 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Space Observation by the Australia Telescope Compact Array: Performance Characterization using GPS Satellite Observation
Oct 07, 2023
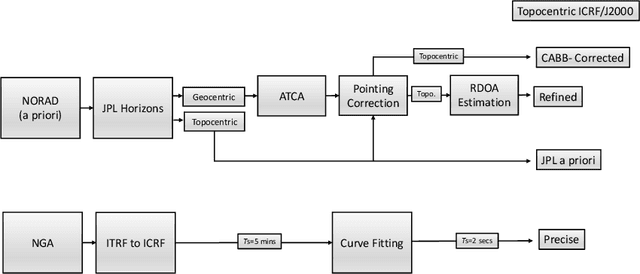
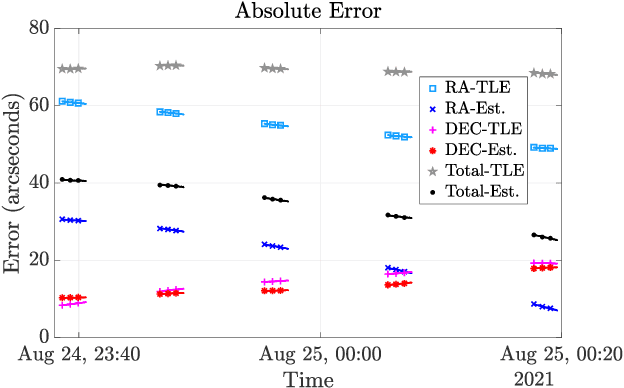
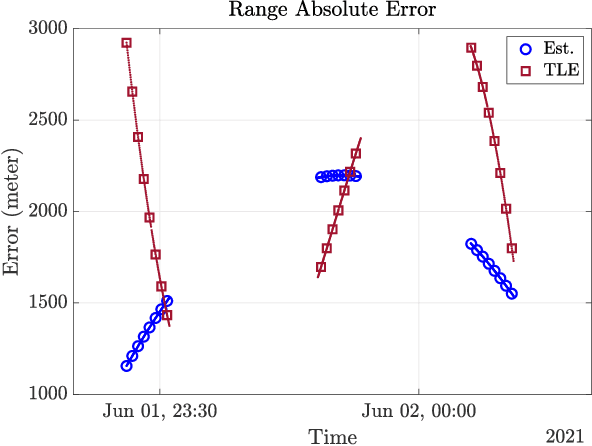
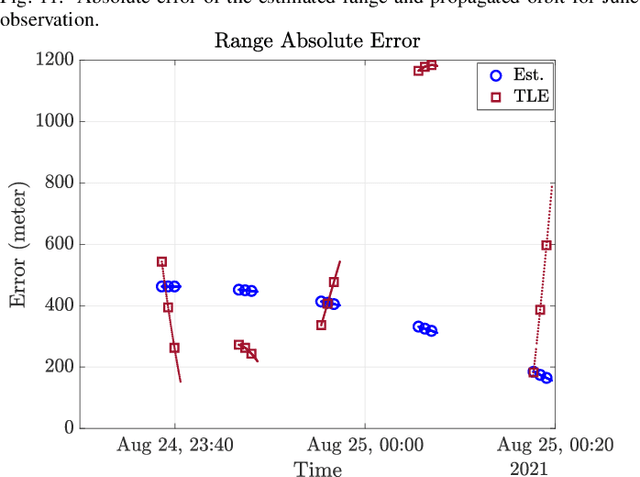
In order to operationalize the Australia Telescope Compact Array (ATCA) for space situational awareness (SSA) applications, we develop a system model for range and direction of arrival (DOA) estimation based on the interferometric data. We employ the observational data collected from global positioning system (GPS) satellites to evaluate the developed model and demonstrate that, compared to a priori location propagated from the most recent two-line element (TLE), both range and direction information are improved significantly.
