 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Bivariate Estimation-of-Distribution Algorithms Can Find an Exponential Number of Optima
Oct 06, 2023
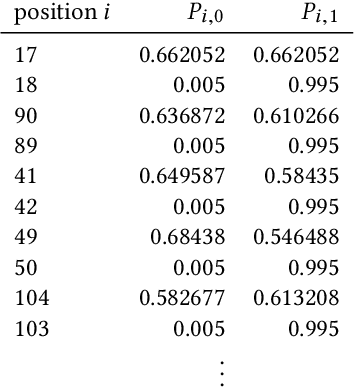
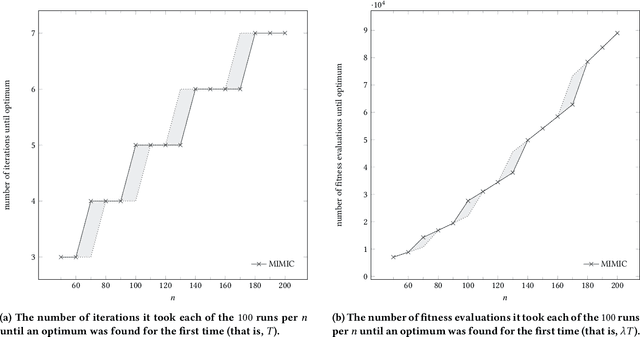
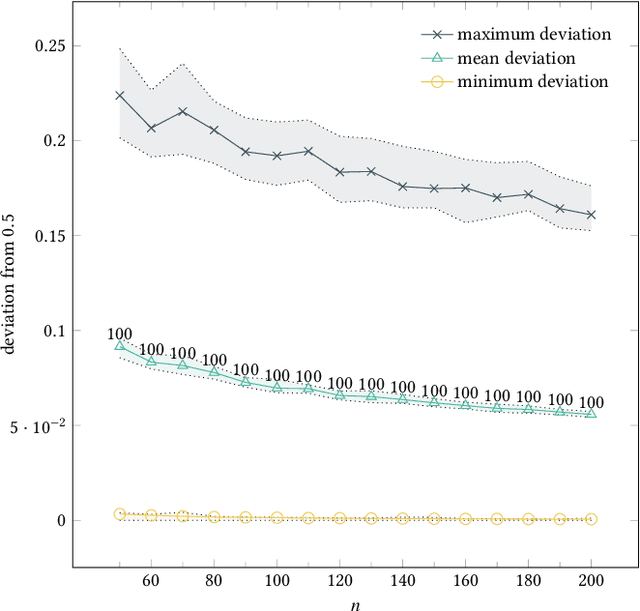
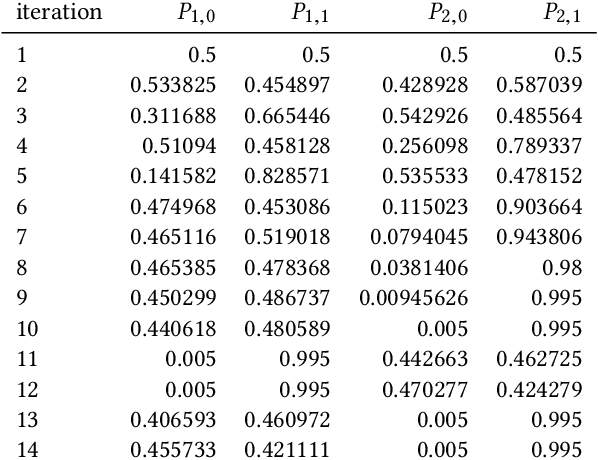
Finding a large set of optima in a multimodal optimization landscape is a challenging task. Classical population-based evolutionary algorithms typically converge only to a single solution. While this can be counteracted by applying niching strategies, the number of optima is nonetheless trivially bounded by the population size. Estimation-of-distribution algorithms (EDAs) are an alternative, maintaining a probabilistic model of the solution space instead of a population. Such a model is able to implicitly represent a solution set far larger than any realistic population size. To support the study of how optimization algorithms handle large sets of optima, we propose the test function EqualBlocksOneMax (EBOM). It has an easy fitness landscape with exponentially many optima. We show that the bivariate EDA mutual-information-maximizing input clustering, without any problem-specific modification, quickly generates a model that behaves very similarly to a theoretically ideal model for EBOM, which samples each of the exponentially many optima with the same maximal probability. We also prove via mathematical means that no univariate model can come close to having this property: If the probability to sample an optimum is at least inverse-polynomial, there is a Hamming ball of logarithmic radius such that, with high probability, each sample is in this ball.
