 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fusion approaches for emotion recognition from speech using acoustic and text-based features
Mar 27, 2024
In this paper, we study different approaches for classifying emotions from speech using acoustic and text-based features. We propose to obtain contextualized word embeddings with BERT to represent the information contained in speech transcriptions and show that this results in better performance than using Glove embeddings. We also propose and compare different strategies to combine the audio and text modalities, evaluating them on IEMOCAP and MSP-PODCAST datasets. We find that fusing acoustic and text-based systems is beneficial on both datasets, though only subtle differences are observed across the evaluated fusion approaches. Finally, for IEMOCAP, we show the large effect that the criteria used to define the cross-validation folds have on results. In particular, the standard way of creating folds for this dataset results in a highly optimistic estimation of performance for the text-based system, suggesting that some previous works may overestimate the advantage of incorporating transcriptions.
Seed-based information retrieval in networks of research publications: Evaluation of direct citations, bibliographic coupling, co-citations and PubMed related article score
Mar 14, 2024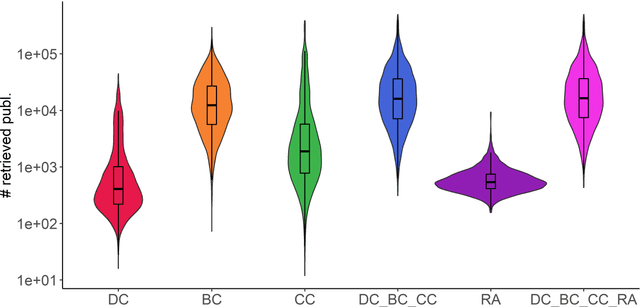
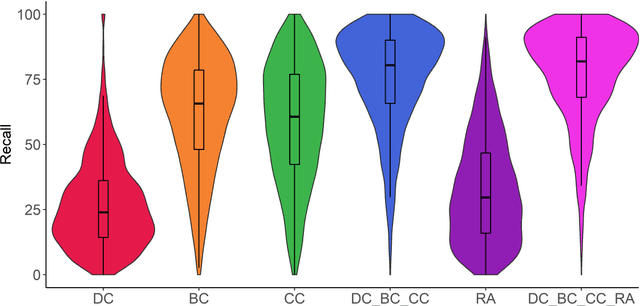
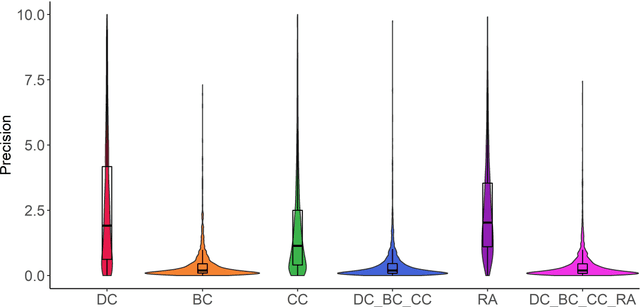
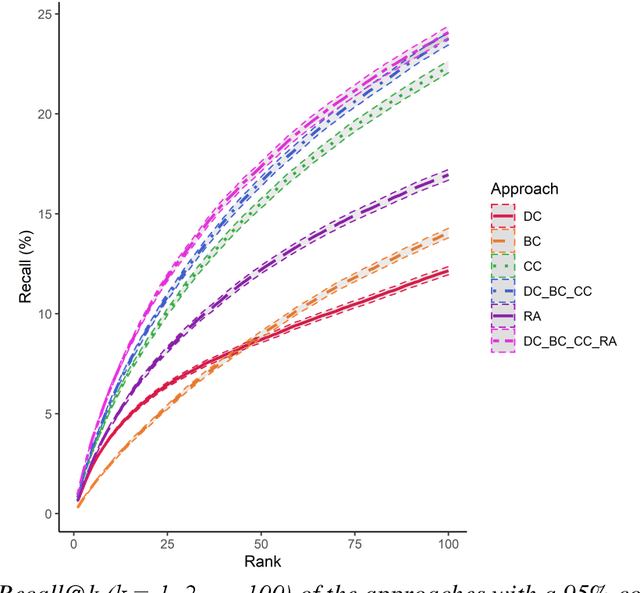
In this contribution, we deal with seed-based information retrieval in networks of research publications. Using systematic reviews as a baseline, and publication data from the NIH Open Citation Collection, we compare the performance of the three citation-based approaches direct citation, co-citation, and bibliographic coupling with respect to recall and precision measures. In addition, we include the PubMed Related Article score as well as combined approaches in the comparison. We also provide a fairly comprehensive review of earlier research in which citation relations have been used for information retrieval purposes. The results show an advantage for co-citation over bibliographic coupling and direct citation. However, combining the three approaches outperforms the exclusive use of co-citation in the study. The results further indicate, in line with previous research, that combining citation-based approaches with textual approaches enhances the performance of seed-based information retrieval. The results from the study may guide approaches combining citation-based and textual approaches in their choice of citation similarity measures. We suggest that future research use more structured approaches to evaluate methods for seed-based retrieval of publications, including comparative approaches as well as the elaboration of common data sets and baselines for evaluation.