FOSA: Full Information Maximum Likelihood (FIML) Optimized Self-Attention Imputation for Missing Data
Aug 23, 2023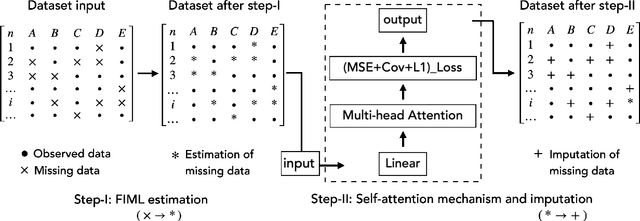

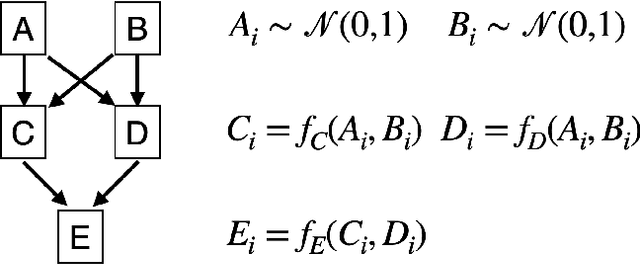
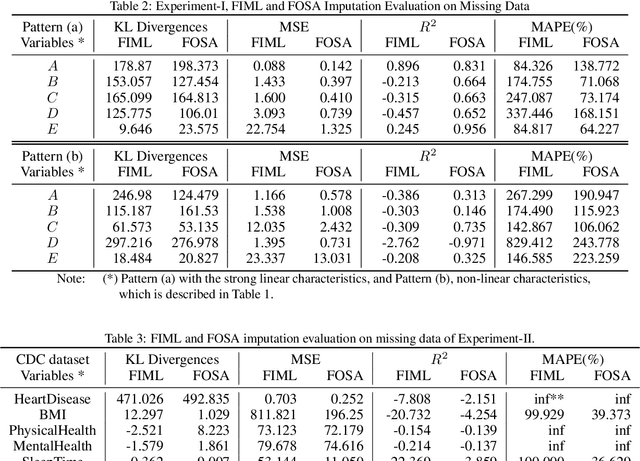
In data imputation, effectively addressing missing values is pivotal, especially in intricate datasets. This paper delves into the FIML Optimized Self-attention (FOSA) framework, an innovative approach that amalgamates the strengths of Full Information Maximum Likelihood (FIML) estimation with the capabilities of self-attention neural networks. Our methodology commences with an initial estimation of missing values via FIML, subsequently refining these estimates by leveraging the self-attention mechanism. Our comprehensive experiments on both simulated and real-world datasets underscore FOSA's pronounced advantages over traditional FIML techniques, encapsulating facets of accuracy, computational efficiency, and adaptability to diverse data structures. Intriguingly, even in scenarios where the Structural Equation Model (SEM) might be mis-specified, leading to suboptimal FIML estimates, the robust architecture of FOSA's self-attention component adeptly rectifies and optimizes the imputation outcomes. Our empirical tests reveal that FOSA consistently delivers commendable predictions, even in the face of up to 40% random missingness, highlighting its robustness and potential for wide-scale applications in data imputation.
COIN-LIO: Complementary Intensity-Augmented LiDAR Inertial Odometry
Oct 02, 2023
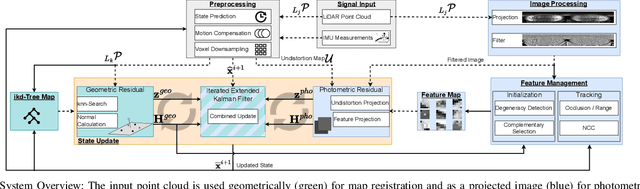


We present COIN-LIO, a LiDAR Inertial Odometry pipeline that tightly couples information from LiDAR intensity with geometry-based point cloud registration. The focus of our work is to improve the robustness of LiDAR-inertial odometry in geometrically degenerate scenarios, like tunnels or flat fields. We project LiDAR intensity returns into an intensity image, and propose an image processing pipeline that produces filtered images with improved brightness consistency within the image as well as across different scenes. To effectively leverage intensity as an additional modality, we present a novel feature selection scheme that detects uninformative directions in the point cloud registration and explicitly selects patches with complementary image information. Photometric error minimization in the image patches is then fused with inertial measurements and point-to-plane registration in an iterated Extended Kalman Filter. The proposed approach improves accuracy and robustness on a public dataset. We additionally publish a new dataset, that captures five real-world environments in challenging, geometrically degenerate scenes. By using the additional photometric information, our approach shows drastically improved robustness against geometric degeneracy in environments where all compared baseline approaches fail.