A Plug-and-Play Image Registration Network
Oct 06, 2023Deformable image registration (DIR) is an active research topic in biomedical imaging. There is a growing interest in developing DIR methods based on deep learning (DL). A traditional DL approach to DIR is based on training a convolutional neural network (CNN) to estimate the registration field between two input images. While conceptually simple, this approach comes with a limitation that it exclusively relies on a pre-trained CNN without explicitly enforcing fidelity between the registered image and the reference. We present plug-and-play image registration network (PIRATE) as a new DIR method that addresses this issue by integrating an explicit data-fidelity penalty and a CNN prior. PIRATE pre-trains a CNN denoiser on the registration field and "plugs" it into an iterative method as a regularizer. We additionally present PIRATE+ that fine-tunes the CNN prior in PIRATE using deep equilibrium models (DEQ). PIRATE+ interprets the fixed-point iteration of PIRATE as a network with effectively infinite layers and then trains the resulting network end-to-end, enabling it to learn more task-specific information and boosting its performance. Our numerical results on OASIS and CANDI datasets show that our methods achieve state-of-the-art performance on DIR.
A 5' UTR Language Model for Decoding Untranslated Regions of mRNA and Function Predictions
Oct 06, 2023The 5' UTR, a regulatory region at the beginning of an mRNA molecule, plays a crucial role in regulating the translation process and impacts the protein expression level. Language models have showcased their effectiveness in decoding the functions of protein and genome sequences. Here, we introduced a language model for 5' UTR, which we refer to as the UTR-LM. The UTR-LM is pre-trained on endogenous 5' UTRs from multiple species and is further augmented with supervised information including secondary structure and minimum free energy. We fine-tuned the UTR-LM in a variety of downstream tasks. The model outperformed the best-known benchmark by up to 42% for predicting the Mean Ribosome Loading, and by up to 60% for predicting the Translation Efficiency and the mRNA Expression Level. The model also applies to identifying unannotated Internal Ribosome Entry Sites within the untranslated region and improves the AUPR from 0.37 to 0.52 compared to the best baseline. Further, we designed a library of 211 novel 5' UTRs with high predicted values of translation efficiency and evaluated them via a wet-lab assay. Experiment results confirmed that our top designs achieved a 32.5% increase in protein production level relative to well-established 5' UTR optimized for therapeutics.
Universal Humanoid Motion Representations for Physics-Based Control
Oct 06, 2023
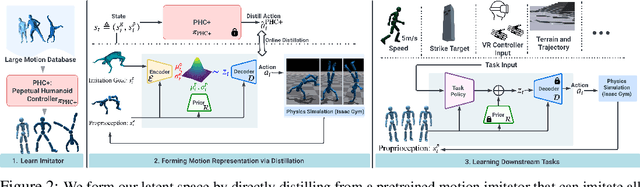
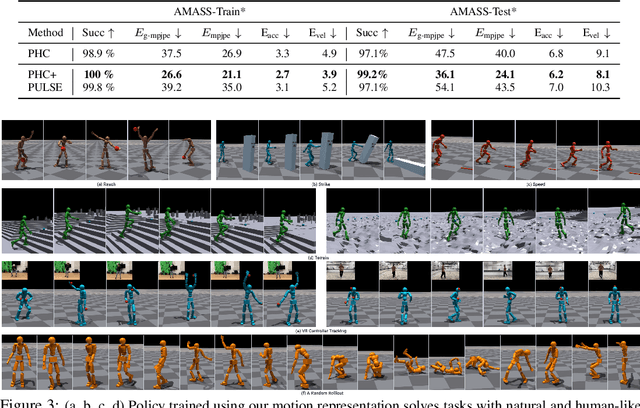

We present a universal motion representation that encompasses a comprehensive range of motor skills for physics-based humanoid control. Due to the high-dimensionality of humanoid control as well as the inherent difficulties in reinforcement learning, prior methods have focused on learning skill embeddings for a narrow range of movement styles (e.g. locomotion, game characters) from specialized motion datasets. This limited scope hampers its applicability in complex tasks. Our work closes this gap, significantly increasing the coverage of motion representation space. To achieve this, we first learn a motion imitator that can imitate all of human motion from a large, unstructured motion dataset. We then create our motion representation by distilling skills directly from the imitator. This is achieved using an encoder-decoder structure with a variational information bottleneck. Additionally, we jointly learn a prior conditioned on proprioception (humanoid's own pose and velocities) to improve model expressiveness and sampling efficiency for downstream tasks. Sampling from the prior, we can generate long, stable, and diverse human motions. Using this latent space for hierarchical RL, we show that our policies solve tasks using natural and realistic human behavior. We demonstrate the effectiveness of our motion representation by solving generative tasks (e.g. strike, terrain traversal) and motion tracking using VR controllers.
