 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Music- and Lyrics-driven Dance Synthesis
Sep 30, 2023
Lyrics often convey information about the songs that are beyond the auditory dimension, enriching the semantic meaning of movements and musical themes. Such insights are important in the dance choreography domain. However, most existing dance synthesis methods mainly focus on music-to-dance generation, without considering the semantic information. To complement it, we introduce JustLMD, a new multimodal dataset of 3D dance motion with music and lyrics. To the best of our knowledge, this is the first dataset with triplet information including dance motion, music, and lyrics. Additionally, we showcase a cross-modal diffusion-based network designed to generate 3D dance motion conditioned on music and lyrics. The proposed JustLMD dataset encompasses 4.6 hours of 3D dance motion in 1867 sequences, accompanied by musical tracks and their corresponding English lyrics.
Multi-Factor Spatio-Temporal Prediction based on Graph Decomposition Learning
Oct 16, 2023Spatio-temporal (ST) prediction is an important and widely used technique in data mining and analytics, especially for ST data in urban systems such as transportation data. In practice, the ST data generation is usually influenced by various latent factors tied to natural phenomena or human socioeconomic activities, impacting specific spatial areas selectively. However, existing ST prediction methods usually do not refine the impacts of different factors, but directly model the entangled impacts of multiple factors. This amplifies the modeling complexity of ST data and compromises model interpretability. To this end, we propose a multi-factor ST prediction task that predicts partial ST data evolution under different factors, and combines them for a final prediction. We make two contributions to this task: an effective theoretical solution and a portable instantiation framework. Specifically, we first propose a theoretical solution called decomposed prediction strategy and prove its effectiveness from the perspective of information entropy theory. On top of that, we instantiate a novel model-agnostic framework, named spatio-temporal graph decomposition learning (STGDL), for multi-factor ST prediction. The framework consists of two main components: an automatic graph decomposition module that decomposes the original graph structure inherent in ST data into subgraphs corresponding to different factors, and a decomposed learning network that learns the partial ST data on each subgraph separately and integrates them for the final prediction. We conduct extensive experiments on four real-world ST datasets of two types of graphs, i.e., grid graph and network graph. Results show that our framework significantly reduces prediction errors of various ST models by 9.41% on average (35.36% at most). Furthermore, a case study reveals the interpretability potential of our framework.
Visual Data-Type Understanding does not emerge from Scaling Vision-Language Models
Oct 16, 2023Recent advances in the development of vision-language models (VLMs) are yielding remarkable success in recognizing visual semantic content, including impressive instances of compositional image understanding. Here, we introduce the novel task of Visual Data-Type Identification, a basic perceptual skill with implications for data curation (e.g., noisy data-removal from large datasets, domain-specific retrieval) and autonomous vision (e.g., distinguishing changing weather conditions from camera lens staining). We develop two datasets consisting of animal images altered across a diverse set of 27 visual data-types, spanning four broad categories. An extensive zero-shot evaluation of 39 VLMs, ranging from 100M to 80B parameters, shows a nuanced performance landscape. While VLMs are reasonably good at identifying certain stylistic \textit{data-types}, such as cartoons and sketches, they struggle with simpler data-types arising from basic manipulations like image rotations or additive noise. Our findings reveal that (i) model scaling alone yields marginal gains for contrastively-trained models like CLIP, and (ii) there is a pronounced drop in performance for the largest auto-regressively trained VLMs like OpenFlamingo. This finding points to a blind spot in current frontier VLMs: they excel in recognizing semantic content but fail to acquire an understanding of visual data-types through scaling. By analyzing the pre-training distributions of these models and incorporating data-type information into the captions during fine-tuning, we achieve a significant enhancement in performance. By exploring this previously uncharted task, we aim to set the stage for further advancing VLMs to equip them with visual data-type understanding. Code and datasets are released at https://github.com/bethgelab/DataTypeIdentification.
