 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Distance-based Weighted Transformer Network for Image Completion
Oct 11, 2023
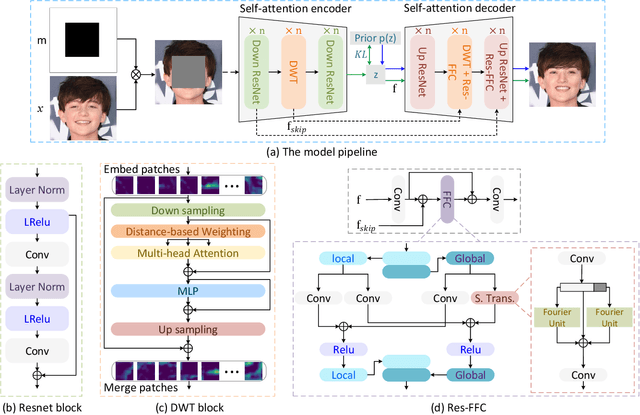
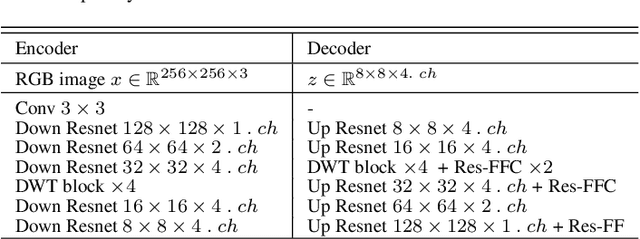

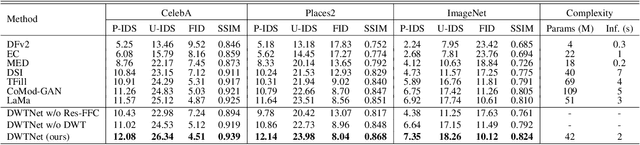
The challenge of image generation has been effectively modeled as a problem of structure priors or transformation. However, existing models have unsatisfactory performance in understanding the global input image structures because of particular inherent features (for example, local inductive prior). Recent studies have shown that self-attention is an efficient modeling technique for image completion problems. In this paper, we propose a new architecture that relies on Distance-based Weighted Transformer (DWT) to better understand the relationships between an image's components. In our model, we leverage the strengths of both Convolutional Neural Networks (CNNs) and DWT blocks to enhance the image completion process. Specifically, CNNs are used to augment the local texture information of coarse priors and DWT blocks are used to recover certain coarse textures and coherent visual structures. Unlike current approaches that generally use CNNs to create feature maps, we use the DWT to encode global dependencies and compute distance-based weighted feature maps, which substantially minimizes the problem of visual ambiguities. Meanwhile, to better produce repeated textures, we introduce Residual Fast Fourier Convolution (Res-FFC) blocks to combine the encoder's skip features with the coarse features provided by our generator. Furthermore, a simple yet effective technique is proposed to normalize the non-zero values of convolutions, and fine-tune the network layers for regularization of the gradient norms to provide an efficient training stabiliser. Extensive quantitative and qualitative experiments on three challenging datasets demonstrate the superiority of our proposed model compared to existing approaches.
