 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Locality-Aware Generalizable Implicit Neural Representation}
Oct 09, 2023
Generalizable implicit neural representation (INR) enables a single continuous function, i.e., a coordinate-based neural network, to represent multiple data instances by modulating its weights or intermediate features using latent codes. However, the expressive power of the state-of-the-art modulation is limited due to its inability to localize and capture fine-grained details of data entities such as specific pixels and rays. To address this issue, we propose a novel framework for generalizable INR that combines a transformer encoder with a locality-aware INR decoder. The transformer encoder predicts a set of latent tokens from a data instance to encode local information into each latent token. The locality-aware INR decoder extracts a modulation vector by selectively aggregating the latent tokens via cross-attention for a coordinate input and then predicts the output by progressively decoding with coarse-to-fine modulation through multiple frequency bandwidths. The selective token aggregation and the multi-band feature modulation enable us to learn locality-aware representation in spatial and spectral aspects, respectively. Our framework significantly outperforms previous generalizable INRs and validates the usefulness of the locality-aware latents for downstream tasks such as image generation.
Collaborative Visual Place Recognition
Oct 09, 2023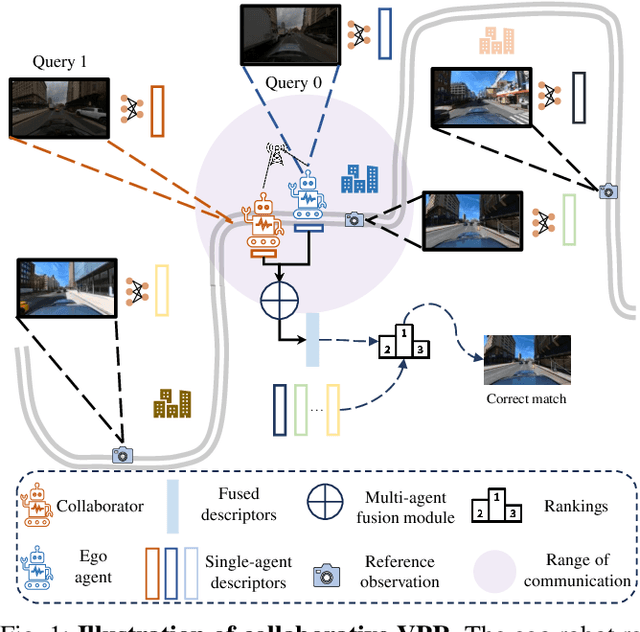
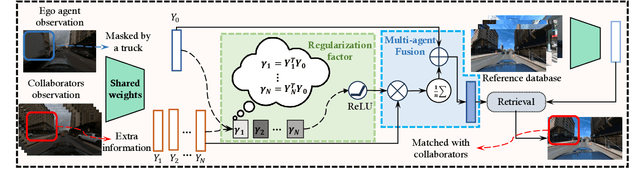
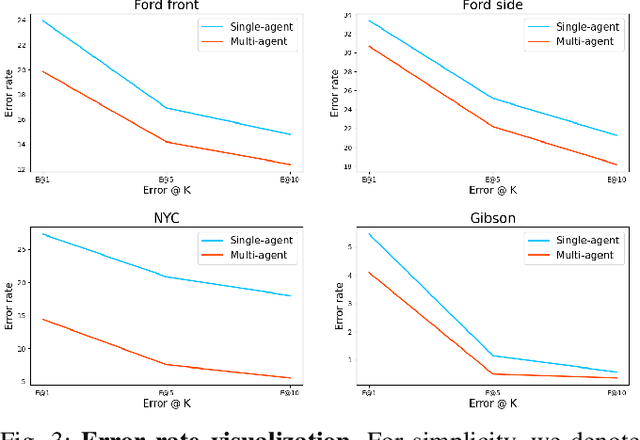

Visual place recognition (VPR) capabilities enable autonomous robots to navigate complex environments by discovering the environment's topology based on visual input. Most research efforts focus on enhancing the accuracy and robustness of single-robot VPR but often encounter issues such as occlusion due to individual viewpoints. Despite a number of research on multi-robot metric-based localization, there is a notable gap in research concerning more robust and efficient place-based localization with a multi-robot system. This work proposes collaborative VPR, where multiple robots share abstracted visual features to enhance place recognition capabilities. We also introduce a novel collaborative VPR framework based on similarity-regularized information fusion, reducing irrelevant noise while harnessing valuable data from collaborators. This framework seamlessly integrates with well-established single-robot VPR techniques and supports end-to-end training with a weakly-supervised contrastive loss. We conduct experiments in urban, rural, and indoor scenes, achieving a notable improvement over single-agent VPR in urban environments (~12\%), along with consistent enhancements in rural (~3\%) and indoor (~1\%) scenarios. Our work presents a promising solution to the pressing challenges of VPR, representing a substantial step towards safe and robust autonomous systems.
