 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Heuristic Vision Pre-Training with Self-Supervised and Supervised Multi-Task Learning
Oct 11, 2023
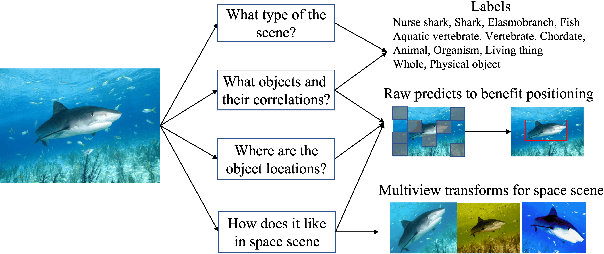
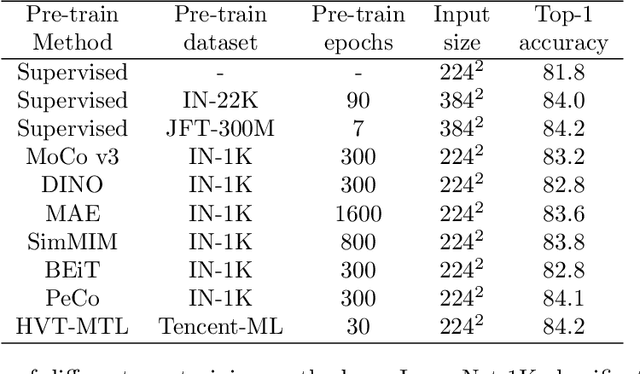
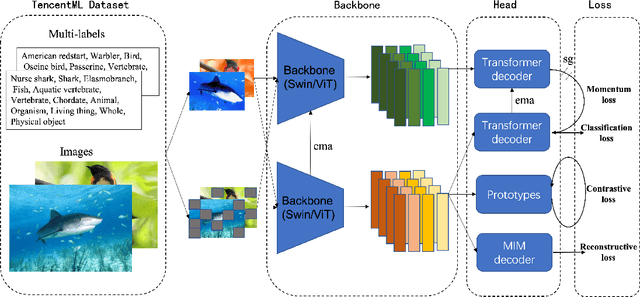
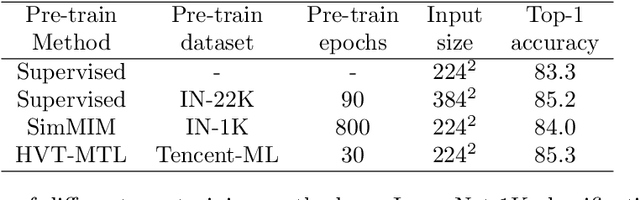
To mimic human vision with the way of recognizing the diverse and open world, foundation vision models are much critical. While recent techniques of self-supervised learning show the promising potentiality of this mission, we argue that signals from labelled data are also important for common-sense recognition, and properly chosen pre-text tasks can facilitate the efficiency of vision representation learning. To this end, we propose a novel pre-training framework by adopting both self-supervised and supervised visual pre-text tasks in a multi-task manner. Specifically, given an image, we take a heuristic way by considering its intrinsic style properties, inside objects with their locations and correlations, and how it looks like in 3D space for basic visual understanding. However, large-scale object bounding boxes and correlations are usually hard to achieve. Alternatively, we develop a hybrid method by leveraging both multi-label classification and self-supervised learning. On the one hand, under the multi-label supervision, the pre-trained model can explore the detailed information of an image, e.g., image types, objects, and part of semantic relations. On the other hand, self-supervised learning tasks, with respect to Masked Image Modeling (MIM) and contrastive learning, can help the model learn pixel details and patch correlations. Results show that our pre-trained models can deliver results on par with or better than state-of-the-art (SOTA) results on multiple visual tasks. For example, with a vanilla Swin-B backbone, we achieve 85.3\% top-1 accuracy on ImageNet-1K classification, 47.9 box AP on COCO object detection for Mask R-CNN, and 50.6 mIoU on ADE-20K semantic segmentation when using Upernet. The performance shows the ability of our vision foundation model to serve general purpose vision tasks.