Leave-one-out Distinguishability in Machine Learning
Sep 29, 2023We introduce a new analytical framework to quantify the changes in a machine learning algorithm's output distribution following the inclusion of a few data points in its training set, a notion we define as leave-one-out distinguishability (LOOD). This problem is key to measuring data **memorization** and **information leakage** in machine learning, and the **influence** of training data points on model predictions. We illustrate how our method broadens and refines existing empirical measures of memorization and privacy risks associated with training data. We use Gaussian processes to model the randomness of machine learning algorithms, and validate LOOD with extensive empirical analysis of information leakage using membership inference attacks. Our theoretical framework enables us to investigate the causes of information leakage and where the leakage is high. For example, we analyze the influence of activation functions, on data memorization. Additionally, our method allows us to optimize queries that disclose the most significant information about the training data in the leave-one-out setting. We illustrate how optimal queries can be used for accurate **reconstruction** of training data.
IPMix: Label-Preserving Data Augmentation Method for Training Robust Classifiers
Oct 13, 2023
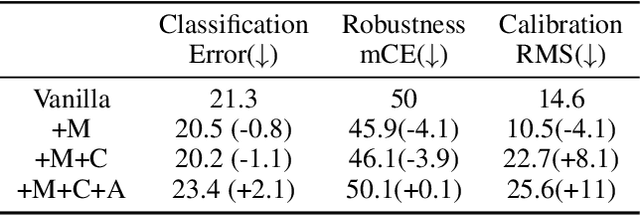
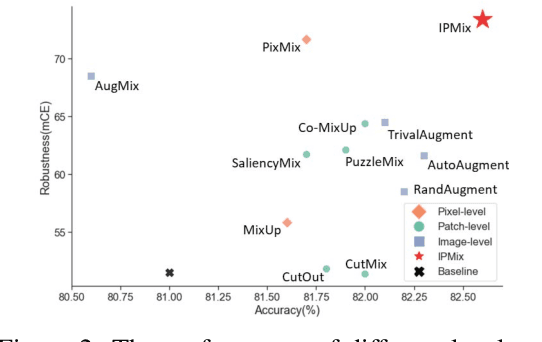
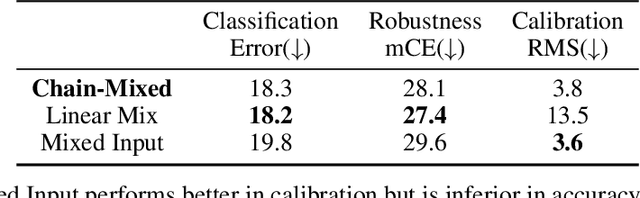
Data augmentation has been proven effective for training high-accuracy convolutional neural network classifiers by preventing overfitting. However, building deep neural networks in real-world scenarios requires not only high accuracy on clean data but also robustness when data distributions shift. While prior methods have proposed that there is a trade-off between accuracy and robustness, we propose IPMix, a simple data augmentation approach to improve robustness without hurting clean accuracy. IPMix integrates three levels of data augmentation (image-level, patch-level, and pixel-level) into a coherent and label-preserving technique to increase the diversity of training data with limited computational overhead. To further improve the robustness, IPMix introduces structural complexity at different levels to generate more diverse images and adopts the random mixing method for multi-scale information fusion. Experiments demonstrate that IPMix outperforms state-of-the-art corruption robustness on CIFAR-C and ImageNet-C. In addition, we show that IPMix also significantly improves the other safety measures, including robustness to adversarial perturbations, calibration, prediction consistency, and anomaly detection, achieving state-of-the-art or comparable results on several benchmarks, including ImageNet-R, ImageNet-A, and ImageNet-O.