NetTiSA: Extended IP Flow with Time-series Features for Universal Bandwidth-constrained High-speed Network Traffic Classification
Oct 09, 2023Network traffic monitoring based on IP Flows is a standard monitoring approach that can be deployed to various network infrastructures, even the large IPS-based networks connecting millions of people. Since flow records traditionally contain only limited information (addresses, transport ports, and amount of exchanged data), they are also commonly extended for additional features that enable network traffic analysis with high accuracy. Nevertheless, the flow extensions are often too large or hard to compute, which limits their deployment only to smaller-sized networks. This paper proposes a novel extended IP flow called NetTiSA (Network Time Series Analysed), which is based on the analysis of the time series of packet sizes. By thoroughly testing 25 different network classification tasks, we show the broad applicability and high usability of NetTiSA, which often outperforms the best-performing related works. For practical deployment, we also consider the sizes of flows extended for NetTiSA and evaluate the performance impacts of its computation in the flow exporter. The novel feature set proved universal and deployable to high-speed ISP networks with 100\,Gbps lines; thus, it enables accurate and widespread network security protection.
Factorized Tensor Networks for Multi-Task and Multi-Domain Learning
Oct 09, 2023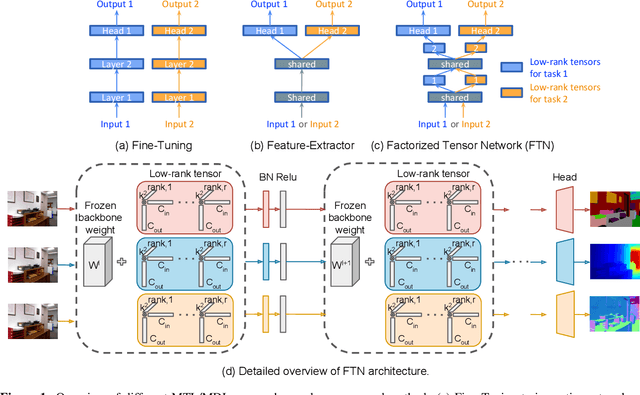
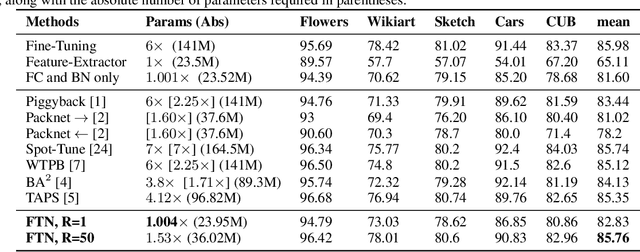
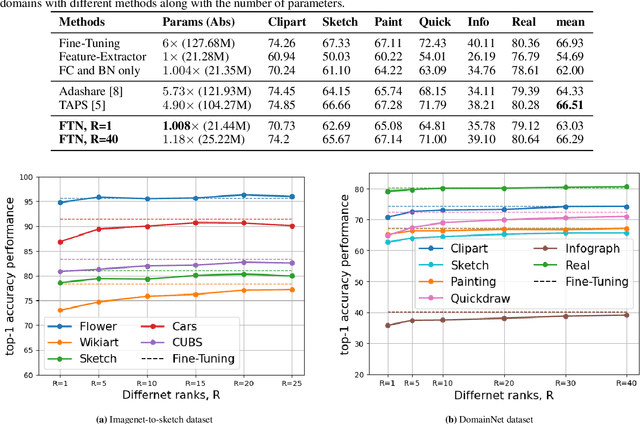
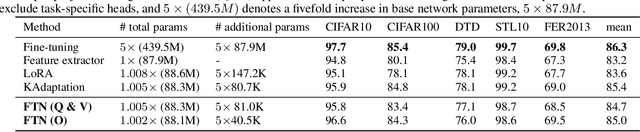
Multi-task and multi-domain learning methods seek to learn multiple tasks/domains, jointly or one after another, using a single unified network. The key challenge and opportunity is to exploit shared information across tasks and domains to improve the efficiency of the unified network. The efficiency can be in terms of accuracy, storage cost, computation, or sample complexity. In this paper, we propose a factorized tensor network (FTN) that can achieve accuracy comparable to independent single-task/domain networks with a small number of additional parameters. FTN uses a frozen backbone network from a source model and incrementally adds task/domain-specific low-rank tensor factors to the shared frozen network. This approach can adapt to a large number of target domains and tasks without catastrophic forgetting. Furthermore, FTN requires a significantly smaller number of task-specific parameters compared to existing methods. We performed experiments on widely used multi-domain and multi-task datasets. We show the experiments on convolutional-based architecture with different backbones and on transformer-based architecture. We observed that FTN achieves similar accuracy as single-task/domain methods while using only a fraction of additional parameters per task.
