 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Slip Detection and Surface Prediction Through Bio-Inspired Tactile Feedback
Oct 12, 2023
High resolution tactile sensing has great potential in autonomous mobile robotics, particularly for legged robots. One particular area where it has significant promise is the traversal of challenging, varied terrain. Depending on whether an environment is slippery, soft, hard or dry, a robot must adapt its method of locomotion accordingly. Currently many multi-legged robots, such as Boston Dynamic's Spot robot, have preset gaits for different surface types, but struggle over terrains where the surface type changes frequently. Being able to automatically detect changes within an environment would allow a robot to autonomously adjust its method of locomotion to better suit conditions, without requiring a human user to manually set the change in surface type. In this paper we report on the first detailed investigation of the properties of a particular bio-inspired tactile sensor, the TacTip, to test its suitability for this kind of automatic detection of surface conditions. We explored different processing techniques and a regression model, using a custom made rig for data collection to determine how a robot could sense directional and general force on the sensor in a variety of conditions. This allowed us to successfully demonstrate how the sensor can be used to distinguish between soft, hard, dry and (wet) slippery surfaces. We further explored a neural model to classify specific surface textures. Pin movement (the movement of optical markers within the sensor) was key to sensing this information, and all models relied on some form of temporal information. Our final trained models could successfully determine the direction the sensor is heading in, the amount of force acting on it, and determine differences in the surface texture such as Lego vs smooth hard surface, or concrete vs smooth hard surface.
QASiNa: Religious Domain Question Answering using Sirah Nabawiyah
Oct 12, 2023
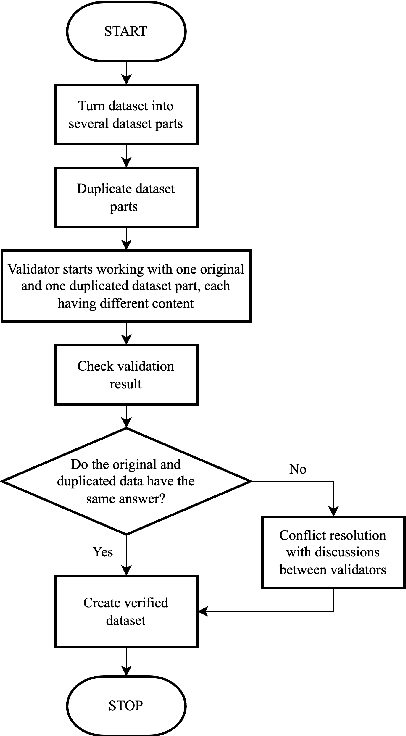

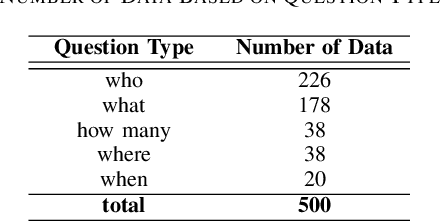
Nowadays, Question Answering (QA) tasks receive significant research focus, particularly with the development of Large Language Model (LLM) such as Chat GPT [1]. LLM can be applied to various domains, but it contradicts the principles of information transmission when applied to the Islamic domain. In Islam we strictly regulates the sources of information and who can give interpretations or tafseer for that sources [2]. The approach used by LLM to generate answers based on its own interpretation is similar to the concept of tafseer, LLM is neither an Islamic expert nor a human which is not permitted in Islam. Indonesia is the country with the largest Islamic believer population in the world [3]. With the high influence of LLM, we need to make evaluation of LLM in religious domain. Currently, there is only few religious QA dataset available and none of them using Sirah Nabawiyah especially in Indonesian Language. In this paper, we propose the Question Answering Sirah Nabawiyah (QASiNa) dataset, a novel dataset compiled from Sirah Nabawiyah literatures in Indonesian language. We demonstrate our dataset by using mBERT [4], XLM-R [5], and IndoBERT [6] which fine-tuned with Indonesian translation of SQuAD v2.0 [7]. XLM-R model returned the best performance on QASiNa with EM of 61.20, F1-Score of 75.94, and Substring Match of 70.00. We compare XLM-R performance with Chat GPT-3.5 and GPT-4 [1]. Both Chat GPT version returned lower EM and F1-Score with higher Substring Match, the gap of EM and Substring Match get wider in GPT-4. The experiment indicate that Chat GPT tends to give excessive interpretations as evidenced by its higher Substring Match scores compared to EM and F1-Score, even after providing instruction and context. This concludes Chat GPT is unsuitable for question answering task in religious domain especially for Islamic religion.
