 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Optimal Sequential Decision-Making in Geosteering: A Reinforcement Learning Approach
Oct 07, 2023
Trajectory adjustment decisions throughout the drilling process, called geosteering, affect subsequent choices and information gathering, thus resulting in a coupled sequential decision problem. Previous works on applying decision optimization methods in geosteering rely on greedy optimization or Approximate Dynamic Programming (ADP). Either decision optimization method requires explicit uncertainty and objective function models, making developing decision optimization methods for complex and realistic geosteering environments challenging to impossible. We use the Deep Q-Network (DQN) method, a model-free reinforcement learning (RL) method that learns directly from the decision environment, to optimize geosteering decisions. The expensive computations for RL are handled during the offline training stage. Evaluating DQN needed for real-time decision support takes milliseconds and is faster than the traditional alternatives. Moreover, for two previously published synthetic geosteering scenarios, our results show that RL achieves high-quality outcomes comparable to the quasi-optimal ADP. Yet, the model-free nature of RL means that by replacing the training environment, we can extend it to problems where the solution to ADP is prohibitively expensive to compute. This flexibility will allow applying it to more complex environments and make hybrid versions trained with real data in the future.
GradXKG: A Universal Explain-per-use Temporal Knowledge Graph Explainer
Oct 07, 2023Temporal knowledge graphs (TKGs) have shown promise for reasoning tasks by incorporating a temporal dimension to represent how facts evolve over time. However, existing TKG reasoning (TKGR) models lack explainability due to their black-box nature. Recent work has attempted to address this through customized model architectures that generate reasoning paths, but these recent approaches have limited generalizability and provide sparse explanatory output. To enable interpretability for most TKGR models, we propose GradXKG, a novel two-stage gradient-based approach for explaining Relational Graph Convolution Network (RGCN)-based TKGR models. First, a Grad-CAM-inspired RGCN explainer tracks gradients to quantify each node's contribution across timesteps in an efficient "explain-per-use" fashion. Second, an integrated gradients explainer consolidates importance scores for RGCN outputs, extending compatibility across diverse TKGR architectures based on RGCN. Together, the two explainers highlight the most critical nodes at each timestep for a given prediction. Our extensive experiments demonstrated that, by leveraging gradient information, GradXKG provides insightful explanations grounded in the model's logic in a timely manner for most RGCN-based TKGR models. This helps address the lack of interpretability in existing TKGR models and provides a universal explanation approach applicable across various models.
