 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Machine Learning Approach to Predicting Single Event Upsets
Oct 09, 2023
A single event upset (SEU) is a critical soft error that occurs in semiconductor devices on exposure to ionising particles from space environments. SEUs cause bit flips in the memory component of semiconductors. This creates a multitude of safety hazards as stored information becomes less reliable. Currently, SEUs are only detected several hours after their occurrence. CREMER, the model presented in this paper, predicts SEUs in advance using machine learning. CREMER uses only positional data to predict SEU occurrence, making it robust, inexpensive and scalable. Upon implementation, the improved reliability of memory devices will create a digitally safer environment onboard space vehicles.
Get the gist? Using large language models for few-shot decontextualization
Oct 10, 2023
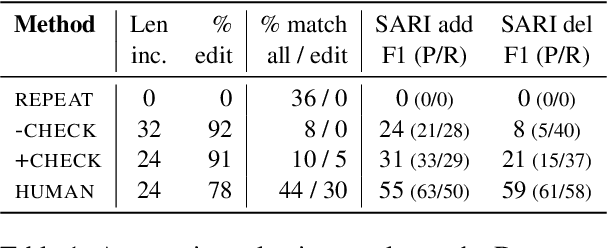
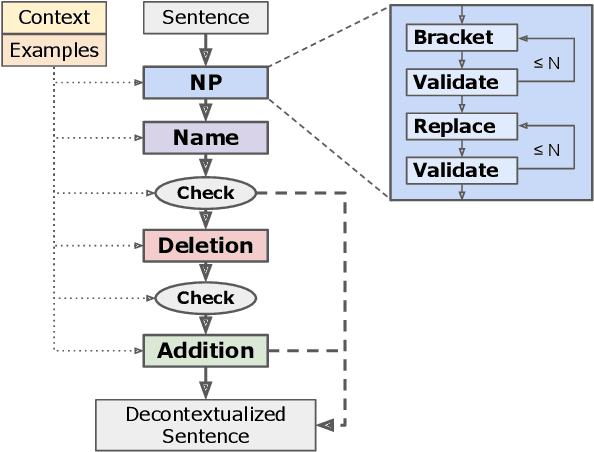
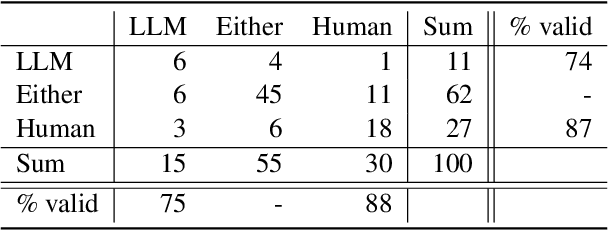
In many NLP applications that involve interpreting sentences within a rich context -- for instance, information retrieval systems or dialogue systems -- it is desirable to be able to preserve the sentence in a form that can be readily understood without context, for later reuse -- a process known as ``decontextualization''. While previous work demonstrated that generative Seq2Seq models could effectively perform decontextualization after being fine-tuned on a specific dataset, this approach requires expensive human annotations and may not transfer to other domains. We propose a few-shot method of decontextualization using a large language model, and present preliminary results showing that this method achieves viable performance on multiple domains using only a small set of examples.
Radar Instance Transformer: Reliable Moving Instance Segmentation in Sparse Radar Point Clouds
Sep 28, 2023The perception of moving objects is crucial for autonomous robots performing collision avoidance in dynamic environments. LiDARs and cameras tremendously enhance scene interpretation but do not provide direct motion information and face limitations under adverse weather. Radar sensors overcome these limitations and provide Doppler velocities, delivering direct information on dynamic objects. In this paper, we address the problem of moving instance segmentation in radar point clouds to enhance scene interpretation for safety-critical tasks. Our Radar Instance Transformer enriches the current radar scan with temporal information without passing aggregated scans through a neural network. We propose a full-resolution backbone to prevent information loss in sparse point cloud processing. Our instance transformer head incorporates essential information to enhance segmentation but also enables reliable, class-agnostic instance assignments. In sum, our approach shows superior performance on the new moving instance segmentation benchmarks, including diverse environments, and provides model-agnostic modules to enhance scene interpretation. The benchmark is based on the RadarScenes dataset and will be made available upon acceptance.
