 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-resolution HuBERT: Multi-resolution Speech Self-Supervised Learning with Masked Unit Prediction
Oct 04, 2023
Existing Self-Supervised Learning (SSL) models for speech typically process speech signals at a fixed resolution of 20 milliseconds. This approach overlooks the varying informational content present at different resolutions in speech signals. In contrast, this paper aims to incorporate multi-resolution information into speech self-supervised representation learning. We introduce a SSL model that leverages a hierarchical Transformer architecture, complemented by HuBERT-style masked prediction objectives, to process speech at multiple resolutions. Experimental results indicate that the proposed model not only achieves more efficient inference but also exhibits superior or comparable performance to the original HuBERT model over various tasks. Specifically, significant performance improvements over the original HuBERT have been observed in fine-tuning experiments on the LibriSpeech speech recognition benchmark as well as in evaluations using the Speech Universal PERformance Benchmark (SUPERB) and Multilingual SUPERB (ML-SUPERB).
Improving severity preservation of healthy-to-pathological voice conversion with global style tokens
Oct 04, 2023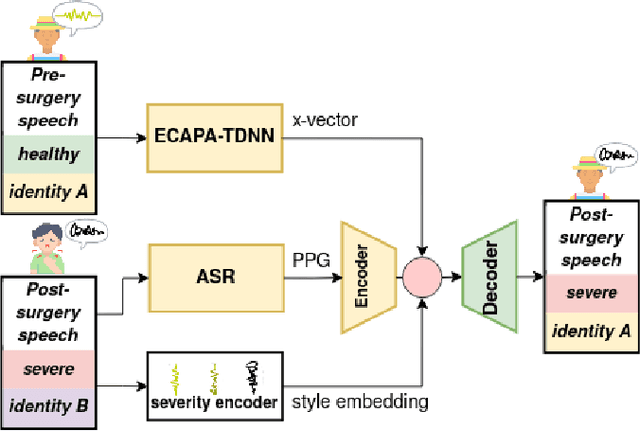


In healthy-to-pathological voice conversion (H2P-VC), healthy speech is converted into pathological while preserving the identity. The paper improves on previous two-stage approach to H2P-VC where (1) speech is created first with the appropriate severity, (2) then the speaker identity of the voice is converted while preserving the severity of the voice. Specifically, we propose improvements to (2) by using phonetic posteriorgrams (PPG) and global style tokens (GST). Furthermore, we present a new dataset that contains parallel recordings of pathological and healthy speakers with the same identity which allows more precise evaluation. Listening tests by expert listeners show that the framework preserves severity of the source sample, while modelling target speaker's voice. We also show that (a) pathology impacts x-vectors but not all speaker information is lost, (b) choosing source speakers based on severity labels alone is insufficient.
AstroCLIP: Cross-Modal Pre-Training for Astronomical Foundation Models
Oct 04, 2023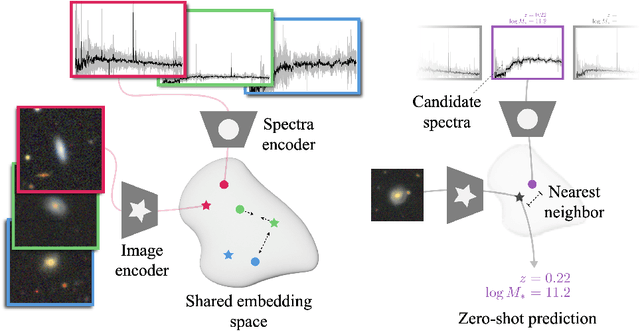
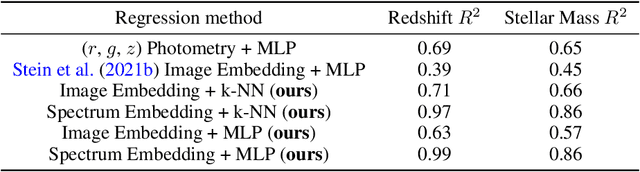
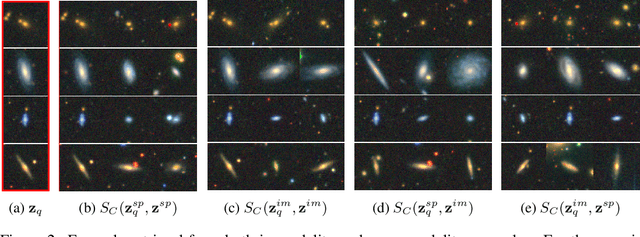
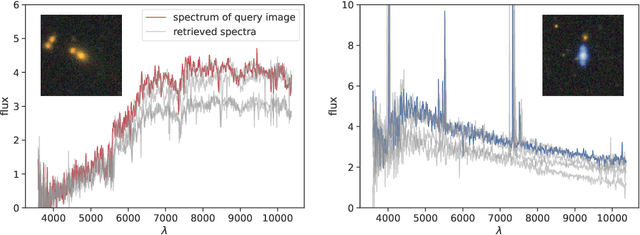
We present AstroCLIP, a strategy to facilitate the construction of astronomical foundation models that bridge the gap between diverse observational modalities. We demonstrate that a cross-modal contrastive learning approach between images and optical spectra of galaxies yields highly informative embeddings of both modalities. In particular, we apply our method on multi-band images and optical spectra from the Dark Energy Spectroscopic Instrument (DESI), and show that: (1) these embeddings are well-aligned between modalities and can be used for accurate cross-modal searches, and (2) these embeddings encode valuable physical information about the galaxies -- in particular redshift and stellar mass -- that can be used to achieve competitive zero- and few- shot predictions without further finetuning. Additionally, in the process of developing our approach, we also construct a novel, transformer-based model and pretraining approach for processing galaxy spectra.
