 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
"Sorry, Come Again?" Prompting -- Enhancing Comprehension and Diminishing Hallucination with [PAUSE]-injected Optimal Paraphrasing
Mar 27, 2024
Hallucination has emerged as the most vulnerable aspect of contemporary Large Language Models (LLMs). In this paper, we introduce the Sorry, Come Again (SCA) prompting, aimed to avoid LLM hallucinations by enhancing comprehension through: (i) optimal paraphrasing and (ii) injecting [PAUSE] tokens to delay LLM generation. First, we provide an in-depth analysis of linguistic nuances: formality, readability, and concreteness of prompts for 21 LLMs, and elucidate how these nuances contribute to hallucinated generation. Prompts with lower readability, formality, or concreteness pose comprehension challenges for LLMs, similar to those faced by humans. In such scenarios, an LLM tends to speculate and generate content based on its imagination (associative memory) to fill these information gaps. Although these speculations may occasionally align with factual information, their accuracy is not assured, often resulting in hallucination. Recent studies reveal that an LLM often neglects the middle sections of extended prompts, a phenomenon termed as lost in the middle. While a specific paraphrase may suit one LLM, the same paraphrased version may elicit a different response from another LLM. Therefore, we propose an optimal paraphrasing technique to identify the most comprehensible paraphrase of a given prompt, evaluated using Integrated Gradient (and its variations) to guarantee that the LLM accurately processes all words. While reading lengthy sentences, humans often pause at various points to better comprehend the meaning read thus far. We have fine-tuned an LLM with injected [PAUSE] tokens, allowing the LLM to pause while reading lengthier prompts. This has brought several key contributions: (i) determining the optimal position to inject [PAUSE], (ii) determining the number of [PAUSE] tokens to be inserted, and (iii) introducing reverse proxy tuning to fine-tune the LLM for [PAUSE] insertion.
Invisible Gas Detection: An RGB-Thermal Cross Attention Network and A New Benchmark
Mar 26, 2024The widespread use of various chemical gases in industrial processes necessitates effective measures to prevent their leakage during transportation and storage, given their high toxicity. Thermal infrared-based computer vision detection techniques provide a straightforward approach to identify gas leakage areas. However, the development of high-quality algorithms has been challenging due to the low texture in thermal images and the lack of open-source datasets. In this paper, we present the RGB-Thermal Cross Attention Network (RT-CAN), which employs an RGB-assisted two-stream network architecture to integrate texture information from RGB images and gas area information from thermal images. Additionally, to facilitate the research of invisible gas detection, we introduce Gas-DB, an extensive open-source gas detection database including about 1.3K well-annotated RGB-thermal images with eight variant collection scenes. Experimental results demonstrate that our method successfully leverages the advantages of both modalities, achieving state-of-the-art (SOTA) performance among RGB-thermal methods, surpassing single-stream SOTA models in terms of accuracy, Intersection of Union (IoU), and F2 metrics by 4.86%, 5.65%, and 4.88%, respectively. The code and data will be made available soon.
Building Bridges across Spatial and Temporal Resolutions: Reference-Based Super-Resolution via Change Priors and Conditional Diffusion Model
Mar 26, 2024Reference-based super-resolution (RefSR) has the potential to build bridges across spatial and temporal resolutions of remote sensing images. However, existing RefSR methods are limited by the faithfulness of content reconstruction and the effectiveness of texture transfer in large scaling factors. Conditional diffusion models have opened up new opportunities for generating realistic high-resolution images, but effectively utilizing reference images within these models remains an area for further exploration. Furthermore, content fidelity is difficult to guarantee in areas without relevant reference information. To solve these issues, we propose a change-aware diffusion model named Ref-Diff for RefSR, using the land cover change priors to guide the denoising process explicitly. Specifically, we inject the priors into the denoising model to improve the utilization of reference information in unchanged areas and regulate the reconstruction of semantically relevant content in changed areas. With this powerful guidance, we decouple the semantics-guided denoising and reference texture-guided denoising processes to improve the model performance. Extensive experiments demonstrate the superior effectiveness and robustness of the proposed method compared with state-of-the-art RefSR methods in both quantitative and qualitative evaluations. The code and data are available at https://github.com/dongrunmin/RefDiff.
