 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pain Forecasting using Self-supervised Learning and Patient Phenotyping: An attempt to prevent Opioid Addiction
Oct 09, 2023
Sickle Cell Disease (SCD) is a chronic genetic disorder characterized by recurrent acute painful episodes. Opioids are often used to manage these painful episodes; the extent of their use in managing pain in this disorder is an issue of debate. The risk of addiction and side effects of these opioid treatments can often lead to more pain episodes in the future. Hence, it is crucial to forecast future patient pain trajectories to help patients manage their SCD to improve their quality of life without compromising their treatment. It is challenging to obtain many pain records to design forecasting models since it is mainly recorded by patients' self-report. Therefore, it is expensive and painful (due to the need for patient compliance) to solve pain forecasting problems in a purely supervised manner. In light of this challenge, we propose to solve the pain forecasting problem using self-supervised learning methods. Also, clustering such time-series data is crucial for patient phenotyping, anticipating patients' prognoses by identifying "similar" patients, and designing treatment guidelines tailored to homogeneous patient subgroups. Hence, we propose a self-supervised learning approach for clustering time-series data, where each cluster comprises patients who share similar future pain profiles. Experiments on five years of real-world datasets show that our models achieve superior performance over state-of-the-art benchmarks and identify meaningful clusters that can be translated into actionable information for clinical decision-making.
A Lightweight Video Anomaly Detection Model with Weak Supervision and Adaptive Instance Selection
Oct 09, 2023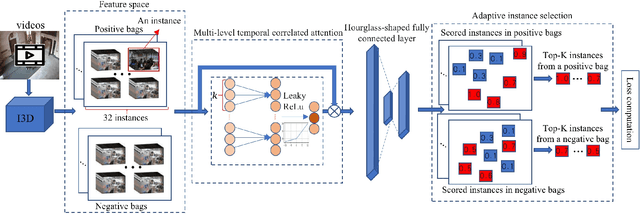
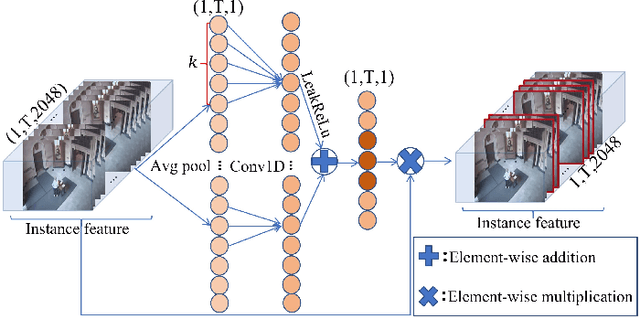
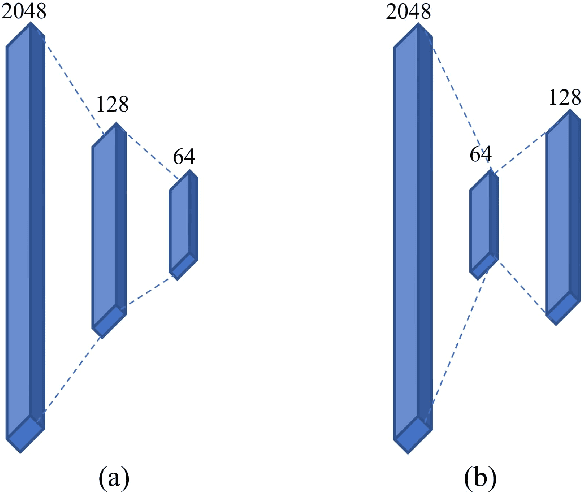
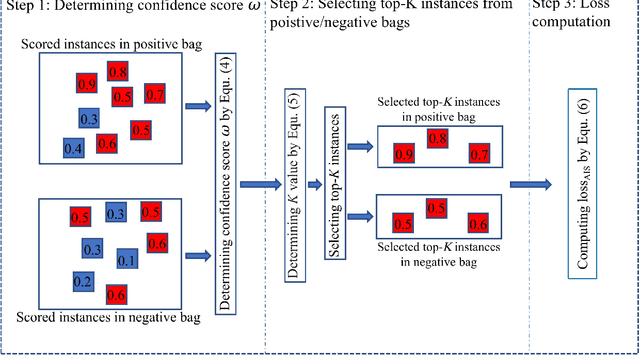
Video anomaly detection is to determine whether there are any abnormal events, behaviors or objects in a given video, which enables effective and intelligent public safety management. As video anomaly labeling is both time-consuming and expensive, most existing works employ unsupervised or weakly supervised learning methods. This paper focuses on weakly supervised video anomaly detection, in which