R&B: Region and Boundary Aware Zero-shot Grounded Text-to-image Generation
Oct 13, 2023Recent text-to-image (T2I) diffusion models have achieved remarkable progress in generating high-quality images given text-prompts as input. However, these models fail to convey appropriate spatial composition specified by a layout instruction. In this work, we probe into zero-shot grounded T2I generation with diffusion models, that is, generating images corresponding to the input layout information without training auxiliary modules or finetuning diffusion models. We propose a Region and Boundary (R&B) aware cross-attention guidance approach that gradually modulates the attention maps of diffusion model during generative process, and assists the model to synthesize images (1) with high fidelity, (2) highly compatible with textual input, and (3) interpreting layout instructions accurately. Specifically, we leverage the discrete sampling to bridge the gap between consecutive attention maps and discrete layout constraints, and design a region-aware loss to refine the generative layout during diffusion process. We further propose a boundary-aware loss to strengthen object discriminability within the corresponding regions. Experimental results show that our method outperforms existing state-of-the-art zero-shot grounded T2I generation methods by a large margin both qualitatively and quantitatively on several benchmarks.
Alteration Detection of Tensor Dependence Structure via Sparsity-Exploited Reranking Algorithm
Oct 13, 2023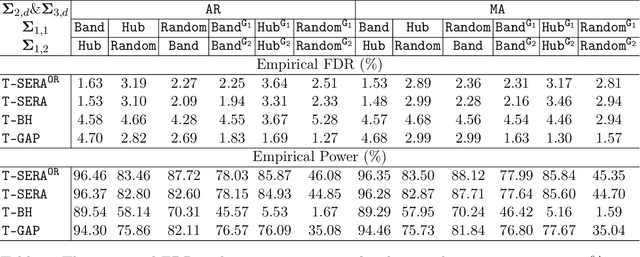
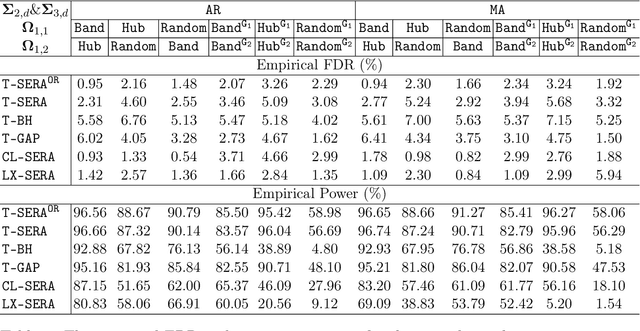
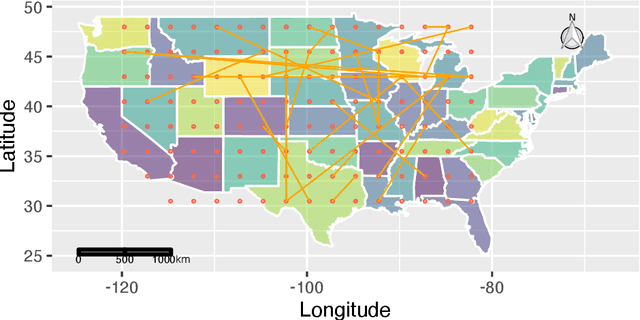
Tensor-valued data arise frequently from a wide variety of scientific applications, and many among them can be translated into an alteration detection problem of tensor dependence structures. In this article, we formulate the problem under the popularly adopted tensor-normal distributions and aim at two-sample correlation/partial correlation comparisons of tensor-valued observations. Through decorrelation and centralization, a separable covariance structure is employed to pool sample information from different tensor modes to enhance the power of the test. Additionally, we propose a novel Sparsity-Exploited Reranking Algorithm (SERA) to further improve the multiple testing efficiency. The algorithm is approached through reranking of the p-values derived from the primary test statistics, by incorporating a carefully constructed auxiliary tensor sequence. Besides the tensor framework, SERA is also generally applicable to a wide range of two-sample large-scale inference problems with sparsity structures, and is of independent interest. The asymptotic properties of the proposed test are derived and the algorithm is shown to control the false discovery at the pre-specified level. We demonstrate the efficacy of the proposed method through intensive simulations and two scientific applications.