Accurate Cold-start Bundle Recommendation via Popularity-based Coalescence and Curriculum Heating
Oct 05, 2023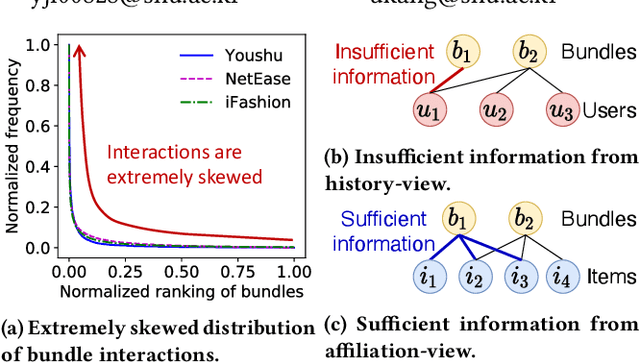

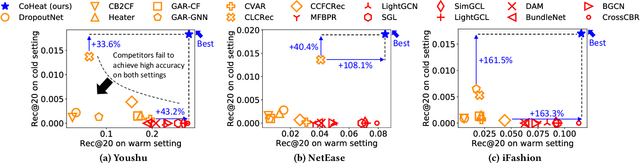
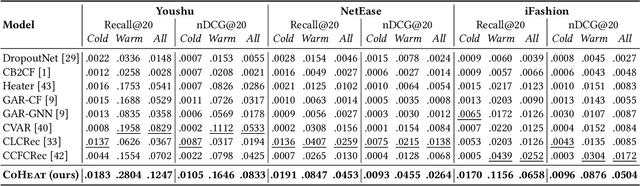
How can we accurately recommend cold-start bundles to users? The cold-start problem in bundle recommendation is critical in practical scenarios since new bundles are continuously created for various marketing purposes. Despite its importance, no previous studies have addressed cold-start bundle recommendation. Moreover, existing methods for cold-start item recommendation overly rely on historical information, even for unpopular bundles, failing to tackle the primary challenge of the highly skewed distribution of bundle interactions. In this work, we propose CoHeat (Popularity-based Coalescence and Curriculum Heating), an accurate approach for the cold-start bundle recommendation. CoHeat tackles the highly skewed distribution of bundle interactions by incorporating both historical and affiliation information based on the bundle's popularity when estimating the user-bundle relationship. Furthermore, CoHeat effectively learns latent representations by exploiting curriculum learning and contrastive learning. CoHeat demonstrates superior performance in cold-start bundle recommendation, achieving up to 193% higher nDCG@20 compared to the best competitor.
Global Convergence of Policy Gradient Methods in Reinforcement Learning, Games and Control
Oct 08, 2023Policy gradient methods, where one searches for the policy of interest by maximizing the value functions using first-order information, become increasingly popular for sequential decision making in reinforcement learning, games, and control. Guaranteeing the global optimality of policy gradient methods, however, is highly nontrivial due to nonconcavity of the value functions. In this exposition, we highlight recent progresses in understanding and developing policy gradient methods with global convergence guarantees, putting an emphasis on their finite-time convergence rates with regard to salient problem parameters.
LANCAR: Leveraging Language for Context-Aware Robot Locomotion in Unstructured Environments
Sep 30, 2023Robotic locomotion is a challenging task, especially in unstructured terrains. In practice, the optimal locomotion policy can be context-dependent by using the contextual information of encountered terrains in decision-making. Humans can interpret the environmental context for robots, but the ambiguity of human language makes it challenging to use in robot locomotion directly. In this paper, we propose a novel approach, LANCAR, that introduces a context translator that works with reinforcement learning (RL) agents for context-aware locomotion. Our formulation allows a robot to interpret the contextual information from environments generated by human observers or Vision-Language Models (VLM) with Large Language Models (LLM) and use this information to generate contextual embeddings. We incorporate the contextual embeddings with the robot's internal environmental observations as the input to the RL agent's decision neural network. We evaluate LANCAR with contextual information in varying ambiguity levels and compare its performance using several alternative approaches. Our experimental results demonstrate that our approach exhibits good generalizability and adaptability across diverse terrains, by achieving at least 10% of performance improvement in episodic reward over baselines. The experiment video can be found at the following link: https://raaslab.org/projects/LLM_Context_Estimation/.
