 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
RA-DIT: Retrieval-Augmented Dual Instruction Tuning
Oct 08, 2023

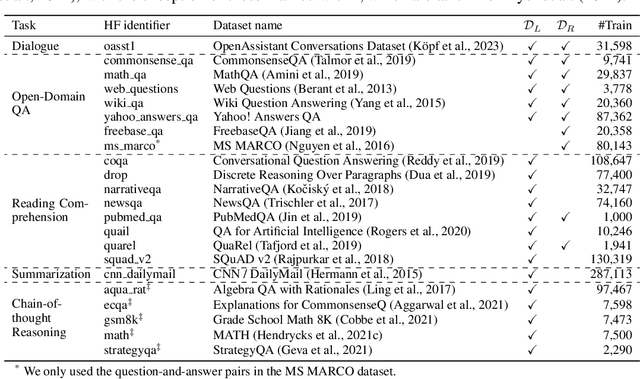
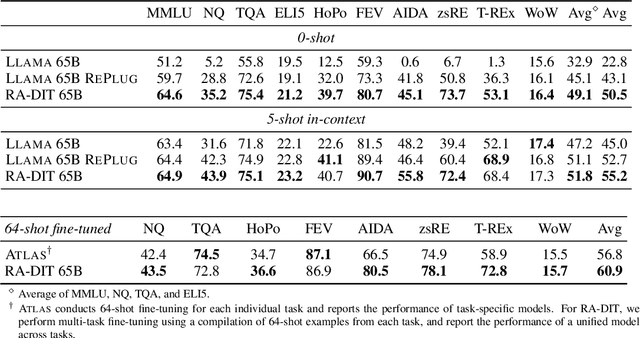
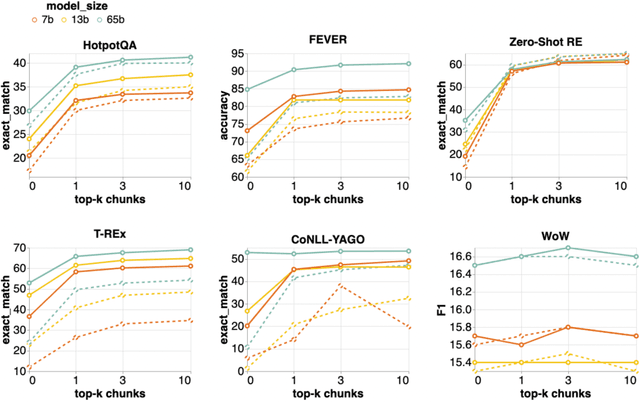
Retrieval-augmented language models (RALMs) improve performance by accessing long-tail and up-to-date knowledge from external data stores, but are challenging to build. Existing approaches require either expensive retrieval-specific modifications to LM pre-training or use post-hoc integration of the data store that leads to suboptimal performance. We introduce Retrieval-Augmented Dual Instruction Tuning (RA-DIT), a lightweight fine-tuning methodology that provides a third option by retrofitting any LLM with retrieval capabilities. Our approach operates in two distinct fine-tuning steps: (1) one updates a pre-trained LM to better use retrieved information, while (2) the other updates the retriever to return more relevant results, as preferred by the LM. By fine-tuning over tasks that require both knowledge utilization and contextual awareness, we demonstrate that each stage yields significant performance improvements, and using both leads to additional gains. Our best model, RA-DIT 65B, achieves state-of-the-art performance across a range of knowledge-intensive zero- and few-shot learning benchmarks, significantly outperforming existing in-context RALM approaches by up to +8.9% in 0-shot setting and +1.4% in 5-shot setting on average.