If CLIP Could Talk: Understanding Vision-Language Model Representations Through Their Preferred Concept Descriptions
Mar 25, 2024Recent works often assume that Vision-Language Model (VLM) representations are based on visual attributes like shape. However, it is unclear to what extent VLMs prioritize this information to represent concepts. We propose Extract and Explore (EX2), a novel approach to characterize important textual features for VLMs. EX2 uses reinforcement learning to align a large language model with VLM preferences and generates descriptions that incorporate the important features for the VLM. Then, we inspect the descriptions to identify the features that contribute to VLM representations. We find that spurious descriptions have a major role in VLM representations despite providing no helpful information, e.g., Click to enlarge photo of CONCEPT. More importantly, among informative descriptions, VLMs rely significantly on non-visual attributes like habitat to represent visual concepts. Also, our analysis reveals that different VLMs prioritize different attributes in their representations. Overall, we show that VLMs do not simply match images to scene descriptions and that non-visual or even spurious descriptions significantly influence their representations.
EXPLORA: A teacher-apprentice methodology for eliciting natural child-computer interactions
Mar 25, 2024Investigating child-computer interactions within their contexts is vital for designing technology that caters to children's needs. However, determining what aspects of context are relevant for designing child-centric technology remains a challenge. We introduce EXPLORA, a multimodal, multistage online methodology comprising three pivotal stages: (1) building a teacher-apprentice relationship,(2) learning from child-teachers, and (3) assessing and reinforcing researcher-apprentice learning. Central to EXPLORA is the collection of attitudinal data through pre-observation interviews, offering researchers a deeper understanding of children's characteristics and contexts. This informs subsequent online observations, allowing researchers to focus on frequent interactions. Furthermore, researchers can validate preliminary assumptions with children. A means-ends analysis framework aids in the systematic analysis of data, shedding light on context, agency and homework-information searching processes children employ in their activities. To illustrate EXPLORA's capabilities, we present nine single case studies investigating Brazilian child-caregiver dyads' (children ages 9-11) use of technology in homework information-searching.
