 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Modality-aware Transformer for Time series Forecasting
Oct 02, 2023
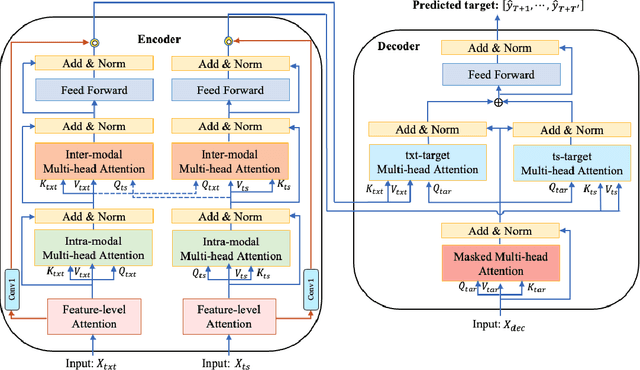

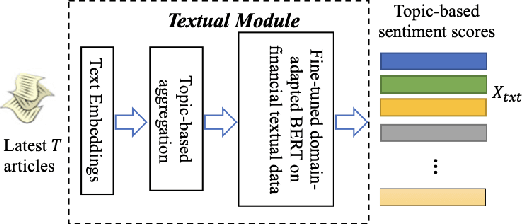
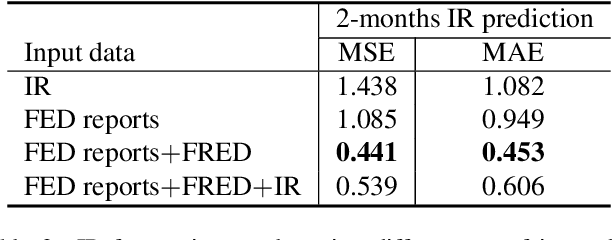
Time series forecasting presents a significant challenge, particularly when its accuracy relies on external data sources rather than solely on historical values. This issue is prevalent in the financial sector, where the future behavior of time series is often intricately linked to information derived from various textual reports and a multitude of economic indicators. In practice, the key challenge lies in constructing a reliable time series forecasting model capable of harnessing data from diverse sources and extracting valuable insights to predict the target time series accurately. In this work, we tackle this challenging problem and introduce a novel multimodal transformer-based model named the Modality-aware Transformer. Our model excels in exploring the power of both categorical text and numerical timeseries to forecast the target time series effectively while providing insights through its neural attention mechanism. To achieve this, we develop feature-level attention layers that encourage the model to focus on the most relevant features within each data modality. By incorporating the proposed feature-level attention, we develop a novel Intra-modal multi-head attention (MHA), Inter-modal MHA and Modality-target MHA in a way that both feature and temporal attentions are incorporated in MHAs. This enables the MHAs to generate temporal attentions with consideration of modality and feature importance which leads to more informative embeddings. The proposed modality-aware structure enables the model to effectively exploit information within each modality as well as foster cross-modal understanding. Our extensive experiments on financial datasets demonstrate that Modality-aware Transformer outperforms existing methods, offering a novel and practical solution to the complex challenges of multi-modality time series forecasting.