Extended target tracking utilizing machine-learning software -- with applications to animal classification
Oct 12, 2023This paper considers the problem of detecting and tracking objects in a sequence of images. The problem is formulated in a filtering framework, using the output of object-detection algorithms as measurements. An extension to the filtering formulation is proposed that incorporates class information from the previous frame to robustify the classification, even if the object-detection algorithm outputs an incorrect prediction. Further, the properties of the object-detection algorithm are exploited to quantify the uncertainty of the bounding box detection in each frame. The complete filtering method is evaluated on camera trap images of the four large Swedish carnivores, bear, lynx, wolf, and wolverine. The experiments show that the class tracking formulation leads to a more robust classification.
Spectral vs Energy Efficiency in 6G: Impact of the Receiver Front-End
Oct 04, 2023This article puts the spotlight on the receiver front-end (RFE), an integral part of any wireless device that information theory typically idealizes into a mere addition of noise. While this idealization was sound in the past, as operating frequencies, bandwidths, and antenna counts rise, a soaring amount of power is required for the RFE to behave accordingly. Containing this surge in power expenditure exposes a harsher behavior on the part of the RFE (more noise, nonlinearities, and coarse quantization), setting up a tradeoff between the spectral efficiency under such nonidealities and the efficiency in the use of energy by the RFE. With the urge for radically better power consumptions and energy efficiencies in 6G, this emerges as an issue on which information theory can cast light at a fundamental level. More broadly, this article advocates the interest of having information theory embrace the device power consumption in its analyses. In turn, this calls for new models and abstractions such as the ones herein put together for the RFE, and for a more holistic perspective.
Building Interpretable and Reliable Open Information Retriever for New Domains Overnight
Aug 09, 2023
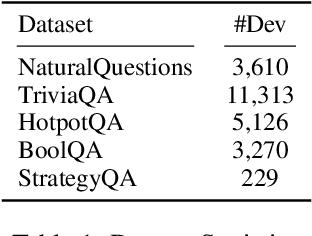
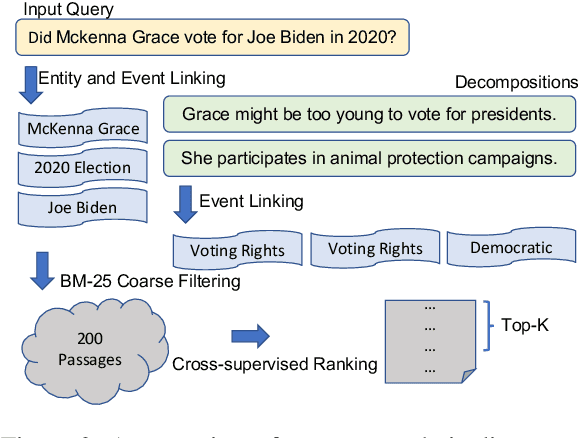

Information retrieval (IR) or knowledge retrieval, is a critical component for many down-stream tasks such as open-domain question answering (QA). It is also very challenging, as it requires succinctness, completeness, and correctness. In recent works, dense retrieval models have achieved state-of-the-art (SOTA) performance on in-domain IR and QA benchmarks by representing queries and knowledge passages with dense vectors and learning the lexical and semantic similarity. However, using single dense vectors and end-to-end supervision are not always optimal because queries may require attention to multiple aspects and event implicit knowledge. In this work, we propose an information retrieval pipeline that uses entity/event linking model and query decomposition model to focus more accurately on different information units of the query. We show that, while being more interpretable and reliable, our proposed pipeline significantly improves passage coverages and denotation accuracies across five IR and QA benchmarks. It will be the go-to system to use for applications that need to perform IR on a new domain without much dedicated effort, because of its superior interpretability and cross-domain performance.
Do self-supervised speech and language models extract similar representations as human brain?
Oct 07, 2023Speech and language models trained through self-supervised learning (SSL) demonstrate strong alignment with brain activity during speech and language perception. However, given their distinct training modalities, it remains unclear whether they correlate with the same neural aspects. We directly address this question by evaluating the brain prediction performance of two representative SSL models, Wav2Vec2.0 and GPT-2, designed for speech and language tasks. Our findings reveal that both models accurately predict speech responses in the auditory cortex, with a significant correlation between their brain predictions. Notably, shared speech contextual information between Wav2Vec2.0 and GPT-2 accounts for the majority of explained variance in brain activity, surpassing static semantic and lower-level acoustic-phonetic information. These results underscore the convergence of speech contextual representations in SSL models and their alignment with the neural network underlying speech perception, offering valuable insights into both SSL models and the neural basis of speech and language processing.