Temporally Aligning Long Audio Interviews with Questions: A Case Study in Multimodal Data Integration
Oct 10, 2023
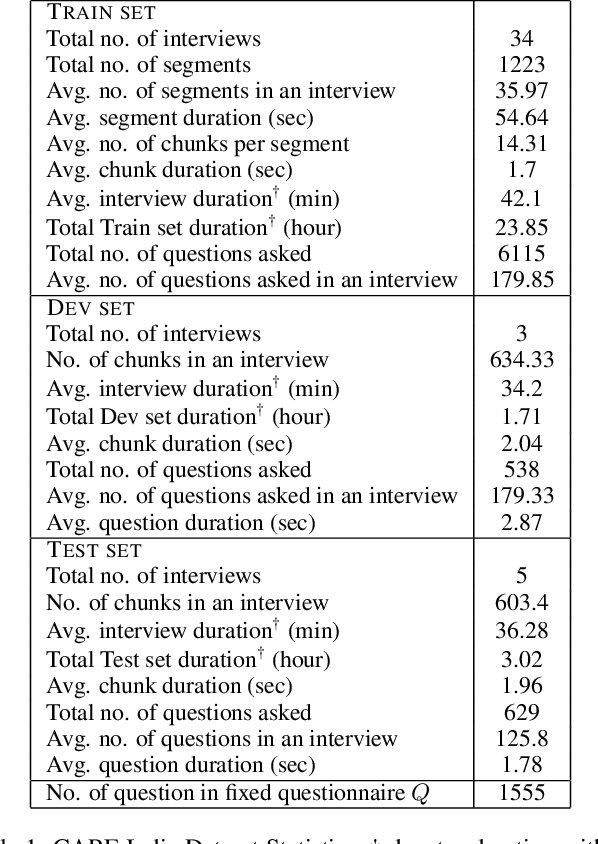
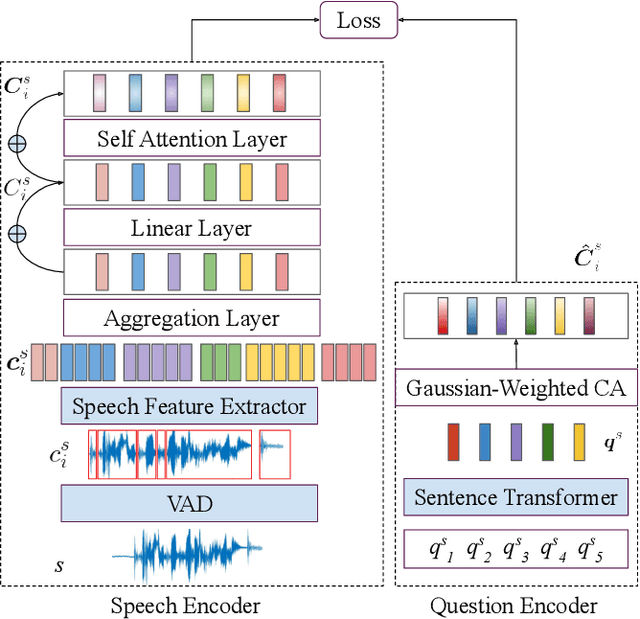
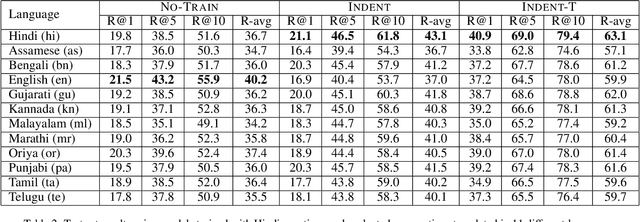
The problem of audio-to-text alignment has seen significant amount of research using complete supervision during training. However, this is typically not in the context of long audio recordings wherein the text being queried does not appear verbatim within the audio file. This work is a collaboration with a non-governmental organization called CARE India that collects long audio health surveys from young mothers residing in rural parts of Bihar, India. Given a question drawn from a questionnaire that is used to guide these surveys, we aim to locate where the question is asked within a long audio recording. This is of great value to African and Asian organizations that would otherwise have to painstakingly go through long and noisy audio recordings to locate questions (and answers) of interest. Our proposed framework, INDENT, uses a cross-attention-based model and prior information on the temporal ordering of sentences to learn speech embeddings that capture the semantics of the underlying spoken text. These learnt embeddings are used to retrieve the corresponding audio segment based on text queries at inference time. We empirically demonstrate the significant effectiveness (improvement in R-avg of about 3%) of our model over those obtained using text-based heuristics. We also show how noisy ASR, generated using state-of-the-art ASR models for Indian languages, yields better results when used in place of speech. INDENT, trained only on Hindi data is able to cater to all languages supported by the (semantically) shared text space. We illustrate this empirically on 11 Indic languages.