Self-supervised Fetal MRI 3D Reconstruction Based on Radiation Diffusion Generation Model
Oct 16, 2023Although the use of multiple stacks can handle slice-to-volume motion correction and artifact removal problems, there are still several problems: 1) The slice-to-volume method usually uses slices as input, which cannot solve the problem of uniform intensity distribution and complementarity in regions of different fetal MRI stacks; 2) The integrity of 3D space is not considered, which adversely affects the discrimination and generation of globally consistent information in fetal MRI; 3) Fetal MRI with severe motion artifacts in the real-world cannot achieve high-quality super-resolution reconstruction. To address these issues, we propose a novel fetal brain MRI high-quality volume reconstruction method, called the Radiation Diffusion Generation Model (RDGM). It is a self-supervised generation method, which incorporates the idea of Neural Radiation Field (NeRF) based on the coordinate generation and diffusion model based on super-resolution generation. To solve regional intensity heterogeneity in different directions, we use a pre-trained transformer model for slice registration, and then, a new regionally Consistent Implicit Neural Representation (CINR) network sub-module is proposed. CINR can generate the initial volume by combining a coordinate association map of two different coordinate mapping spaces. To enhance volume global consistency and discrimination, we introduce the Volume Diffusion Super-resolution Generation (VDSG) mechanism. The global intensity discriminant generation from volume-to-volume is carried out using the idea of diffusion generation, and CINR becomes the deviation intensity generation network of the volume-to-volume diffusion model. Finally, the experimental results on real-world fetal brain MRI stacks demonstrate the state-of-the-art performance of our method.
From Spectral Theorem to Statistical Independence with Application to System Identification
Oct 16, 2023High dimensional random dynamical systems are ubiquitous, including -- but not limited to -- cyber-physical systems, daily return on different stocks of S&P 1500 and velocity profile of interacting particle systems around McKeanVlasov limit. Mathematically, underlying phenomenon can be captured via a stable $n$-dimensional linear transformation `$A$' and additive randomness. System identification aims at extracting useful information about underlying dynamical system, given a length $N$ trajectory from it (corresponds to an $n \times N$ dimensional data matrix). We use spectral theorem for non-Hermitian operators to show that spatio-temperal correlations are dictated by the discrepancy between algebraic and geometric multiplicity of distinct eigenvalues corresponding to state transition matrix. Small discrepancies imply that original trajectory essentially comprises of multiple lower dimensional random dynamical systems living on $A$ invariant subspaces and are statistically independent of each other. In the process, we provide first quantitative handle on decay rate of finite powers of state transition matrix $\|A^{k}\|$ . It is shown that when a stable dynamical system has only one distinct eigenvalue and discrepancy of $n-1$: $\|A\|$ has a dependence on $n$, resulting dynamics are spatially inseparable and consequently there exist at least one row with covariates of typical size $\Theta\big(\sqrt{N-n+1}$ $e^{n}\big)$ i.e., even under stability assumption, covariates can suffer from curse of dimensionality. In the light of these findings we set the stage for non-asymptotic error analysis in estimation of state transition matrix $A$ via least squares regression on observed trajectory by showing that element-wise error is essentially a variant of well-know Littlewood-Offord problem.
No Compromise in Solution Quality: Speeding Up Belief-dependent Continuous POMDPs via Adaptive Multilevel Simplification
Oct 16, 2023Continuous POMDPs with general belief-dependent rewards are notoriously difficult to solve online. In this paper, we present a complete provable theory of adaptive multilevel simplification for the setting of a given externally constructed belief tree and MCTS that constructs the belief tree on the fly using an exploration technique. Our theory allows to accelerate POMDP planning with belief-dependent rewards without any sacrifice in the quality of the obtained solution. We rigorously prove each theoretical claim in the proposed unified theory. Using the general theoretical results, we present three algorithms to accelerate continuous POMDP online planning with belief-dependent rewards. Our two algorithms, SITH-BSP and LAZY-SITH-BSP, can be utilized on top of any method that constructs a belief tree externally. The third algorithm, SITH-PFT, is an anytime MCTS method that permits to plug-in any exploration technique. All our methods are guaranteed to return exactly the same optimal action as their unsimplified equivalents. We replace the costly computation of information-theoretic rewards with novel adaptive upper and lower bounds which we derive in this paper, and are of independent interest. We show that they are easy to calculate and can be tightened by the demand of our algorithms. Our approach is general; namely, any bounds that monotonically converge to the reward can be easily plugged-in to achieve significant speedup without any loss in performance. Our theory and algorithms support the challenging setting of continuous states, actions, and observations. The beliefs can be parametric or general and represented by weighted particles. We demonstrate in simulation a significant speedup in planning compared to baseline approaches with guaranteed identical performance.
