 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
3D Reconstruction in Noisy Agricultural Environments: A Bayesian Optimization Perspective for View Planning
Sep 29, 2023

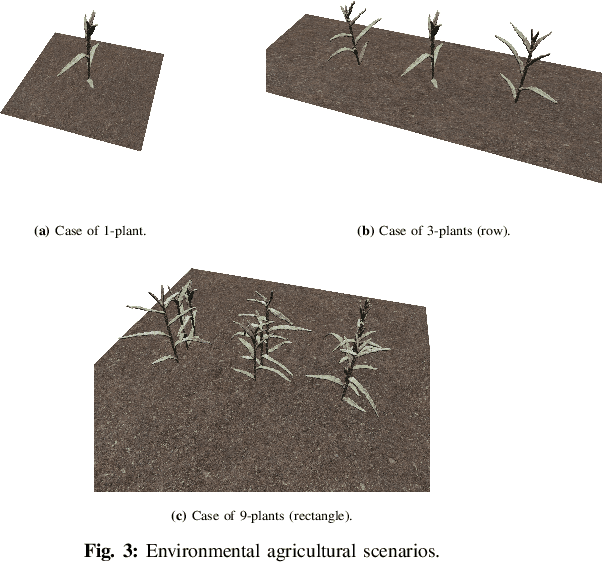
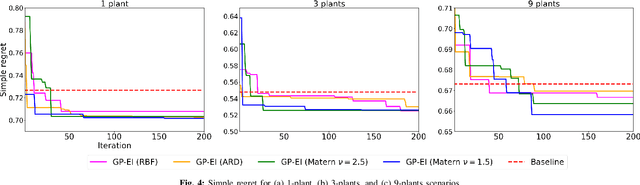
3D reconstruction is a fundamental task in robotics that gained attention due to its major impact in a wide variety of practical settings, including agriculture, underwater, and urban environments. An important approach for this task, known as view planning, is to judiciously place a number of cameras in positions that maximize the visual information improving the resulting 3D reconstruction. Circumventing the need for a large number of arbitrary images, geometric criteria can be applied to select fewer yet more informative images to markedly improve the 3D reconstruction performance. Nonetheless, incorporating the noise of the environment that exists in various real-world scenarios into these criteria may be challenging, particularly when prior information about the noise is not provided. To that end, this work advocates a novel geometric function that accounts for the existing noise, relying solely on a relatively small number of noise realizations without requiring its closed-form expression. With no analytic expression of the geometric function, this work puts forth a Bayesian optimization algorithm for accurate 3D reconstruction in the presence of noise. Numerical tests on noisy agricultural environments showcase the impressive merits of the proposed approach for 3D reconstruction with even a small number of available cameras.
Communication-Aware Map Compression for Online Path-Planning
Sep 23, 2023This paper addresses the problem of the communication of optimally compressed information for mobile robot path-planning. In this context, mobile robots compress their current local maps to assist another robot in reaching a target in an unknown environment. We propose a framework that sequentially selects the optimal compression, guided by the robot's path, by balancing the map resolution and communication cost. Our approach is tractable in close-to-real scenarios and does not necessitate prior environment knowledge. We design a novel decoder that leverages compressed information to estimate the unknown environment via convex optimization with linear constraints and an encoder that utilizes the decoder to select the optimal compression. Numerical simulations are conducted in a large close-to-real map and a maze map and compared with two alternative approaches. The results confirm the effectiveness of our framework in assisting the robot reach its target by reducing transmitted information, on average, by approximately 50% while maintaining satisfactory performance.