SC2GAN: Rethinking Entanglement by Self-correcting Correlated GAN Space
Oct 10, 2023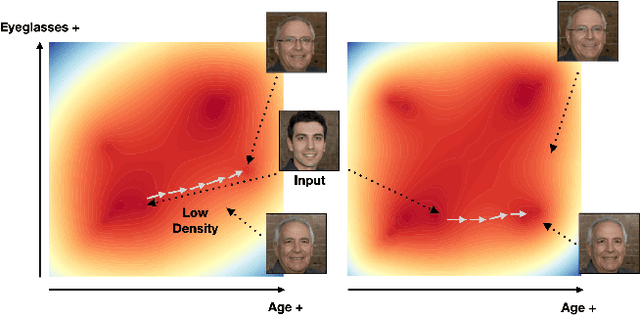

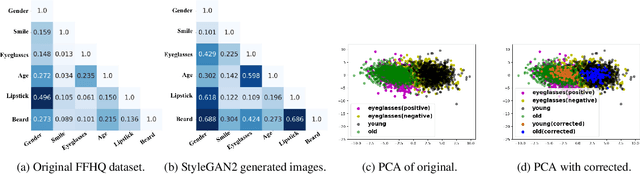

Generative Adversarial Networks (GANs) can synthesize realistic images, with the learned latent space shown to encode rich semantic information with various interpretable directions. However, due to the unstructured nature of the learned latent space, it inherits the bias from the training data where specific groups of visual attributes that are not causally related tend to appear together, a phenomenon also known as spurious correlations, e.g., age and eyeglasses or women and lipsticks. Consequently, the learned distribution often lacks the proper modelling of the missing examples. The interpolation following editing directions for one attribute could result in entangled changes with other attributes. To address this problem, previous works typically adjust the learned directions to minimize the changes in other attributes, yet they still fail on strongly correlated features. In this work, we study the entanglement issue in both the training data and the learned latent space for the StyleGAN2-FFHQ model. We propose a novel framework SC$^2$GAN that achieves disentanglement by re-projecting low-density latent code samples in the original latent space and correcting the editing directions based on both the high-density and low-density regions. By leveraging the original meaningful directions and semantic region-specific layers, our framework interpolates the original latent codes to generate images with attribute combination that appears infrequently, then inverts these samples back to the original latent space. We apply our framework to pre-existing methods that learn meaningful latent directions and showcase its strong capability to disentangle the attributes with small amounts of low-density region samples added.