Index-Modulated Metasurface Transceiver Design using Reconfigurable Intelligent Surfaces for 6G Wireless Networks
Oct 04, 2023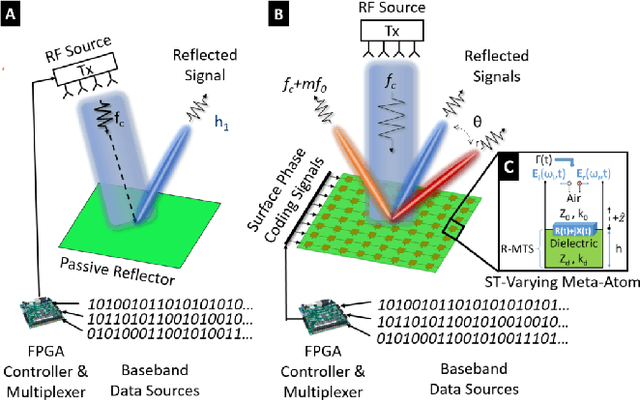
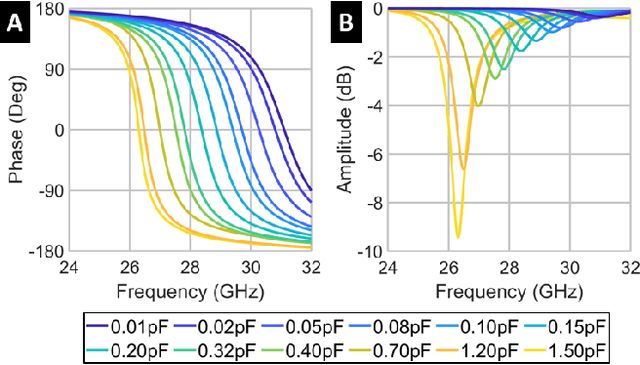
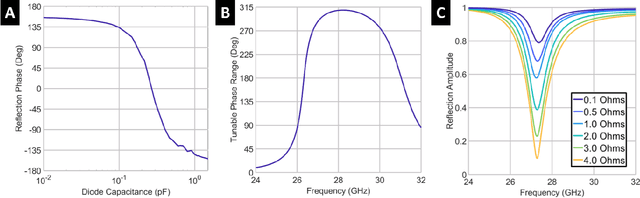
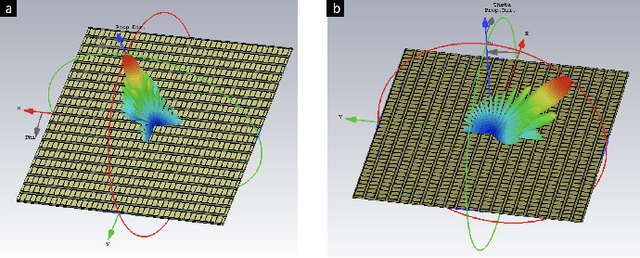
Higher spectral and energy efficiencies are the envisioned defining characteristics of high data-rate sixth-generation (6G) wireless networks. One of the enabling technologies to meet these requirements is index modulation (IM), which transmits information through permutations of indices of spatial, frequency, or temporal media. In this paper, we propose novel electromagnetics-compliant designs of reconfigurable intelligent surface (RIS) apertures for realizing IM in 6G transceivers. We consider RIS modeling and implementation of spatial and subcarrier IMs, including beam steering, spatial multiplexing, and phase modulation capabilities. Numerical experiments for our proposed implementations show that the bit error rates obtained via RIS-aided IM outperform traditional implementations. We further establish the programmability of these transceivers to vary the reflection phase and generate frequency harmonics for IM through full-wave electromagnetic analyses of a specific reflect-array metasurface implementation.