the training videos are labeled whether or not they contain any anomalies, but there is no information about which frames the anomalies are located. However, the uncertainty of weakly labeled data and the large model size prevent existing methods from wide deployment in real scenarios, especially the resource-limit situations such as edge-computing. In this paper, we develop a lightweight video anomaly detection model. On the one hand, we propose an adaptive instance selection strategy, which is based on the model's current status to select confident instances, thereby mitigating the uncertainty of weakly labeled data and subsequently promoting the model's performance. On the other hand, we design a lightweight multi-level temporal correlation attention module and an hourglass-shaped fully connected layer to construct the model, which can reduce the model parameters to only 0.56\% of the existing methods (e.g. RTFM). Our extensive experiments on two public datasets UCF-Crime and ShanghaiTech show that our model can achieve comparable or even superior AUC score compared to the state-of-the-art methods, with a significantly reduced number of model parameters.
Filter Pruning For CNN With Enhanced Linear Representation Redundancy
Oct 10, 2023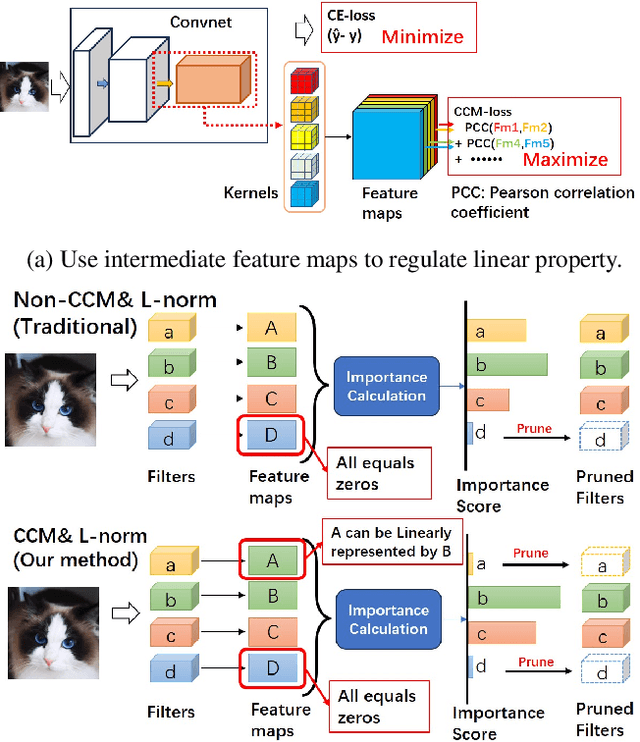
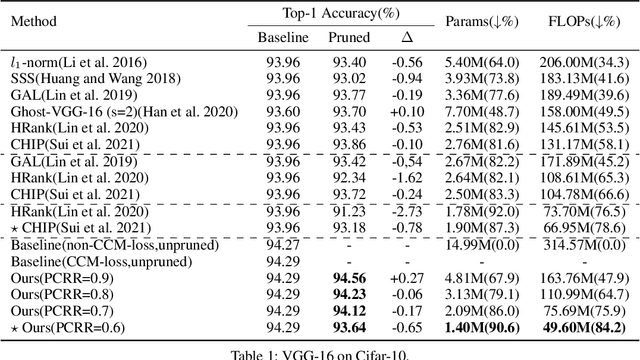
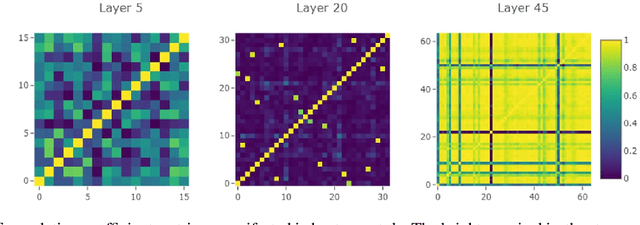
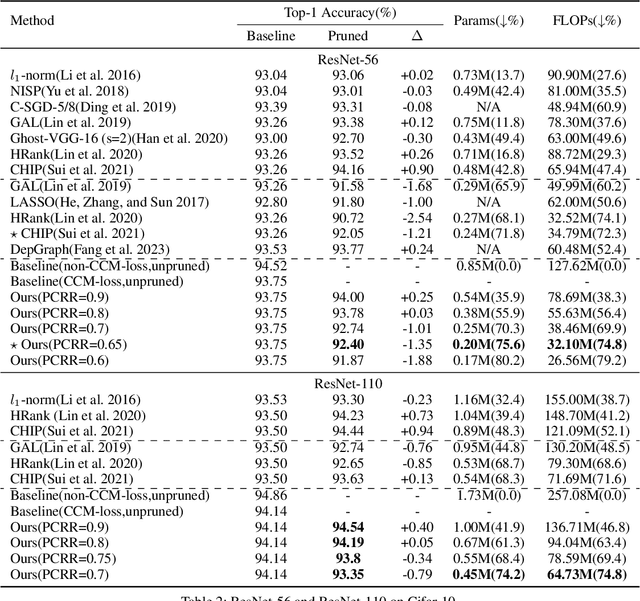
Structured network pruning excels non-structured methods because they can take advantage of the thriving developed parallel computing techniques. In this paper, we propose a new structured pruning method. Firstly, to create more structured redundancy, we present a data-driven loss function term calculated from the correlation coefficient matrix of different feature maps in the same layer, named CCM-loss. This loss term can encourage the neural network to learn stronger linear representation relations between feature maps during the training from the scratch so that more homogenous parts can be removed later in pruning. CCM-loss provides us with another universal transcendental mathematical tool besides L*-norm regularization, which concentrates on generating zeros, to generate more redundancy but for the different genres. Furthermore, we design a matching channel selection strategy based on principal components analysis to exploit the maximum potential ability of CCM-loss. In