Communication-Aware Map Compression for Online Path-Planning
Sep 23, 2023This paper addresses the problem of the communication of optimally compressed information for mobile robot path-planning. In this context, mobile robots compress their current local maps to assist another robot in reaching a target in an unknown environment. We propose a framework that sequentially selects the optimal compression, guided by the robot's path, by balancing the map resolution and communication cost. Our approach is tractable in close-to-real scenarios and does not necessitate prior environment knowledge. We design a novel decoder that leverages compressed information to estimate the unknown environment via convex optimization with linear constraints and an encoder that utilizes the decoder to select the optimal compression. Numerical simulations are conducted in a large close-to-real map and a maze map and compared with two alternative approaches. The results confirm the effectiveness of our framework in assisting the robot reach its target by reducing transmitted information, on average, by approximately 50% while maintaining satisfactory performance.
CORE: Common Random Reconstruction for Distributed Optimization with Provable Low Communication Complexity
Sep 23, 2023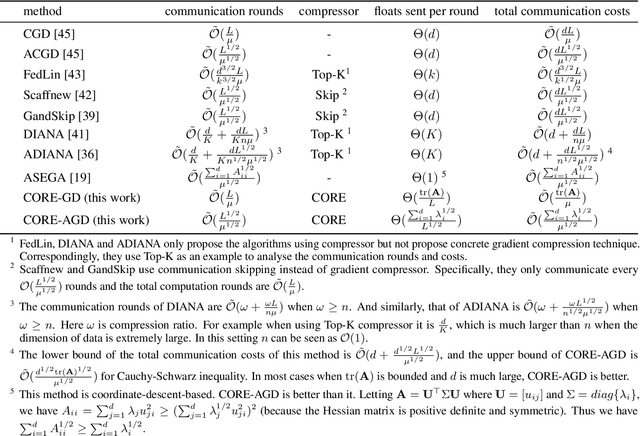
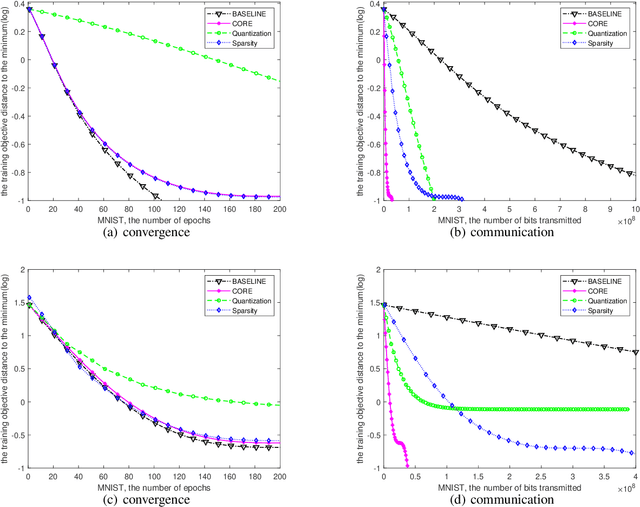
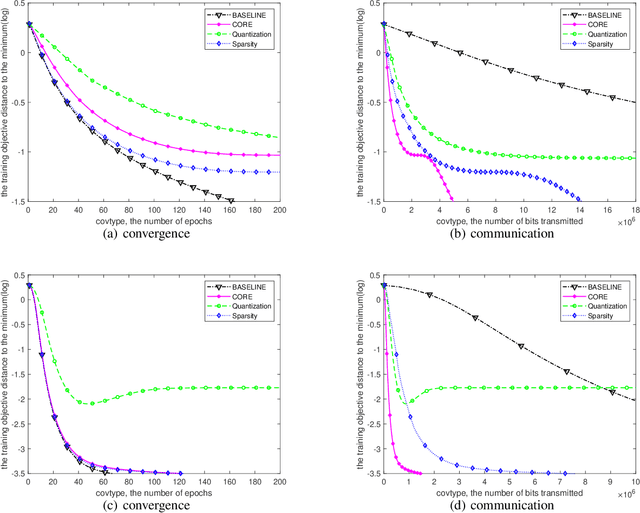
With distributed machine learning being a prominent technique for large-scale machine learning tasks, communication complexity has become a major bottleneck for speeding up training and scaling up machine numbers. In this paper, we propose a new technique named Common randOm REconstruction(CORE), which can be used to compress the information transmitted between machines in order to reduce communication complexity without other strict conditions. Especially, our technique CORE projects the vector-valued information to a low-dimensional one through common random vectors and reconstructs the information with the same random noises after communication. We apply CORE to two distributed tasks, respectively convex optimization on linear models and generic