Towards Semantic Communication Protocols for 6G: From Protocol Learning to Language-Oriented Approaches
Oct 14, 2023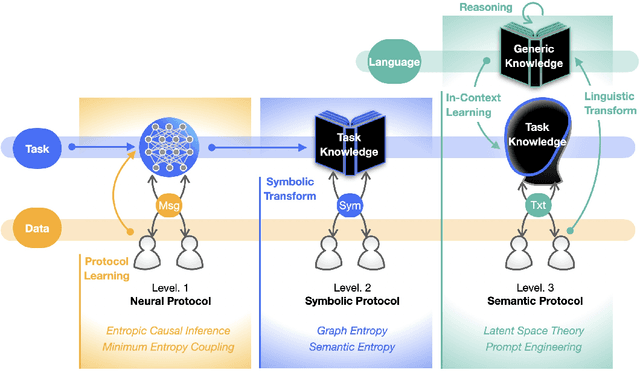
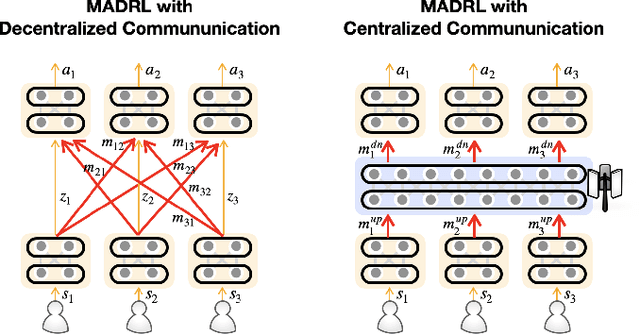
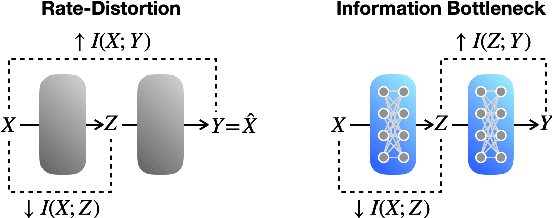

The forthcoming 6G systems are expected to address a wide range of non-stationary tasks. This poses challenges to traditional medium access control (MAC) protocols that are static and predefined. In response, data-driven MAC protocols have recently emerged, offering ability to tailor their signaling messages for specific tasks. This article presents a novel categorization of these data-driven MAC protocols into three levels: Level 1 MAC. task-oriented neural protocols constructed using multi-agent deep reinforcement learning (MADRL); Level 2 MAC. neural network-oriented symbolic protocols developed by converting Level 1 MAC outputs into explicit symbols; and Level 3 MAC. language-oriented semantic protocols harnessing large language models (LLMs) and generative models. With this categorization, we aim to explore the opportunities and challenges of each level by delving into their foundational techniques. Drawing from information theory and associated principles as well as selected case studies, this study provides insights into the trajectory of data-driven MAC protocols and sheds light on future research directions.
Learning Unified Representations for Multi-Resolution Face Recognition
Oct 14, 2023In this work, we propose Branch-to-Trunk network (BTNet), a representation learning method for multi-resolution face recognition. It consists of a trunk network (TNet), namely a unified encoder, and multiple branch networks (BNets), namely resolution adapters. As per the input, a resolution-specific BNet is used and the output are implanted as feature maps in the feature pyramid of TNet, at a layer with the same resolution. The discriminability of tiny faces is significantly improved, as the interpolation error introduced by rescaling, especially up-sampling, is mitigated on the inputs. With branch distillation and backward-compatible training, BTNet transfers discriminative high-resolution information to multiple branches while guaranteeing representation compatibility. Our experiments demonstrate strong performance on face recognition benchmarks, both for multi-resolution identity matching and feature aggregation, with much less computation amount and parameter storage. We establish new state-of-the-art on the challenging QMUL-SurvFace 1: N face identification task. Our code is available at https://github.com/StevenSmith2000/BTNet.