ClimateBERT-NetZero: Detecting and Assessing Net Zero and Reduction Targets
Oct 12, 2023
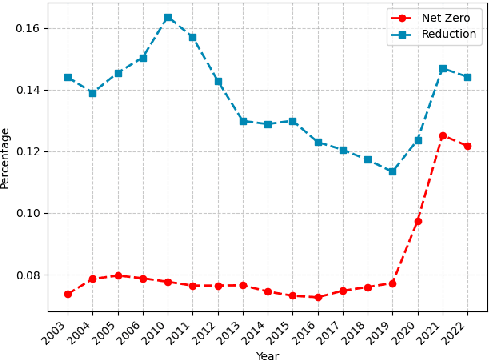
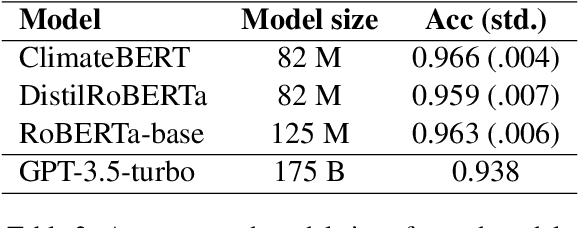
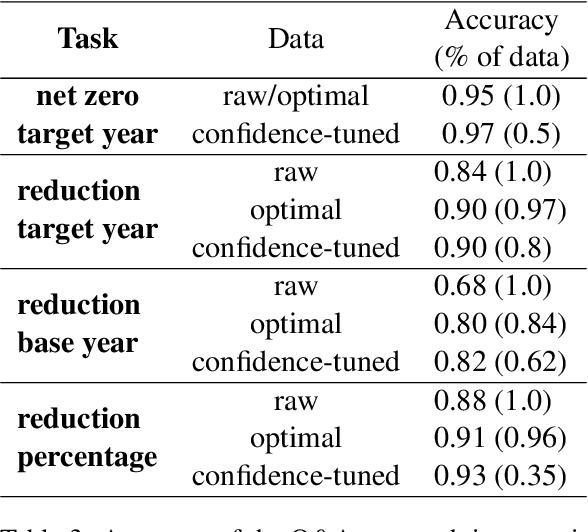
Public and private actors struggle to assess the vast amounts of information about sustainability commitments made by various institutions. To address this problem, we create a novel tool for automatically detecting corporate, national, and regional net zero and reduction targets in three steps. First, we introduce an expert-annotated data set with 3.5K text samples. Second, we train and release ClimateBERT-NetZero, a natural language classifier to detect whether a text contains a net zero or reduction target. Third, we showcase its analysis potential with two use cases: We first demonstrate how ClimateBERT-NetZero can be combined with conventional question-answering (Q&A) models to analyze the ambitions displayed in net zero and reduction targets. Furthermore, we employ the ClimateBERT-NetZero model on quarterly earning call transcripts and outline how communication patterns evolve over time. Our experiments demonstrate promising pathways for extracting and analyzing net zero and emission reduction targets at scale.