Semantic Map Learning of Traffic Light to Lane Assignment based on Motion Data
Sep 28, 2023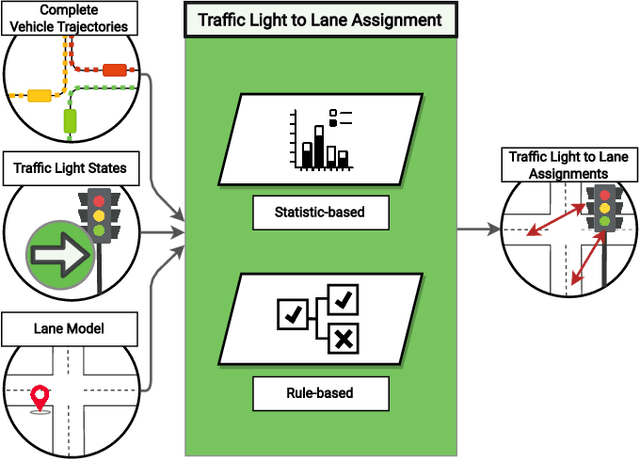
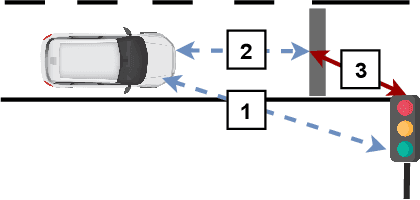
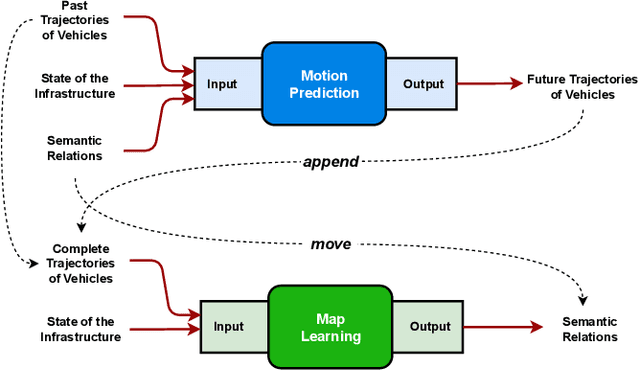
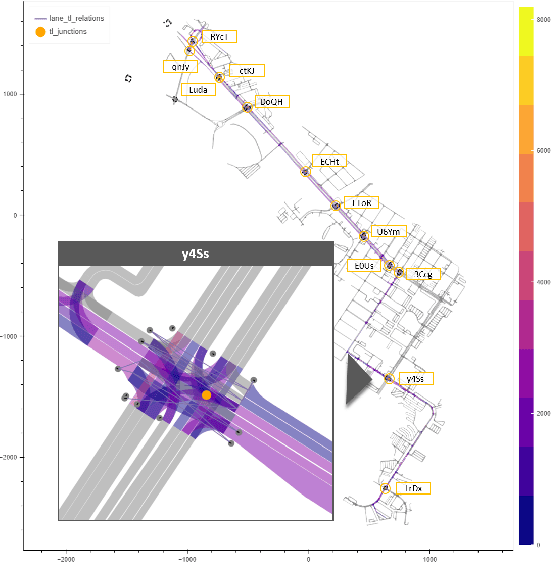
Understanding which traffic light controls which lane is crucial to navigate intersections safely. Autonomous vehicles commonly rely on High Definition (HD) maps that contain information about the assignment of traffic lights to lanes. The manual provisioning of this information is tedious, expensive, and not scalable. To remedy these issues, our novel approach derives the assignments from traffic light states and the corresponding motion patterns of vehicle traffic. This works in an automated way and independently of the geometric arrangement. We show the effectiveness of basic statistical approaches for this task by implementing and evaluating a pattern-based contribution method. In addition, our novel rejection method includes accompanying safety considerations by leveraging statistical hypothesis testing. Finally, we propose a dataset transformation to re-purpose available motion prediction datasets for semantic map learning. Our publicly available API for the Lyft Level 5 dataset enables researchers to develop and evaluate their own approaches.
Redefining Digital Health Interfaces with Large Language Models
Oct 05, 2023Digital health tools have the potential to significantly improve the delivery of healthcare services. However, their use remains comparatively limited due, in part, to challenges surrounding usability and trust. Recently, Large Language Models (LLMs) have emerged as general-purpose models with the ability to process complex information and produce human-quality text, presenting a wealth of potential applications in healthcare. Directly applying LLMs in clinical settings is not straightforward, with LLMs susceptible to providing inconsistent or nonsensical answers. We demonstrate how LLMs can utilize external tools to provide a novel interface between clinicians and digital technologies. This enhances the utility and practical impact of digital healthcare tools and AI models while addressing current issues with using LLM in clinical settings such as hallucinations. We illustrate our approach with examples from cardiovascular disease and diabetes risk prediction, highlighting the benefit compared to traditional interfaces for digital tools.