our new strategy, we mainly focus on the consistency and integrality of the information flow in the network. Instead of empirically hard-code the retain ratio for each layer, our channel selection strategy can dynamically adjust each layer's retain ratio according to the specific circumstance of a per-trained model to push the prune ratio to the limit. Notably, on the Cifar-10 dataset, our method brings 93.64% accuracy for pruned VGG-16 with only 1.40M parameters and 49.60M FLOPs, the pruned ratios for parameters and FLOPs are 90.6% and 84.2%, respectively. For ResNet-50 trained on the ImageNet dataset, our approach achieves 42.8% and 47.3% storage and computation reductions, respectively, with an accuracy of 76.23%. Our code is available at https://github.com/Bojue-Wang/CCM-LRR.
Balancing stability and plasticity in continual learning: the readout-decomposition of activation change (RDAC) framework
Oct 10, 2023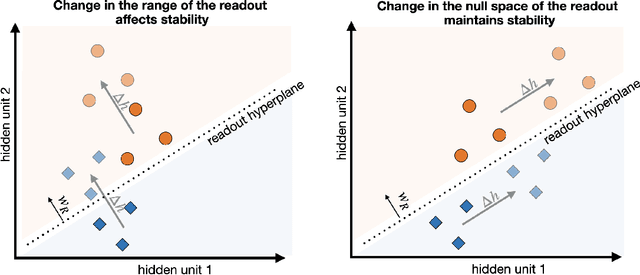
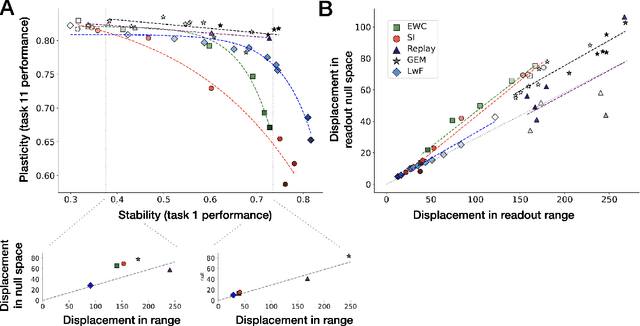
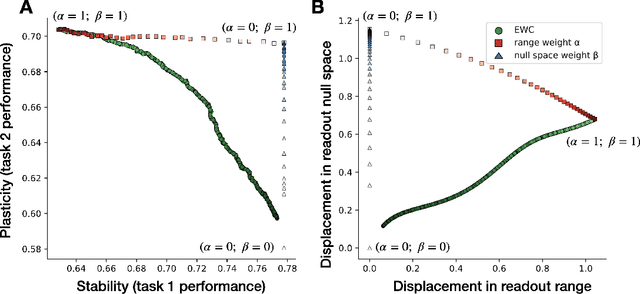
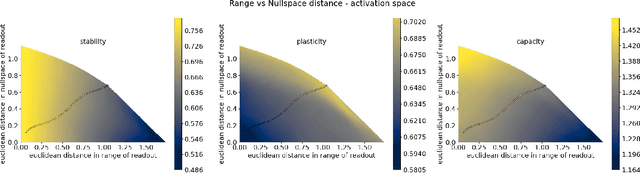
Continual learning (CL) algorithms strive to acquire new knowledge while preserving prior information. However, this stability-plasticity trade-off remains a central challenge. This paper introduces a framework that dissects this trade-off, offering valuable insights into CL algorithms. The Readout-Decomposition of Activation Change (RDAC) framework first addresses the stability-plasticity dilemma and its relation to catastrophic forgetting. It relates learning-induced activation changes in the range of prior readouts to the degree of stability and changes in the null space to the degree of plasticity. In deep non-linear networks tackling split-CIFAR-110 tasks, the framework clarifies the stability-plasticity trade-offs of the popular regularization algorithms Synaptic intelligence (SI), Elastic-weight consolidation (EWC), and learning without Forgetting (LwF), and replay-based algorithms Gradient episodic memory (GEM), and data replay. GEM and data replay preserved stability and plasticity, while SI, EWC, and LwF traded off plasticity for stability. The inability of the regularization algorithms to maintain plasticity was linked to them restricting the change of activations in the null space of the prior readout. Additionally, for one-hidden-layer linear neural networks, we derived a gradient decomposition