Gegenbauer Graph Neural Networks for Time-varying Signal Reconstruction
Mar 28, 2024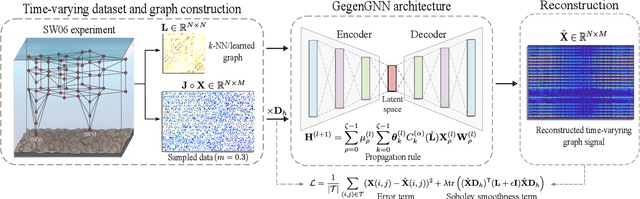
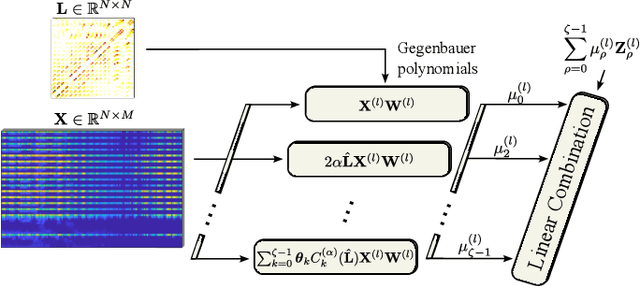
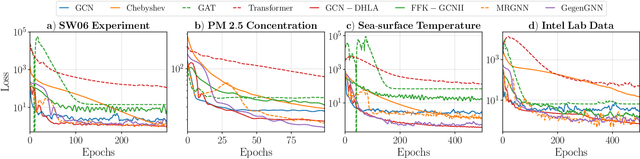
Reconstructing time-varying graph signals (or graph time-series imputation) is a critical problem in machine learning and signal processing with broad applications, ranging from missing data imputation in sensor networks to time-series forecasting. Accurately capturing the spatio-temporal information inherent in these signals is crucial for effectively addressing these tasks. However, existing approaches relying on smoothness assumptions of temporal differences and simple convex optimization techniques have inherent limitations. To address these challenges, we propose a novel approach that incorporates a learning module to enhance the accuracy of the downstream task. To this end, we introduce the Gegenbauer-based graph convolutional (GegenConv) operator, which is a generalization of the conventional Chebyshev graph convolution by leveraging the theory of Gegenbauer polynomials. By deviating from traditional convex problems, we expand the complexity of the model and offer a more accurate solution for recovering time-varying graph signals. Building upon GegenConv, we design the Gegenbauer-based time Graph Neural Network (GegenGNN) architecture, which adopts an encoder-decoder structure. Likewise, our approach also utilizes a dedicated loss function that incorporates a mean squared error component alongside Sobolev smoothness regularization. This combination enables GegenGNN to capture both the fidelity to ground truth and the underlying smoothness properties of the signals, enhancing the reconstruction performance. We conduct extensive experiments on real datasets to evaluate the effectiveness of our proposed approach. The experimental results demonstrate that GegenGNN outperforms state-of-the-art methods, showcasing its superior capability in recovering time-varying graph signals.
Bespoke Large Language Models for Digital Triage Assistance in Mental Health Care
Mar 28, 2024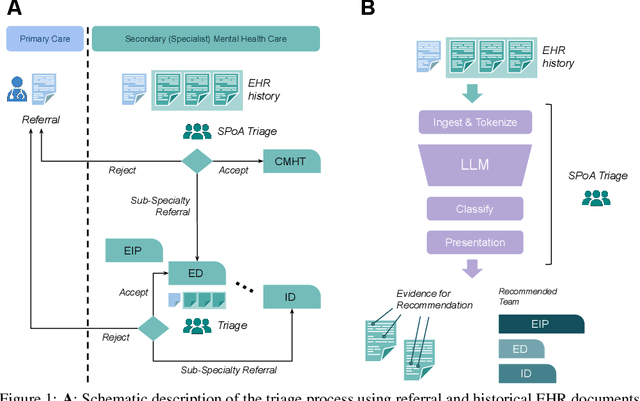

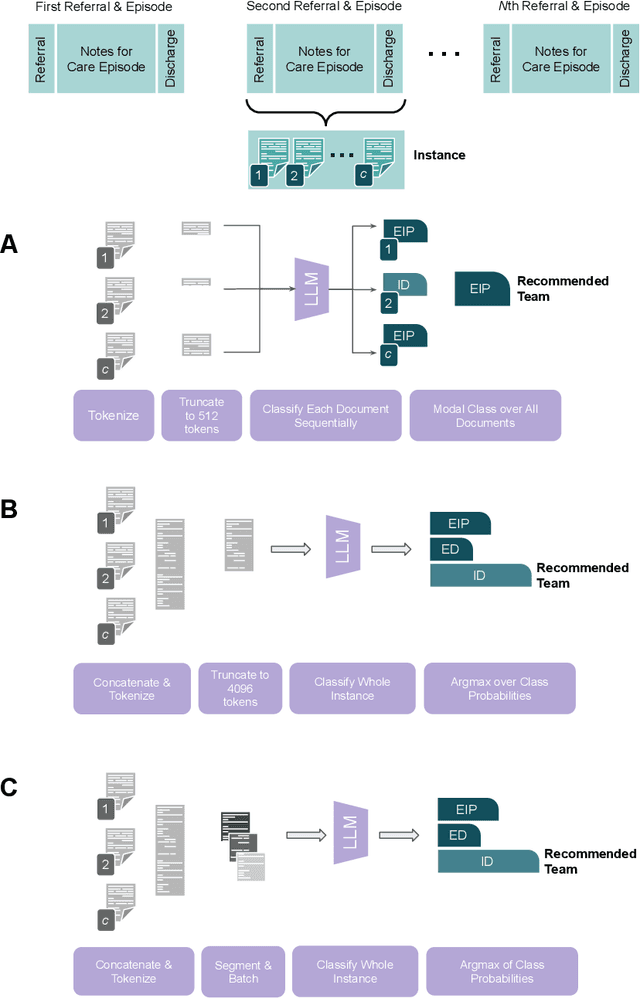

Contemporary large language models (LLMs) may have utility for processing unstructured, narrative free-text clinical data contained in electronic health records (EHRs) -- a particularly important use-case for mental health where a majority of routinely-collected patient data lacks structured, machine-readable content. A significant problem for the the United Kingdom's National Health Service (NHS) are the long waiting lists for specialist mental healthcare. According to NHS data, in each month of 2023, there were between 370,000 and 470,000 individual new referrals into secondary mental healthcare