DualVC 2: Dynamic Masked Convolution for Unified Streaming and Non-Streaming Voice Conversion
Sep 27, 2023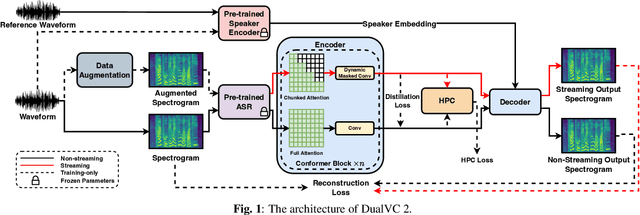
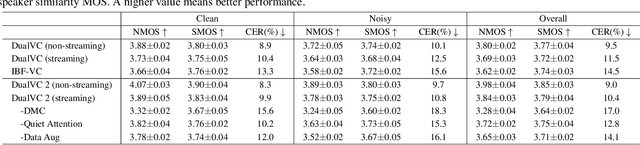
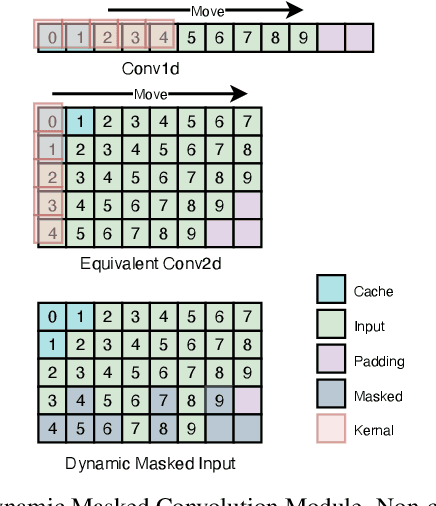
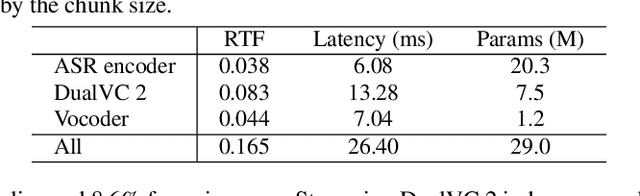
Voice conversion is becoming increasingly popular, and a growing number of application scenarios require models with streaming inference capabilities. The recently proposed DualVC attempts to achieve this objective through streaming model architecture design and intra-model knowledge distillation along with hybrid predictive coding to compensate for the lack of future information. However, DualVC encounters several problems that limit its performance. First, the autoregressive decoder has error accumulation in its nature and limits the inference speed as well. Second, the causal convolution enables streaming capability but cannot sufficiently use future information within chunks. Third, the model is unable to effectively address the noise in the unvoiced segments, lowering the sound quality. In this paper, we propose DualVC 2 to address these issues. Specifically, the model backbone is migrated to a Conformer-based architecture, empowering parallel inference. Causal convolution is replaced by non-causal convolution with dynamic chunk mask to make better use of within-chunk future information. Also, quiet attention is introduced to enhance the model's noise robustness. Experiments show that DualVC 2 outperforms DualVC and other baseline systems in both subjective and objective metrics, with only 186.4 ms latency. Our audio samples are made publicly available.
Enhancing End-to-End Conversational Speech Translation Through Target Language Context Utilization
Sep 27, 2023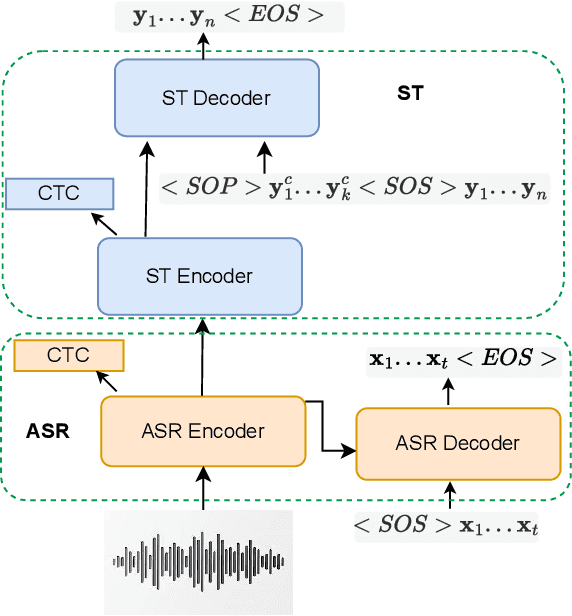
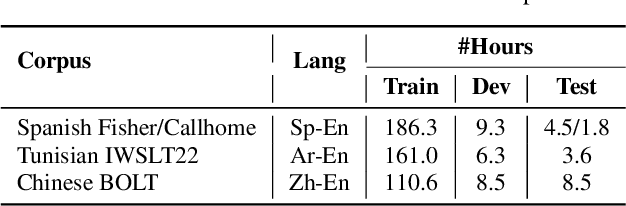
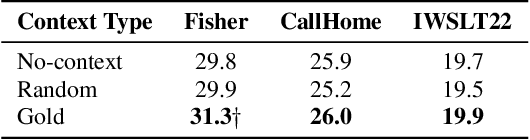
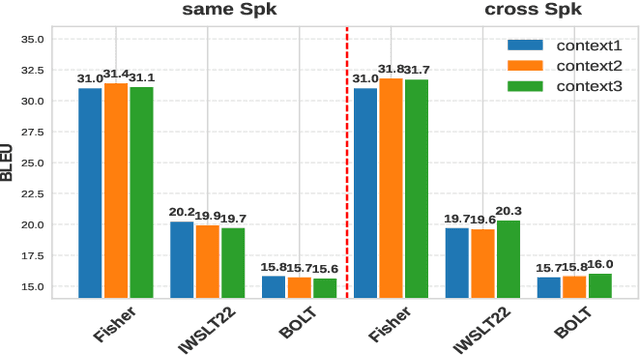
Incorporating longer context has been shown to benefit machine translation, but the inclusion of context in end-to-end speech translation (E2E-ST) remains under-studied. To bridge this gap, we introduce target language context in E2E-ST, enhancing coherence and overcoming memory constraints of extended audio segments. Additionally, we propose context dropout to ensure robustness to the absence of context, and further improve performance by adding speaker information. Our proposed contextual E2E-ST outperforms the isolated utterance-based E2E-ST approach. Lastly, we demonstrate that in conversational speech, contextual information primarily contributes to capturing context style, as well as resolving anaphora and named entities.