EmoTwiCS: A Corpus for Modelling Emotion Trajectories in Dutch Customer Service Dialogues on Twitter
Oct 10, 2023Due to the rise of user-generated content, social media is increasingly adopted as a channel to deliver customer service. Given the public character of these online platforms, the automatic detection of emotions forms an important application in monitoring customer satisfaction and preventing negative word-of-mouth. This paper introduces EmoTwiCS, a corpus of 9,489 Dutch customer service dialogues on Twitter that are annotated for emotion trajectories. In our business-oriented corpus, we view emotions as dynamic attributes of the customer that can change at each utterance of the conversation. The term `emotion trajectory' refers therefore not only to the fine-grained emotions experienced by customers (annotated with 28 labels and valence-arousal-dominance scores), but also to the event happening prior to the conversation and the responses made by the human operator (both annotated with 8 categories). Inter-annotator agreement (IAA) scores on the resulting dataset are substantial and comparable with related research, underscoring its high quality. Given the interplay between the different layers of annotated information, we perform several in-depth analyses to investigate (i) static emotions in isolated tweets, (ii) dynamic emotions and their shifts in trajectory, and (iii) the role of causes and response strategies in emotion trajectories. We conclude by listing the advantages and limitations of our dataset, after which we give some suggestions on the different types of predictive modelling tasks and open research questions to which EmoTwiCS can be applied. The dataset is available upon request and will be made publicly available upon acceptance of the paper.
Automated clinical coding using off-the-shelf large language models
Oct 10, 2023The task of assigning diagnostic ICD codes to patient hospital admissions is typically performed by expert human coders. Efforts towards automated ICD coding are dominated by supervised deep learning models. However, difficulties in learning to predict the large number of rare codes remain a barrier to adoption in clinical practice. In this work, we leverage off-the-shelf pre-trained generative large language models (LLMs) to develop a practical solution that is suitable for zero-shot and few-shot code assignment. Unsupervised pre-training alone does not guarantee precise knowledge of the ICD ontology and specialist clinical coding task, therefore we frame the task as information extraction, providing a description of each coded concept and asking the model to retrieve related mentions. For efficiency, rather than iterating over all codes, we leverage the hierarchical nature of the ICD ontology to sparsely search for relevant codes. Then, in a second stage, which we term 'meta-refinement', we utilise GPT-4 to select a subset of the relevant labels as predictions. We validate our method using Llama-2, GPT-3.5 and GPT-4 on the CodiEsp dataset of ICD-coded clinical case documents. Our tree-search method achieves state-of-the-art performance on rarer classes, achieving the best macro-F1 of 0.225, whilst achieving slightly lower micro-F1 of 0.157, compared to 0.216 and 0.219 respectively from PLM-ICD. To the best of our knowledge, this is the first method for automated ICD coding requiring no task-specific learning.
Information-theoretic Analysis of Test Data Sensitivity in Uncertainty
Jul 23, 2023Bayesian inference is often utilized for uncertainty quantification tasks. A recent analysis by Xu and Raginsky 2022 rigorously decomposed the predictive uncertainty in Bayesian inference into two uncertainties, called aleatoric and epistemic uncertainties, which represent the inherent randomness in the data-generating process and the variability due to insufficient data, respectively. They analyzed those uncertainties in an information-theoretic way, assuming that the model is well-specified and treating the model's parameters as latent variables. However, the existing information-theoretic analysis of uncertainty cannot explain the widely believed property of uncertainty, known as the sensitivity between the test and training data. It implies that when test data are similar to training data in some sense, the epistemic uncertainty should become small. In this work, we study such uncertainty sensitivity using our novel decomposition method for the predictive uncertainty. Our analysis successfully defines such sensitivity using information-theoretic quantities. Furthermore, we extend the existing analysis of Bayesian meta-learning and show the novel sensitivities among tasks for the first time.
