 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hypercomplex Multimodal Emotion Recognition from EEG and Peripheral Physiological Signals
Oct 11, 2023
Multimodal emotion recognition from physiological signals is receiving an increasing amount of attention due to the impossibility to control them at will unlike behavioral reactions, thus providing more reliable information. Existing deep learning-based methods still rely on extracted handcrafted features, not taking full advantage of the learning ability of neural networks, and often adopt a single-modality approach, while human emotions are inherently expressed in a multimodal way. In this paper, we propose a hypercomplex multimodal network equipped with a novel fusion module comprising parameterized hypercomplex multiplications. Indeed, by operating in a hypercomplex domain the operations follow algebraic rules which allow to model latent relations among learned feature dimensions for a more effective fusion step. We perform classification of valence and arousal from electroencephalogram (EEG) and peripheral physiological signals, employing the publicly available database MAHNOB-HCI surpassing a multimodal state-of-the-art network. The code of our work is freely available at https://github.com/ispamm/MHyEEG.
Adaptive Visual Scene Understanding: Incremental Scene Graph Generation
Oct 11, 2023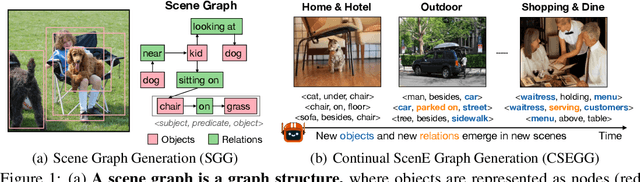
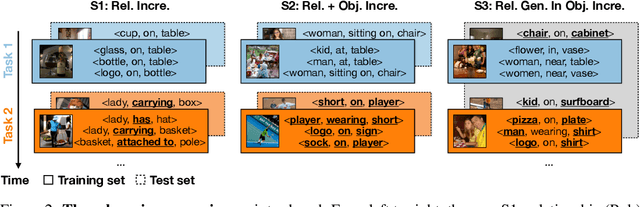
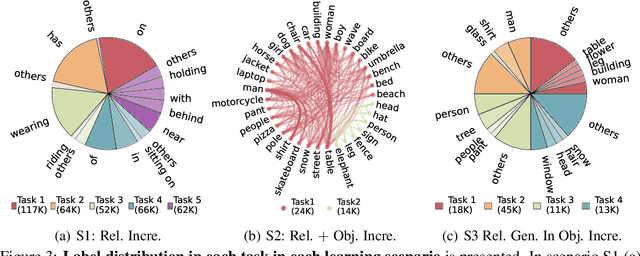
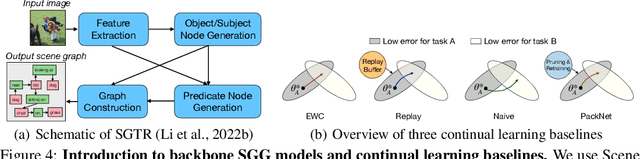
Scene graph generation (SGG) involves analyzing images to extract meaningful information about objects and their relationships. Given the dynamic nature of the visual world, it becomes crucial for AI systems to detect new objects and establish their new relationships with existing objects. To address the lack of continual learning methodologies in SGG, we introduce the comprehensive Continual ScenE Graph Generation (CSEGG) dataset along with 3 learning scenarios and 8 evaluation metrics. Our research investigates the continual learning performances of existing SGG methods on the retention of previous object entities and relationships as they learn new ones. Moreover, we also explore how continual object detection enhances generalization in classifying known relationships on unknown objects. We conduct extensive experiments benchmarking and analyzing the classical two-stage SGG methods and the most recent transformer-based SGG methods in continual learning settings, and gain valuable insights into the CSEGG problem. We invite the research community to explore this emerging field of study.