CORE: Common Random Reconstruction for Distributed Optimization with Provable Low Communication Complexity
Sep 23, 2023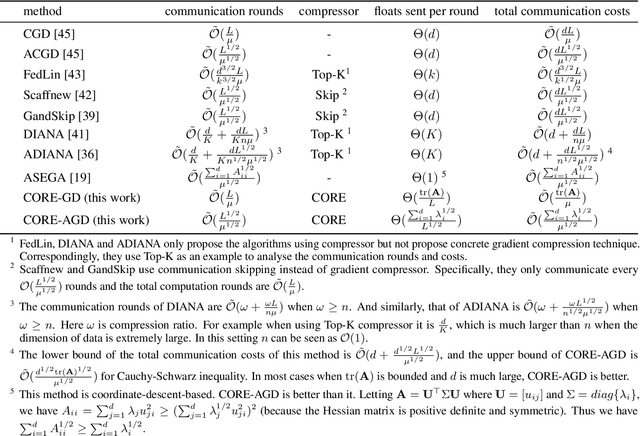
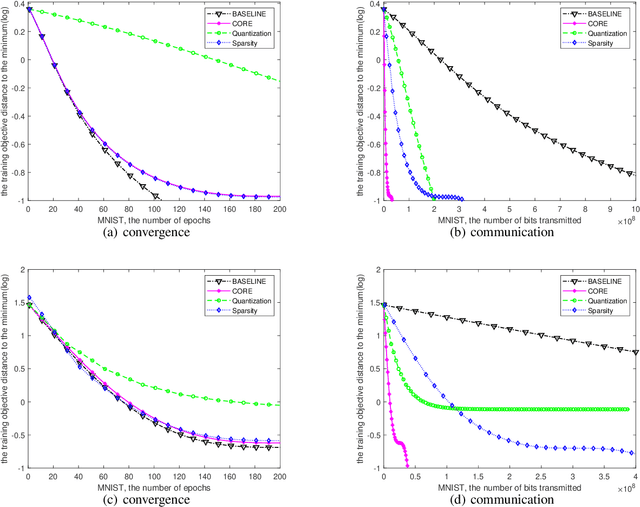
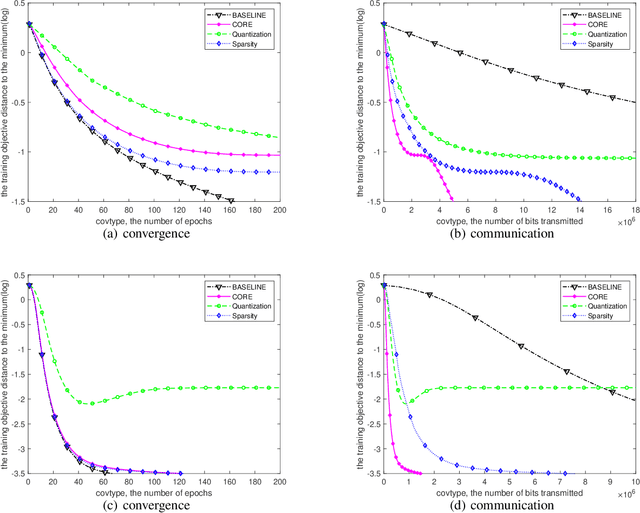
With distributed machine learning being a prominent technique for large-scale machine learning tasks, communication complexity has become a major bottleneck for speeding up training and scaling up machine numbers. In this paper, we propose a new technique named Common randOm REconstruction(CORE), which can be used to compress the information transmitted between machines in order to reduce communication complexity without other strict conditions. Especially, our technique CORE projects the vector-valued information to a low-dimensional one through common random vectors and reconstructs the information with the same random noises after communication. We apply CORE to two distributed tasks, respectively convex optimization on linear models and generic non-convex optimization, and design new distributed algorithms, which achieve provably lower communication complexities. For example, we show for linear models CORE-based algorithm can encode the gradient vector to $\mathcal{O}(1)$-bits (against $\mathcal{O}(d)$), with the convergence rate not worse, preceding the existing results.