LMT: Longitudinal Mixing Training, a Framework to Predict Disease Progression from a Single Image
Oct 16, 2023Longitudinal imaging is able to capture both static anatomical structures and dynamic changes in disease progression toward earlier and better patient-specific pathology management. However, conventional approaches rarely take advantage of longitudinal information for detection and prediction purposes, especially for Diabetic Retinopathy (DR). In the past years, Mix-up training and pretext tasks with longitudinal context have effectively enhanced DR classification results and captured disease progression. In the meantime, a novel type of neural network named Neural Ordinary Differential Equation (NODE) has been proposed for solving ordinary differential equations, with a neural network treated as a black box. By definition, NODE is well suited for solving time-related problems. In this paper, we propose to combine these three aspects to detect and predict DR progression. Our framework, Longitudinal Mixing Training (LMT), can be considered both as a regularizer and as a pretext task that encodes the disease progression in the latent space. Additionally, we evaluate the trained model weights on a downstream task with a longitudinal context using standard and longitudinal pretext tasks. We introduce a new way to train time-aware models using $t_{mix}$, a weighted average time between two consecutive examinations. We compare our approach to standard mixing training on DR classification using OPHDIAT a longitudinal retinal Color Fundus Photographs (CFP) dataset. We were able to predict whether an eye would develop a severe DR in the following visit using a single image, with an AUC of 0.798 compared to baseline results of 0.641. Our results indicate that our longitudinal pretext task can learn the progression of DR disease and that introducing $t_{mix}$ augmentation is beneficial for time-aware models.
Predicting Future Spatiotemporal Occupancy Grids with Semantics for Autonomous Driving
Oct 03, 2023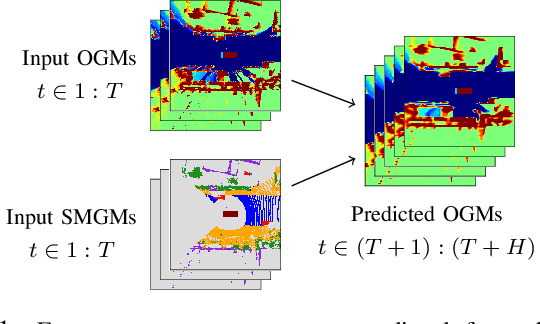
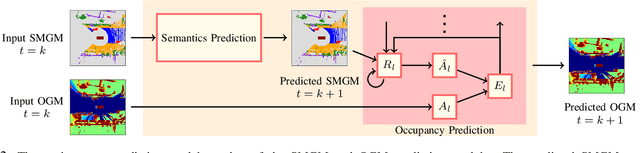
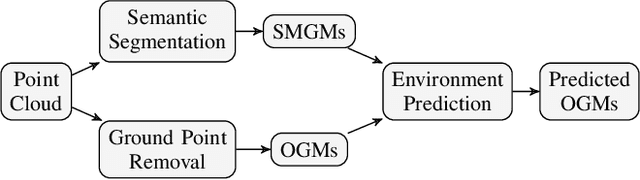
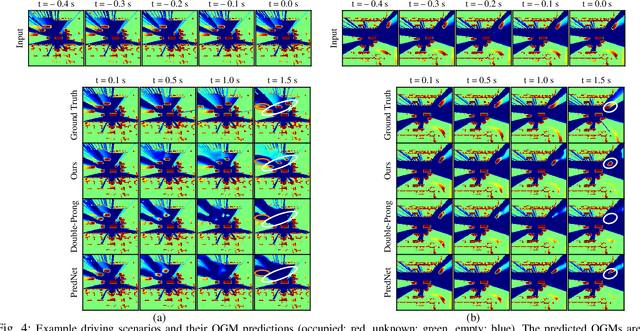
For autonomous vehicles to proactively plan safe trajectories and make informed decisions, they must be able to predict the future occupancy states of the local environment. However, common issues with occupancy prediction include predictions where moving objects vanish or become blurred, particularly at longer time horizons. We propose an environment prediction framework that incorporates environment semantics for future occupancy prediction. Our method first semantically segments the environment and uses this information along with the occupancy information to predict the spatiotemporal evolution of the environment. We validate our approach on the real-world Waymo Open Dataset. Compared to baseline methods, our model has higher prediction accuracy and is capable of maintaining moving object appearances in the predictions for longer prediction time horizons.