Attention Sorting Combats Recency Bias In Long Context Language Models
Sep 28, 2023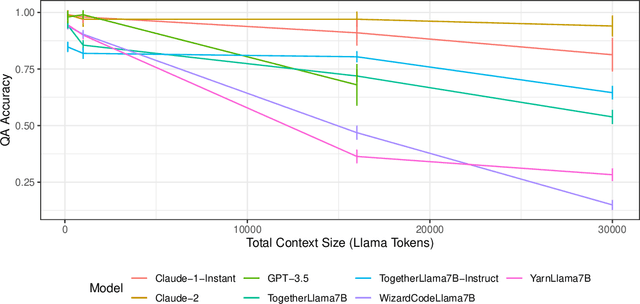
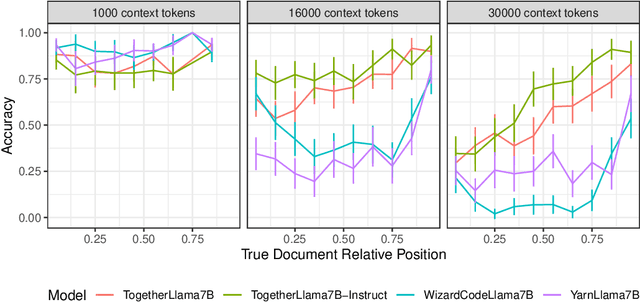
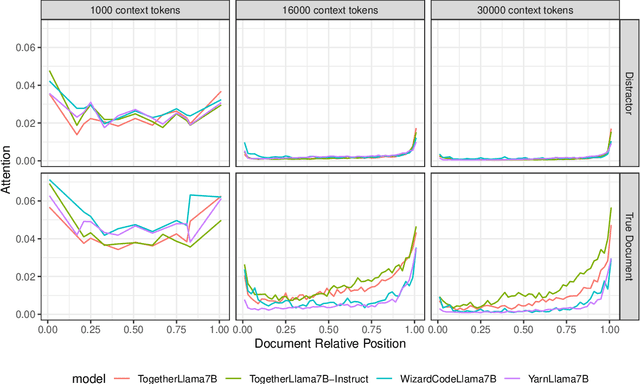
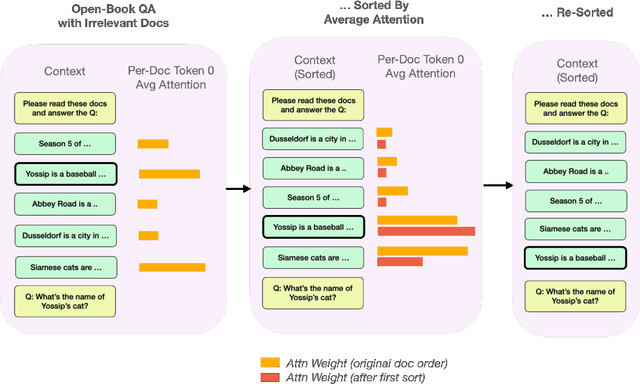
Current language models often fail to incorporate long contexts efficiently during generation. We show that a major contributor to this issue are attention priors that are likely learned during pre-training: relevant information located earlier in context is attended to less on average. Yet even when models fail to use the information from a relevant document in their response, they still pay preferential attention to that document compared to an irrelevant document at the same position. We leverage this fact to introduce ``attention sorting'': perform one step of decoding, sort documents by the attention they receive (highest attention going last), repeat the process, generate the answer with the newly sorted context. We find that attention sorting improves performance of long context models. Our findings highlight some challenges in using off-the-shelf language models for retrieval augmented generation.