OrthoPlanes: A Novel Representation for Better 3D-Awareness of GANs
Sep 27, 2023We present a new method for generating realistic and view-consistent images with fine geometry from 2D image collections. Our method proposes a hybrid explicit-implicit representation called \textbf{OrthoPlanes}, which encodes fine-grained 3D information in feature maps that can be efficiently generated by modifying 2D StyleGANs. Compared to previous representations, our method has better scalability and expressiveness with clear and explicit information. As a result, our method can handle more challenging view-angles and synthesize articulated objects with high spatial degree of freedom. Experiments demonstrate that our method achieves state-of-the-art results on FFHQ and SHHQ datasets, both quantitatively and qualitatively. Project page: \url{https://orthoplanes.github.io/}.
Envisioning Narrative Intelligence: A Creative Visual Storytelling Anthology
Oct 06, 2023In this paper, we collect an anthology of 100 visual stories from authors who participated in our systematic creative process of improvised story-building based on image sequences. Following close reading and thematic analysis of our anthology, we present five themes that characterize the variations found in this creative visual storytelling process: (1) Narrating What is in Vision vs. Envisioning; (2) Dynamically Characterizing Entities/Objects; (3) Sensing Experiential Information About the Scenery; (4) Modulating the Mood; (5) Encoding Narrative Biases. In understanding the varied ways that people derive stories from images, we offer considerations for collecting story-driven training data to inform automatic story generation. In correspondence with each theme, we envision narrative intelligence criteria for computational visual storytelling as: creative, reliable, expressive, grounded, and responsible. From these criteria, we discuss how to foreground creative expression, account for biases, and operate in the bounds of visual storyworlds.