Formalizing Natural Language Intent into Program Specifications via Large Language Models
Oct 03, 2023
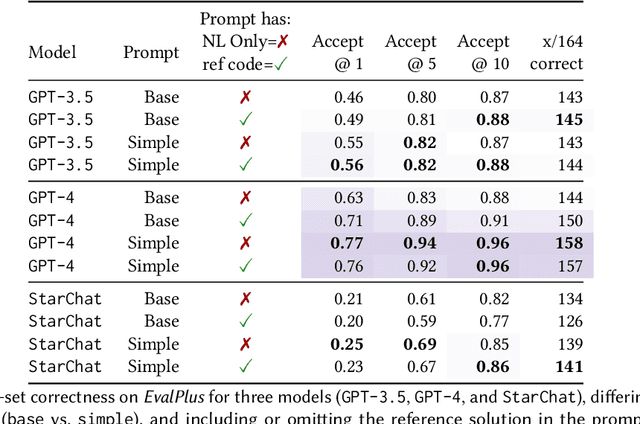
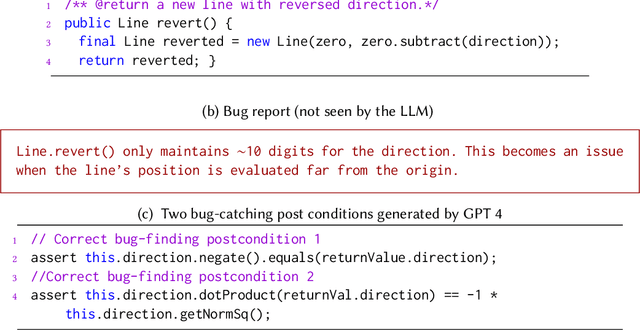
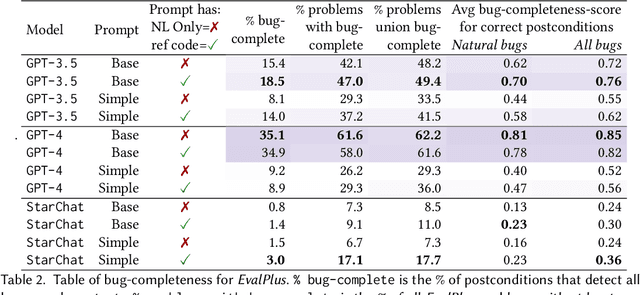
Informal natural language that describes code functionality, such as code comments or function documentation, may contain substantial information about a programs intent. However, there is typically no guarantee that a programs implementation and natural language documentation are aligned. In the case of a conflict, leveraging information in code-adjacent natural language has the potential to enhance fault localization, debugging, and code trustworthiness. In practice, however, this information is often underutilized due to the inherent ambiguity of natural language which makes natural language intent challenging to check programmatically. The "emergent abilities" of Large Language Models (LLMs) have the potential to facilitate the translation of natural language intent to programmatically checkable assertions. However, it is unclear if LLMs can correctly translate informal natural language specifications into formal specifications that match programmer intent. Additionally, it is unclear if such translation could be useful in practice. In this paper, we describe LLM4nl2post, the problem leveraging LLMs for transforming informal natural language to formal method postconditions, expressed as program assertions. We introduce and validate metrics to measure and compare different LLM4nl2post approaches, using the correctness and discriminative power of generated postconditions. We then perform qualitative and quantitative methods to assess the quality of LLM4nl2post postconditions, finding that they are generally correct and able to discriminate incorrect code. Finally, we find that LLM4nl2post via LLMs has the potential to be helpful in practice; specifications generated from natural language were able to catch 70 real-world historical bugs from Defects4J.
Multi-Static ISAC in Cell-Free Massive MIMO: Precoder Design and Privacy Assessment
Oct 03, 2023A multi-static sensing-centric integrated sensing and communication (ISAC) network can take advantage of the cell-free massive multiple-input multiple-output infrastructure to achieve remarkable diversity gains and reduced power consumption. While the conciliation of sensing and communication requirements is still a challenge, the privacy of the sensing information is a growing concern that should be seriously taken on the design of these systems to prevent other attacks. This paper tackles this issue by assessing the probability of an internal adversary to infer the target location information from the received signal by considering the design of transmit precoders that jointly optimizes the sensing and communication requirements in a multi-static-based cell-free ISAC network. Our results show that the multi-static setting facilitates a more precise estimation of the location of the target than the mono-static implementation.