Memory-Efficient Continual Learning Object Segmentation for Long Video
Sep 26, 2023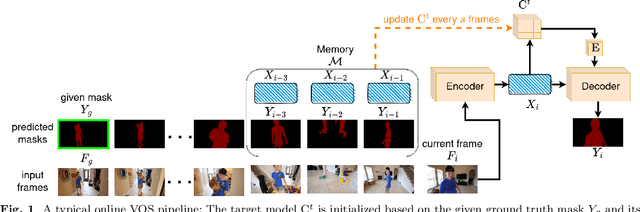
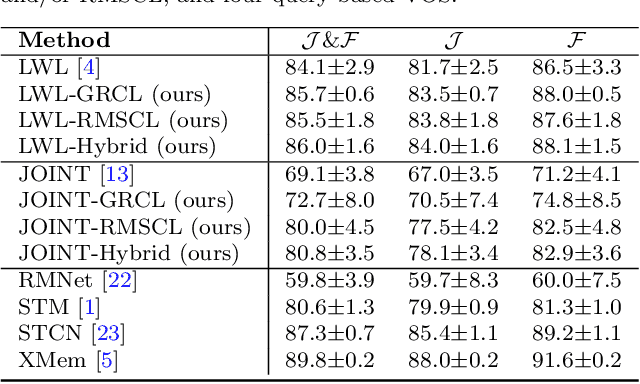
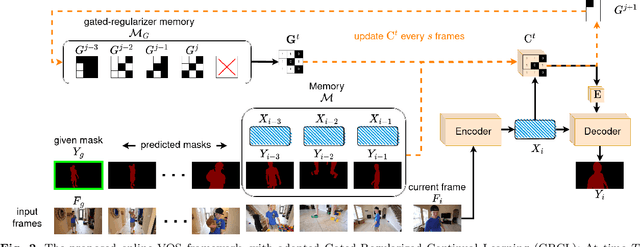
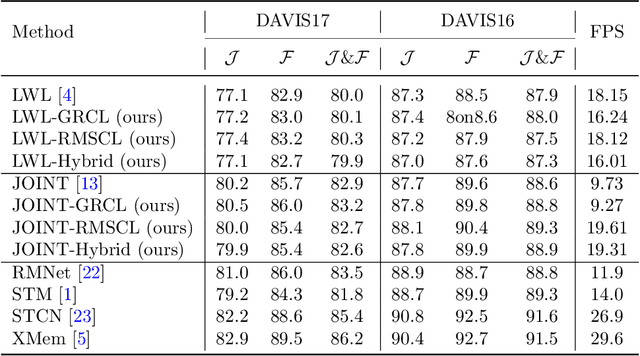
Recent state-of-the-art semi-supervised Video Object Segmentation (VOS) methods have shown significant improvements in target object segmentation accuracy when information from preceding frames is used in undertaking segmentation on the current frame. In particular, such memory-based approaches can help a model to more effectively handle appearance changes (representation drift) or occlusions. Ideally, for maximum performance, online VOS methods would need all or most of the preceding frames (or their extracted information) to be stored in memory and be used for online learning in consecutive frames. Such a solution is not feasible for long videos, as the required memory size would grow without bound. On the other hand, these methods can fail when memory is limited and a target object experiences repeated representation drifts throughout a video. We propose two novel techniques to reduce the memory requirement of online VOS methods while improving modeling accuracy and generalization on long videos. Motivated by the success of continual learning techniques in preserving previously-learned knowledge, here we propose Gated-Regularizer Continual Learning (GRCL), which improves the performance of any online VOS subject to limited memory, and a Reconstruction-based Memory Selection Continual Learning (RMSCL) which empowers online VOS methods to efficiently benefit from stored information in memory. Experimental results show that the proposed methods improve the performance of online VOS models up to 10 %, and boosts their robustness on long-video datasets while maintaining comparable performance on short-video datasets DAVIS16 and DAVIS17.
STRONG -- Structure Controllable Legal Opinion Summary Generation
Sep 29, 2023We propose an approach for the structure controllable summarization of long legal opinions that considers the argument structure of the document. Our approach involves using predicted argument role information to guide the model in generating coherent summaries that follow a provided structure pattern. We demonstrate the effectiveness of our approach on a dataset of legal opinions and show that it outperforms several strong baselines with respect to ROUGE, BERTScore, and structure similarity.
Planning to Go Out-of-Distribution in Offline-to-Online Reinforcement Learning
Oct 09, 2023Offline pretraining with a static dataset followed by online fine-tuning (offline-to-online, or OtO) is a paradigm that is well matched to a real-world RL deployment process: in few real settings would one deploy an offline policy with no test runs and tuning. In this scenario, we aim to find the best-performing policy within a limited budget of online interactions. Previous work in the OtO setting has focused on correcting for bias introduced by the policy-constraint mechanisms of offline RL algorithms. Such constraints keep the learned policy close to the behavior policy that collected the dataset, but this unnecessarily limits policy performance if the behavior policy is far from optimal. Instead, we forgo policy constraints and frame OtO RL as an exploration problem: we must maximize the benefit of the online data-collection. We study major online RL exploration paradigms, adapting them to work well with the OtO setting. These adapted methods contribute several strong baselines. Also, we introduce an algorithm for planning to go out of distribution (PTGOOD), which targets online exploration in relatively high-reward regions of the state-action space unlikely to be visited by the behavior policy. By leveraging concepts from the Conditional Entropy Bottleneck, PTGOOD encourages data collected online to provide new information relevant to improving the final deployment policy. In that way the limited interaction budget is used effectively. We show that PTGOOD significantly improves agent returns during online fine-tuning and finds the optimal policy in as few as 10k online steps in Walker and in as few as 50k in complex control tasks like Humanoid. Also, we find that PTGOOD avoids the suboptimal policy convergence that many of our baselines exhibit in several environments.