Comparing Time-Series Analysis Approaches Utilized in Research Papers to Forecast COVID-19 Cases in Africa: A Literature Review
Oct 05, 2023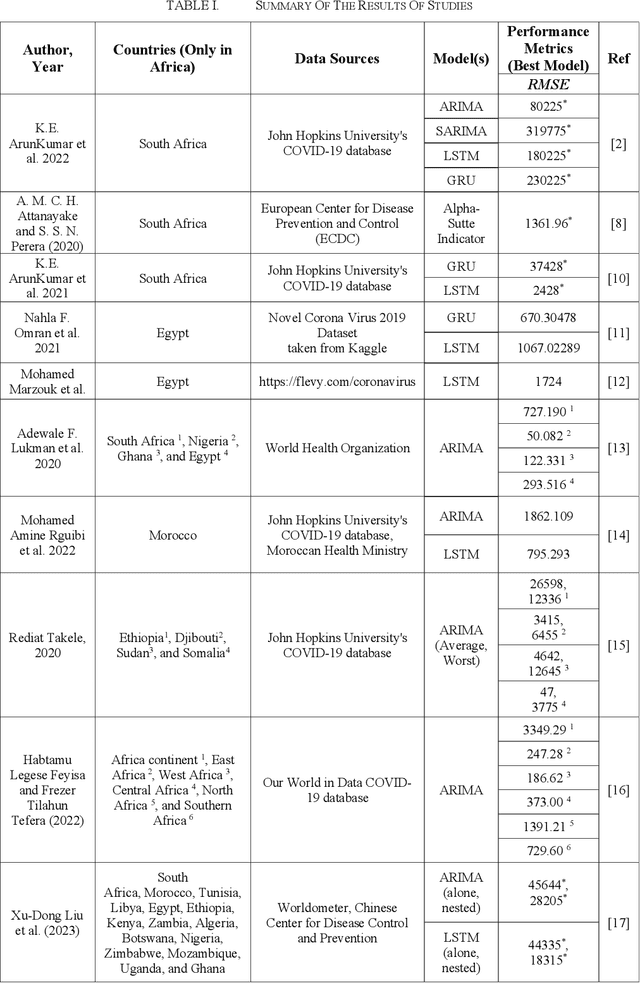
This literature review aimed to compare various time-series analysis approaches utilized in forecasting COVID-19 cases in Africa. The study involved a methodical search for English-language research papers published between January 2020 and July 2023, focusing specifically on papers that utilized time-series analysis approaches on COVID-19 datasets in Africa. A variety of databases including PubMed, Google Scholar, Scopus, and Web of Science were utilized for this process. The research papers underwent an evaluation process to extract relevant information regarding the implementation and performance of the time-series analysis models. The study highlighted the different methodologies employed, evaluating their effectiveness and limitations in forecasting the spread of the virus. The result of this review could contribute deeper insights into the field, and future research should consider these insights to improve time series analysis models and explore the integration of different approaches for enhanced public health decision-making.
HAvatar: High-fidelity Head Avatar via Facial Model Conditioned Neural Radiance Field
Sep 29, 2023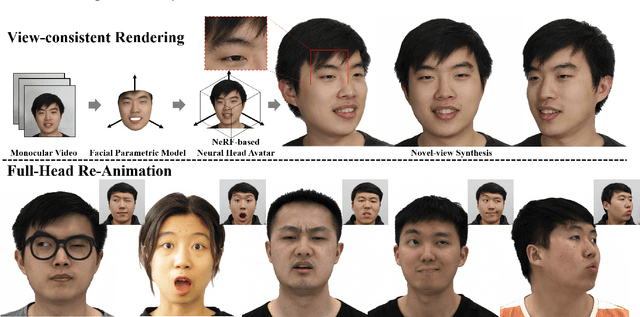
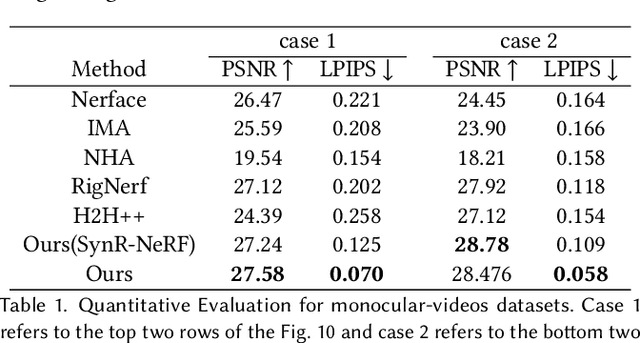
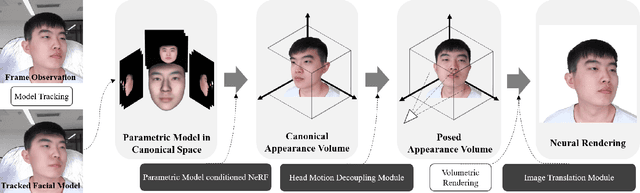
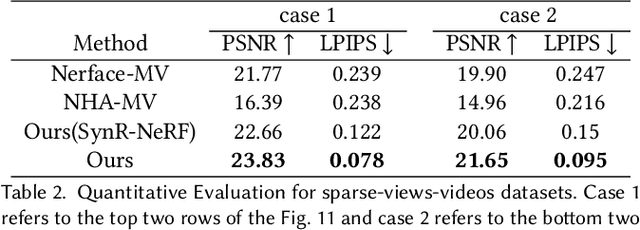
The problem of modeling an animatable 3D human head avatar under light-weight setups is of significant importance but has not been well solved. Existing 3D representations either perform well in the realism of portrait images synthesis or the accuracy of expression control, but not both. To address the problem, we introduce a novel hybrid explicit-implicit 3D representation, Facial Model Conditioned Neural Radiance Field, which integrates the expressiveness of NeRF and the prior information from the parametric template. At the core of our representation, a synthetic-renderings-based condition method is proposed to fuse the prior information from the parametric model into the implicit field without