 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploit the antenna response consistency to define the alignment criteria for CSI data
Oct 10, 2023
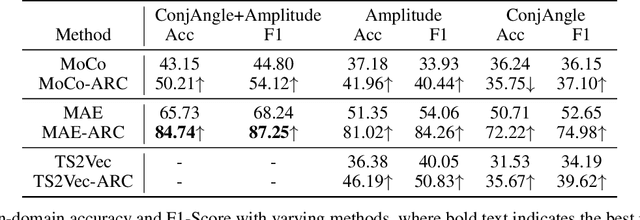
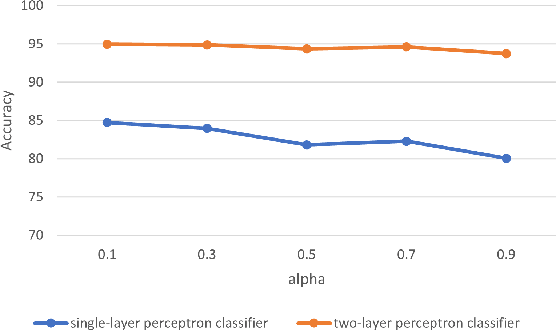
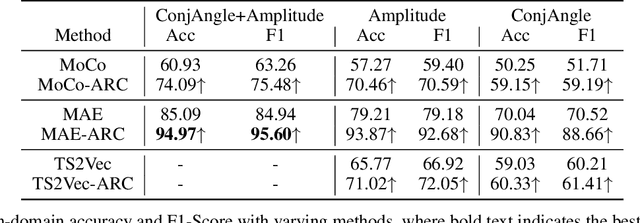
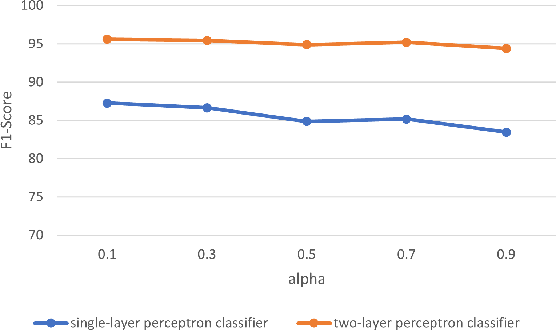
Self-supervised learning (SSL) for WiFi-based human activity recognition (HAR) holds great promise due to its ability to address the challenge of insufficient labeled data. However, directly transplanting SSL algorithms, especially contrastive learning, originally designed for other domains to CSI data, often fails to achieve the expected performance. We attribute this issue to the inappropriate alignment criteria, which disrupt the semantic distance consistency between the feature space and the input space. To address this challenge, we introduce \textbf{A}netenna \textbf{R}esponse \textbf{C}onsistency (ARC) as a solution to define proper alignment criteria. ARC is designed to retain semantic information from the input space while introducing robustness to real-world noise. We analyze ARC from the perspective of CSI data structure, demonstrating that its optimal solution leads to a direct mapping from input CSI data to action vectors in the feature map. Furthermore, we provide extensive experimental evidence to validate the effectiveness of ARC in improving the performance of self-supervised learning for WiFi-based HAR.
Evaluating Explanation Methods for Vision-and-Language Navigation
Oct 10, 2023The ability to navigate robots with natural language instructions in an unknown environment is a crucial step for achieving embodied artificial intelligence (AI). With the improving performance of deep neural models proposed in the field of vision-and-language navigation (VLN), it is equally interesting to know what information the models utilize for their decision-making in the navigation tasks. To understand the inner workings of deep neural models, various explanation methods have been developed for promoting explainable AI (XAI). But they are mostly applied to deep neural models for image or text classification tasks and little work has been done in explaining deep neural models for VLN tasks. In this paper, we address these problems by building quantitative benchmarks to evaluate explanation methods for VLN models in terms of faithfulness. We propose a new erasure-based evaluation pipeline to measure the step-wise textual explanation in the sequential decision-making setting. We evaluate several explanation methods for two representative VLN models on two popular VLN datasets and reveal valuable findings through our experiments.
Blind Dates: Examining the Expression of Temporality in Historical Photographs
Oct 10, 2023This paper explores the capacity of computer vision models to discern temporal information in visual content, focusing specifically on historical photographs. We investigate the dating of images using OpenCLIP, an open-source implementation of CLIP, a multi-modal language and vision model. Our experiment consists of three steps: zero-shot classification, fine-tuning, and analysis of visual content. We use the \textit{De Boer Scene Detection} dataset, containing 39,866 gray-scale historical press photographs from 1950 to 1999. The results show that zero-shot classification is relatively ineffective for image dating, with a bias towards predicting dates in the past. Fine-tuning OpenCLIP with a logistic classifier improves performance and eliminates the bias. Additionally, our analysis reveals that images featuring buses, cars, cats, dogs, and people are more accurately dated, suggesting the presence of temporal markers. The study highlights the potential of machine learning models like OpenCLIP in dating images and emphasizes the importance of fine-tuning for accurate temporal analysis. Future research should explore the application of these findings to color photographs and diverse datasets.