Heterophily-Based Graph Neural Network for Imbalanced Classification
Oct 12, 2023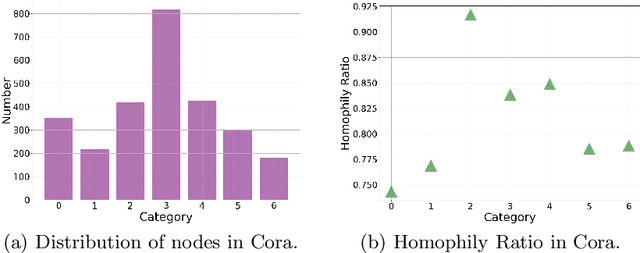

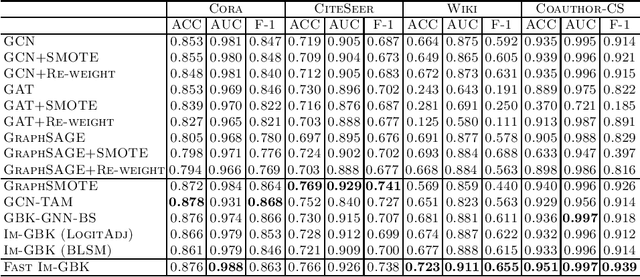
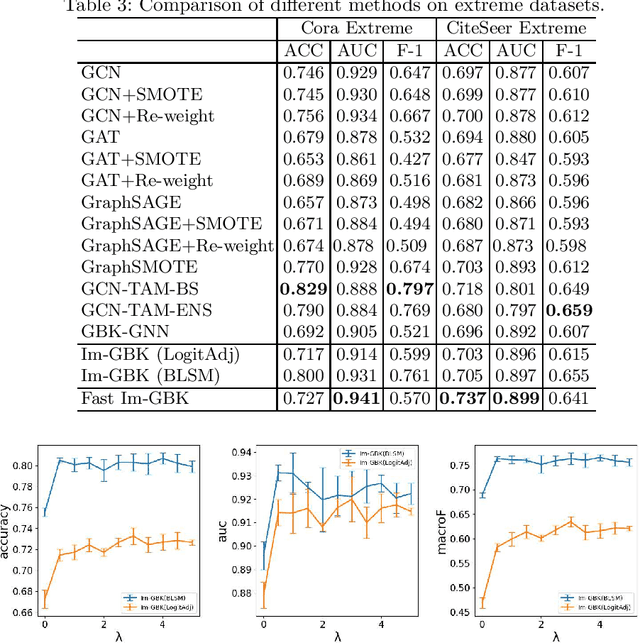
Graph neural networks (GNNs) have shown promise in addressing graph-related problems, including node classification. However, conventional GNNs assume an even distribution of data across classes, which is often not the case in real-world scenarios, where certain classes are severely underrepresented. This leads to suboptimal performance of standard GNNs on imbalanced graphs. In this paper, we introduce a unique approach that tackles imbalanced classification on graphs by considering graph heterophily. We investigate the intricate relationship between class imbalance and graph heterophily, revealing that minority classes not only exhibit a scarcity of samples but also manifest lower levels of homophily, facilitating the propagation of erroneous information among neighboring nodes. Drawing upon this insight, we propose an efficient method, called Fast Im-GBK, which integrates an imbalance classification strategy with heterophily-aware GNNs to effectively address the class imbalance problem while significantly reducing training time. Our experiments on real-world graphs demonstrate our model's superiority in classification performance and efficiency for node classification tasks compared to existing baselines.
Learning to Act from Actionless Videos through Dense Correspondences
Oct 12, 2023In this work, we present an approach to construct a video-based robot policy capable of reliably executing diverse tasks across different robots and environments from few video demonstrations without using any action annotations. Our method leverages images as a task-agnostic representation, encoding both the state and action information, and text as a general representation for specifying robot goals. By synthesizing videos that ``hallucinate'' robot executing actions and in combination with dense correspondences between frames, our approach can infer the closed-formed action to execute to an environment without the need of any explicit action labels. This unique capability allows us to train the policy solely based on RGB videos and deploy learned policies to various robotic tasks. We demonstrate the efficacy of our approach in learning policies on table-top manipulation and navigation tasks. Additionally, we contribute an open-source framework for efficient video modeling, enabling the training of high-fidelity policy models with four GPUs within a single day.