Proposal-based Temporal Action Localization with Point-level Supervision
Oct 09, 2023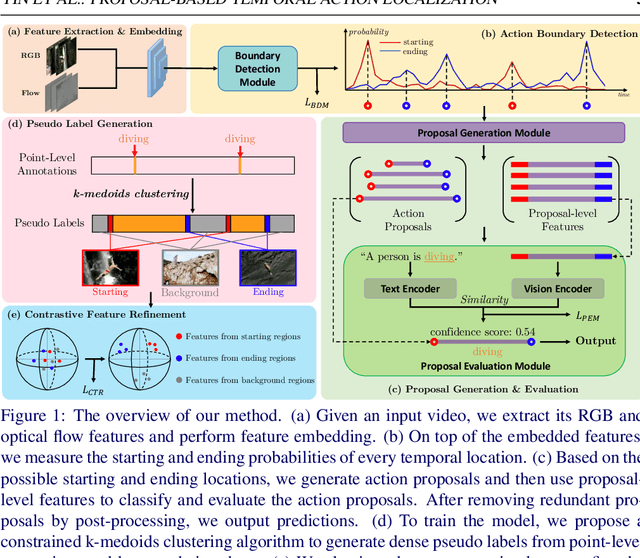
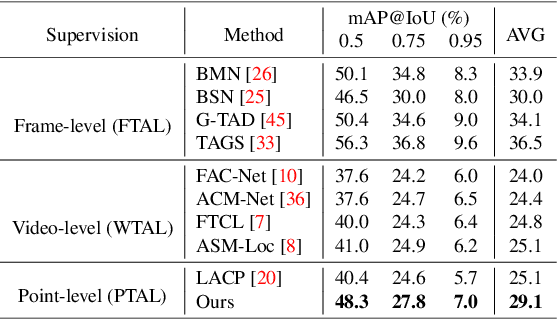
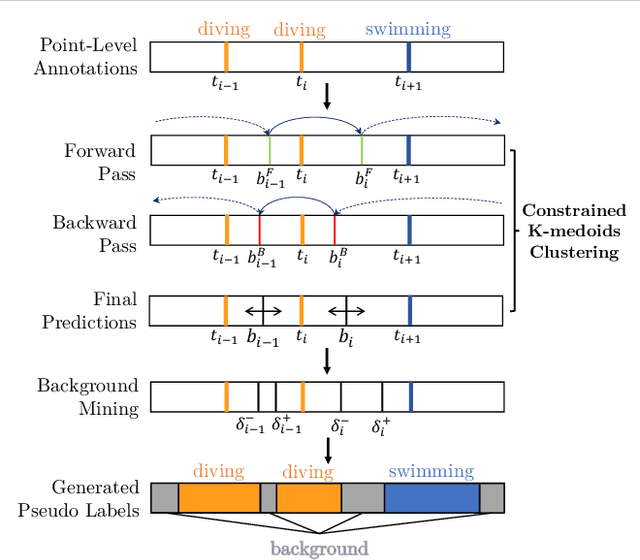
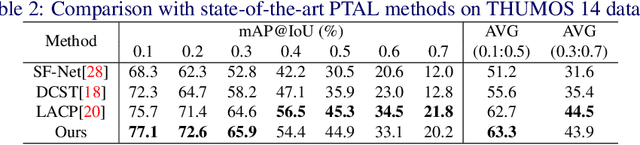
Point-level supervised temporal action localization (PTAL) aims at recognizing and localizing actions in untrimmed videos where only a single point (frame) within every action instance is annotated in training data. Without temporal annotations, most previous works adopt the multiple instance learning (MIL) framework, where the input video is segmented into non-overlapped short snippets, and action classification is performed independently on every short snippet. We argue that the MIL framework is suboptimal for PTAL because it operates on separated short snippets that contain limited temporal information. Therefore, the classifier only focuses on several easy-to-distinguish snippets instead of discovering the whole action instance without missing any relevant snippets. To alleviate this problem, we propose a novel method that localizes actions by generating and evaluating action proposals of flexible duration that involve more comprehensive temporal information. Moreover, we introduce an efficient clustering algorithm to efficiently generate dense pseudo labels that provide stronger supervision, and a fine-grained contrastive loss to further refine the quality of pseudo labels. Experiments show that our proposed method achieves competitive or superior performance to the state-of-the-art methods and some fully-supervised methods on four benchmarks: ActivityNet 1.3, THUMOS 14, GTEA, and BEOID datasets.
CoBEVFusion: Cooperative Perception with LiDAR-Camera Bird's-Eye View Fusion
Oct 09, 2023Autonomous Vehicles (AVs) use multiple sensors to gather information about their surroundings. By sharing sensor data between Connected Autonomous Vehicles (CAVs), the safety and reliability of these vehicles can be improved through a concept known as cooperative perception. However, recent approaches in cooperative perception only share single sensor information such as cameras or LiDAR. In this research, we explore the fusion of multiple sensor data sources and present a framework, called CoBEVFusion, that fuses LiDAR and camera data to create a Bird's-Eye View (BEV) representation. The CAVs process the multi-modal data locally and utilize a Dual Window-based Cross-Attention (DWCA) module to fuse the LiDAR and camera features into a unified BEV representation. The fused BEV feature maps are shared among the CAVs, and a 3D Convolutional Neural Network is applied to aggregate the features from the CAVs. Our CoBEVFusion framework was evaluated on the cooperative perception dataset OPV2V for two perception tasks: BEV semantic segmentation and 3D object detection. The results show that our DWCA LiDAR-camera fusion model outperforms perception models with single-modal data and state-of-the-art BEV fusion models. Our overall cooperative perception architecture, CoBEVFusion, also achieves comparable performance with other cooperative perception models.