LLMs Killed the Script Kiddie: How Agents Supported by Large Language Models Change the Landscape of Network Threat Testing
Oct 10, 2023In this paper, we explore the potential of Large Language Models (LLMs) to reason about threats, generate information about tools, and automate cyber campaigns. We begin with a manual exploration of LLMs in supporting specific threat-related actions and decisions. We proceed by automating the decision process in a cyber campaign. We present prompt engineering approaches for a plan-act-report loop for one action of a threat campaign and and a prompt chaining design that directs the sequential decision process of a multi-action campaign. We assess the extent of LLM's cyber-specific knowledge w.r.t the short campaign we demonstrate and provide insights into prompt design for eliciting actionable responses. We discuss the potential impact of LLMs on the threat landscape and the ethical considerations of using LLMs for accelerating threat actor capabilities. We report a promising, yet concerning, application of generative AI to cyber threats. However, the LLM's capabilities to deal with more complex networks, sophisticated vulnerabilities, and the sensitivity of prompts are open questions. This research should spur deliberations over the inevitable advancements in LLM-supported cyber adversarial landscape.
Stochastic Super-resolution of Cosmological Simulations with Denoising Diffusion Models
Oct 10, 2023In recent years, deep learning models have been successfully employed for augmenting low-resolution cosmological simulations with small-scale information, a task known as "super-resolution". So far, these cosmological super-resolution models have relied on generative adversarial networks (GANs), which can achieve highly realistic results, but suffer from various shortcomings (e.g. low sample diversity). We introduce denoising diffusion models as a powerful generative model for super-resolving cosmic large-scale structure predictions (as a first proof-of-concept in two dimensions). To obtain accurate results down to small scales, we develop a new "filter-boosted" training approach that redistributes the importance of different scales in the pixel-wise training objective. We demonstrate that our model not only produces convincing super-resolution images and power spectra consistent at the percent level, but is also able to reproduce the diversity of small-scale features consistent with a given low-resolution simulation. This enables uncertainty quantification for the generated small-scale features, which is critical for the usefulness of such super-resolution models as a viable surrogate model for cosmic structure formation.
Multi-domain improves out-of-distribution and data-limited scenarios for medical image analysis
Oct 10, 2023Current machine learning methods for medical image analysis primarily focus on developing models tailored for their specific tasks, utilizing data within their target domain. These specialized models tend to be data-hungry and often exhibit limitations in generalizing to out-of-distribution samples. Recently, foundation models have been proposed, which combine data from various domains and demonstrate excellent generalization capabilities. Building upon this, this work introduces the incorporation of diverse medical image domains, including different imaging modalities like X-ray, MRI, CT, and ultrasound images, as well as various viewpoints such as axial, coronal, and sagittal views. We refer to this approach as multi-domain model and compare its performance to that of specialized models. Our findings underscore the superior generalization capabilities of multi-domain models, particularly in scenarios characterized by limited data availability and out-of-distribution, frequently encountered in healthcare applications. The integration of diverse data allows multi-domain models to utilize shared information across domains, enhancing the overall outcomes significantly. To illustrate, for organ recognition, multi-domain model can enhance accuracy by up to 10% compared to conventional specialized models.
WS-YOLO: Weakly Supervised Yolo Network for Surgical Tool Localization in Endoscopic Videos
Sep 27, 2023Being able to automatically detect and track surgical instruments in endoscopic video recordings would allow for many useful applications that could transform different aspects of surgery. In robot-assisted surgery, the potentially informative data like categories of surgical tool can be captured, which is sparse, full of noise and without spatial information. We proposed a Weakly Supervised Yolo Network (WS-YOLO) for Surgical Tool Localization in Endoscopic Videos, to generate fine-grained semantic information with location and category from coarse-grained semantic information outputted by the da Vinci surgical robot, which significantly diminished the necessary human annotation labor while striking an optimal balance between the quantity of manually annotated data and detection performance. The source code is available at https://github.com/Breezewrf/Weakly-Supervised-Yolov8.