Uncertainty-Aware Deployment of Pre-trained Language-Conditioned Imitation Learning Policies
Mar 27, 2024Large-scale robotic policies trained on data from diverse tasks and robotic platforms hold great promise for enabling general-purpose robots; however, reliable generalization to new environment conditions remains a major challenge. Toward addressing this challenge, we propose a novel approach for uncertainty-aware deployment of pre-trained language-conditioned imitation learning agents. Specifically, we use temperature scaling to calibrate these models and exploit the calibrated model to make uncertainty-aware decisions by aggregating the local information of candidate actions. We implement our approach in simulation using three such pre-trained models, and showcase its potential to significantly enhance task completion rates. The accompanying code is accessible at the link: https://github.com/BobWu1998/uncertainty_quant_all.git
Resonant Beam Communications: A New Design Paradigm and Challenges
Mar 25, 2024Resonant beam communications (RBCom), which adopt oscillating photons between two separate retroreflectors for information transmission, exhibit potential advantages over other types of wireless optical communications (WOC). However, echo interference generated by the modulated beam reflected from the receiver affects the transmission of the desired information. To tackle this challenge, a synchronization-based point-to-point RBCom system is proposed to eliminate the echo interference, and the design for the transmitter and receiver is discussed. Subsequently, the performance of the proposed RBCom is evaluated and compared with that of visible light communications (VLC) and free space optical communications (FOC). Finally, future research directions are outlined and several implementation challenges of RBCom systems are highlighted.
Cross-lingual Contextualized Phrase Retrieval
Mar 25, 2024Phrase-level dense retrieval has shown many appealing characteristics in downstream NLP tasks by leveraging the fine-grained information that phrases offer. In our work, we propose a new task formulation of dense retrieval, cross-lingual contextualized phrase retrieval, which aims to augment cross-lingual applications by addressing polysemy using context information. However, the lack of specific training data and models are the primary challenges to achieve our goal. As a result, we extract pairs of cross-lingual phrases using word alignment information automatically induced from parallel sentences. Subsequently, we train our Cross-lingual Contextualized Phrase Retriever (CCPR) using contrastive learning, which encourages the hidden representations of phrases with similar contexts and semantics to align closely. Comprehensive experiments on both the cross-lingual phrase retrieval task and a downstream task, i.e, machine translation, demonstrate the effectiveness of CCPR. On the phrase retrieval task, CCPR surpasses baselines by a significant margin, achieving a top-1 accuracy that is at least 13 points higher. When utilizing CCPR to augment the large-language-model-based translator, it achieves average gains of 0.7 and 1.5 in BERTScore for translations from X=>En and vice versa, respectively, on WMT16 dataset. Our code and data are available at \url{https://github.com/ghrua/ccpr_release}.
Interpreting Key Mechanisms of Factual Recall in Transformer-Based Language Models
Mar 28, 2024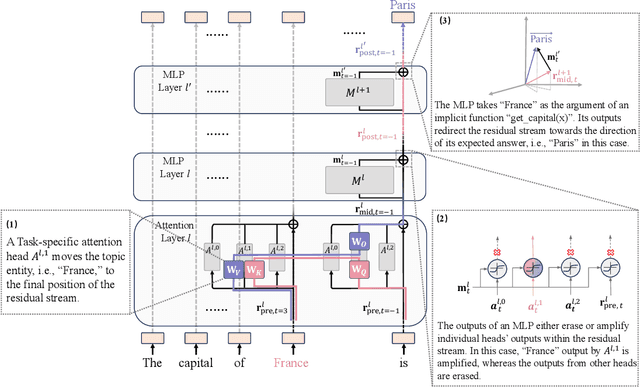

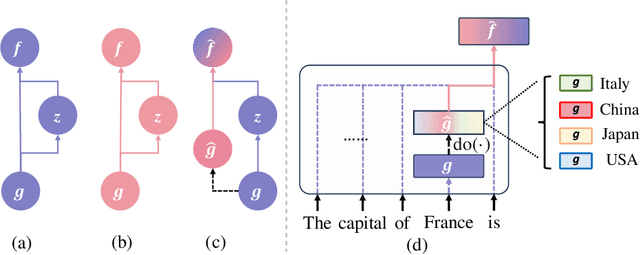

In this paper, we deeply explore the mechanisms employed by Transformer-based language models in factual recall tasks. In zero-shot scenarios, given a prompt like "The capital of France is," task-specific attention heads extract the topic entity, such as "France," from the context and pass it to subsequent MLPs to recall the required answer such as "Paris." We introduce a novel analysis method aimed at decomposing the outputs of the MLP into components understandable by humans. Through this method, we quantify the function of the MLP layer following these task-specific heads. In the residual stream, it either erases or amplifies the information originating from individual heads. Moreover, it generates a component that redirects the residual stream towards the direction of its expected answer. These zero-shot mechanisms are also employed in few-shot scenarios. Additionally, we observed a widely existent anti-overconfidence mechanism in the final layer of models, which suppresses correct predictions. We mitigate this suppression by leveraging our interpretation to improve factual recall performance. Our interpretations have been evaluated across various language models, from the GPT-2 families to 1.3B OPT, and across tasks covering different domains of factual knowledge.