Denoising Task Routing for Diffusion Models
Oct 11, 2023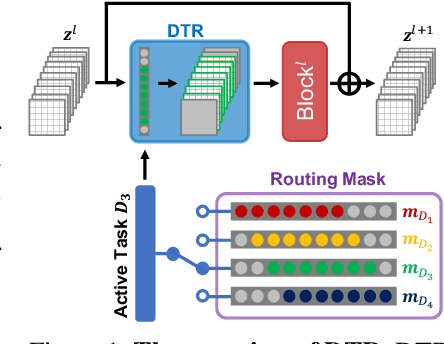

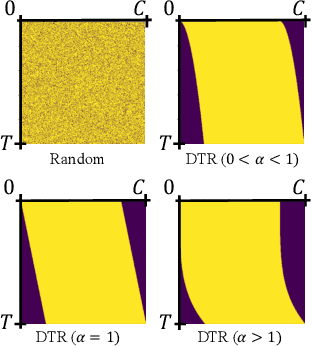
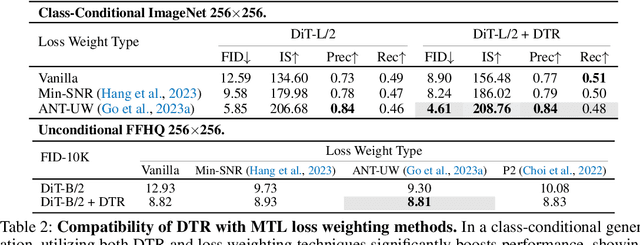
Diffusion models generate highly realistic images through learning a multi-step denoising process, naturally embodying the principles of multi-task learning (MTL). Despite the inherent connection between diffusion models and MTL, there remains an unexplored area in designing neural architectures that explicitly incorporate MTL into the framework of diffusion models. In this paper, we present Denoising Task Routing (DTR), a simple add-on strategy for existing diffusion model architectures to establish distinct information pathways for individual tasks within a single architecture by selectively activating subsets of channels in the model. What makes DTR particularly compelling is its seamless integration of prior knowledge of denoising tasks into the framework: (1) Task Affinity: DTR activates similar channels for tasks at adjacent timesteps and shifts activated channels as sliding windows through timesteps, capitalizing on the inherent strong affinity between tasks at adjacent timesteps. (2) Task Weights: During the early stages (higher timesteps) of the denoising process, DTR assigns a greater number of task-specific channels, leveraging the insight that diffusion models prioritize reconstructing global structure and perceptually rich contents in earlier stages, and focus on simple noise removal in later stages. Our experiments demonstrate that DTR consistently enhances the performance of diffusion models across various evaluation protocols, all without introducing additional parameters. Furthermore, DTR contributes to accelerating convergence during training. Finally, we show the complementarity between our architectural approach and existing MTL optimization techniques, providing a more complete view of MTL within the context of diffusion training.
NeuroInspect: Interpretable Neuron-based Debugging Framework through Class-conditional Visualizations
Oct 11, 2023Despite deep learning (DL) has achieved remarkable progress in various domains, the DL models are still prone to making mistakes. This issue necessitates effective debugging tools for DL practitioners to interpret the decision-making process within the networks. However, existing debugging methods often demand extra data or adjustments to the decision process, limiting their applicability. To tackle this problem, we present NeuroInspect, an interpretable neuron-based debugging framework with three key stages: counterfactual explanations, feature visualizations, and false correlation mitigation. Our debugging framework first pinpoints neurons responsible for mistakes in the network and then visualizes features embedded in the neurons to be human-interpretable. To provide these explanations, we introduce CLIP-Illusion, a novel feature visualization method that generates images representing features conditioned on classes to examine the connection between neurons and the decision layer. We alleviate convoluted explanations of the conventional visualization approach by employing class information, thereby isolating mixed properties. This process offers more human-interpretable explanations for model errors without altering the trained network or requiring additional data. Furthermore, our framework mitigates false correlations learned from a dataset under a stochastic perspective, modifying decisions for the neurons considered as the main causes. We validate the effectiveness of our framework by addressing false correlations and improving inferences for classes with the worst performance in real-world settings. Moreover, we demonstrate that NeuroInspect helps debug the mistakes of DL models through evaluation for human understanding. The code is openly available at https://github.com/yeongjoonJu/NeuroInspect.
Concise and Organized Perception Facilitates Large Language Models for Deductive Reasoning
Oct 05, 2023Exploiting large language models (LLMs) to tackle deductive reasoning has garnered growing attention. It still remains highly challenging to achieve satisfactory results in complex deductive problems, characterized by plenty of premises (i.e., facts or rules) entailing intricate relationships among entities and requiring multi-hop reasoning. One intuitive solution is to decompose the original task into smaller sub-tasks, and then chain the multiple casual reasoning steps together in a forward (e.g., Selection-Inference) or backward (e.g., LAMBADA) direction. However, these techniques inevitably necessitate a large number of overall stages, leading to computationally expensive operations and a higher possibility of making misleading steps. In addition to stage-by-stage decomposition, we draw inspiration from another aspect of human problem-solving. Humans tend to distill the most relevant information and organize their thoughts systematically (e.g., creating mind maps), which assists them in answering questions or drawing conclusions precisely and quickly. In light of this, we propose a novel reasoning approach named Concise and Organized Perception (COP). COP carefully analyzes the given statements to efficiently identify the most pertinent information while eliminating redundancy. It then prompts the LLMs in a more organized form that adapts to the model's inference process. By perceiving concise and organized proofs, the deductive reasoning abilities of LLMs can be better elicited, and the risk of acquiring errors caused by excessive reasoning stages is mitigated. Furthermore, our approach can be combined with the aforementioned ones to further boost their performance. Extensive experimental results on three popular deductive benchmarks (i.e., ProofWriter, PrOntoQA and PrOntoQA-OOD) show that COP significantly outperforms previous state-of-the-art methods.