Extraction of Medication and Temporal Relation from Clinical Text by Harnessing Different Deep Learning Models
Oct 03, 2023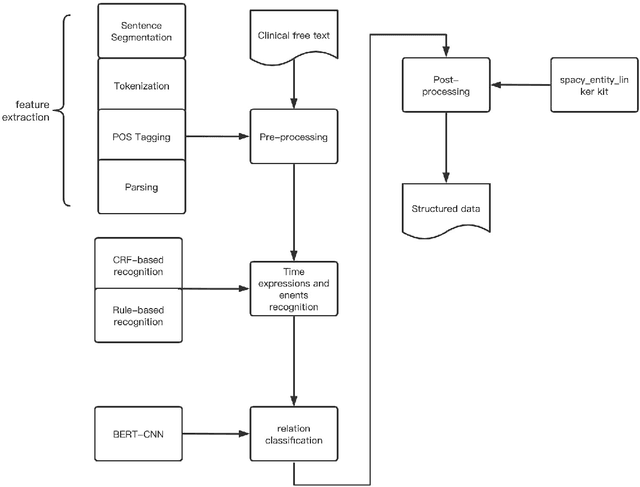
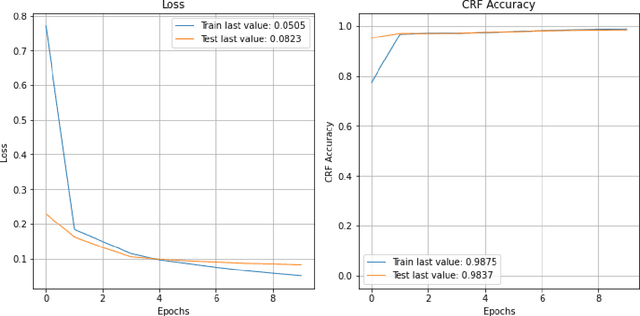
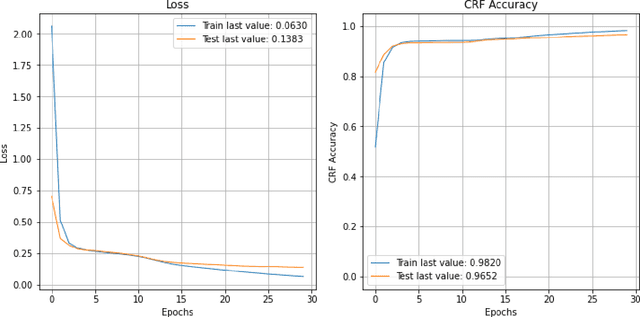
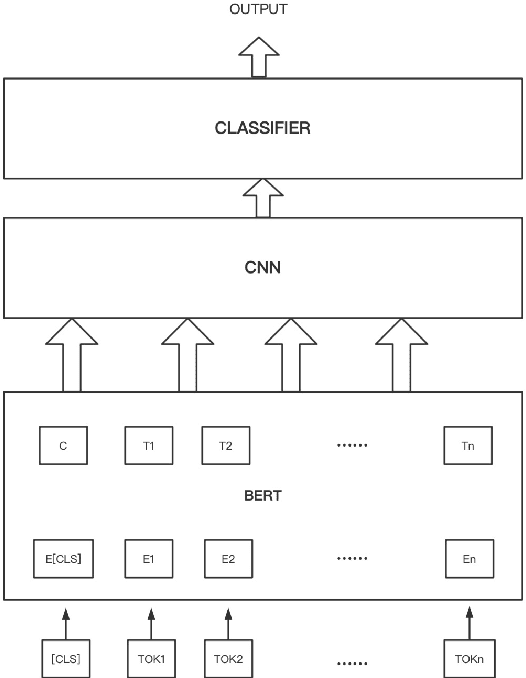
Clinical texts, represented in electronic medical records (EMRs), contain rich medical information and are essential for disease prediction, personalised information recommendation, clinical decision support, and medication pattern mining and measurement. Relation extractions between medication mentions and temporal information can further help clinicians better understand the patients' treatment history. To evaluate the performances of deep learning (DL) and large language models (LLMs) in medication extraction and temporal relations classification, we carry out an empirical investigation of \textbf{MedTem} project using several advanced learning structures including BiLSTM-CRF and CNN-BiLSTM for a clinical domain named entity recognition (NER), and BERT-CNN for temporal relation extraction (RE), in addition to the exploration of different word embedding techniques. Furthermore, we also designed a set of post-processing roles to generate structured output on medications and the temporal relation. Our experiments show that CNN-BiLSTM slightly wins the BiLSTM-CRF model on the i2b2-2009 clinical NER task yielding 75.67, 77.83, and 78.17 for precision, recall, and F1 scores using Macro Average. BERT-CNN model also produced reasonable evaluation scores 64.48, 67.17, and 65.03 for P/R/F1 using Macro Avg on the temporal relation extraction test set from i2b2-2012 challenges. Code and Tools from MedTem will be hosted at \url{https://github.com/HECTA-UoM/MedTem}