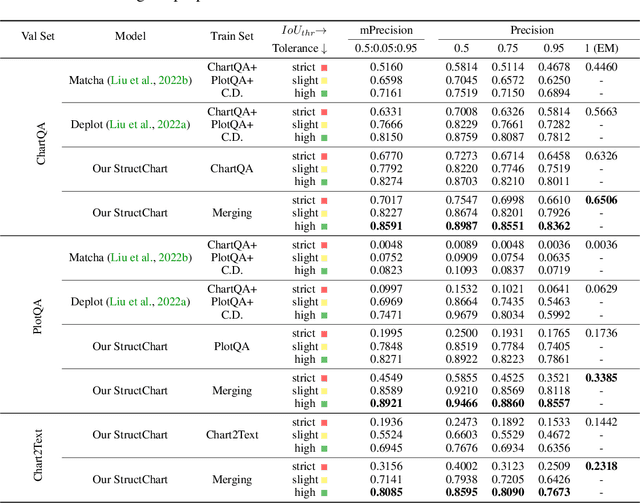
Charts are common in literature across different scientific fields, conveying rich information easily accessible to readers. Current chart-related tasks focus on either chart perception which refers to extracting information from the visual charts, or performing reasoning given the extracted data, e.g. in a tabular form. In this paper, we aim to establish a unified and label-efficient learning paradigm for joint perception and reasoning tasks, which can be generally applicable to different downstream tasks, beyond the question-answering task as specifically studied in peer works. Specifically, StructChart first reformulates the chart information from the popular tubular form (specifically linearized CSV) to the proposed Structured Triplet Representations (STR), which is more friendly for reducing the task gap between chart perception and reasoning due to the employed structured information extraction for charts. We then propose a Structuring Chart-oriented Representation Metric (SCRM) to quantitatively evaluate the performance for the chart perception task. To enrich the dataset for training, we further explore the possibility of leveraging the Large Language Model (LLM), enhancing the chart diversity in terms of both chart visual style and its statistical information. Extensive experiments are conducted on various chart-related tasks, demonstrating the effectiveness and promising potential for a unified chart perception-reasoning paradigm to push the frontier of chart understanding.
Multi-view Fuzzy Representation Learning with Rules based Model
Sep 20, 2023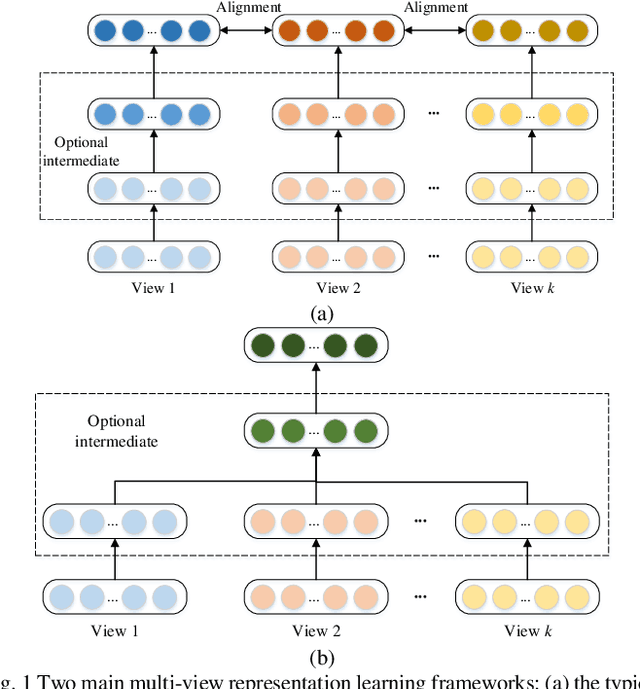
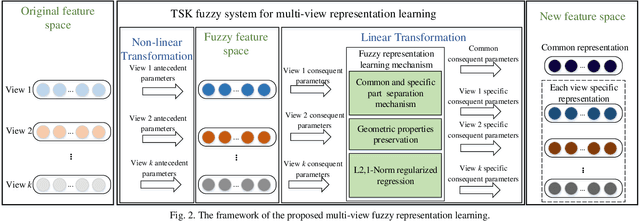
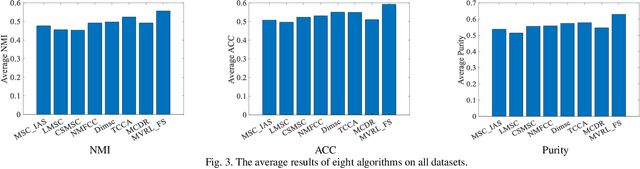
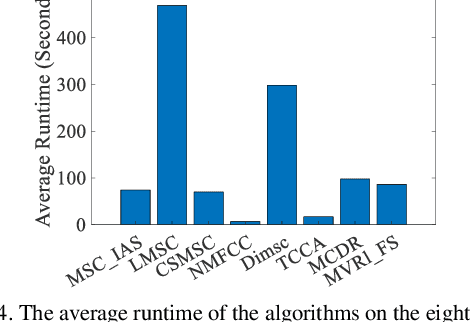