Longitudinal Volumetric Study for the Progression of Alzheimer's Disease from Structural MR Images
Oct 09, 2023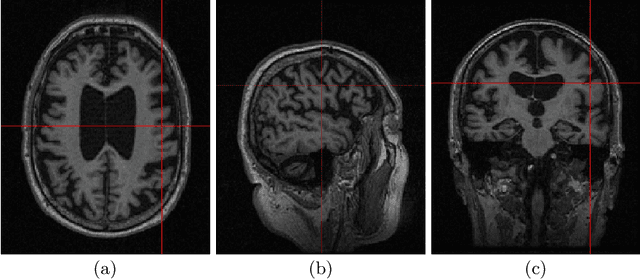

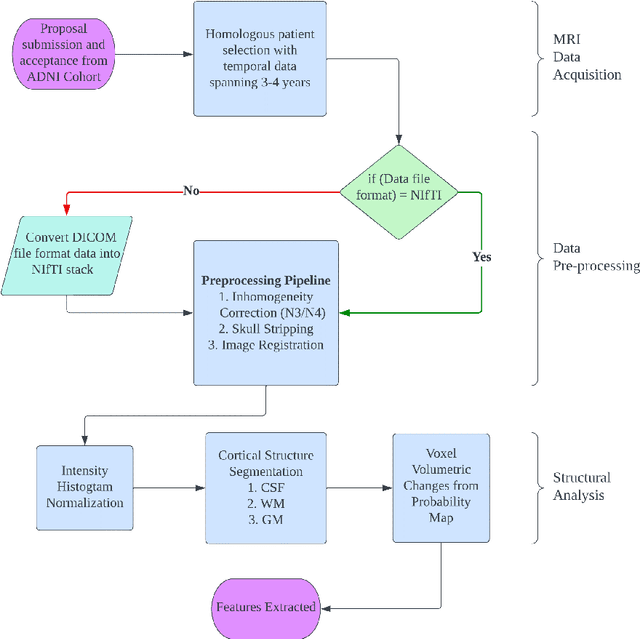
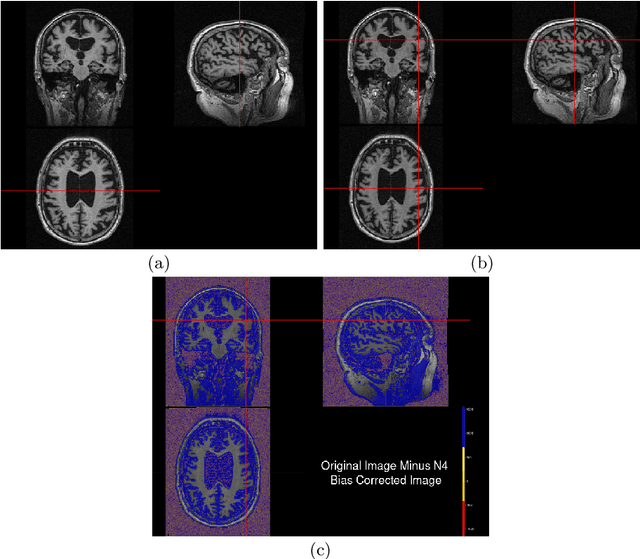
Alzheimer's Disease (AD) is primarily an irreversible neurodegenerative disorder affecting millions of individuals today. The prognosis of the disease solely depends on treating symptoms as they arise and proper caregiving, as there are no current medical preventative treatments. For this purpose, early detection of the disease at its most premature state is of paramount importance. This work aims to survey imaging biomarkers corresponding to the progression of Alzheimer's Disease (AD). A longitudinal study of structural MR images was performed for given temporal test subjects selected randomly from the Alzheimer's Disease Neuroimaging Initiative (ADNI) database. The pipeline implemented includes modern pre-processing techniques such as spatial image registration, skull stripping, and inhomogeneity correction. The temporal data across multiple visits spanning several years helped identify the structural change in the form of volumes of cerebrospinal fluid (CSF), grey matter (GM), and white matter (WM) as the patients progressed further into the disease. Tissue classes are segmented using an unsupervised learning approach using intensity histogram information. The segmented features thus extracted provide insights such as atrophy, increase or intolerable shifting of GM, WM and CSF and should help in future research for automated analysis of Alzheimer's detection with clinical domain explainability.