Pursuing Counterfactual Fairness via Sequential Autoencoder Across Domains
Sep 22, 2023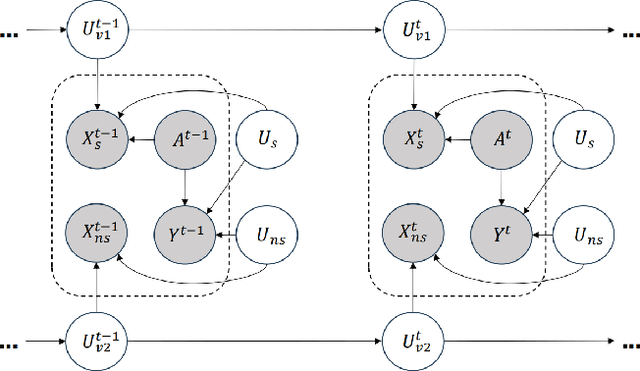
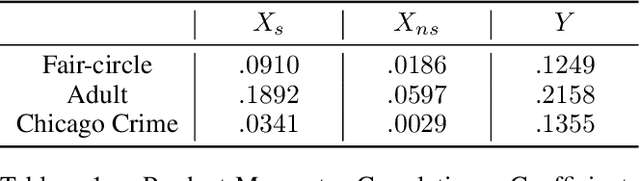
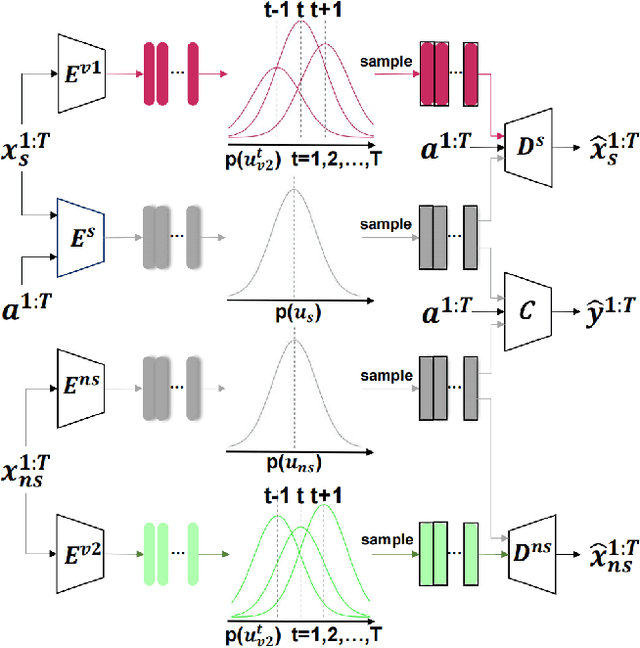
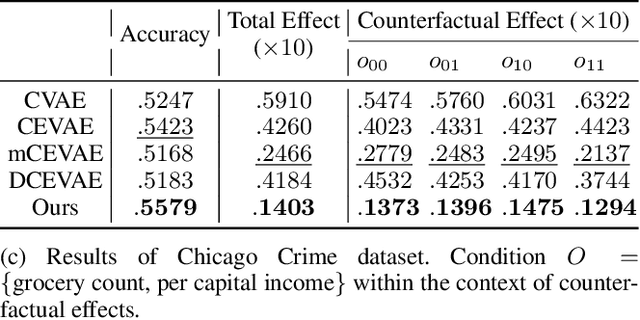
Recognizing the prevalence of domain shift as a common challenge in machine learning, various domain generalization (DG) techniques have been developed to enhance the performance of machine learning systems when dealing with out-of-distribution (OOD) data. Furthermore, in real-world scenarios, data distributions can gradually change across a sequence of sequential domains. While current methodologies primarily focus on improving model effectiveness within these new domains, they often overlook fairness issues throughout the learning process. In response, we introduce an innovative framework called Counterfactual Fairness-Aware Domain Generalization with Sequential Autoencoder (CDSAE). This approach effectively separates environmental information and sensitive attributes from the embedded representation of classification features. This concurrent separation not only greatly improves model generalization across diverse and unfamiliar domains but also effectively addresses challenges related to unfair classification. Our strategy is rooted in the principles of causal inference to tackle these dual issues. To examine the intricate relationship between semantic information, sensitive attributes, and environmental cues, we systematically categorize exogenous uncertainty factors into four latent variables: 1) semantic information influenced by sensitive attributes, 2) semantic information unaffected by sensitive attributes, 3) environmental cues influenced by sensitive attributes, and 4) environmental cues unaffected by sensitive attributes. By incorporating fairness regularization, we exclusively employ semantic information for classification purposes. Empirical validation on synthetic and real-world datasets substantiates the effectiveness of our approach, demonstrating improved accuracy levels while ensuring the preservation of fairness in the evolving landscape of continuous domains.
An Exploration of Optimal Parameters for Efficient Blind Source Separation of EEG Recordings Using AMICA
Sep 27, 2023EEG continues to find a multitude of uses in both neuroscience research and medical practice, and independent component analysis (ICA) continues to be an important tool for analyzing EEG. A multitude of ICA algorithms for EEG decomposition exist, and in the past, their relative effectiveness has been studied. AMICA is considered the benchmark against which to compare the performance of other ICA algorithms for EEG decomposition. AMICA exposes many parameters to the user to allow for precise control of the decomposition. However, several of the parameters currently tend to be set according to "rules of thumb" shared in the EEG community. Here, AMICA decompositions are run on data from a collection of subjects while varying certain key parameters. The running time and quality of decompositions are analyzed based on two metrics: Pairwise Mutual Information (PMI) and Mutual Information Reduction (MIR). Recommendations for selecting starting values for parameters are presented.