Cross-Modal Translation and Alignment for Survival Analysis
Sep 22, 2023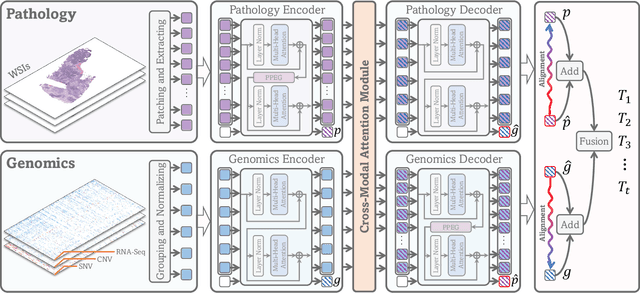
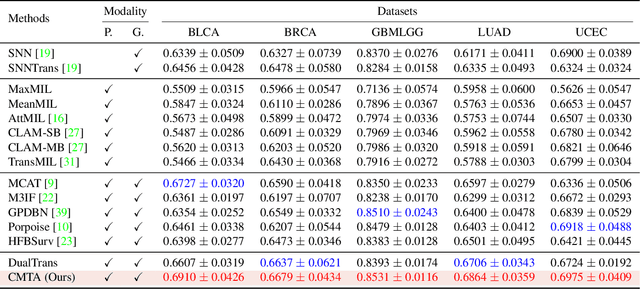
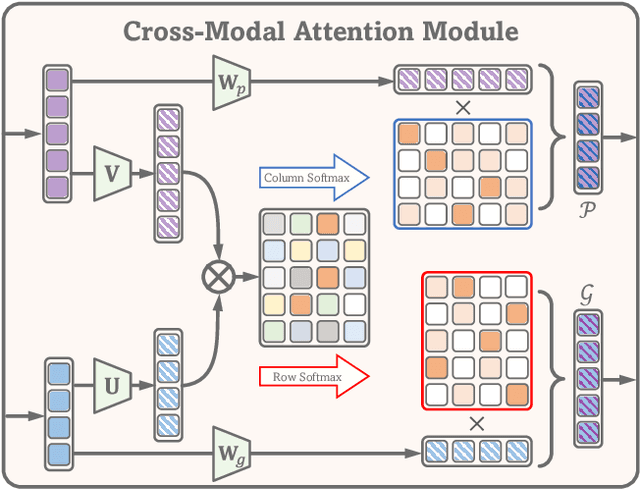
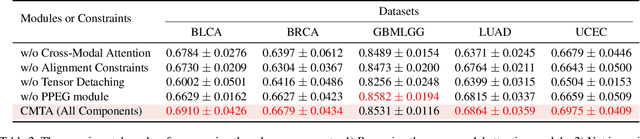
With the rapid advances in high-throughput sequencing technologies, the focus of survival analysis has shifted from examining clinical indicators to incorporating genomic profiles with pathological images. However, existing methods either directly adopt a straightforward fusion of pathological features and genomic profiles for survival prediction, or take genomic profiles as guidance to integrate the features of pathological images. The former would overlook intrinsic cross-modal correlations. The latter would discard pathological information irrelevant to gene expression. To address these issues, we present a Cross-Modal Translation and Alignment (CMTA) framework to explore the intrinsic cross-modal correlations and transfer potential complementary information. Specifically, we construct two parallel encoder-decoder structures for multi-modal data to integrate intra-modal information and generate cross-modal representation. Taking the generated cross-modal representation to enhance and recalibrate intra-modal representation can significantly improve its discrimination for comprehensive survival analysis. To explore the intrinsic crossmodal correlations, we further design a cross-modal attention module as the information bridge between different modalities to perform cross-modal interactions and transfer complementary information. Our extensive experiments on five public TCGA datasets demonstrate that our proposed framework outperforms the state-of-the-art methods.
Comprehensive Review on Semantic Information Retrieval and Ontology Engineering
Jul 25, 2023Situation awareness is a crucial cognitive skill that enables individuals to perceive, comprehend, and project the current state of their environment accurately. It involves being conscious of relevant information, understanding its meaning, and using that understanding to make well-informed decisions. Awareness systems often need to integrate new knowledge and adapt to changing environments. Ontology reasoning facilitates knowledge integration and evolution, allowing for seamless updates and expansions of the ontology. With the consideration of above, we are providing a quick review on semantic information retrieval and ontology engineering to understand the emerging challenges and future research. In the review we have found that the ontology reasoning addresses the limitations of traditional systems by providing a formal, flexible, and scalable framework for knowledge representation, reasoning, and inference.