Linear Progressive Coding for Semantic Communication using Deep Neural Networks
Sep 27, 2023We propose a general method for semantic representation of images and other data using progressive coding. Semantic coding allows for specific pieces of information to be selectively encoded into a set of measurements that can be highly compressed compared to the size of the original raw data. We consider a hierarchical method of coding where a partial amount of semantic information is first encoded a into a coarse representation of the data, which is then refined by additional encodings that add additional semantic information. Such hierarchical coding is especially well-suited for semantic communication i.e. transferring semantic information over noisy channels. Our proposed method can be considered as a generalization of both progressive image compression and source coding for semantic communication. We present results from experiments on the MNIST and CIFAR-10 datasets that show that progressive semantic coding can provide timely previews of semantic information with a small number of initial measurements while achieving overall accuracy and efficiency comparable to non-progressive methods.
Space Observation by the Australia Telescope Compact Array: Performance Characterization using GPS Satellite Observation
Oct 07, 2023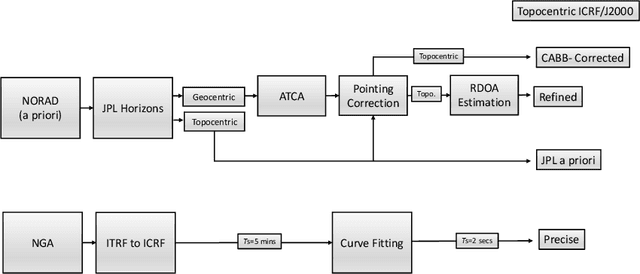
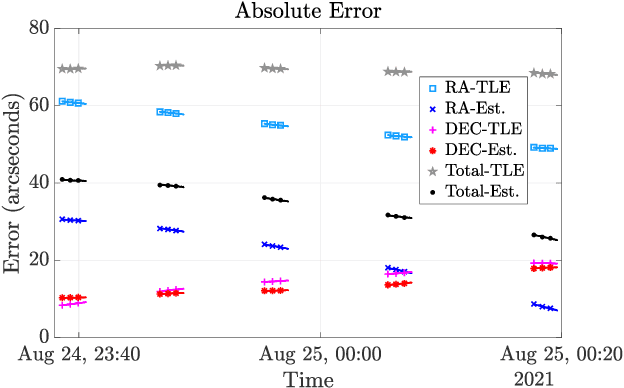
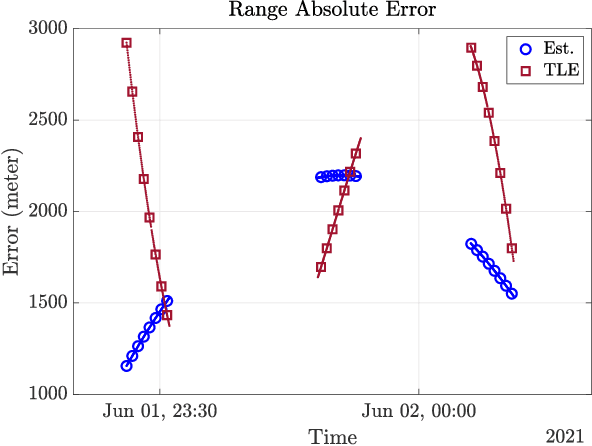
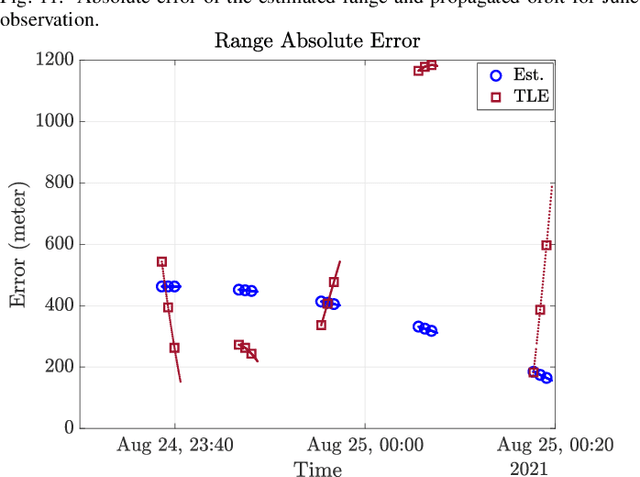
In order to operationalize the Australia Telescope Compact Array (ATCA) for space situational awareness (SSA) applications, we develop a system model for range and direction of arrival (DOA) estimation based on the interferometric data. We employ the observational data collected from global positioning system (GPS) satellites to evaluate the developed model and demonstrate that, compared to a priori location propagated from the most recent two-line element (TLE), both range and direction information are improved significantly.