Matrix Completion from One-Bit Dither Samples
Oct 05, 2023We explore the impact of coarse quantization on matrix completion in the extreme scenario of dithered one-bit sensing, where the matrix entries are compared with time-varying threshold levels. In particular, instead of observing a subset of high-resolution entries of a low-rank matrix, we have access to a small number of one-bit samples, generated as a result of these comparisons. In order to recover the low-rank matrix using its coarsely quantized known entries, we begin by transforming the problem of one-bit matrix completion (one-bit MC) with time-varying thresholds into a nuclear norm minimization problem. The one-bit sampled information is represented as linear inequality feasibility constraints. We then develop the popular singular value thresholding (SVT) algorithm to accommodate these inequality constraints, resulting in the creation of the One-Bit SVT (OB-SVT). Our findings demonstrate that incorporating multiple time-varying sampling threshold sequences in one-bit MC can significantly improve the performance of the matrix completion algorithm. In pursuit of achieving this objective, we utilize diverse thresholding schemes, namely uniform, Gaussian, and discrete thresholds. To accelerate the convergence of our proposed algorithm, we introduce three variants of the OB-SVT algorithm. Among these variants is the randomized sketched OB-SVT, which departs from using the entire information at each iteration, opting instead to utilize sketched data. This approach effectively reduces the dimension of the operational space and accelerates the convergence. We perform numerical evaluations comparing our proposed algorithm with the maximum likelihood estimation method previously employed for one-bit MC, and demonstrate that our approach can achieve a better recovery performance.
PASTA: PArallel Spatio-Temporal Attention with spatial auto-correlation gating for fine-grained crowd flow prediction
Oct 02, 2023Understanding the movement patterns of objects (e.g., humans and vehicles) in a city is essential for many applications, including city planning and management. This paper proposes a method for predicting future city-wide crowd flows by modeling the spatio-temporal patterns of historical crowd flows in fine-grained city-wide maps. We introduce a novel neural network named PArallel Spatio-Temporal Attention with spatial auto-correlation gating (PASTA) that effectively captures the irregular spatio-temporal patterns of fine-grained maps. The novel components in our approach include spatial auto-correlation gating, multi-scale residual block, and temporal attention gating module. The spatial auto-correlation gating employs the concept of spatial statistics to identify irregular spatial regions. The multi-scale residual block is responsible for handling multiple range spatial dependencies in the fine-grained map, and the temporal attention gating filters out irrelevant temporal information for the prediction. The experimental results demonstrate that our model outperforms other competing baselines, especially under challenging conditions that contain irregular spatial regions. We also provide a qualitative analysis to derive the critical time information where our model assigns high attention scores in prediction.