services. Referrals must be triaged by clinicians, using clinical information contained in the patient's EHR to arrive at a decision about the most appropriate mental healthcare team to assess and potentially treat these patients. The ability to efficiently recommend a relevant team by ingesting potentially voluminous clinical notes could help services both reduce referral waiting times and with the right technology, improve the evidence available to justify triage decisions. We present and evaluate three different approaches for LLM-based, end-to-end ingestion of variable-length clinical EHR data to assist clinicians when triaging referrals. Our model is able to deliver triage recommendations consistent with existing clinical practices and it's architecture was implemented on a single GPU, making it practical for implementation in resource-limited NHS environments where private implementations of LLM technology will be necessary to ensure confidential clinical data is appropriately controlled and governed.
OV-Uni3DETR: Towards Unified Open-Vocabulary 3D Object Detection via Cycle-Modality Propagation
Mar 28, 2024In the current state of 3D object detection research, the severe scarcity of annotated 3D data, substantial disparities across different data modalities, and the absence of a unified architecture, have impeded the progress towards the goal of universality. In this paper, we propose \textbf{OV-Uni3DETR}, a unified open-vocabulary 3D detector via cycle-modality propagation. Compared with existing 3D detectors, OV-Uni3DETR offers distinct advantages: 1) Open-vocabulary 3D detection: During training, it leverages various accessible data, especially extensive 2D detection images, to boost training diversity. During inference, it can detect both seen and unseen classes. 2) Modality unifying: It seamlessly accommodates input data from any given modality, effectively addressing scenarios involving disparate modalities or missing sensor information, thereby supporting test-time modality switching. 3) Scene unifying: It provides a unified multi-modal model architecture for diverse scenes collected by distinct sensors. Specifically, we propose the cycle-modality propagation, aimed at propagating knowledge bridging 2D and 3D modalities, to support the aforementioned functionalities. 2D semantic knowledge from large-vocabulary learning guides novel class discovery in the 3D domain, and 3D geometric knowledge provides localization supervision for 2D detection images. OV-Uni3DETR achieves the state-of-the-art performance on various scenarios, surpassing existing methods by more than 6\% on average. Its performance using only RGB images is on par with or even surpasses that of previous point cloud based methods. Code and pre-trained models will be released later.