DSG: An End-to-End Document Structure Generator
Oct 13, 2023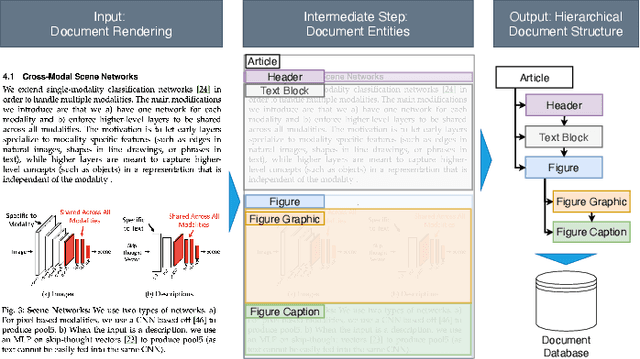
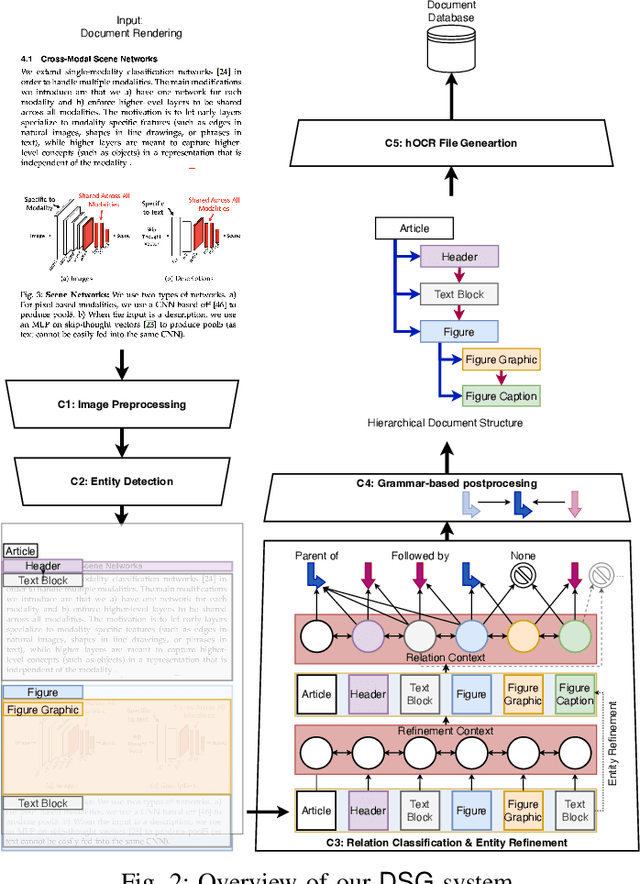
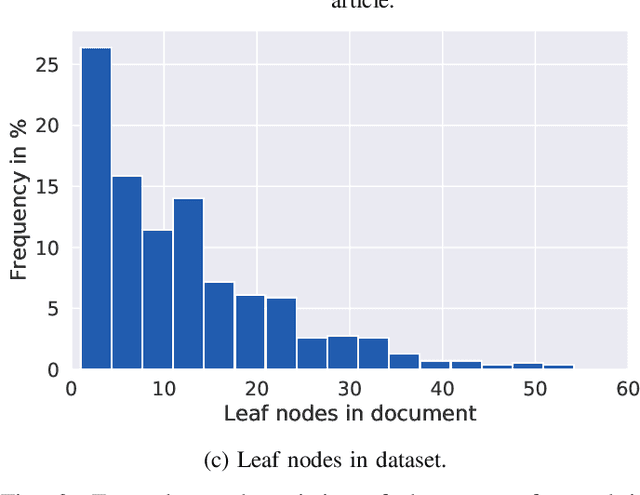
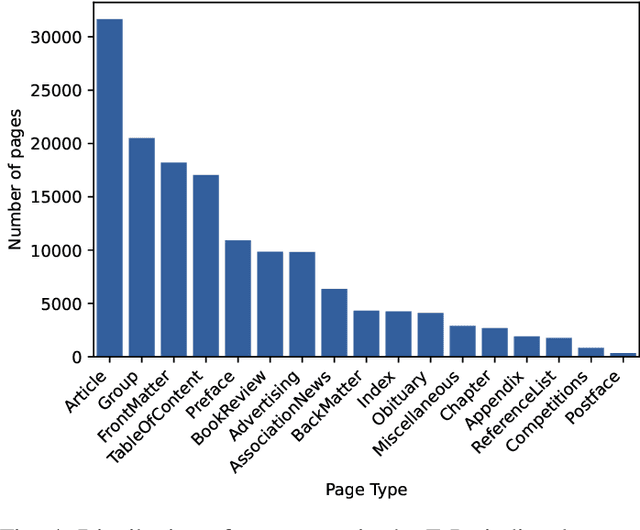
Information in industry, research, and the public sector is widely stored as rendered documents (e.g., PDF files, scans). Hence, to enable downstream tasks, systems are needed that map rendered documents onto a structured hierarchical format. However, existing systems for this task are limited by heuristics and are not end-to-end trainable. In this work, we introduce the Document Structure Generator (DSG), a novel system for document parsing that is fully end-to-end trainable. DSG combines a deep neural network for parsing (i) entities in documents (e.g., figures, text blocks, headers, etc.) and (ii) relations that capture the sequence and nested structure between entities. Unlike existing systems that rely on heuristics, our DSG is trained end-to-end, making it effective and flexible for real-world applications. We further contribute a new, large-scale dataset called E-Periodica comprising real-world magazines with complex document structures for evaluation. Our results demonstrate that our DSG outperforms commercial OCR tools and, on top of that, achieves state-of-the-art performance. To the best of our knowledge, our DSG system is the first end-to-end trainable system for hierarchical document parsing.
Ultrasound Image Segmentation of Thyroid Nodule via Latent Semantic Feature Co-Registration