* 21 pages, 11 figures
DPGOMI: Differentially Private Data Publishing with Gaussian Optimized Model Inversion
Oct 06, 2023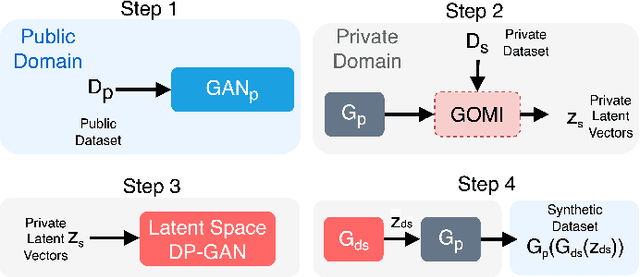

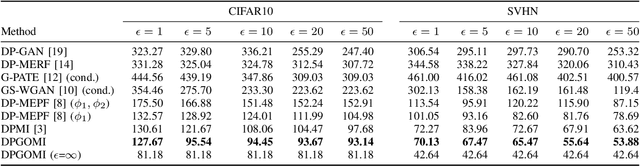
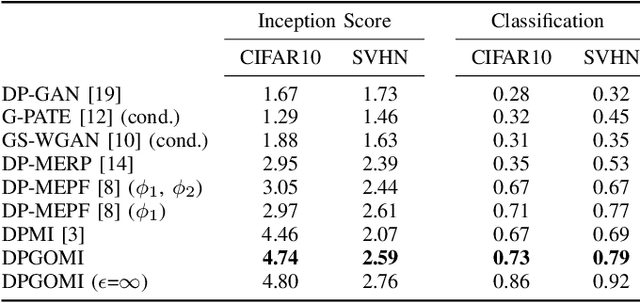
High-dimensional data are widely used in the era of deep learning with numerous applications. However, certain data which has sensitive information are not allowed to be shared without privacy protection. In this paper, we propose a novel differentially private data releasing method called Differentially Private Data Publishing with Gaussian Optimized Model Inversion (DPGOMI) to address this issue. Our approach involves mapping private data to the latent space using a public generator, followed by a lower-dimensional DP-GAN with better convergence properties. We evaluate the performance of DPGOMI on standard datasets CIFAR10 and SVHN. Our results show that DPGOMI outperforms the standard DP-GAN method in terms of Inception Score, Fr\'echet Inception Distance, and classification performance, while providing the same level of privacy. Our proposed approach offers a promising solution for protecting sensitive data in GAN training while maintaining high-quality results.
ODE-based Recurrent Model-free Reinforcement Learning for POMDPs
Sep 25, 2023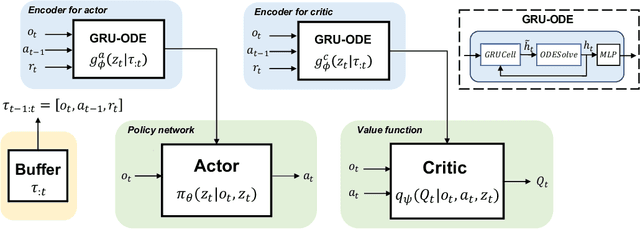
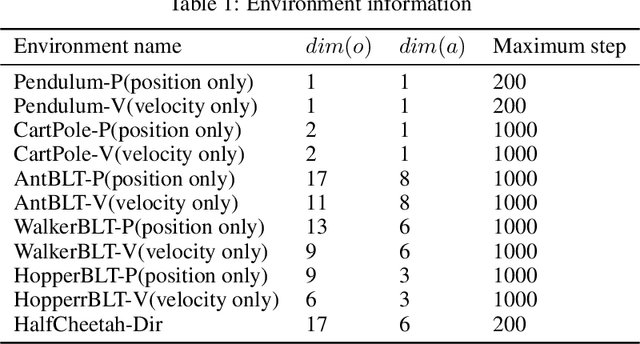
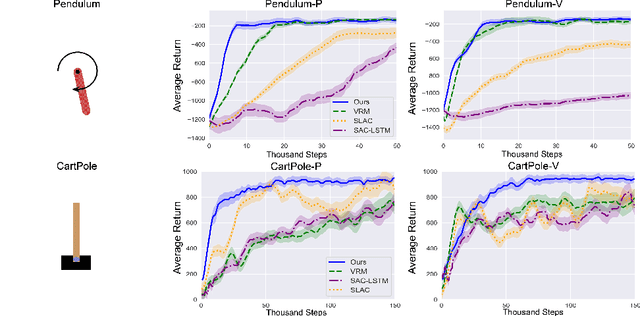
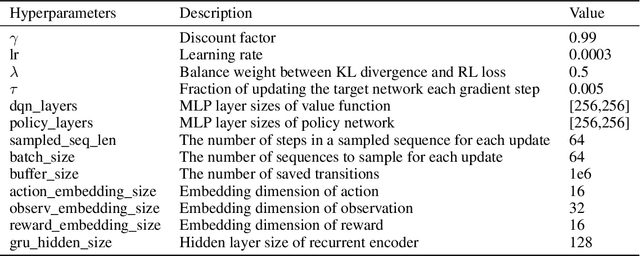
Neural ordinary differential equations (ODEs) are widely recognized as the standard for modeling physical mechanisms, which help to perform approximate inference in unknown physical or biological environments. In partially observable (PO) environments, how to infer unseen information from raw observations puzzled the agents. By using a recurrent policy with a compact context, context-based reinforcement learning provides a flexible way to extract unobservable information from historical transitions. To help the agent extract more dynamics-related information, we present a novel ODE-based recurrent model combines with model-free reinforcement learning (RL) framework to solve partially observable Markov decision processes (POMDPs). We experimentally demonstrate the efficacy of our methods across various PO continuous control and meta-RL tasks. Furthermore, our experiments illustrate that our method is robust against irregular observations, owing to the ability of ODEs to model irregularly-sampled time series.