Spherical Position Encoding for Transformers
Oct 04, 2023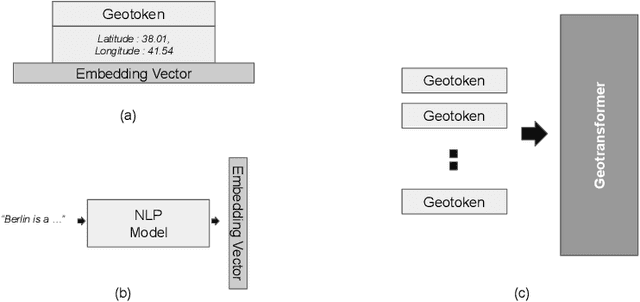
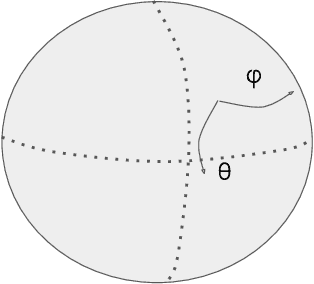
Position encoding is the primary mechanism which induces notion of sequential order for input tokens in transformer architectures. Even though this formulation in the original transformer paper has yielded plausible performance for general purpose language understanding and generation, several new frameworks such as Rotary Position Embedding (RoPE) are proposed for further enhancement. In this paper, we introduce the notion of "geotokens" which are input elements for transformer architectures, each representing an information related to a geological location. Unlike the natural language the sequential position is not important for the model but the geographical coordinates are. In order to induce the concept of relative position for such a setting and maintain the proportion between the physical distance and distance on embedding space, we formulate a position encoding mechanism based on RoPE architecture which is adjusted for spherical coordinates.
Causality-informed Rapid Post-hurricane Building Damage Detection in Large Scale from InSAR Imagery
Oct 02, 2023Timely and accurate assessment of hurricane-induced building damage is crucial for effective post-hurricane response and recovery efforts. Recently, remote sensing technologies provide large-scale optical or Interferometric Synthetic Aperture Radar (InSAR) imagery data immediately after a disastrous event, which can be readily used to conduct rapid building damage assessment. Compared to optical satellite imageries, the Synthetic Aperture Radar can penetrate cloud cover and provide more complete spatial coverage of damaged zones in various weather conditions. However, these InSAR imageries often contain highly noisy and mixed signals induced by co-occurring or co-located building damage, flood, flood/wind-induced vegetation changes, as well as anthropogenic activities, making it challenging to extract accurate building damage information. In this paper, we introduced an approach for rapid post-hurricane building damage detection from InSAR imagery. This approach encoded complex causal dependencies among wind, flood, building damage, and InSAR imagery using a holistic causal Bayesian network. Based on the causal Bayesian network, we further jointly inferred the large-scale unobserved building damage by fusing the information from InSAR imagery with prior physical models of flood and wind, without the need for ground truth labels. Furthermore, we validated our estimation results in a real-world devastating hurricane -- the 2022 Hurricane Ian. We gathered and annotated building damage ground truth data in Lee County, Florida, and compared the introduced method's estimation results with the ground truth and benchmarked it against state-of-the-art models to assess the effectiveness of our proposed method. Results show that our method achieves rapid and accurate detection of building damage, with significantly reduced processing time compared to traditional manual inspection methods.