DreamSalon: A Staged Diffusion Framework for Preserving Identity-Context in Editable Face Generation
Mar 28, 2024While large-scale pre-trained text-to-image models can synthesize diverse and high-quality human-centered images, novel challenges arise with a nuanced task of "identity fine editing": precisely modifying specific features of a subject while maintaining its inherent identity and context. Existing personalization methods either require time-consuming optimization or learning additional encoders, adept in "identity re-contextualization". However, they often struggle with detailed and sensitive tasks like human face editing. To address these challenges, we introduce DreamSalon, a noise-guided, staged-editing framework, uniquely focusing on detailed image manipulations and identity-context preservation. By discerning editing and boosting stages via the frequency and gradient of predicted noises, DreamSalon first performs detailed manipulations on specific features in the editing stage, guided by high-frequency information, and then employs stochastic denoising in the boosting stage to improve image quality. For more precise editing, DreamSalon semantically mixes source and target textual prompts, guided by differences in their embedding covariances, to direct the model's focus on specific manipulation areas. Our experiments demonstrate DreamSalon's ability to efficiently and faithfully edit fine details on human faces, outperforming existing methods both qualitatively and quantitatively.
Blind Identification of Binaural Room Impulse Responses from Smart Glasses
Mar 28, 2024Smart glasses are increasingly recognized as a key medium for augmented reality, offering a hands-free platform with integrated microphones and non-ear-occluding loudspeakers to seamlessly mix virtual sound sources into the real-world acoustic scene. To convincingly integrate virtual sound sources, the room acoustic rendering of the virtual sources must match the real-world acoustics. Information about a user's acoustic environment however is typically not available. This work uses a microphone array in a pair of smart glasses to blindly identify binaural room impulse responses (BRIRs) from a few seconds of speech in the real-world environment. The proposed method uses dereverberation and beamforming to generate a pseudo reference signal that is used by a multichannel Wiener filter to estimate room impulse responses which are then converted to BRIRs. The multichannel room impulse responses can be used to estimate room acoustic parameters which is shown to outperform baseline algorithms in the estimation of reverberation time and direct-to-reverberant energy ratio. Results from a listening experiment further indicate that the estimated BRIRs often reproduce the real-world room acoustics perceptually more convincingly than measured BRIRs from other rooms with similar geometry.
Active Learning of Dynamics Using Prior Domain Knowledge in the Sampling Process
Mar 25, 2024We present an active learning algorithm for learning dynamics that leverages side information by explicitly incorporating prior domain knowledge into the sampling process. Our proposed algorithm guides the exploration toward regions that demonstrate high empirical discrepancy between the observed data and an imperfect prior model of the dynamics derived from side information. Through numerical experiments, we demonstrate that this strategy explores regions of high discrepancy and accelerates learning while simultaneously reducing model uncertainty. We rigorously prove that our active learning algorithm yields a consistent estimate of the underlying dynamics by providing an explicit rate of convergence for the maximum predictive variance. We demonstrate the efficacy of our approach on an under-actuated pendulum system and on the half-cheetah MuJoCo environment.