Transferring speech-generic and depression-specific knowledge for Alzheimer's disease detection
Oct 06, 2023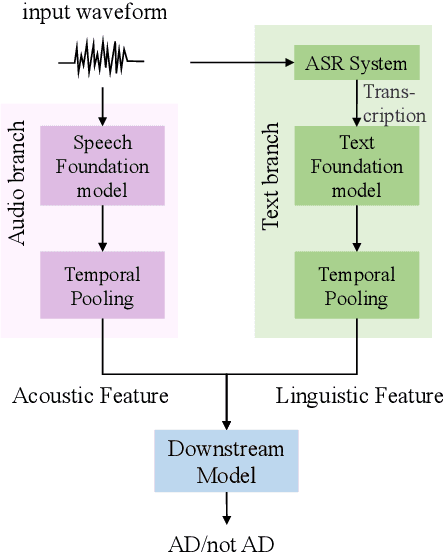
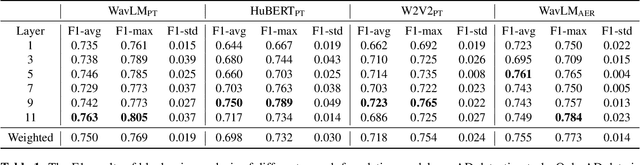
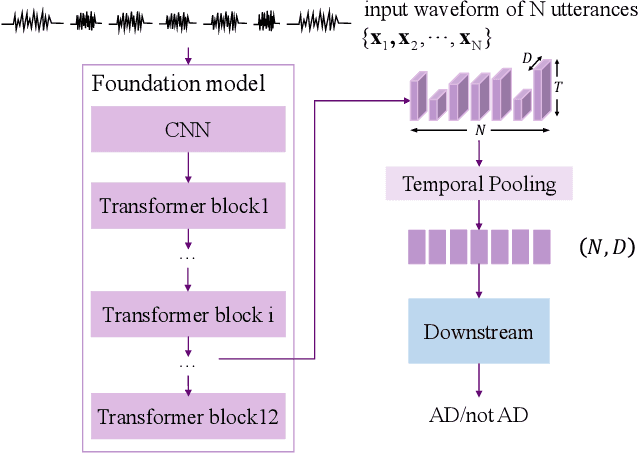
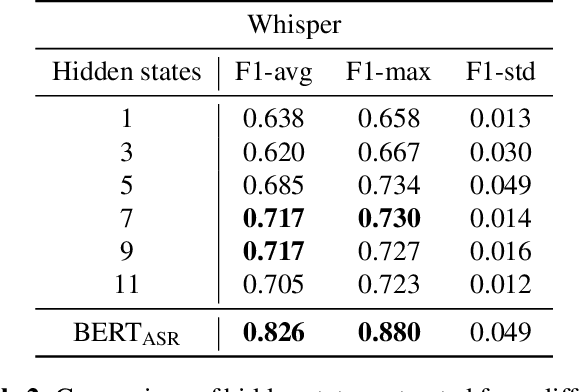
The detection of Alzheimer's disease (AD) from spontaneous speech has attracted increasing attention while the sparsity of training data remains an important issue. This paper handles the issue by knowledge transfer, specifically from both speech-generic and depression-specific knowledge. The paper first studies sequential knowledge transfer from generic foundation models pretrained on large amounts of speech and text data. A block-wise analysis is performed for AD diagnosis based on the representations extracted from different intermediate blocks of different foundation models. Apart from the knowledge from speech-generic representations, this paper also proposes to simultaneously transfer the knowledge from a speech depression detection task based on the high comorbidity rates of depression and AD. A parallel knowledge transfer framework is studied that jointly learns the information shared between these two tasks. Experimental results show that the proposed method improves AD and depression detection, and produces a state-of-the-art F1 score of 0.928 for AD diagnosis on the commonly used ADReSSo dataset.