Modality-aware Transformer for Time series Forecasting
Oct 02, 2023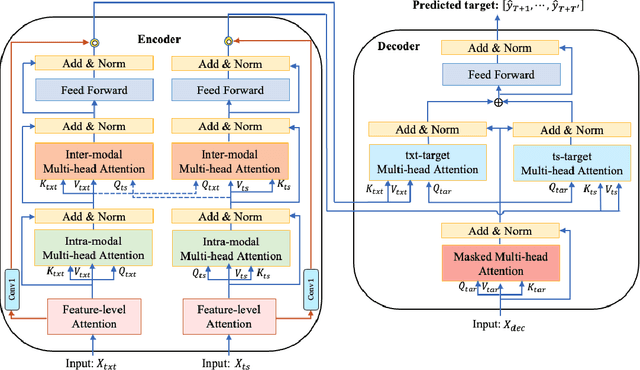

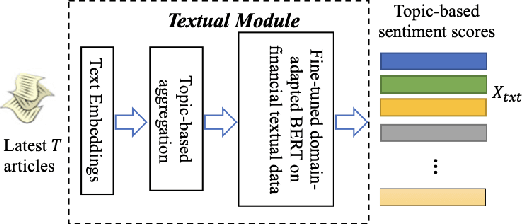
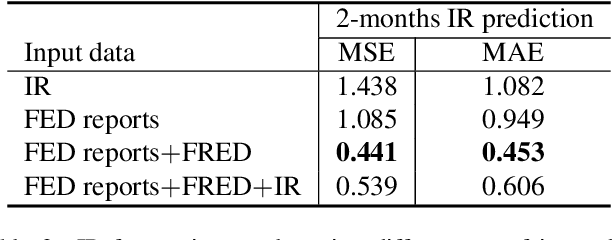
Time series forecasting presents a significant challenge, particularly when its accuracy relies on external data sources rather than solely on historical values. This issue is prevalent in the financial sector, where the future behavior of time series is often intricately linked to information derived from various textual reports and a multitude of economic indicators. In practice, the key challenge lies in constructing a reliable time series forecasting model capable of harnessing data from diverse sources and extracting valuable insights to predict the target time series accurately. In this work, we tackle this challenging problem and introduce a novel multimodal transformer-based model named the Modality-aware Transformer. Our model excels in exploring the power of both categorical text and numerical timeseries to forecast the target time series effectively while providing insights through its neural attention mechanism. To achieve this, we develop feature-level attention layers that encourage the model to focus on the most relevant features within each data modality. By incorporating the proposed feature-level attention, we develop a novel Intra-modal multi-head attention (MHA), Inter-modal MHA and Modality-target MHA in a way that both feature and temporal attentions are incorporated in MHAs. This enables the MHAs to generate temporal attentions with consideration of modality and feature importance which leads to more informative embeddings. The proposed modality-aware structure enables the model to effectively exploit information within each modality as well as foster cross-modal understanding. Our extensive experiments on financial datasets demonstrate that Modality-aware Transformer outperforms existing methods, offering a novel and practical solution to the complex challenges of multi-modality time series forecasting.
AANet: Aggregation and Alignment Network with Semi-hard Positive Sample Mining for Hierarchical Place Recognition
Oct 08, 2023Visual place recognition (VPR) is one of the research hotspots in robotics, which uses visual information to locate robots. Recently, the hierarchical two-stage VPR methods have become popular in this field due to the trade-off between accuracy and efficiency. These methods retrieve the top-k candidate images using the global features in the first stage, then re-rank the candidates by matching the local features in the second stage. However, they usually require additional algorithms (e.g. RANSAC) for geometric consistency verification in re-ranking, which is time-consuming. Here we propose a Dynamically Aligning Local Features (DALF) algorithm to align the local features under spatial constraints. It is significantly more efficient than the methods that need geometric consistency verification. We present a unified network capable of extracting global features for retrieving candidates via an aggregation module and aligning local features for re-ranking via the DALF alignment module. We call this network AANet. Meanwhile, many works use the simplest positive samples in triplet for weakly supervised training, which limits the ability of the network to recognize harder positive pairs. To address this issue, we propose a Semi-hard Positive Sample Mining (ShPSM) strategy to select appropriate hard positive images for training more robust VPR networks. Extensive experiments on four benchmark VPR datasets show that the proposed AANet can outperform several state-of-the-art methods with less time consumption. The code is released at https://github.com/Lu-Feng/AANet.