algorithm to restrict activation change only in the range of the prior readouts, to maintain high stability while not further sacrificing plasticity. Results demonstrate that the algorithm maintained stability without significant plasticity loss. The RDAC framework informs the behavior of existing CL algorithms and paves the way for novel CL approaches. Finally, it sheds light on the connection between learning-induced activation/representation changes and the stability-plasticity dilemma, also offering insights into representational drift in biological systems.
The Lattice Overparametrization Paradigm for the Machine Learning of Lattice Operators
Oct 10, 2023The machine learning of lattice operators has three possible bottlenecks. From a statistical standpoint, it is necessary to design a constrained class of operators based on prior information with low bias, and low complexity relative to the sample size. From a computational perspective, there should be an efficient algorithm to minimize an empirical error over the class. From an understanding point of view, the properties of the learned operator need to be derived, so its behavior can be theoretically understood. The statistical bottleneck can be overcome due to the rich literature about the representation of lattice operators, but there is no general learning algorithm for them. In this paper, we discuss a learning paradigm in which, by overparametrizing a class via elements in a lattice, an algorithm for minimizing functions in a lattice is applied to learn. We present the stochastic lattice gradient descent algorithm as a general algorithm to learn on constrained classes of operators as long as a lattice overparametrization of it is fixed, and we discuss previous works which are proves of concept. Moreover, if there are algorithms to compute the basis of an operator from its overparametrization, then its properties can be deduced and the understanding bottleneck is also overcome. This learning paradigm has three properties that modern methods based on neural networks lack: control, transparency and interpretability. Nowadays, there is an increasing demand for methods with these characteristics, and we believe that mathematical morphology is in a unique position to supply them. The lattice overparametrization paradigm could be a missing piece for it to achieve its full potential within modern machine learning.