Efficient Predictive Coding of Intra Prediction Modes
Oct 09, 2023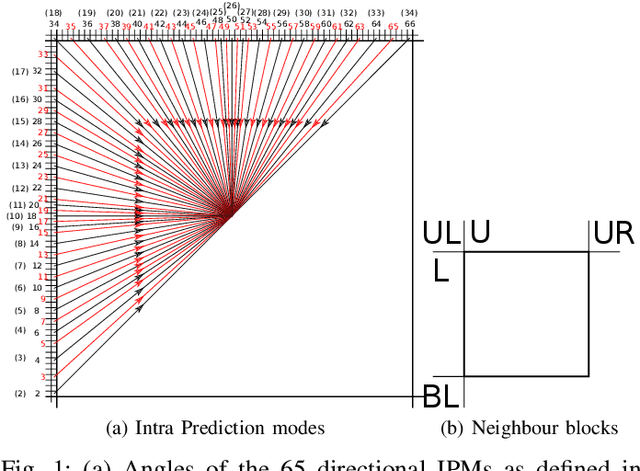
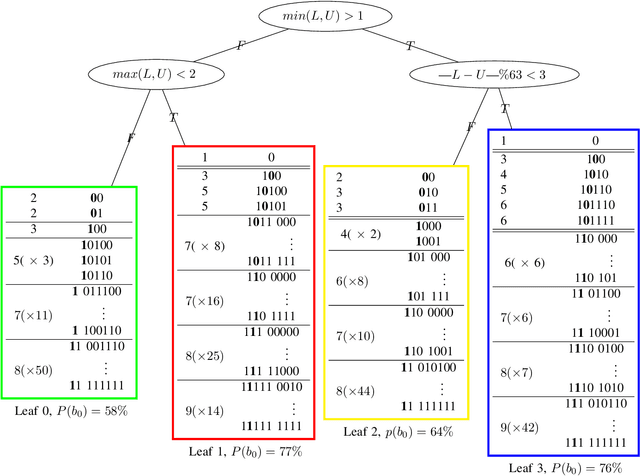
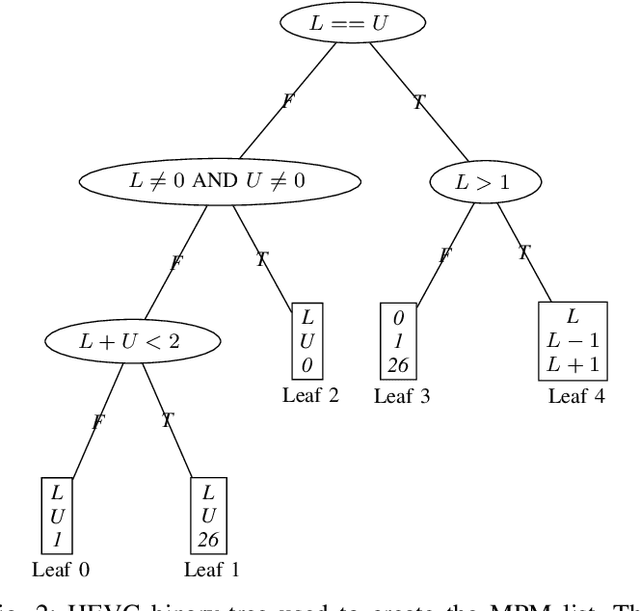
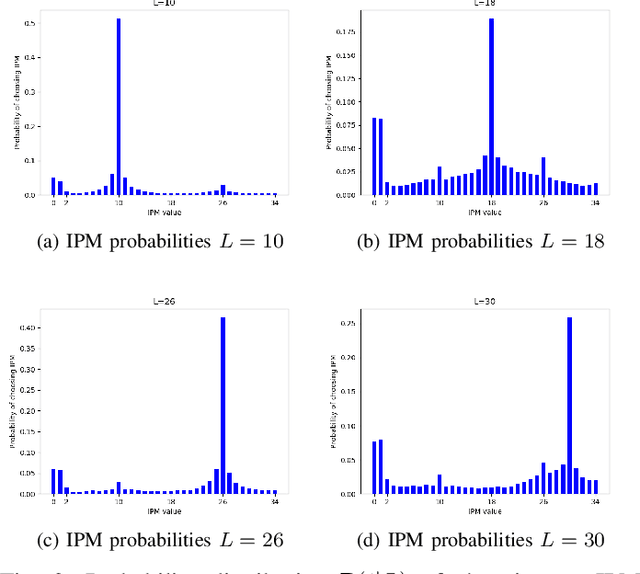
The high efficiency video coding (HEVC) standard and the joint exploration model (JEM) codec incorporate 35 and 67 intra prediction modes (IPMs) respectively, which are essential for efficient compression of Intra coded blocks. These IPMs are transmitted to the decoder through a coding scheme. In our paper, we present an innovative approach to construct a dedicated coding scheme for IPM based on contextual information. This approach comprises three key steps: prediction, clustering, and coding, each of which has been enhanced by introducing new elements, namely, labels for prediction, tests for clustering, and codes for coding. In this context, we have proposed a method that utilizes a genetic algorithm to minimize the rate cost, aiming to derive the most efficient coding scheme while leveraging the available labels, tests, and codes. The resulting coding scheme, expressed as a binary tree, achieves the highest coding efficiency for a given level of complexity. In our experimental evaluation under the HEVC standard, we observed significant bitrate gains while maintaining coding efficiency under the JEM codec. These results demonstrate the potential of our approach to improve compression efficiency, particularly under the HEVC standard, while preserving the coding efficiency of the JEM codec.