Text Data-Centric Image Captioning with Interactive Prompts
Mar 28, 2024Supervised image captioning approaches have made great progress, but it is challenging to collect high-quality human-annotated image-text data. Recently, large-scale vision and language models (e.g., CLIP) and large-scale generative language models (e.g., GPT-2) have shown strong performances in various tasks, which also provide some new solutions for image captioning with web paired data, unpaired data or even text-only data. Among them, the mainstream solution is to project image embeddings into the text embedding space with the assistance of consistent representations between image-text pairs from the CLIP model. However, the current methods still face several challenges in adapting to the diversity of data configurations in a unified solution, accurately estimating image-text embedding bias, and correcting unsatisfactory prediction results in the inference stage. This paper proposes a new Text data-centric approach with Interactive Prompts for image Captioning, named TIPCap. 1) We consider four different settings which gradually reduce the dependence on paired data. 2) We construct a mapping module driven by multivariate Gaussian distribution to mitigate the modality gap, which is applicable to the above four different settings. 3) We propose a prompt interaction module that can incorporate optional prompt information before generating captions. Extensive experiments show that our TIPCap outperforms other weakly or unsupervised image captioning methods and achieves a new state-of-the-art performance on two widely used datasets, i.e., MS-COCO and Flickr30K.
DANCER: Entity Description Augmented Named Entity Corrector for Automatic Speech Recognition
Mar 28, 2024End-to-end automatic speech recognition (E2E ASR) systems often suffer from mistranscription of domain-specific phrases, such as named entities, sometimes leading to catastrophic failures in downstream tasks. A family of fast and lightweight named entity correction (NEC) models for ASR have recently been proposed, which normally build on phonetic-level edit distance algorithms and have shown impressive NEC performance. However, as the named entity (NE) list grows, the problems of phonetic confusion in the NE list are exacerbated; for example, homophone ambiguities increase substantially. In view of this, we proposed a novel Description Augmented Named entity CorrEctoR (dubbed DANCER), which leverages entity descriptions to provide additional information to facilitate mitigation of phonetic confusion for NEC on ASR transcription. To this end, an efficient entity description augmented masked language model (EDA-MLM) comprised of a dense retrieval model is introduced, enabling MLM to adapt swiftly to domain-specific entities for the NEC task. A series of experiments conducted on the AISHELL-1 and Homophone datasets confirm the effectiveness of our modeling approach. DANCER outperforms a strong baseline, the phonetic edit-distance-based NEC model (PED-NEC), by a character error rate (CER) reduction of about 7% relatively on AISHELL-1 for named entities. More notably, when tested on Homophone that contain named entities of high phonetic confusion, DANCER offers a more pronounced CER reduction of 46% relatively over PED-NEC for named entities.
Partially Blinded Unlearning: Class Unlearning for Deep Networks a Bayesian Perspective
Mar 24, 2024In order to adhere to regulatory standards governing individual data privacy and safety, machine learning models must systematically eliminate information derived from specific subsets of a user's training data that can no longer be utilized. The emerging discipline of Machine Unlearning has arisen as a pivotal area of research, facilitating the process of selectively discarding information designated to specific sets or classes of data from a pre-trained model, thereby eliminating the necessity for extensive retraining from scratch. The principal aim of this study is to formulate a methodology tailored for the purposeful elimination of information linked to a specific class of data from a pre-trained classification network. This intentional removal is crafted to degrade the model's performance specifically concerning the unlearned data class while concurrently minimizing any detrimental impacts on the model's performance in other classes. To achieve this goal, we frame the class unlearning problem from a Bayesian perspective, which yields a loss function that minimizes the log-likelihood associated with the unlearned data with a stability regularization in parameter space. This stability regularization incorporates Mohalanobis distance with respect to the Fisher Information matrix and $l_2$ distance from the pre-trained model parameters. Our novel approach, termed \textbf{Partially-Blinded Unlearning (PBU)}, surpasses existing state-of-the-art class unlearning methods, demonstrating superior effectiveness. Notably, PBU achieves this efficacy without requiring awareness of the entire training dataset but only to the unlearned data points, marking a distinctive feature of its performance.