CarDS-Plus ECG Platform: Development and Feasibility Evaluation of a Multiplatform Artificial Intelligence Toolkit for Portable and Wearable Device Electrocardiograms
Oct 10, 2023In the rapidly evolving landscape of modern healthcare, the integration of wearable & portable technology provides a unique opportunity for personalized health monitoring in the community. Devices like the Apple Watch, FitBit, and AliveCor KardiaMobile have revolutionized the acquisition and processing of intricate health data streams. Amidst the variety of data collected by these gadgets, single-lead electrocardiogram (ECG) recordings have emerged as a crucial source of information for monitoring cardiovascular health. There has been significant advances in artificial intelligence capable of interpreting these 1-lead ECGs, facilitating clinical diagnosis as well as the detection of rare cardiac disorders. This design study describes the development of an innovative multiplatform system aimed at the rapid deployment of AI-based ECG solutions for clinical investigation & care delivery. The study examines design considerations, aligning them with specific applications, develops data flows to maximize efficiency for research & clinical use. This process encompasses the reception of single-lead ECGs from diverse wearable devices, channeling this data into a centralized data lake & facilitating real-time inference through AI models for ECG interpretation. An evaluation of the platform demonstrates a mean duration from acquisition to reporting of results of 33.0 to 35.7 seconds, after a standard 30 second acquisition. There were no substantial differences in acquisition to reporting across two commercially available devices (Apple Watch and KardiaMobile). These results demonstrate the succcessful translation of design principles into a fully integrated & efficient strategy for leveraging 1-lead ECGs across platforms & interpretation by AI-ECG algorithms. Such a platform is critical to translating AI discoveries for wearable and portable ECG devices to clinical impact through rapid deployment.
GPT-4 as an Agronomist Assistant? Answering Agriculture Exams Using Large Language Models
Oct 10, 2023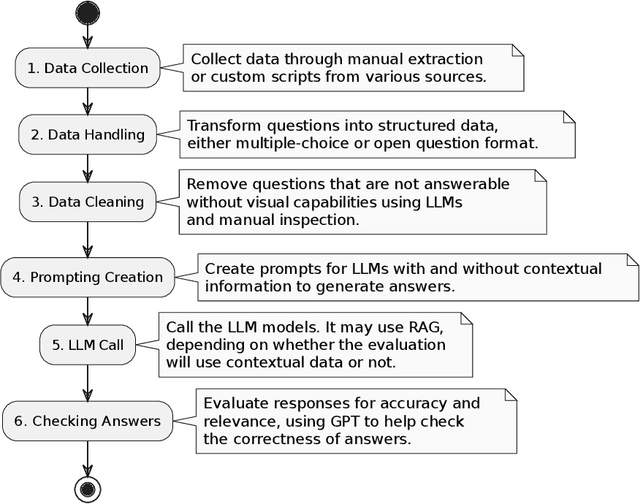

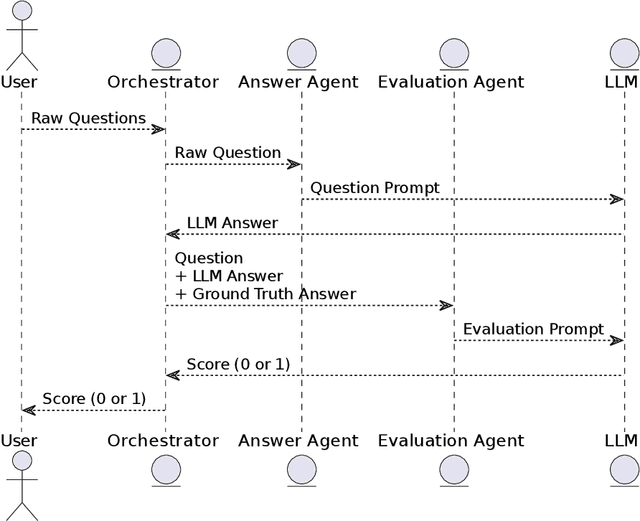

Large language models (LLMs) have demonstrated remarkable capabilities in natural language understanding across various domains, including healthcare and finance. For some tasks, LLMs achieve similar or better performance than trained human beings, therefore it is reasonable to employ human exams (e.g., certification tests) to assess the performance of LLMs. We present a comprehensive evaluation of popular LLMs, such as Llama 2 and GPT, on their ability to answer agriculture-related questions. In our evaluation, we also employ RAG (Retrieval-Augmented Generation) and ER (Ensemble Refinement) techniques, which combine information retrieval, generation capabilities, and prompting strategies to improve the LLMs' performance. To demonstrate the capabilities of LLMs, we selected agriculture exams and benchmark datasets from three of the largest agriculture producer countries: Brazil, India, and the USA. Our analysis highlights GPT-4's ability to achieve a passing score on exams to earn credits for renewing agronomist certifications, answering 93% of the questions correctly and outperforming earlier general-purpose models, which achieved 88% accuracy. On one of our experiments, GPT-4 obtained the highest performance when compared to human subjects. This performance suggests that GPT-4 could potentially pass on major graduate education admission tests or even earn credits for renewing agronomy certificates. We also explore the models' capacity to address general agriculture-related questions and generate crop management guidelines for Brazilian and Indian farmers, utilizing robust datasets from the Brazilian Agency of Agriculture (Embrapa) and graduate program exams from India. The results suggest that GPT-4, ER, and RAG can contribute meaningfully to agricultural education, assessment, and crop management practice, offering valuable insights to farmers and agricultural professionals.
ResolvNet: A Graph Convolutional Network with multi-scale Consistency
Sep 30, 2023It is by now a well known fact in the graph learning community that the presence of bottlenecks severely limits the ability of graph neural networks to propagate information over long distances. What so far has not been appreciated is that, counter-intuitively, also the presence of strongly connected sub-graphs may severely restrict information flow in common architectures. Motivated by this observation, we introduce the concept of multi-scale consistency. At the node level this concept refers to the retention of a connected propagation graph even if connectivity varies over a given graph. At the graph-level, multi-scale consistency refers to the fact that distinct graphs describing the same object at different resolutions should be assigned similar feature vectors. As we show, both properties are not satisfied by poular graph neural network architectures. To remedy these shortcomings, we introduce ResolvNet, a flexible graph neural network based on the mathematical concept of resolvents. We rigorously establish its multi-scale consistency theoretically and verify it in extensive experiments on real world data: Here networks based on this ResolvNet architecture prove expressive; out-performing baselines significantly on many tasks; in- and outside the multi-scale setting.
RPEFlow: Multimodal Fusion of RGB-PointCloud-Event for Joint Optical Flow and Scene Flow Estimation
Sep 26, 2023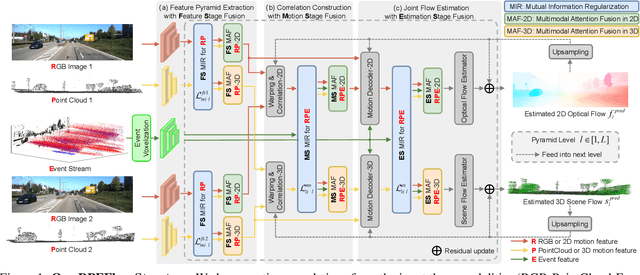