On Prediction-Modelers and Decision-Makers: Why Fairness Requires More Than a Fair Prediction Model
Oct 09, 2023An implicit ambiguity in the field of prediction-based decision-making regards the relation between the concepts of prediction and decision. Much of the literature in the field tends to blur the boundaries between the two concepts and often simply speaks of 'fair prediction.' In this paper, we point out that a differentiation of these concepts is helpful when implementing algorithmic fairness. Even if fairness properties are related to the features of the used prediction model, what is more properly called 'fair' or 'unfair' is a decision system, not a prediction model. This is because fairness is about the consequences on human lives, created by a decision, not by a prediction. We clarify the distinction between the concepts of prediction and decision and show the different ways in which these two elements influence the final fairness properties of a prediction-based decision system. In addition to exploring this relationship conceptually and practically, we propose a framework that enables a better understanding and reasoning of the conceptual logic of creating fairness in prediction-based decision-making. In our framework, we specify different roles, namely the 'prediction-modeler' and the 'decision-maker,' and the information required from each of them for being able to implement fairness of the system. Our framework allows for deriving distinct responsibilities for both roles and discussing some insights related to ethical and legal requirements. Our contribution is twofold. First, we shift the focus from abstract algorithmic fairness to context-dependent decision-making, recognizing diverse actors with unique objectives and independent actions. Second, we provide a conceptual framework that can help structure prediction-based decision problems with respect to fairness issues, identify responsibilities, and implement fairness governance mechanisms in real-world scenarios.
Local Compressed Video Stream Learning for Generic Event Boundary Detection
Sep 27, 2023Generic event boundary detection aims to localize the generic, taxonomy-free event boundaries that segment videos into chunks. Existing methods typically require video frames to be decoded before feeding into the network, which contains significant spatio-temporal redundancy and demands considerable computational power and storage space. To remedy these issues, we propose a novel compressed video representation learning method for event boundary detection that is fully end-to-end leveraging rich information in the compressed domain, i.e., RGB, motion vectors, residuals, and the internal group of pictures (GOP) structure, without fully decoding the video. Specifically, we use lightweight ConvNets to extract features of the P-frames in the GOPs and spatial-channel attention module (SCAM) is designed to refine the feature representations of the P-frames based on the compressed information with bidirectional information flow. To learn a suitable representation for boundary detection, we construct the local frames bag for each candidate frame and use the long short-term memory (LSTM) module to capture temporal relationships. We then compute frame differences with group similarities in the temporal domain. This module is only applied within a local window, which is critical for event boundary detection. Finally a simple classifier is used to determine the event boundaries of video sequences based on the learned feature representation. To remedy the ambiguities of annotations and speed up the training process, we use the Gaussian kernel to preprocess the ground-truth event boundaries. Extensive experiments conducted on the Kinetics-GEBD and TAPOS datasets demonstrate that the proposed method achieves considerable improvements compared to previous end-to-end approach while running at the same speed. The code is available at https://github.com/GX77/LCVSL.