constraining its topological flexibility. Besides, based on the hybrid representation, we properly overcome the inconsistent shape issue presented in existing methods and improve the animation stability. Moreover, by adopting an overall GAN-based architecture using an image-to-image translation network, we achieve high-resolution, realistic and view-consistent synthesis of dynamic head appearance. Experiments demonstrate that our method can achieve state-of-the-art performance for 3D head avatar animation compared with previous methods.
MinPrompt: Graph-based Minimal Prompt Data Augmentation for Few-shot Question Answering
Oct 08, 2023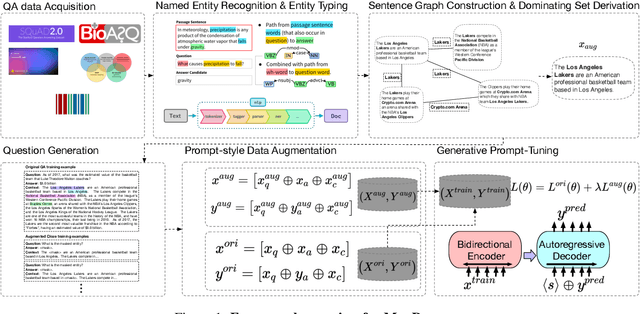

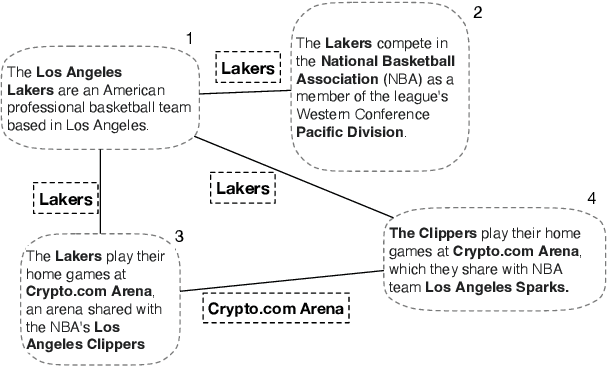
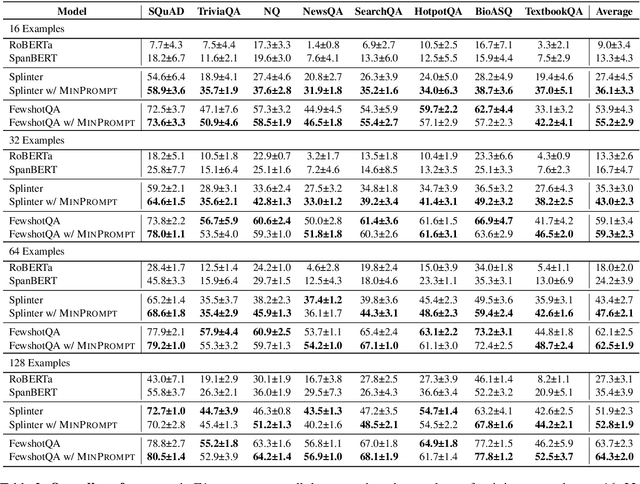
Few-shot question answering (QA) aims at achieving satisfactory results on machine question answering when only a few training samples are available. Recent advances mostly rely on the power of pre-trained large language models (LLMs) and fine-tuning in specific settings. Although the pre-training stage has already equipped LLMs with powerful reasoning capabilities, LLMs still need to be fine-tuned to adapt to specific domains to achieve the best results. In this paper, we propose to select the most informative data for fine-tuning, thereby improving the efficiency of the fine-tuning process with comparative or even better accuracy on the open-domain QA task. We present MinPrompt, a minimal data augmentation framework for open-domain QA based on an approximate graph algorithm and unsupervised question generation. We transform the raw text into a graph structure to build connections between different factual sentences, then apply graph algorithms to identify the minimal set of sentences needed to cover the most information in the raw text. We then generate QA pairs based on the identified sentence subset and train the model on the selected sentences to obtain the final model. Empirical results on several benchmark datasets and theoretical analysis show that MinPrompt is able to achieve comparable or better results than baselines with a high degree of efficiency, bringing improvements in F-1 scores by up to 27.5%.