Unsupervised multi-view representation learning has been extensively studied for mining multi-view data. However, some critical challenges remain. On the one hand, the existing methods cannot explore multi-view data comprehensively since they usually learn a common representation between views, given that multi-view data contains both the common information between views and the specific information within each view. On the other hand, to mine the nonlinear relationship between data, kernel or neural network methods are commonly used for multi-view representation learning. However, these methods are lacking in interpretability. To this end, this paper proposes a new multi-view fuzzy representation learning method based on the interpretable Takagi-Sugeno-Kang (TSK) fuzzy system (MVRL_FS). The method realizes multi-view representation learning from two aspects. First, multi-view data are transformed into a high-dimensional fuzzy feature space, while the common information between views and specific information of each view are explored simultaneously. Second, a new regularization method based on L_(2,1)-norm regression is proposed to mine the consistency information between views, while the geometric structure of the data is preserved through the Laplacian graph. Finally, extensive experiments on many benchmark multi-view datasets are conducted to validate the superiority of the proposed method.
The Role of Early Sampling in Age of Information Minimization in the Presence of ACK Delays
Aug 15, 2023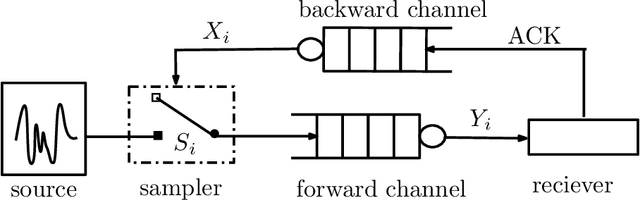

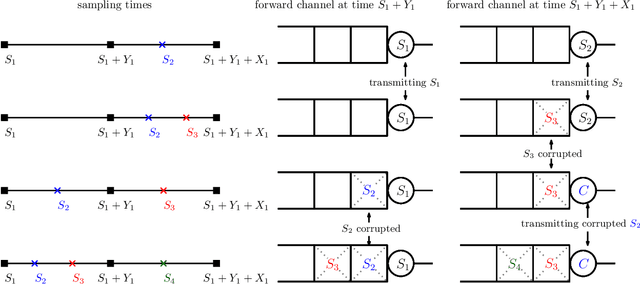
We study the structure of the optimal sampling policy to minimize the average age of information when the channel state (i.e., busy or idle) is not immediately perceived by the transmitter upon the delivery of a sample due to random delays in the feedback (ACK) channel. In this setting, we show that it is not always optimal to wait for ACKs before sampling, and thus, early sampling before the arrival of an ACK may be optimal. We show that, under certain conditions on the distribution of the ACK delays, the optimal policy is a mixture of two threshold policies.