Oct 13, 2023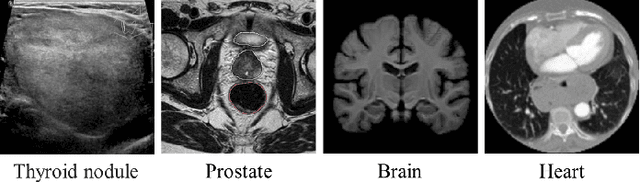
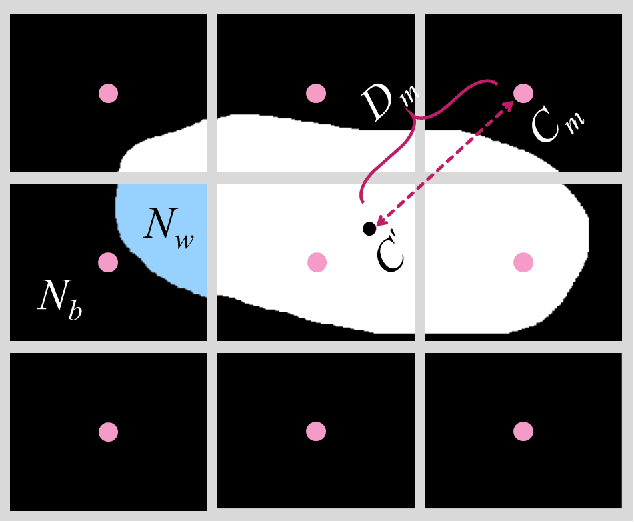
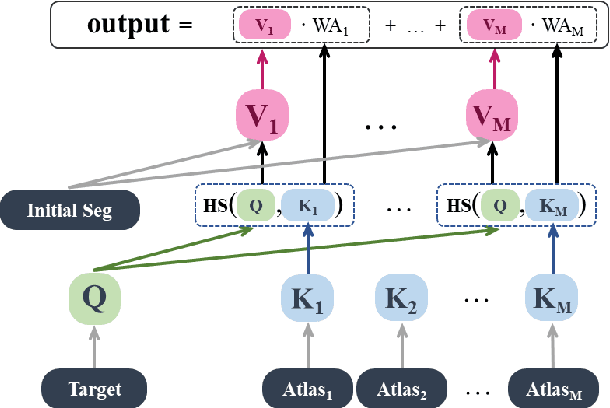
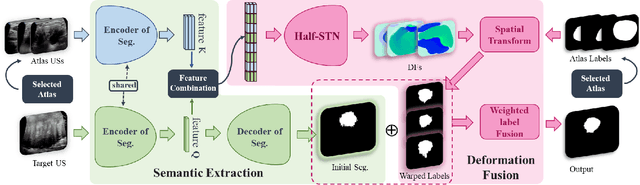
Segmentation of nodules in thyroid ultrasound imaging plays a crucial role in the detection and treatment of thyroid cancer. However, owing to the diversity of scanner vendors and imaging protocols in different hospitals, the automatic segmentation model, which has already demonstrated expert-level accuracy in the field of medical image segmentation, finds its accuracy reduced as the result of its weak generalization performance when being applied in clinically realistic environments. To address this issue, the present paper proposes ASTN, a framework for thyroid nodule segmentation achieved through a new type co-registration network. By extracting latent semantic information from the atlas and target images and utilizing in-depth features to accomplish the co-registration of nodules in thyroid ultrasound images, this framework can ensure the integrity of anatomical structure and reduce the impact on segmentation as the result of overall differences in image caused by different devices. In addition, this paper also provides an atlas selection algorithm to mitigate the difficulty of co-registration. As shown by the evaluation results collected from the datasets of different devices, thanks to the method we proposed, the model generalization has been greatly improved while maintaining a high level of segmentation accuracy.