V2X-AHD:Vehicle-to-Everything Cooperation Perception via Asymmetric Heterogenous Distillation Network
Oct 10, 2023
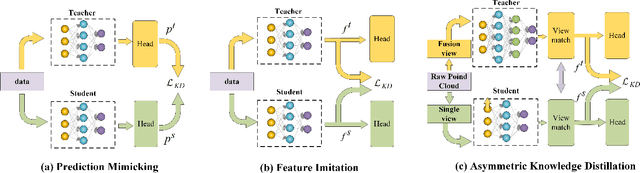
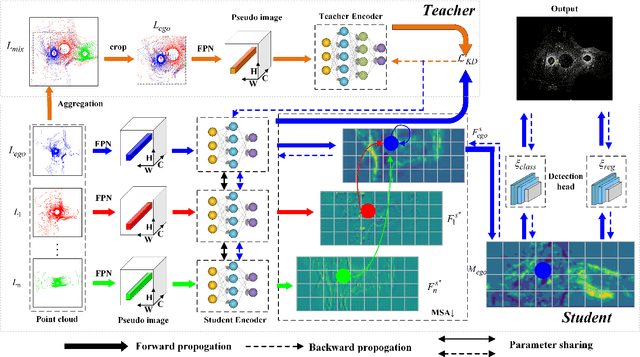
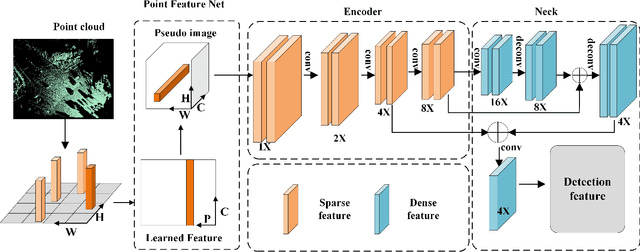
Object detection is the central issue of intelligent traffic systems, and recent advancements in single-vehicle lidar-based 3D detection indicate that it can provide accurate position information for intelligent agents to make decisions and plan. Compared with single-vehicle perception, multi-view vehicle-road cooperation perception has fundamental advantages, such as the elimination of blind spots and a broader range of perception, and has become a research hotspot. However, the current perception of cooperation focuses on improving the complexity of fusion while ignoring the fundamental problems caused by the absence of single-view outlines. We propose a multi-view vehicle-road cooperation perception system, vehicle-to-everything cooperative perception (V2X-AHD), in order to enhance the identification capability, particularly for predicting the vehicle's shape. At first, we propose an asymmetric heterogeneous distillation network fed with different training data to improve the accuracy of contour recognition, with multi-view teacher features transferring to single-view student features. While the point cloud data are sparse, we propose Spara Pillar, a spare convolutional-based plug-in feature extraction backbone, to reduce the number of parameters and improve and enhance feature extraction capabilities. Moreover, we leverage the multi-head self-attention (MSA) to fuse the single-view feature, and the lightweight design makes the fusion feature a smooth expression. The results of applying our algorithm to the massive open dataset V2Xset demonstrate that our method achieves the state-of-the-art result. The V2X-AHD can effectively improve the accuracy of 3D object detection and reduce the number of network parameters, according to this study, which serves as a benchmark for cooperative perception. The code for this article is available at https://github.com/feeling0414-lab/V2X-AHD.