Impact of architecture on robustness and interpretability of multispectral deep neural networks
Sep 27, 2023Including information from additional spectral bands (e.g., near-infrared) can improve deep learning model performance for many vision-oriented tasks. There are many possible ways to incorporate this additional information into a deep learning model, but the optimal fusion strategy has not yet been determined and can vary between applications. At one extreme, known as "early fusion," additional bands are stacked as extra channels to obtain an input image with more than three channels. At the other extreme, known as "late fusion," RGB and non-RGB bands are passed through separate branches of a deep learning model and merged immediately before a final classification or segmentation layer. In this work, we characterize the performance of a suite of multispectral deep learning models with different fusion approaches, quantify their relative reliance on different input bands and evaluate their robustness to naturalistic image corruptions affecting one or more input channels.
Superimposed RIS-phase Modulation for MIMO Communications: A Novel Paradigm of Information Transfer
Aug 10, 2023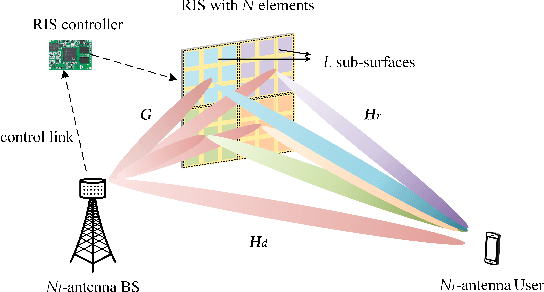
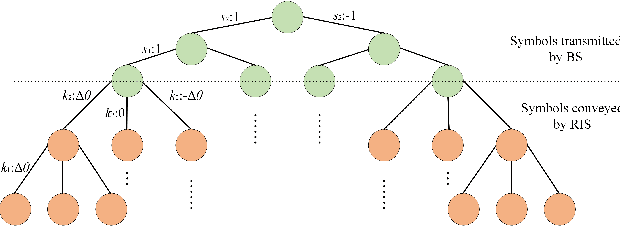
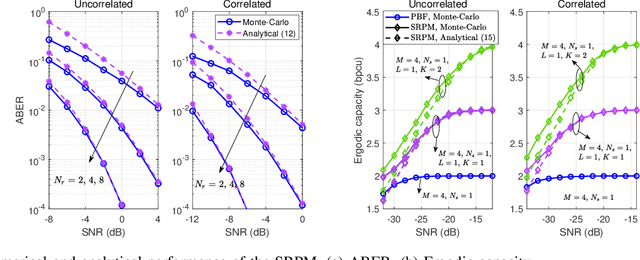
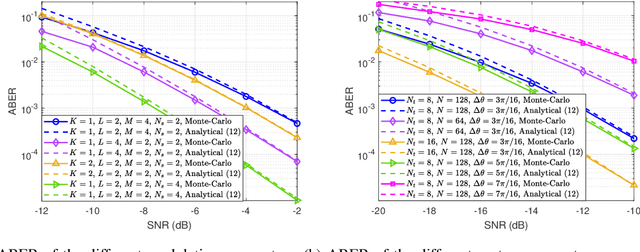
Reconfigurable intelligent surface (RIS) is regarded as an important enabling technology for the sixth-generation (6G) network. Recently, modulating information in reflection patterns of RIS, referred to as reflection modulation (RM), has been proven in theory to have the potential of achieving higher transmission rate than existing passive beamforming (PBF) schemes of RIS. To fully unlock this potential of RM, we propose a novel superimposed RIS-phase modulation (SRPM) scheme for multiple-input multiple-output (MIMO) systems, where tunable phase offsets are superimposed onto predetermined RIS phases to bear extra information messages. The proposed SRPM establishes a universal framework for RM, which retrieves various existing RM-based schemes as special cases. Moreover, the advantages and applicability of the SRPM in practice is also validated in theory by analytical characterization of its performance in terms of average bit error rate (ABER) and ergodic capacity. To maximize the performance gain, we formulate a general precoding optimization at the base station (BS) for a single-stream case with uncorrelated channels and obtain the optimal SRPM design via the semidefinite relaxation (SDR) technique. Furthermore, to avoid extremely high complexity in maximum likelihood (ML) detection for the SRPM, we propose a sphere decoding (SD)-based layered detection method with near-ML performance and much lower complexity. Numerical results demonstrate the effectiveness of SRPM, precoding optimization, and detection design. It is verified that the proposed SRPM achieves a higher diversity order than that of existing RM-based schemes and outperforms PBF significantly especially when the transmitter is equipped with limited radio-frequency (RF) chains.