non-convex optimization, and design new distributed algorithms, which achieve provably lower communication complexities. For example, we show for linear models CORE-based algorithm can encode the gradient vector to $\mathcal{O}(1)$-bits (against $\mathcal{O}(d)$), with the convergence rate not worse, preceding the existing results.
Superimposed RIS-phase Modulation for MIMO Communications: A Novel Paradigm of Information Transfer
Aug 10, 2023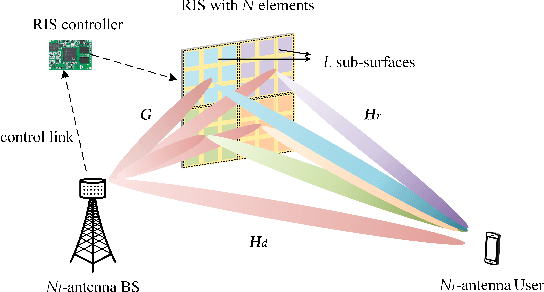
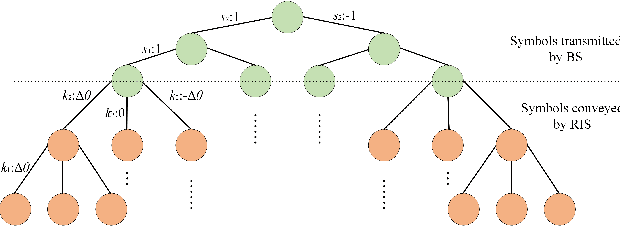
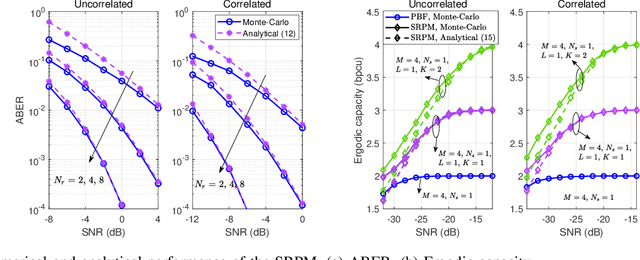
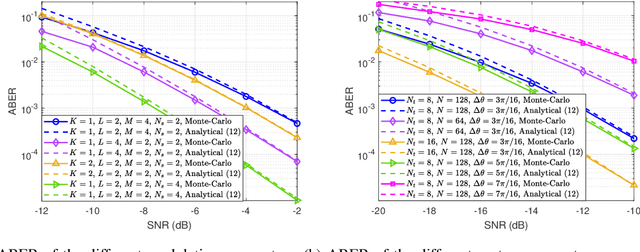
Reconfigurable intelligent surface (RIS) is regarded as an important enabling technology for the sixth-generation (6G) network. Recently, modulating information in reflection patterns of RIS, referred to as reflection modulation (RM), has been proven in theory to have the potential of achieving higher transmission rate than existing passive beamforming (PBF) schemes of RIS. To fully unlock this potential of RM, we propose a novel superimposed RIS-phase modulation (SRPM) scheme for multiple-input multiple-output (MIMO) systems, where tunable phase offsets are superimposed onto predetermined RIS phases to bear extra information messages. The proposed SRPM establishes a universal framework for RM, which retrieves various existing RM-based schemes as special cases. Moreover, the advantages and applicability of the SRPM in practice is also validated in theory by analytical characterization of its performance in terms of average bit error rate (ABER) and ergodic capacity. To maximize the performance gain, we formulate a general precoding optimization at the base station (BS) for a single-stream case with uncorrelated channels and obtain the optimal SRPM design via the semidefinite relaxation (SDR) technique. Furthermore, to avoid extremely high complexity in maximum likelihood (ML) detection for the SRPM, we propose a sphere decoding (SD)-based layered detection method with near-ML performance and much lower complexity. Numerical results demonstrate the effectiveness of SRPM, precoding optimization, and detection design. It is verified that the proposed SRPM achieves a higher diversity order than that of existing RM-based schemes and outperforms PBF significantly especially when the transmitter is equipped with limited radio-frequency (RF) chains.