High-dimensional SGD aligns with emerging outlier eigenspaces
Oct 04, 2023We rigorously study the joint evolution of training dynamics via stochastic gradient descent (SGD) and the spectra of empirical Hessian and gradient matrices. We prove that in two canonical classification tasks for multi-class high-dimensional mixtures and either 1 or 2-layer neural networks, the SGD trajectory rapidly aligns with emerging low-rank outlier eigenspaces of the Hessian and gradient matrices. Moreover, in multi-layer settings this alignment occurs per layer, with the final layer's outlier eigenspace evolving over the course of training, and exhibiting rank deficiency when the SGD converges to sub-optimal classifiers. This establishes some of the rich predictions that have arisen from extensive numerical studies in the last decade about the spectra of Hessian and information matrices over the course of training in overparametrized networks.
A Language-Agent Approach to Formal Theorem-Proving
Oct 06, 2023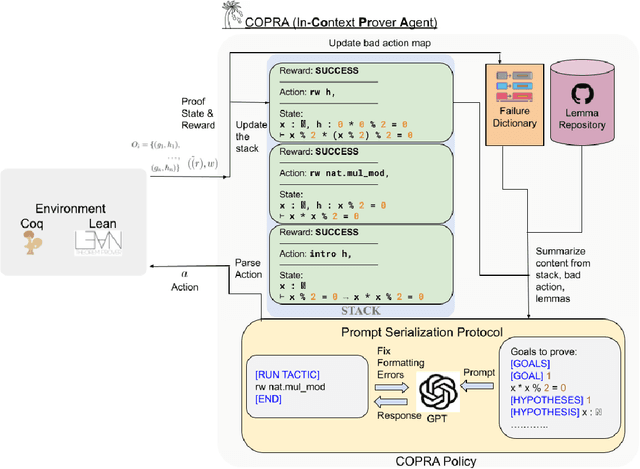
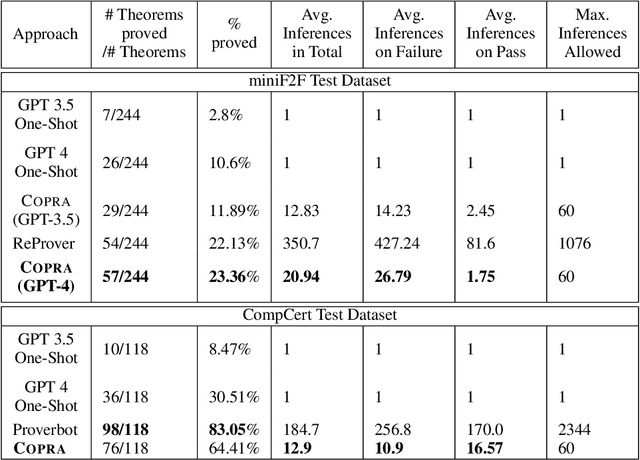

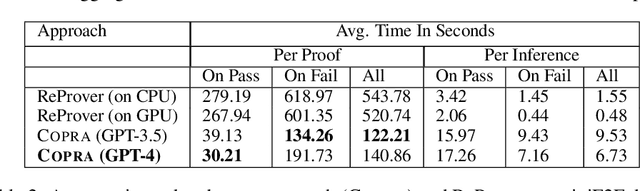
Language agents, which use a large language model (LLM) capable of in-context learning to interact with an external environment, have recently emerged as a promising approach to control tasks. We present the first language-agent approach to formal theorem-proving. Our method, COPRA, uses a high-capacity, black-box LLM (GPT-4) as part of a policy for a stateful backtracking search. During the search, the policy can select proof tactics and retrieve lemmas and definitions from an external database. Each selected tactic is executed in the underlying proof framework, and the execution feedback is used to build the prompt for the next policy invocation. The search also tracks selected information from its history and uses it to reduce hallucinations and unnecessary LLM queries. We evaluate COPRA on the miniF2F benchmark for Lean and a set of Coq tasks from the Compcert project. On these benchmarks, COPRA is significantly better than one-shot invocations of GPT-4, as well as state-of-the-art models fine-tuned on proof data, at finding correct proofs quickly.