Uncertainty Quantification in Inverse Models in Hydrology
Oct 03, 2023In hydrology, modeling streamflow remains a challenging task due to the limited availability of basin characteristics information such as soil geology and geomorphology. These characteristics may be noisy due to measurement errors or may be missing altogether. To overcome this challenge, we propose a knowledge-guided, probabilistic inverse modeling method for recovering physical characteristics from streamflow and weather data, which are more readily available. We compare our framework with state-of-the-art inverse models for estimating river basin characteristics. We also show that these estimates offer improvement in streamflow modeling as opposed to using the original basin characteristic values. Our inverse model offers 3\% improvement in R$^2$ for the inverse model (basin characteristic estimation) and 6\% for the forward model (streamflow prediction). Our framework also offers improved explainability since it can quantify uncertainty in both the inverse and the forward model. Uncertainty quantification plays a pivotal role in improving the explainability of machine learning models by providing additional insights into the reliability and limitations of model predictions. In our analysis, we assess the quality of the uncertainty estimates. Compared to baseline uncertainty quantification methods, our framework offers 10\% improvement in the dispersion of epistemic uncertainty and 13\% improvement in coverage rate. This information can help stakeholders understand the level of uncertainty associated with the predictions and provide a more comprehensive view of the potential outcomes.
A Deep Reinforcement Learning Approach for Interactive Search with Sentence-level Feedback
Oct 03, 2023Interactive search can provide a better experience by incorporating interaction feedback from the users. This can significantly improve search accuracy as it helps avoid irrelevant information and captures the users' search intents. Existing state-of-the-art (SOTA) systems use reinforcement learning (RL) models to incorporate the interactions but focus on item-level feedback, ignoring the fine-grained information found in sentence-level feedback. Yet such feedback requires extensive RL action space exploration and large amounts of annotated data. This work addresses these challenges by proposing a new deep Q-learning (DQ) approach, DQrank. DQrank adapts BERT-based models, the SOTA in natural language processing, to select crucial sentences based on users' engagement and rank the items to obtain more satisfactory responses. We also propose two mechanisms to better explore optimal actions. DQrank further utilizes the experience replay mechanism in DQ to store the feedback sentences to obtain a better initial ranking performance. We validate the effectiveness of DQrank on three search datasets. The results show that DQRank performs at least 12% better than the previous SOTA RL approaches. We also conduct detailed ablation studies. The ablation results demonstrate that each model component can efficiently extract and accumulate long-term engagement effects from the users' sentence-level feedback. This structure offers new technologies with promised performance to construct a search system with sentence-level interaction.
Federated Deep Multi-View Clustering with Global Self-Supervision
Sep 24, 2023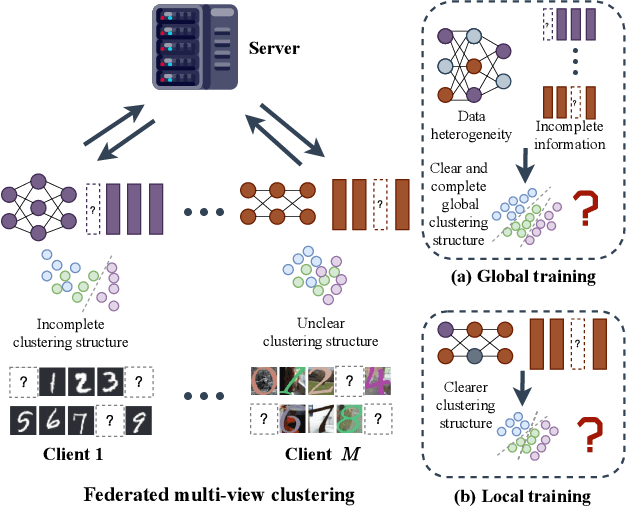
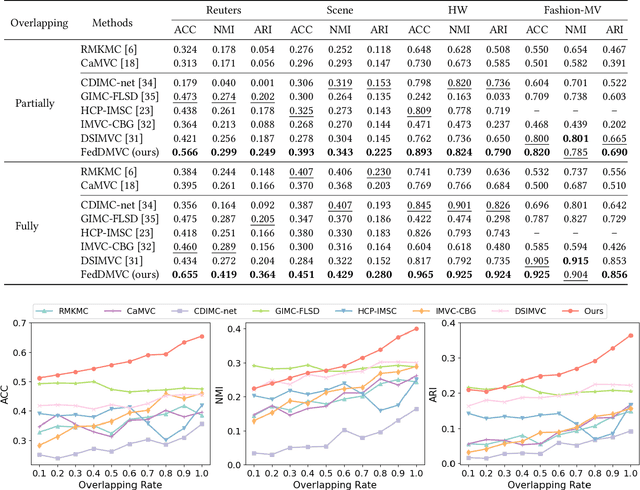