LSOR: Longitudinally-Consistent Self-Organized Representation Learning
Sep 30, 2023Interpretability is a key issue when applying deep learning models to longitudinal brain MRIs. One way to address this issue is by visualizing the high-dimensional latent spaces generated by deep learning via self-organizing maps (SOM). SOM separates the latent space into clusters and then maps the cluster centers to a discrete (typically 2D) grid preserving the high-dimensional relationship between clusters. However, learning SOM in a high-dimensional latent space tends to be unstable, especially in a self-supervision setting. Furthermore, the learned SOM grid does not necessarily capture clinically interesting information, such as brain age. To resolve these issues, we propose the first self-supervised SOM approach that derives a high-dimensional, interpretable representation stratified by brain age solely based on longitudinal brain MRIs (i.e., without demographic or cognitive information). Called Longitudinally-consistent Self-Organized Representation learning (LSOR), the method is stable during training as it relies on soft clustering (vs. the hard cluster assignments used by existing SOM). Furthermore, our approach generates a latent space stratified according to brain age by aligning trajectories inferred from longitudinal MRIs to the reference vector associated with the corresponding SOM cluster. When applied to longitudinal MRIs of the Alzheimer's Disease Neuroimaging Initiative (ADNI, N=632), LSOR generates an interpretable latent space and achieves comparable or higher accuracy than the state-of-the-art representations with respect to the downstream tasks of classification (static vs. progressive mild cognitive impairment) and regression (determining ADAS-Cog score of all subjects). The code is available at https://github.com/ouyangjiahong/longitudinal-som-single-modality.
On the Sweet Spot of Contrastive Views for Knowledge-enhanced Recommendation
Sep 23, 2023In recommender systems, knowledge graph (KG) can offer critical information that is lacking in the original user-item interaction graph (IG). Recent process has explored this direction and shows that contrastive learning is a promising way to integrate both. However, we observe that existing KG-enhanced recommenders struggle in balancing between the two contrastive views of IG and KG, making them sometimes even less effective than simply applying contrastive learning on IG without using KG. In this paper, we propose a new contrastive learning framework for KG-enhanced recommendation. Specifically, to make full use of the knowledge, we construct two separate contrastive views for KG and IG, and maximize their mutual information; to ease the contrastive learning on the two views, we further fuse KG information into IG in a one-direction manner.Extensive experimental results on three real-world datasets demonstrate the effectiveness and efficiency of our method, compared to the state-of-the-art. Our code is available through the anonymous link:https://figshare.com/articles/conference_contribution/SimKGCL/22783382
Reducing Information Loss for Spiking Neural Networks
Jul 10, 2023
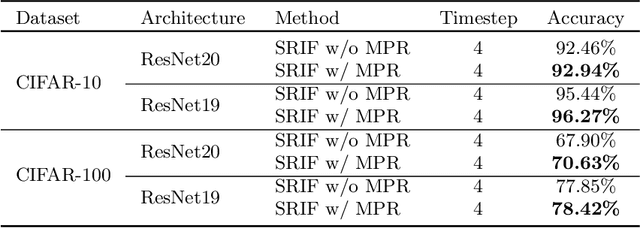
The Spiking Neural Network (SNN) has attracted more and more attention recently. It adopts binary spike signals to transmit information. Benefitting from the information passing paradigm of SNNs, the multiplications of activations and weights can be replaced by additions, which are more energy-efficient. However, its ``Hard Reset" mechanism for the firing activity would ignore the difference among membrane potentials when the membrane potential is above the firing threshold, causing information loss. Meanwhile, quantifying the membrane potential to 0/1 spikes at the firing instants will inevitably introduce the quantization error thus bringing about information loss too. To address these problems, we propose to use the ``Soft Reset" mechanism for the supervised training-based SNNs, which will drive the membrane potential to a dynamic reset potential according to its magnitude, and Membrane Potential Rectifier (MPR) to reduce the quantization error via redistributing the membrane potential to a range close to the spikes. Results show that the SNNs with the ``Soft Reset" mechanism and MPR outperform their vanilla counterparts on both static and dynamic datasets.