Heuristic Vision Pre-Training with Self-Supervised and Supervised Multi-Task Learning
Oct 11, 2023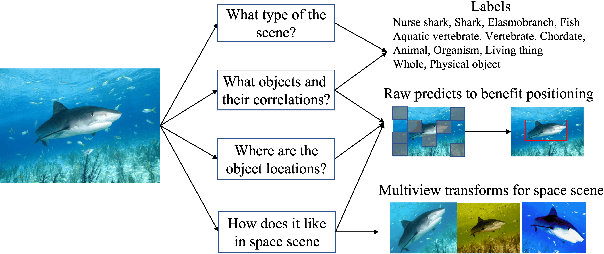
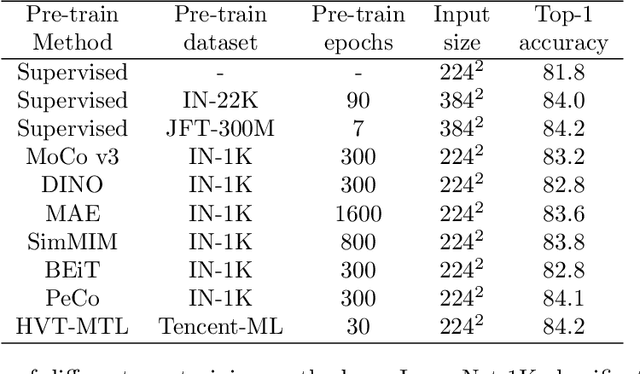
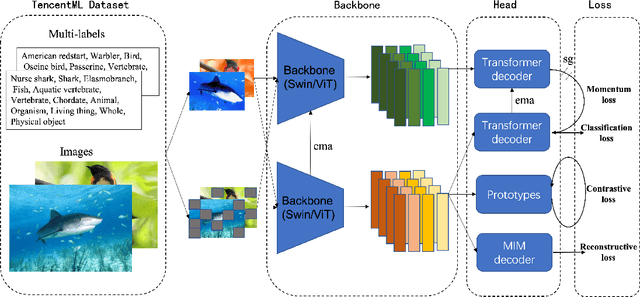
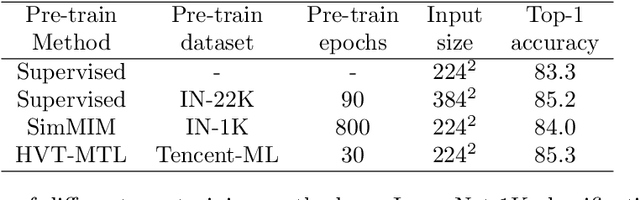
To mimic human vision with the way of recognizing the diverse and open world, foundation vision models are much critical. While recent techniques of self-supervised learning show the promising potentiality of this mission, we argue that signals from labelled data are also important for common-sense recognition, and properly chosen pre-text tasks can facilitate the efficiency of vision representation learning. To this end, we propose a novel pre-training framework by adopting both self-supervised and supervised visual pre-text tasks in a multi-task manner. Specifically, given an image, we take a heuristic way by considering its intrinsic style properties, inside objects with their locations and correlations, and how it looks like in 3D space for basic visual understanding. However, large-scale object bounding boxes and correlations are usually hard to achieve. Alternatively, we develop a hybrid method by leveraging both multi-label classification and self-supervised learning. On the one hand, under the multi-label supervision, the pre-trained model can explore the detailed information of an image, e.g., image types, objects, and part of semantic relations. On the other hand, self-supervised learning tasks, with respect to Masked Image Modeling (MIM) and contrastive learning, can help the model learn pixel details and patch correlations. Results show that our pre-trained models can deliver results on par with or better than state-of-the-art (SOTA) results on multiple visual tasks. For example, with a vanilla Swin-B backbone, we achieve 85.3\% top-1 accuracy on ImageNet-1K classification, 47.9 box AP on COCO object detection for Mask R-CNN, and 50.6 mIoU on ADE-20K semantic segmentation when using Upernet. The performance shows the ability of our vision foundation model to serve general purpose vision tasks.