The Role of Early Sampling in Age of Information Minimization in the Presence of ACK Delays
Aug 15, 2023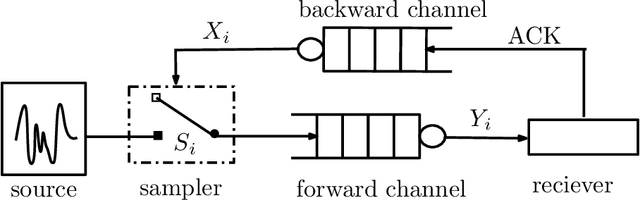

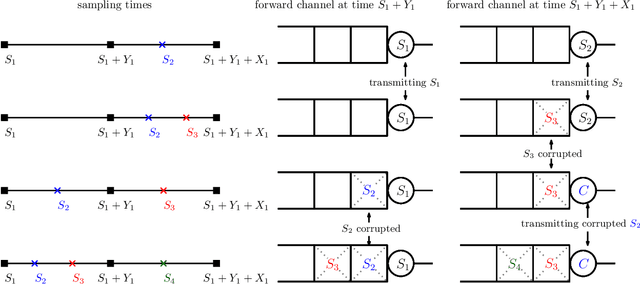
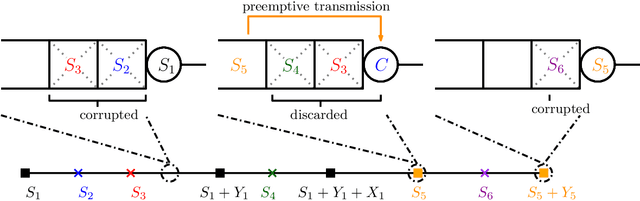
We study the structure of the optimal sampling policy to minimize the average age of information when the channel state (i.e., busy or idle) is not immediately perceived by the transmitter upon the delivery of a sample due to random delays in the feedback (ACK) channel. In this setting, we show that it is not always optimal to wait for ACKs before sampling, and thus, early sampling before the arrival of an ACK may be optimal. We show that, under certain conditions on the distribution of the ACK delays, the optimal policy is a mixture of two threshold policies.
LanguageMPC: Large Language Models as Decision Makers for Autonomous Driving
Oct 04, 2023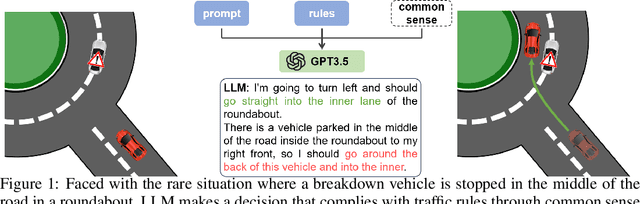
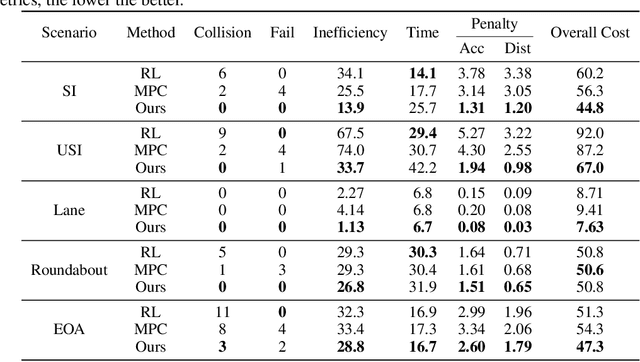
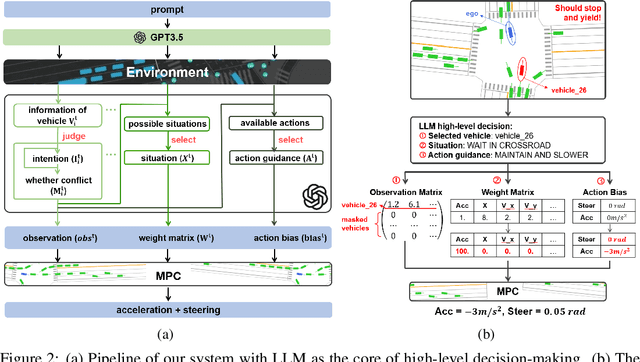

Existing learning-based autonomous driving (AD) systems face challenges in comprehending high-level information, generalizing to rare events, and providing interpretability. To address these problems, this work employs Large Language Models (LLMs) as a decision-making component for complex AD scenarios that require human commonsense understanding. We devise cognitive pathways to enable comprehensive reasoning with LLMs, and develop algorithms for translating LLM decisions into actionable driving commands. Through this approach, LLM decisions are seamlessly integrated with low-level controllers by guided parameter matrix adaptation. Extensive experiments demonstrate that our proposed method not only consistently surpasses baseline approaches in single-vehicle tasks, but also helps handle complex driving behaviors even multi-vehicle coordination, thanks to the commonsense reasoning capabilities of LLMs. This paper presents an initial step toward leveraging LLMs as effective decision-makers for intricate AD scenarios in terms of safety, efficiency, generalizability, and interoperability. We aspire for it to serve as inspiration for future research in this field. Project page: https://sites.google.com/view/llm-mpc