LLaMA Rider: Spurring Large Language Models to Explore the Open World
Oct 13, 2023Recently, various studies have leveraged Large Language Models (LLMs) to help decision-making and planning in environments, and try to align the LLMs' knowledge with the world conditions. Nonetheless, the capacity of LLMs to continuously acquire environmental knowledge and adapt in an open world remains uncertain. In this paper, we propose an approach to spur LLMs to explore the open world, gather experiences, and learn to improve their task-solving capabilities. In this approach, a multi-round feedback-revision mechanism is utilized to encourage LLMs to actively select appropriate revision actions guided by feedback information from the environment. This facilitates exploration and enhances the model's performance. Besides, we integrate sub-task relabeling to assist LLMs in maintaining consistency in sub-task planning and help the model learn the combinatorial nature between tasks, enabling it to complete a wider range of tasks through training based on the acquired exploration experiences. By evaluation in Minecraft, an open-ended sandbox world, we demonstrate that our approach LLaMA-Rider enhances the efficiency of the LLM in exploring the environment, and effectively improves the LLM's ability to accomplish more tasks through fine-tuning with merely 1.3k instances of collected data, showing minimal training costs compared to the baseline using reinforcement learning.
The Consensus Game: Language Model Generation via Equilibrium Search
Oct 13, 2023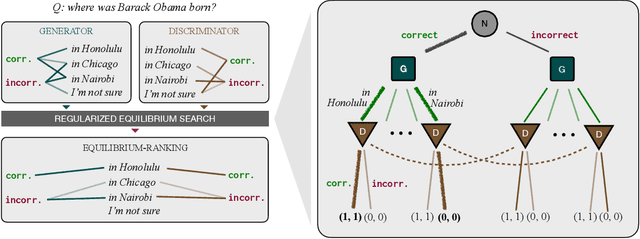
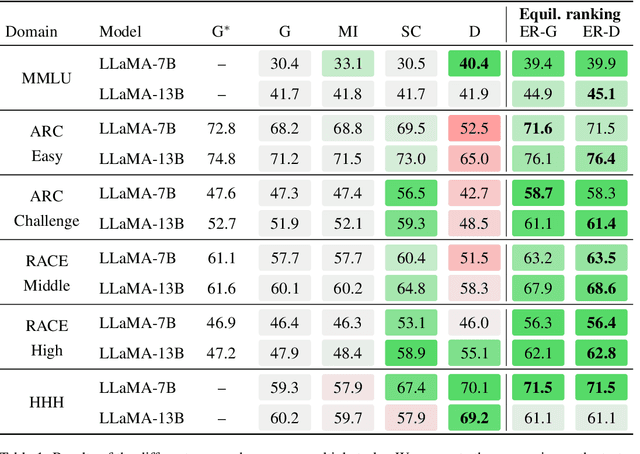
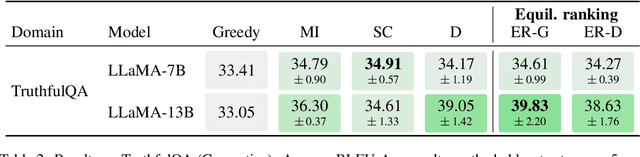
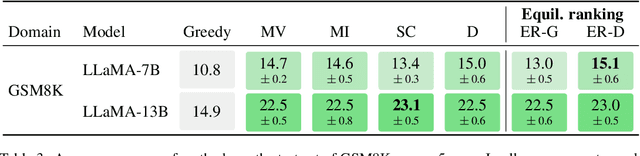
When applied to question answering and other text generation tasks, language models (LMs) may be queried generatively (by sampling answers from their output distribution) or discriminatively (by using them to score or rank a set of candidate outputs). These procedures sometimes yield very different predictions. How do we reconcile mutually incompatible scoring procedures to obtain coherent LM predictions? We introduce a new, a training-free, game-theoretic procedure for language model decoding. Our approach casts language model decoding as a regularized imperfect-information sequential signaling game - which we term the CONSENSUS GAME - in which a GENERATOR seeks to communicate an abstract correctness parameter using natural language sentences to a DISCRIMINATOR. We develop computational procedures for finding approximate equilibria of this game, resulting in a decoding algorithm we call EQUILIBRIUM-RANKING. Applied to a large number of tasks (including reading comprehension, commonsense reasoning, mathematical problem-solving, and dialog), EQUILIBRIUM-RANKING consistently, and sometimes substantially, improves performance over existing LM decoding procedures - on multiple benchmarks, we observe that applying EQUILIBRIUM-RANKING to LLaMA-7B outperforms the much larger LLaMA-65B and PaLM-540B models. These results highlight the promise of game-theoretic tools for addressing fundamental challenges of truthfulness and consistency in LMs.