Jointly-Learned Exit and Inference for a Dynamic Neural Network : JEI-DNN
Oct 13, 2023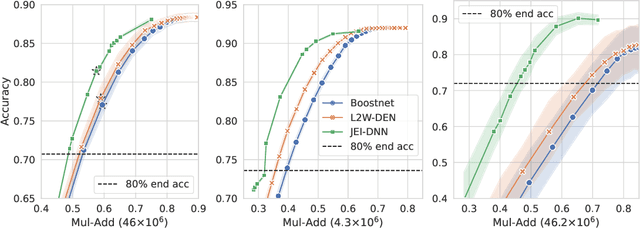
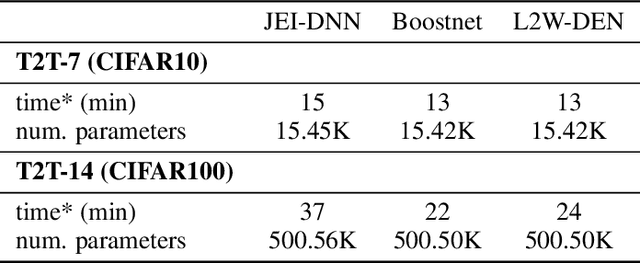
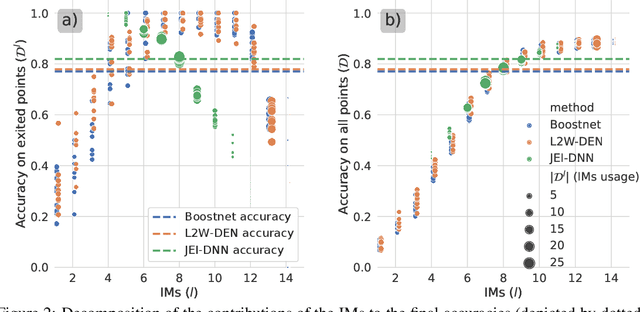

Large pretrained models, coupled with fine-tuning, are slowly becoming established as the dominant architecture in machine learning. Even though these models offer impressive performance, their practical application is often limited by the prohibitive amount of resources required for every inference. Early-exiting dynamic neural networks (EDNN) circumvent this issue by allowing a model to make some of its predictions from intermediate layers (i.e., early-exit). Training an EDNN architecture is challenging as it consists of two intertwined components: the gating mechanism (GM) that controls early-exiting decisions and the intermediate inference modules (IMs) that perform inference from intermediate representations. As a result, most existing approaches rely on thresholding confidence metrics for the gating mechanism and strive to improve the underlying backbone network and the inference modules. Although successful, this approach has two fundamental shortcomings: 1) the GMs and the IMs are decoupled during training, leading to a train-test mismatch; and 2) the thresholding gating mechanism introduces a positive bias into the predictive probabilities, making it difficult to readily extract uncertainty information. We propose a novel architecture that connects these two modules. This leads to significant performance improvements on classification datasets and enables better uncertainty characterization capabilities.