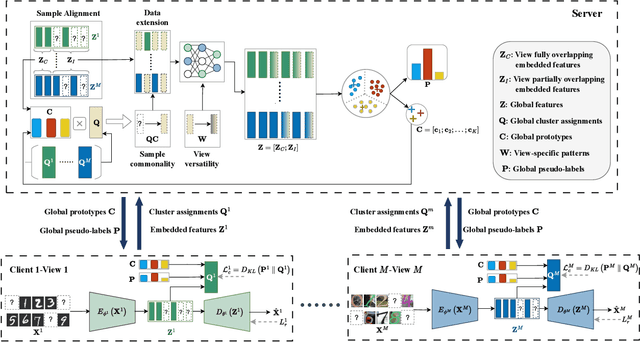

Federated multi-view clustering has the potential to learn a global clustering model from data distributed across multiple devices. In this setting, label information is unknown and data privacy must be preserved, leading to two major challenges. First, views on different clients often have feature heterogeneity, and mining their complementary cluster information is not trivial. Second, the storage and usage of data from multiple clients in a distributed environment can lead to incompleteness of multi-view data. To address these challenges, we propose a novel federated deep multi-view clustering method that can mine complementary cluster structures from multiple clients, while dealing with data incompleteness and privacy concerns. Specifically, in the server environment, we propose sample alignment and data extension techniques to explore the complementary cluster structures of multiple views. The server then distributes global prototypes and global pseudo-labels to each client as global self-supervised information. In the client environment, multiple clients use the global self-supervised information and deep autoencoders to learn view-specific cluster assignments and embedded features, which are then uploaded to the server for refining the global self-supervised information. Finally, the results of our extensive experiments demonstrate that our proposed method exhibits superior performance in addressing the challenges of incomplete multi-view data in distributed environments.
An IRS-Assisted Secure Dual-Function Radar-Communication System
Oct 01, 2023In dual-function radar-communication (DFRC) systems the probing signal contains information intended for the communication users, which makes that information vulnerable to eavesdropping by the targets. We propose a novel design for enhancing the physical layer security (PLS) of DFRC systems, via the help of intelligent reflecting surface (IRS) and artificial noise (AN), transmitted along with the probing waveform. The radar waveform, the AN jamming noise and the IRS parameters are designed to optimize the communication secrecy rate while meeting radar signal-to-noise ratio (SNR) constrains. Key challenges in the resulting optimization problem include the fractional form objective, the SNR being a quartic function of the IRS parameters, and the unit-modulus constraint of the IRS parameters. A fractional programming technique is used to transform the fractional form objective of the optimization problem into more tractable non-fractional polynomials. Numerical results are provided to demonstrate the convergence of the proposed system design algorithm, and also show the impact of the power assigned to the AN on the secrecy performance of the designed system.
Generative Autoencoding of Dropout Patterns
Oct 03, 2023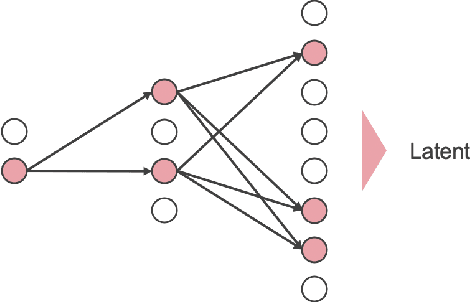

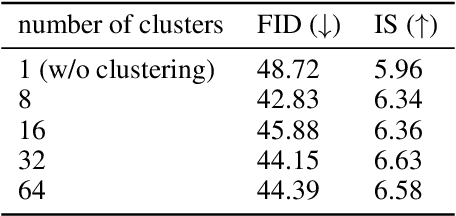
We propose a generative model termed Deciphering Autoencoders. In this model, we assign a unique random dropout pattern to each data point in the training dataset and then train an autoencoder to reconstruct the corresponding data point using this pattern as information to be encoded. Since the training of Deciphering Autoencoders relies solely on reconstruction error, it offers more stable training than other generative models. Despite its simplicity, Deciphering Autoencoders show comparable sampling quality to DCGAN on the CIFAR-10 dataset.