Understanding and Modeling the Effects of Task and Context on Drivers' Gaze Allocation
Oct 13, 2023
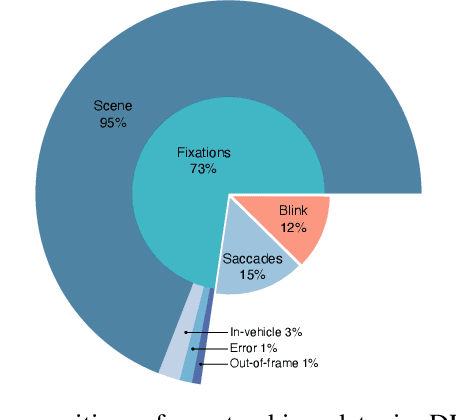

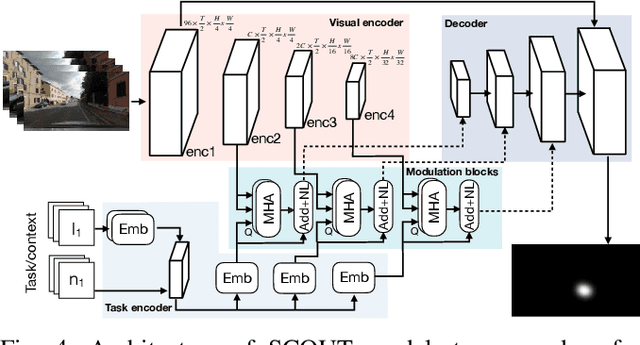
Understanding what drivers look at is important for many applications, including driver training, monitoring, and assistance, as well as self-driving. Traditionally, factors affecting human visual attention have been divided into bottom-up (involuntary attraction to salient regions) and top-down (task- and context-driven). Although both play a role in drivers' gaze allocation, most of the existing modeling approaches apply techniques developed for bottom-up saliency and do not consider task and context influences explicitly. Likewise, common driving attention benchmarks lack relevant task and context annotations. Therefore, to enable analysis and modeling of these factors for drivers' gaze prediction, we propose the following: 1) address some shortcomings of the popular DR(eye)VE dataset and extend it with per-frame annotations for driving task and context; 2) benchmark a number of baseline and SOTA models for saliency and driver gaze prediction and analyze them w.r.t. the new annotations; and finally, 3) a novel model that modulates drivers' gaze prediction with explicit action and context information, and as a result significantly improves SOTA performance on DR(eye)VE overall (by 24\% KLD and 89\% NSS) and on a subset of action and safety-critical intersection scenarios (by 10--30\% KLD). Extended annotations, code for model and evaluation will be made publicly available.
Tikuna: An Ethereum Blockchain Network Security Monitoring System
Oct 13, 2023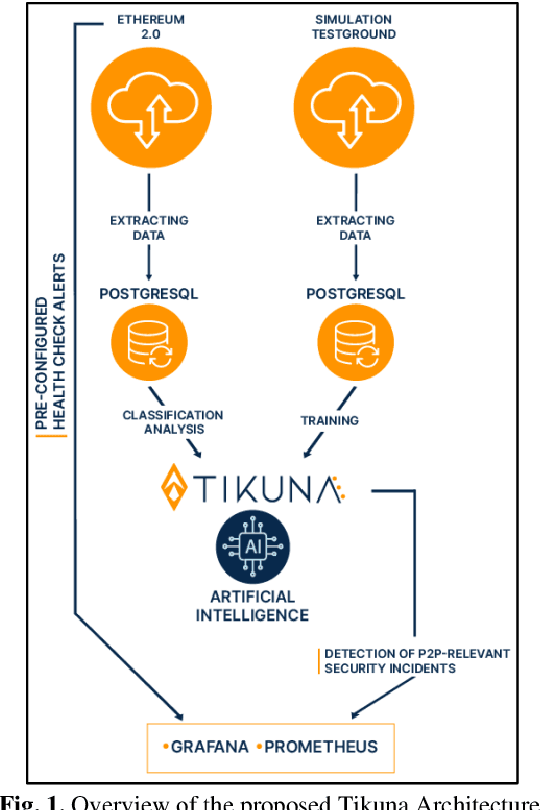
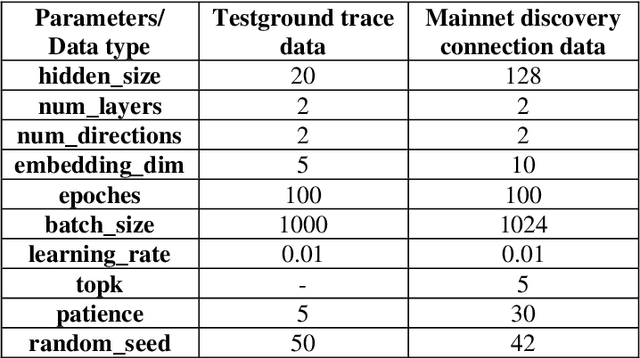
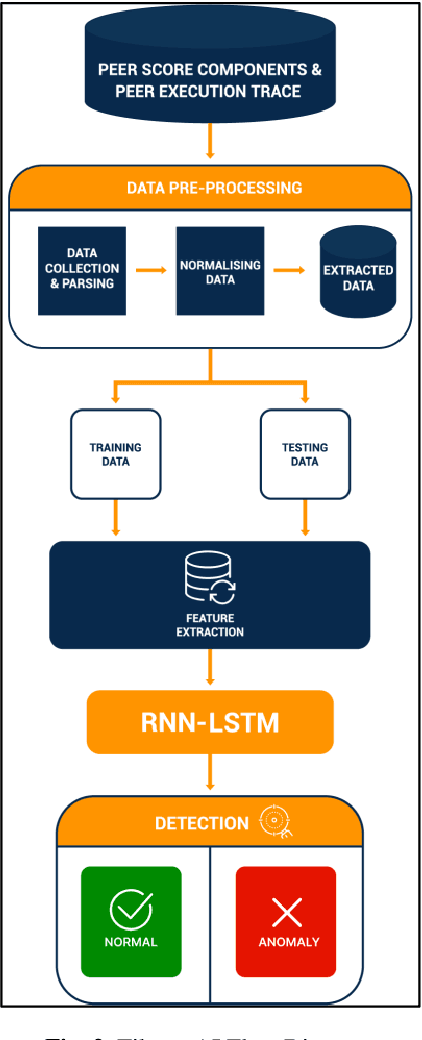
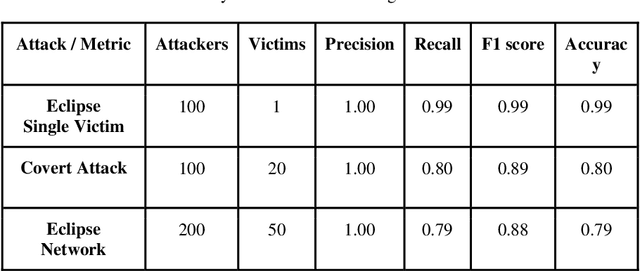