SELF: Language-Driven Self-Evolution for Large Language Model
Oct 07, 2023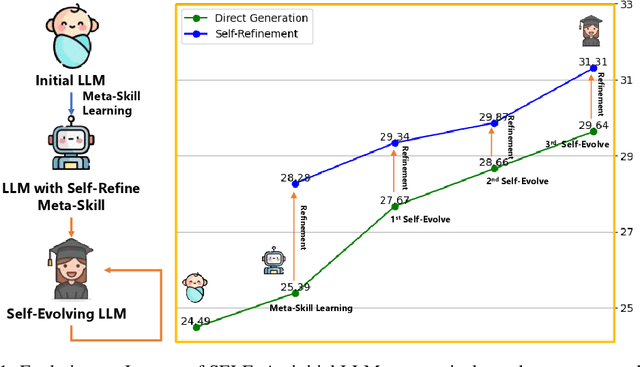
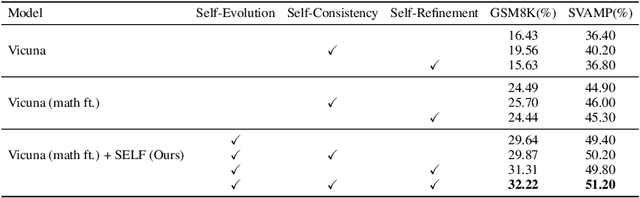
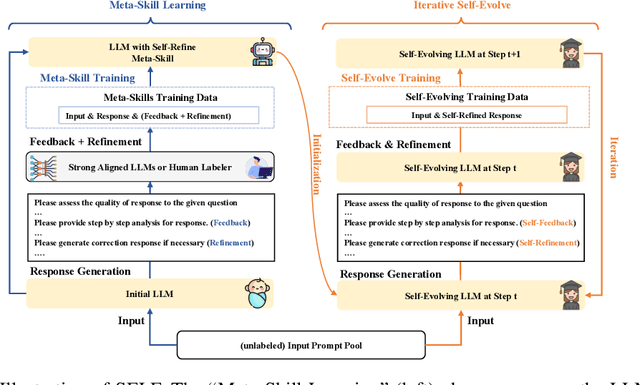

Large Language Models (LLMs) have showcased remarkable versatility across diverse domains. However, the pathway toward autonomous model development, a cornerstone for achieving human-level learning and advancing autonomous AI, remains largely uncharted. We introduce an innovative approach, termed "SELF" (Self-Evolution with Language Feedback). This methodology empowers LLMs to undergo continual self-evolution. Furthermore, SELF employs language-based feedback as a versatile and comprehensive evaluative tool, pinpointing areas for response refinement and bolstering the stability of self-evolutionary training. Initiating with meta-skill learning, SELF acquires foundational meta-skills with a focus on self-feedback and self-refinement. These meta-skills are critical, guiding the model's subsequent self-evolution through a cycle of perpetual training with self-curated data, thereby enhancing its intrinsic abilities. Given unlabeled instructions, SELF equips the model with the capability to autonomously generate and interactively refine responses. This synthesized training data is subsequently filtered and utilized for iterative fine-tuning, enhancing the model's capabilities. Experimental results on representative benchmarks substantiate that SELF can progressively advance its inherent abilities without the requirement of human intervention, thereby indicating a viable pathway for autonomous model evolution. Additionally, SELF can employ online self-refinement strategy to produce responses of superior quality. In essence, the SELF framework signifies a progressive step towards autonomous LLM development, transforming the LLM from a mere passive recipient of information into an active participant in its own evolution.