AANet: Aggregation and Alignment Network with Semi-hard Positive Sample Mining for Hierarchical Place Recognition
Oct 08, 2023Visual place recognition (VPR) is one of the research hotspots in robotics, which uses visual information to locate robots. Recently, the hierarchical two-stage VPR methods have become popular in this field due to the trade-off between accuracy and efficiency. These methods retrieve the top-k candidate images using the global features in the first stage, then re-rank the candidates by matching the local features in the second stage. However, they usually require additional algorithms (e.g. RANSAC) for geometric consistency verification in re-ranking, which is time-consuming. Here we propose a Dynamically Aligning Local Features (DALF) algorithm to align the local features under spatial constraints. It is significantly more efficient than the methods that need geometric consistency verification. We present a unified network capable of extracting global features for retrieving candidates via an aggregation module and aligning local features for re-ranking via the DALF alignment module. We call this network AANet. Meanwhile, many works use the simplest positive samples in triplet for weakly supervised training, which limits the ability of the network to recognize harder positive pairs. To address this issue, we propose a Semi-hard Positive Sample Mining (ShPSM) strategy to select appropriate hard positive images for training more robust VPR networks. Extensive experiments on four benchmark VPR datasets show that the proposed AANet can outperform several state-of-the-art methods with less time consumption. The code is released at https://github.com/Lu-Feng/AANet.
Information Retrieval Meets Large Language Models: A Strategic Report from Chinese IR Community
Jul 27, 2023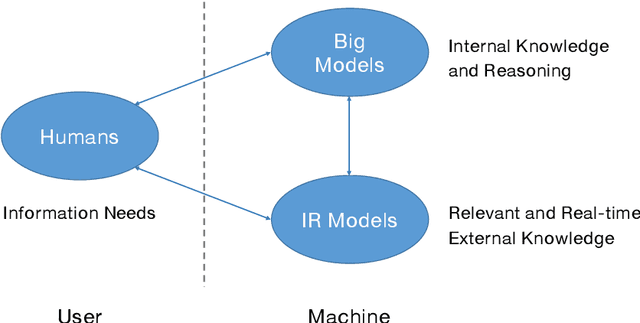
The research field of Information Retrieval (IR) has evolved significantly, expanding beyond traditional search to meet diverse user information needs. Recently, Large Language Models (LLMs) have demonstrated exceptional capabilities in text understanding, generation, and knowledge inference, opening up exciting avenues for IR research. LLMs not only facilitate generative retrieval but also offer improved solutions for user understanding, model evaluation, and user-system interactions. More importantly, the synergistic relationship among IR models, LLMs, and humans forms a new technical paradigm that is more powerful for information seeking. IR models provide real-time and relevant information, LLMs contribute internal knowledge, and humans play a central role of demanders and evaluators to the reliability of information services. Nevertheless, significant challenges exist, including computational costs, credibility concerns, domain-specific limitations, and ethical considerations. To thoroughly discuss the transformative impact of LLMs on IR research, the Chinese IR community conducted a strategic workshop in April 2023, yielding valuable insights. This paper provides a summary of the workshop's outcomes, including the rethinking of IR's core values, the mutual enhancement of LLMs and IR, the proposal of a novel IR technical paradigm, and open challenges.