Blockchain security is becoming increasingly relevant in today's cyberspace as it extends its influence in many industries. This paper focuses on protecting the lowest level layer in the blockchain, particularly the P2P network that allows the nodes to communicate and share information. The P2P network layer may be vulnerable to several families of attacks, such as Distributed Denial of Service (DDoS), eclipse attacks, or Sybil attacks. This layer is prone to threats inherited from traditional P2P networks, and it must be analyzed and understood by collecting data and extracting insights from the network behavior to reduce those risks. We introduce Tikuna, an open-source tool for monitoring and detecting potential attacks on the Ethereum blockchain P2P network, at an early stage. Tikuna employs an unsupervised Long Short-Term Memory (LSTM) method based on Recurrent Neural Network (RNN) to detect attacks and alert users. Empirical results indicate that the proposed approach significantly improves detection performance, with the ability to detect and classify attacks, including eclipse attacks, Covert Flash attacks, and others that target the Ethereum blockchain P2P network layer, with high accuracy. Our research findings demonstrate that Tikuna is a valuable security tool for assisting operators to efficiently monitor and safeguard the status of Ethereum validators and the wider P2P network
Precedent-Enhanced Legal Judgment Prediction with LLM and Domain-Model Collaboration
Oct 13, 2023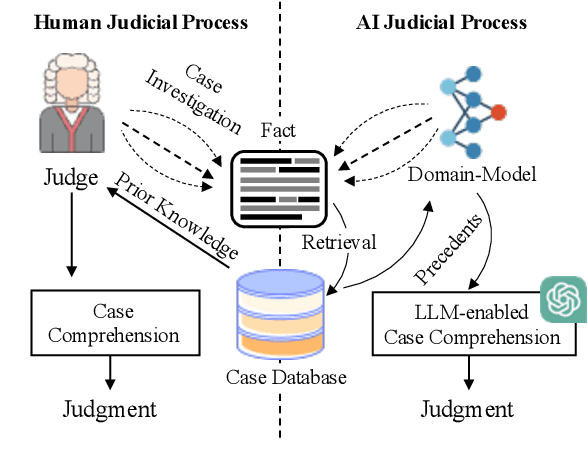
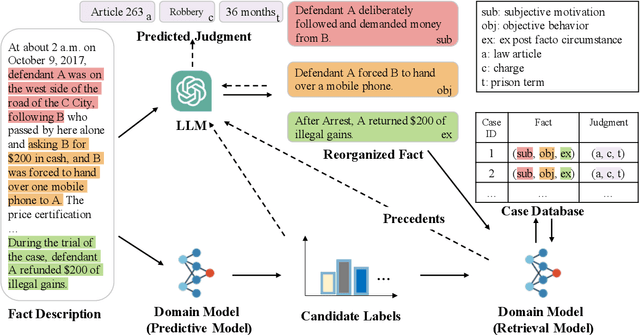
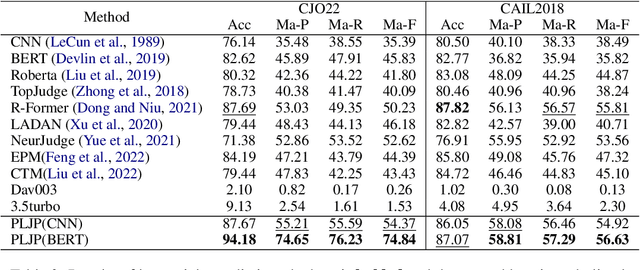
Legal Judgment Prediction (LJP) has become an increasingly crucial task in Legal AI, i.e., predicting the judgment of the case in terms of case fact description. Precedents are the previous legal cases with similar facts, which are the basis for the judgment of the subsequent case in national legal systems. Thus, it is worthwhile to explore the utilization of precedents in the LJP. Recent advances in deep learning have enabled a variety of techniques to be used to solve the LJP task. These can be broken down into two categories: large language models (LLMs) and domain-specific models. LLMs are capable of interpreting and generating complex natural language, while domain models are efficient in learning task-specific information. In this paper, we propose the precedent-enhanced LJP framework (PLJP), a system that leverages the strength of both LLM and domain models in the context of precedents. Specifically, the domain models are designed to provide candidate labels and find the proper precedents efficiently, and the large models will make the final prediction with an in-context precedents comprehension. Experiments on the real-world dataset demonstrate the effectiveness of our PLJP. Moreover, our work shows a promising direction for LLM and domain-model collaboration that can be generalized to other vertical domains.
Integrating Symbolic Reasoning into Neural Generative Models for Design Generation
Oct 13, 2023Design generation requires tight integration of neural and symbolic reasoning, as good design must meet explicit user needs and honor implicit rules for aesthetics, utility, and convenience. Current automated design tools driven by neural networks produce appealing designs, but cannot satisfy user specifications and utility requirements. Symbolic reasoning tools, such as constraint programming, cannot perceive low-level visual information in images or capture subtle aspects such as aesthetics. We introduce the Spatial Reasoning Integrated Generator (SPRING) for design generation. SPRING embeds a neural and symbolic integrated spatial reasoning module inside the deep generative network. The spatial reasoning module decides the locations of objects to be generated in the form of bounding boxes, which are predicted by a recurrent neural network and filtered by symbolic constraint satisfaction. Embedding symbolic reasoning into neural generation guarantees that the output of SPRING satisfies user requirements. Furthermore, SPRING offers interpretability, allowing users to visualize and diagnose the generation process through the bounding boxes. SPRING is also adept at managing novel user specifications not encountered during its training, thanks to its proficiency in zero-shot constraint transfer. Quantitative evaluations and a human study reveal that SPRING outperforms baseline generative models, excelling in delivering high design quality and better meeting user specifications.