A Dual Latent State Learning Approach: Exploiting Regional Network Similarities for QoS Prediction
Oct 07, 2023Individual objects, whether users or services, within a specific region often exhibit similar network states due to their shared origin from the same city or autonomous system (AS). Despite this regional network similarity, many existing techniques overlook its potential, resulting in subpar performance arising from challenges such as data sparsity and label imbalance. In this paper, we introduce the regional-based dual latent state learning network(R2SL), a novel deep learning framework designed to overcome the pitfalls of traditional individual object-based prediction techniques in Quality of Service (QoS) prediction. Unlike its predecessors, R2SL captures the nuances of regional network behavior by deriving two distinct regional network latent states: the city-network latent state and the AS-network latent state. These states are constructed utilizing aggregated data from common regions rather than individual object data. Furthermore, R2SL adopts an enhanced Huber loss function that adjusts its linear loss component, providing a remedy for prevalent label imbalance issues. To cap off the prediction process, a multi-scale perception network is leveraged to interpret the integrated feature map, a fusion of regional network latent features and other pertinent information, ultimately accomplishing the QoS prediction. Through rigorous testing on real-world QoS datasets, R2SL demonstrates superior performance compared to prevailing state-of-the-art methods. Our R2SL approach ushers in an innovative avenue for precise QoS predictions by fully harnessing the regional network similarities inherent in objects.
Cross-domain Robust Deepfake Bias Expansion Network for Face Forgery Detection
Oct 08, 2023The rapid advancement of deepfake technologies raises significant concerns about the security of face recognition systems. While existing methods leverage the clues left by deepfake techniques for face forgery detection, malicious users may intentionally manipulate forged faces to obscure the traces of deepfake clues and thereby deceive detection tools. Meanwhile, attaining cross-domain robustness for data-based methods poses a challenge due to potential gaps in the training data, which may not encompass samples from all relevant domains. Therefore, in this paper, we introduce a solution - a Cross-Domain Robust Bias Expansion Network (BENet) - designed to enhance face forgery detection. BENet employs an auto-encoder to reconstruct input faces, maintaining the invariance of real faces while selectively enhancing the difference between reconstructed fake faces and their original counterparts. This enhanced bias forms a robust foundation upon which dependable forgery detection can be built. To optimize the reconstruction results in BENet, we employ a bias expansion loss infused with contrastive concepts to attain the aforementioned objective. In addition, to further heighten the amplification of forged clues, BENet incorporates a Latent-Space Attention (LSA) module. This LSA module effectively captures variances in latent features between the auto-encoder's encoder and decoder, placing emphasis on inconsistent forgery-related information. Furthermore, BENet incorporates a cross-domain detector with a threshold to determine whether the sample belongs to a known distribution. The correction of classification results through the cross-domain detector enables BENet to defend against unknown deepfake attacks from cross-domain. Extensive experiments demonstrate the superiority of BENet compared with state-of-the-art methods in intra-database and cross-database evaluations.