Bi-directional Deformation for Parameterization of Neural Implicit Surfaces
Oct 09, 2023The growing capabilities of neural rendering have increased the demand for new techniques that enable the intuitive editing of 3D objects, particularly when they are represented as neural implicit surfaces. In this paper, we present a novel neural algorithm to parameterize neural implicit surfaces to simple parametric domains, such as spheres, cubes or polycubes, where 3D radiance field can be represented as a 2D field, thereby facilitating visualization and various editing tasks. Technically, our method computes a bi-directional deformation between 3D objects and their chosen parametric domains, eliminating the need for any prior information. We adopt a forward mapping of points on the zero level set of the 3D object to a parametric domain, followed by a backward mapping through inverse deformation. To ensure the map is bijective, we employ a cycle loss while optimizing the smoothness of both deformations. Additionally, we leverage a Laplacian regularizer to effectively control angle distortion and offer the flexibility to choose from a range of parametric domains for managing area distortion. Designed for compatibility, our framework integrates seamlessly with existing neural rendering pipelines, taking multi-view images as input to reconstruct 3D geometry and compute the corresponding texture map. We also introduce a simple yet effective technique for intrinsic radiance decomposition, facilitating both view-independent material editing and view-dependent shading editing. Our method allows for the immediate rendering of edited textures through volume rendering, without the need for network re-training. Moreover, our approach supports the co-parameterization of multiple objects and enables texture transfer between them. We demonstrate the effectiveness of our method on images of human heads and man-made objects. We will make the source code publicly available.
Layout Sequence Prediction From Noisy Mobile Modality
Oct 09, 2023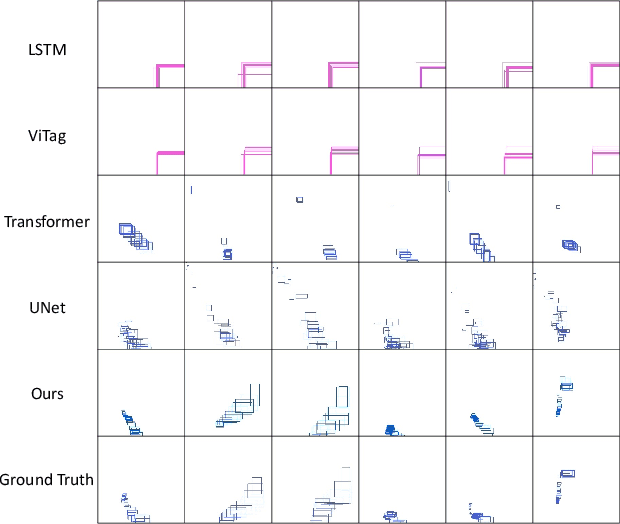
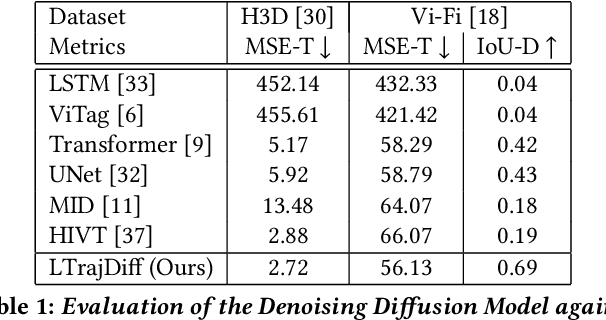
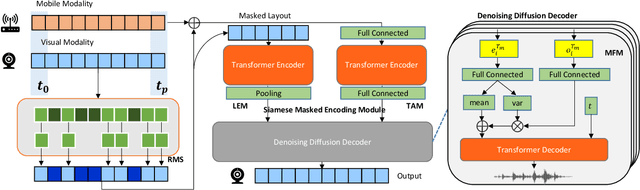
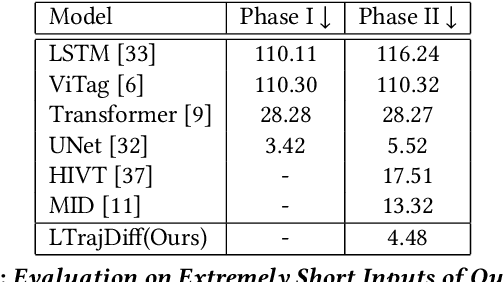
Trajectory prediction plays a vital role in understanding pedestrian movement for applications such as autonomous driving and robotics. Current trajectory prediction models depend on long, complete, and accurately observed sequences from visual modalities. Nevertheless, real-world situations often involve obstructed cameras, missed objects, or objects out of sight due to environmental factors, leading to incomplete or noisy trajectories. To overcome these limitations, we propose LTrajDiff, a novel approach that treats objects obstructed or out of sight as equally important as those with fully visible trajectories. LTrajDiff utilizes sensor data from mobile phones to surmount out-of-sight constraints, albeit introducing new challenges such as modality fusion, noisy data, and the absence of spatial layout and object size information. We employ a denoising diffusion model to predict precise layout sequences from noisy mobile data using a coarse-to-fine diffusion strategy, incorporating the RMS, Siamese Masked Encoding Module, and MFM. Our model predicts layout sequences by implicitly inferring object size and projection status from a single reference timestamp or significantly obstructed sequences. Achieving SOTA results in randomly obstructed experiments and extremely short input experiments, our model illustrates the effectiveness of leveraging noisy mobile data. In summary, our approach offers a promising solution to the challenges faced by layout sequence and trajectory prediction models in real-world settings, paving the way for utilizing sensor data from mobile phones to accurately predict pedestrian bounding box trajectories. To the best of our knowledge, this is the first work that addresses severely obstructed and extremely short layout sequences by combining vision with noisy mobile modality, making it the pioneering work in the field of layout sequence trajectory prediction.