Longitudinal Volumetric Study for the Progression of Alzheimer's Disease from Structural MR Images
Oct 09, 2023

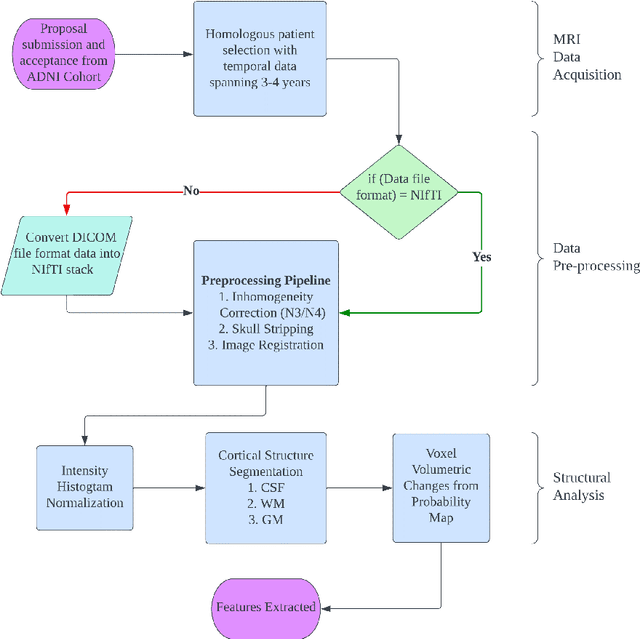
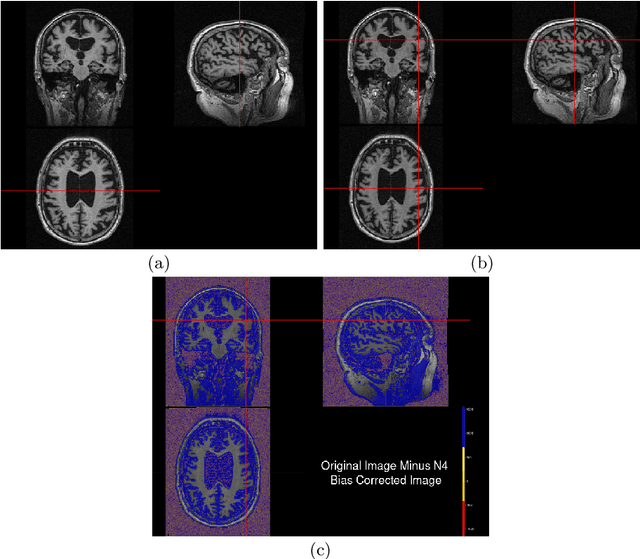
Alzheimer's Disease (AD) is primarily an irreversible neurodegenerative disorder affecting millions of individuals today. The prognosis of the disease solely depends on treating symptoms as they arise and proper caregiving, as there are no current medical preventative treatments. For this purpose, early detection of the disease at its most premature state is of paramount importance. This work aims to survey imaging biomarkers corresponding to the progression of Alzheimer's Disease (AD). A longitudinal study of structural MR images was performed for given temporal test subjects selected randomly from the Alzheimer's Disease Neuroimaging Initiative (ADNI) database. The pipeline implemented includes modern pre-processing techniques such as spatial image registration, skull stripping, and inhomogeneity correction. The temporal data across multiple visits spanning several years helped identify the structural change in the form of volumes of cerebrospinal fluid (CSF), grey matter (GM), and white matter (WM) as the patients progressed further into the disease. Tissue classes are segmented using an unsupervised learning approach using intensity histogram information. The segmented features thus extracted provide insights such as atrophy, increase or intolerable shifting of GM, WM and CSF and should help in future research for automated analysis of Alzheimer's detection with clinical domain explainability.