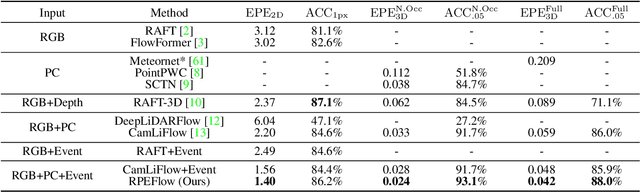
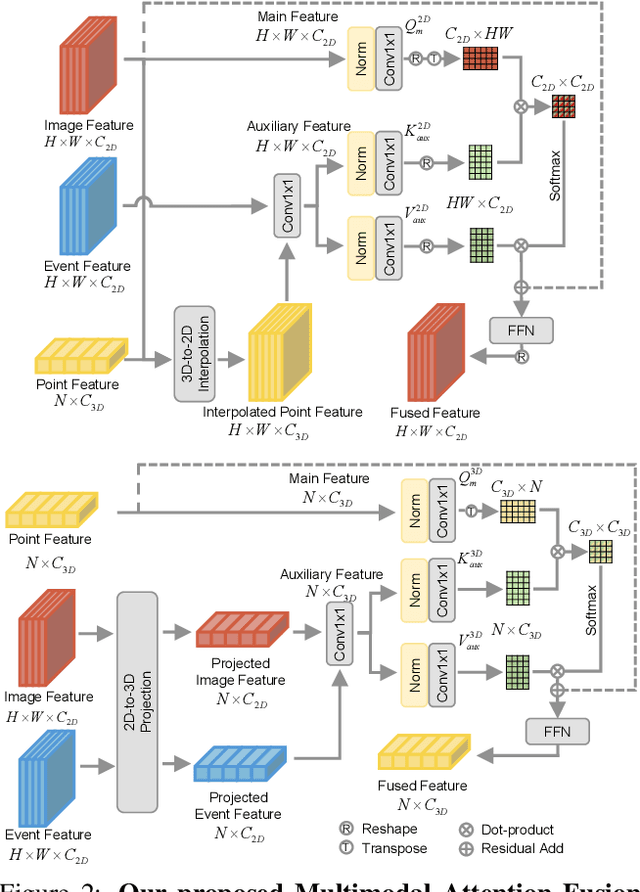
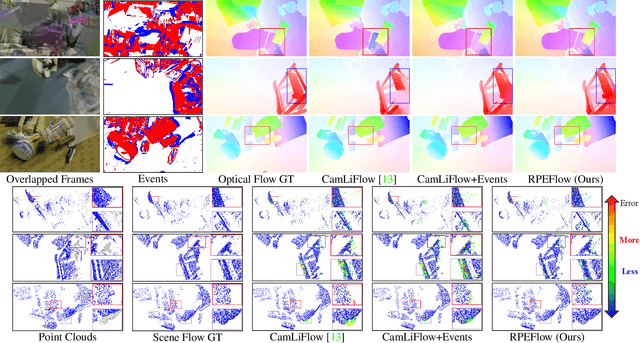
Recently, the RGB images and point clouds fusion methods have been proposed to jointly estimate 2D optical flow and 3D scene flow. However, as both conventional RGB cameras and LiDAR sensors adopt a frame-based data acquisition mechanism, their performance is limited by the fixed low sampling rates, especially in highly-dynamic scenes. By contrast, the event camera can asynchronously capture the intensity changes with a very high temporal resolution, providing complementary dynamic information of the observed scenes. In this paper, we incorporate RGB images, Point clouds and Events for joint optical flow and scene flow estimation with our proposed multi-stage multimodal fusion model, RPEFlow. First, we present an attention fusion module with a cross-attention mechanism to implicitly explore the internal cross-modal correlation for 2D and 3D branches, respectively. Second, we introduce a mutual information regularization term to explicitly model the complementary information of three modalities for effective multimodal feature learning. We also contribute a new synthetic dataset to advocate further research. Experiments on both synthetic and real datasets show that our model outperforms the existing state-of-the-art by a wide margin. Code and dataset is available at https://npucvr.github.io/RPEFlow.
Contrastive Continual Multi-view Clustering with Filtered Structural Fusion
Sep 26, 2023Multi-view clustering thrives in applications where views are collected in advance by extracting consistent and complementary information among views. However, it overlooks scenarios where data views are collected sequentially, i.e., real-time data. Due to privacy issues or memory burden, previous views are not available with time in these situations. Some methods are proposed to handle it but are trapped in a stability-plasticity dilemma. In specific, these methods undergo a catastrophic forgetting of prior knowledge when a new view is attained. Such a catastrophic forgetting problem (CFP) would cause the consistent and complementary information hard to get and affect the clustering performance. To tackle this, we propose a novel method termed Contrastive Continual Multi-view Clustering with Filtered Structural Fusion (CCMVC-FSF). Precisely, considering that data correlations play a vital role in clustering and prior knowledge ought to guide the clustering process of a new view, we develop a data buffer with fixed size to store filtered structural information and utilize it to guide the generation of a robust partition matrix via contrastive learning. Furthermore, we theoretically connect CCMVC-FSF with semi-supervised learning and knowledge distillation. Extensive experiments exhibit the excellence of the proposed method.