Layout Sequence Prediction From Noisy Mobile Modality
Oct 09, 2023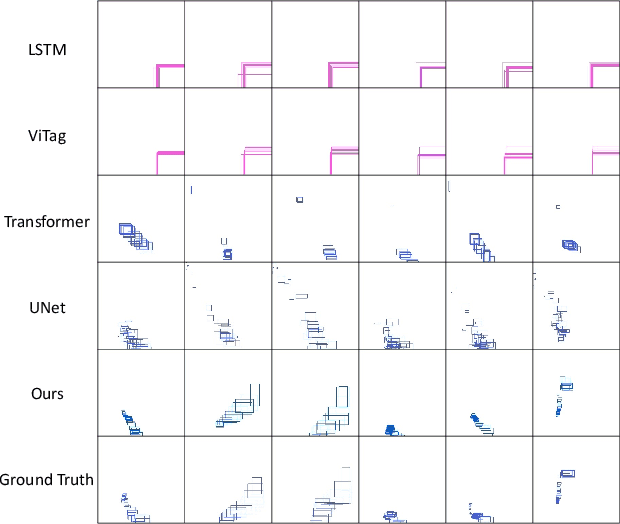
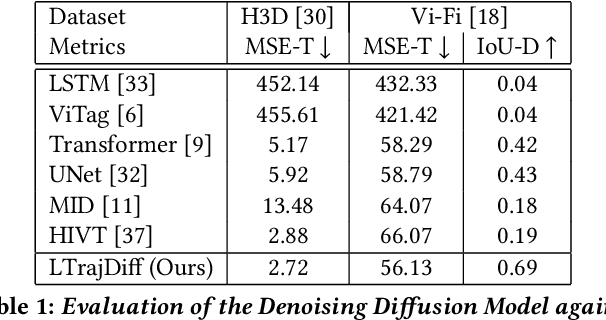
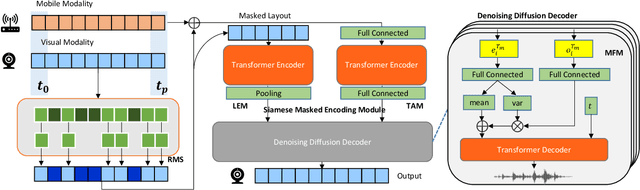
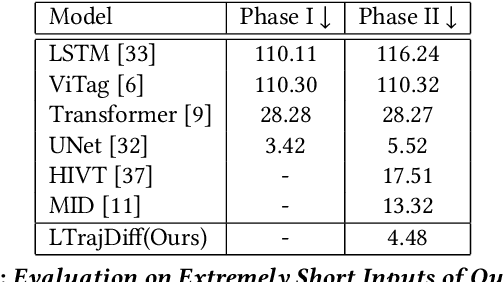
Trajectory prediction plays a vital role in understanding pedestrian movement for applications such as autonomous driving and robotics. Current trajectory prediction models depend on long, complete, and accurately observed sequences from visual modalities. Nevertheless, real-world situations often involve obstructed cameras, missed objects, or objects out of sight due to environmental factors, leading to incomplete or noisy trajectories. To overcome these limitations, we propose LTrajDiff, a novel approach that treats objects obstructed or out of sight as equally important as those with fully visible trajectories. LTrajDiff utilizes sensor data from mobile phones to surmount out-of-sight constraints, albeit introducing new challenges such as modality fusion, noisy data, and the absence of spatial layout and object size information. We employ a denoising diffusion model to predict precise layout sequences from noisy mobile data using a coarse-to-fine diffusion strategy, incorporating the RMS, Siamese Masked Encoding Module, and MFM. Our model predicts layout sequences by implicitly inferring object size and projection status from a single reference timestamp or significantly obstructed sequences. Achieving SOTA results in randomly obstructed experiments and extremely short input experiments, our model illustrates the effectiveness of leveraging noisy mobile data. In summary, our approach offers a promising solution to the challenges faced by layout sequence and trajectory prediction models in real-world settings, paving the way for utilizing sensor data from mobile phones to accurately predict pedestrian bounding box trajectories. To the best of our knowledge, this is the first work that addresses severely obstructed and extremely short layout sequences by combining vision with noisy mobile modality, making it the pioneering work in the field of layout sequence trajectory prediction.
Bi-directional Deformation for Parameterization of Neural Implicit Surfaces
Oct 09, 2023The growing capabilities of neural rendering have increased the demand for new techniques that enable the intuitive editing of 3D objects, particularly when they are represented as neural implicit surfaces. In this paper, we present a novel neural algorithm to parameterize neural implicit surfaces to simple parametric domains, such as spheres, cubes or polycubes, where 3D radiance field can be represented as a 2D field, thereby facilitating visualization and various editing tasks. Technically, our method computes a bi-directional deformation between 3D objects and their chosen parametric domains, eliminating the need for any prior information. We adopt a forward mapping of points on the zero level set of the 3D object to a parametric domain, followed by a backward mapping through inverse deformation. To ensure the map is bijective, we employ a cycle loss while optimizing the smoothness of both deformations. Additionally, we leverage a Laplacian regularizer to effectively control angle distortion and offer the flexibility to choose from a range of parametric domains for managing area distortion. Designed for compatibility, our framework integrates seamlessly with existing neural rendering pipelines, taking multi-view images as input to reconstruct 3D geometry and compute the corresponding texture map. We also introduce a simple yet effective technique for intrinsic radiance decomposition, facilitating both view-independent material editing and view-dependent shading editing. Our method allows for the immediate rendering of edited textures through volume rendering, without the need for network re-training. Moreover, our approach supports the co-parameterization of multiple objects and enables texture transfer between them. We demonstrate the effectiveness of our method on images of human heads and man-made objects. We will make the source code publicly available.