Factorized Tensor Networks for Multi-Task and Multi-Domain Learning
Oct 09, 2023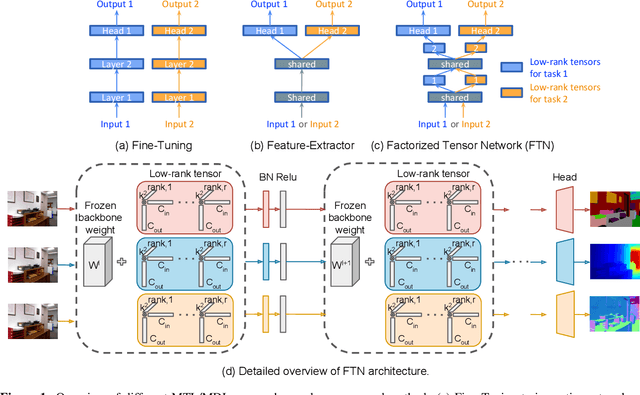
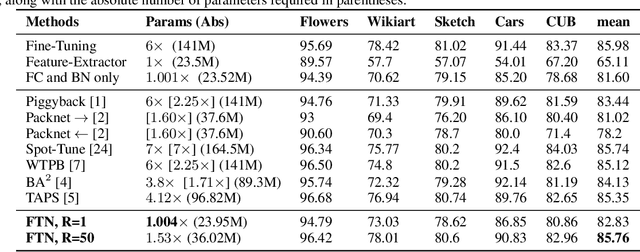
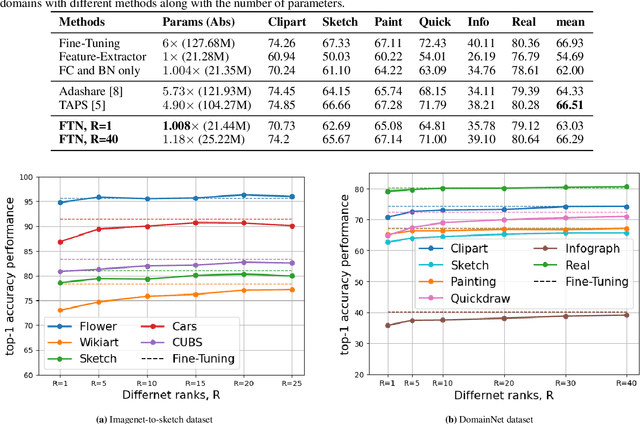
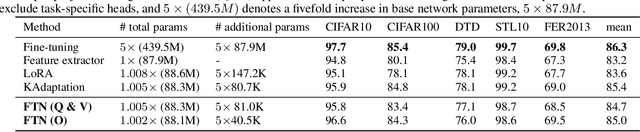
Multi-task and multi-domain learning methods seek to learn multiple tasks/domains, jointly or one after another, using a single unified network. The key challenge and opportunity is to exploit shared information across tasks and domains to improve the efficiency of the unified network. The efficiency can be in terms of accuracy, storage cost, computation, or sample complexity. In this paper, we propose a factorized tensor network (FTN) that can achieve accuracy comparable to independent single-task/domain networks with a small number of additional parameters. FTN uses a frozen backbone network from a source model and incrementally adds task/domain-specific low-rank tensor factors to the shared frozen network. This approach can adapt to a large number of target domains and tasks without catastrophic forgetting. Furthermore, FTN requires a significantly smaller number of task-specific parameters compared to existing methods. We performed experiments on widely used multi-domain and multi-task datasets. We show the experiments on convolutional-based architecture with different backbones and on transformer-based architecture. We observed that FTN achieves similar accuracy as single-task/domain methods while using only a fraction of additional parameters per task.
Locality-Aware Generalizable Implicit Neural Representation}
Oct 09, 2023Generalizable implicit neural representation (INR) enables a single continuous function, i.e., a coordinate-based neural network, to represent multiple data instances by modulating its weights or intermediate features using latent codes. However, the expressive power of the state-of-the-art modulation is limited due to its inability to localize and capture fine-grained details of data entities such as specific pixels and rays. To address this issue, we propose a novel framework for generalizable INR that combines a transformer encoder with a locality-aware INR decoder. The transformer encoder predicts a set of latent tokens from a data instance to encode local information into each latent token. The locality-aware INR decoder extracts a modulation vector by selectively aggregating the latent tokens via cross-attention for a coordinate input and then predicts the output by progressively decoding with coarse-to-fine modulation through multiple frequency bandwidths. The selective token aggregation and the multi-band feature modulation enable us to learn locality-aware representation in spatial and spectral aspects, respectively. Our framework significantly outperforms previous generalizable INRs and validates the usefulness of the locality-aware latents for downstream tasks such as image generation.