ViCor: Bridging Visual Understanding and Commonsense Reasoning with Large Language Models
Oct 09, 2023In our work, we explore the synergistic capabilities of pre-trained vision-and-language models (VLMs) and large language models (LLMs) for visual commonsense reasoning (VCR). We categorize the problem of VCR into visual commonsense understanding (VCU) and visual commonsense inference (VCI). For VCU, which involves perceiving the literal visual content, pre-trained VLMs exhibit strong cross-dataset generalization. On the other hand, in VCI, where the goal is to infer conclusions beyond image content, VLMs face difficulties. We find that a baseline where VLMs provide perception results (image captions) to LLMs leads to improved performance on VCI. However, we identify a challenge with VLMs' passive perception, which often misses crucial context information, leading to incorrect or uncertain reasoning by LLMs. To mitigate this issue, we suggest a collaborative approach where LLMs, when uncertain about their reasoning, actively direct VLMs to concentrate on and gather relevant visual elements to support potential commonsense inferences. In our method, named ViCor, pre-trained LLMs serve as problem classifiers to analyze the problem category, VLM commanders to leverage VLMs differently based on the problem classification, and visual commonsense reasoners to answer the question. VLMs will perform visual recognition and understanding. We evaluate our framework on two VCR benchmark datasets and outperform all other methods that do not require in-domain supervised fine-tuning.
Asynchrony-Robust Collaborative Perception via Bird's Eye View Flow
Oct 09, 2023Collaborative perception can substantially boost each agent's perception ability by facilitating communication among multiple agents. However, temporal asynchrony among agents is inevitable in the real world due to communication delays, interruptions, and clock misalignments. This issue causes information mismatch during multi-agent fusion, seriously shaking the foundation of collaboration. To address this issue, we propose CoBEVFlow, an asynchrony-robust collaborative perception system based on bird's eye view (BEV) flow. The key intuition of CoBEVFlow is to compensate motions to align asynchronous collaboration messages sent by multiple agents. To model the motion in a scene, we propose BEV flow, which is a collection of the motion vector corresponding to each spatial location. Based on BEV flow, asynchronous perceptual features can be reassigned to appropriate positions, mitigating the impact of asynchrony. CoBEVFlow has two advantages: (i) CoBEVFlow can handle asynchronous collaboration messages sent at irregular, continuous time stamps without discretization; and (ii) with BEV flow, CoBEVFlow only transports the original perceptual features, instead of generating new perceptual features, avoiding additional noises. To validate CoBEVFlow's efficacy, we create IRregular V2V(IRV2V), the first synthetic collaborative perception dataset with various temporal asynchronies that simulate different real-world scenarios. Extensive experiments conducted on both IRV2V and the real-world dataset DAIR-V2X show that CoBEVFlow consistently outperforms other baselines and is robust in extremely asynchronous settings. The code is available at https://github.com/MediaBrain-SJTU/CoBEVFlow.