HIC-YOLOv5: Improved YOLOv5 For Small Object Detection
Sep 28, 2023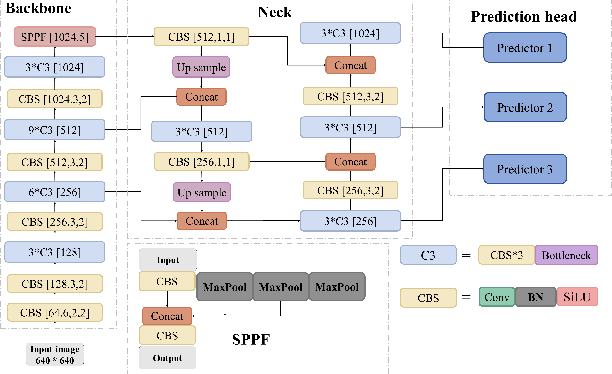
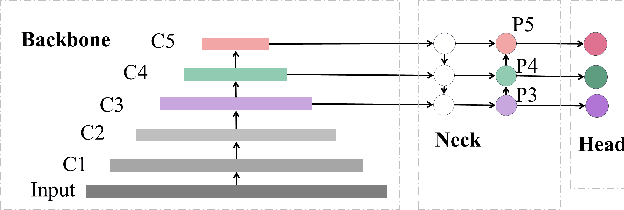
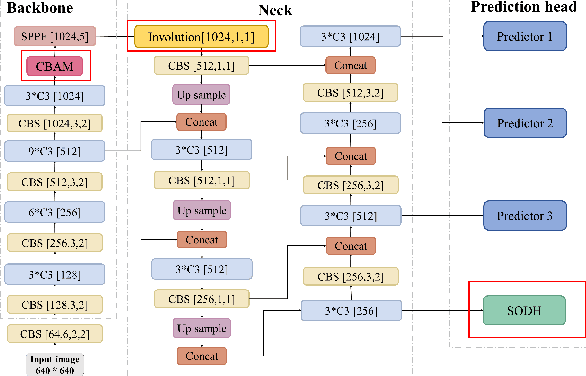
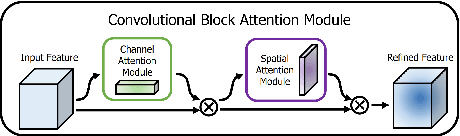
Small object detection has been a challenging problem in the field of object detection. There has been some works that proposes improvements for this task, such as adding several attention blocks or changing the whole structure of feature fusion networks. However, the computation cost of these models is large, which makes deploying a real-time object detection system unfeasible, while leaving room for improvement. To this end, an improved YOLOv5 model: HIC-YOLOv5 is proposed to address the aforementioned problems. Firstly, an additional prediction head specific to small objects is added to provide a higher-resolution feature map for better prediction. Secondly, an involution block is adopted between the backbone and neck to increase channel information of the feature map. Moreover, an attention mechanism named CBAM is applied at the end of the backbone, thus not only decreasing the computation cost compared with previous works but also emphasizing the important information in both channel and spatial domain. Our result shows that HIC-YOLOv5 has improved mAP@[.5:.95] by 6.42% and mAP@0.5 by 9.38% on VisDrone-2019-DET dataset.