ProGO: Probabilistic Global Optimizer
Oct 13, 2023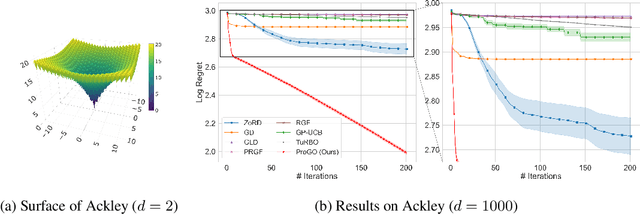
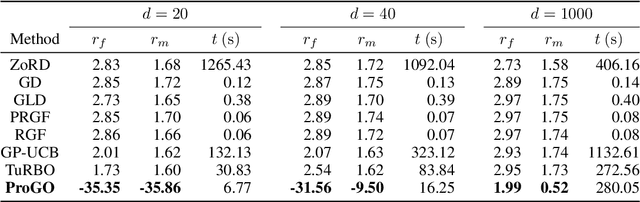
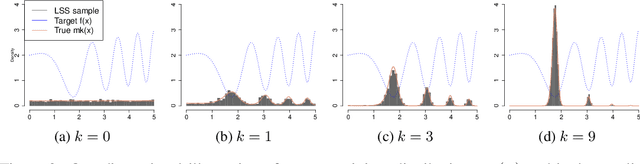
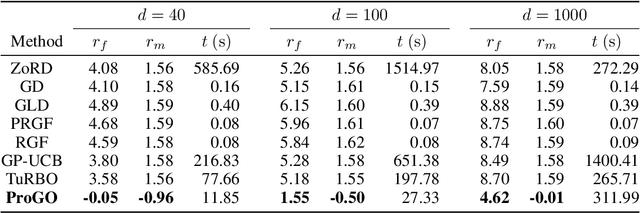
In the field of global optimization, many existing algorithms face challenges posed by non-convex target functions and high computational complexity or unavailability of gradient information. These limitations, exacerbated by sensitivity to initial conditions, often lead to suboptimal solutions or failed convergence. This is true even for Metaheuristic algorithms designed to amalgamate different optimization techniques to improve their efficiency and robustness. To address these challenges, we develop a sequence of multidimensional integration-based methods that we show to converge to the global optima under some mild regularity conditions. Our probabilistic approach does not require the use of gradients and is underpinned by a mathematically rigorous convergence framework anchored in the nuanced properties of nascent optima distribution. In order to alleviate the problem of multidimensional integration, we develop a latent slice sampler that enjoys a geometric rate of convergence in generating samples from the nascent optima distribution, which is used to approximate the global optima. The proposed Probabilistic Global Optimizer (ProGO) provides a scalable unified framework to approximate the global optima of any continuous function defined on a domain of arbitrary dimension. Empirical illustrations of ProGO across a variety of popular non-convex test functions (having finite global optima) reveal that the proposed algorithm outperforms, by order of magnitude, many existing state-of-the-art methods, including gradient-based, zeroth-order gradient-free, and some Bayesian Optimization methods, in term regret value and speed of convergence. It is, however, to be noted that our approach may not be suitable for functions that are expensive to compute.
DDMT: Denoising Diffusion Mask Transformer Models for Multivariate Time Series Anomaly Detection
Oct 13, 2023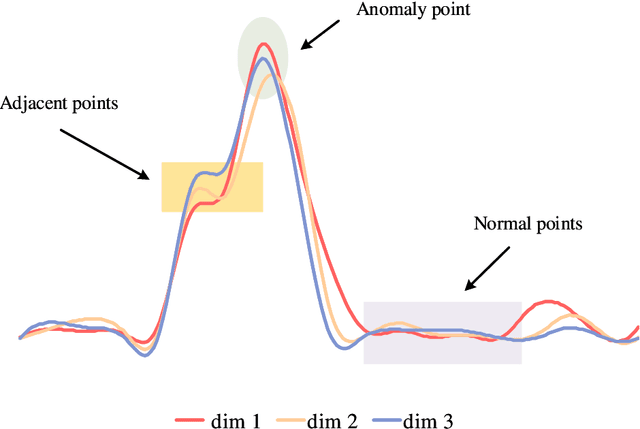

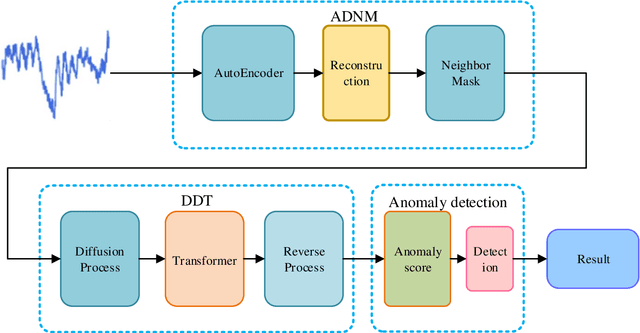
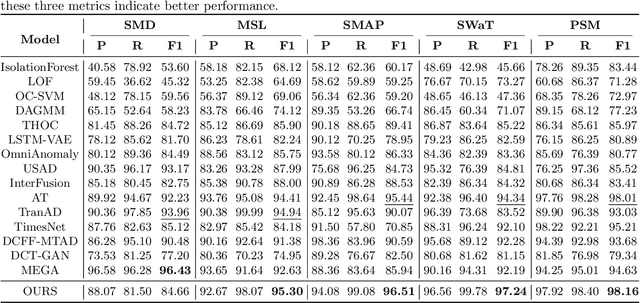
Anomaly detection in multivariate time series has emerged as a crucial challenge in time series research, with significant research implications in various fields such as fraud detection, fault diagnosis, and system state estimation. Reconstruction-based models have shown promising potential in recent years for detecting anomalies in time series data. However, due to the rapid increase in data scale and dimensionality, the issues of noise and Weak Identity Mapping (WIM) during time series reconstruction have become increasingly pronounced. To address this, we introduce a novel Adaptive Dynamic Neighbor Mask (ADNM) mechanism and integrate it with the Transformer and Denoising Diffusion Model, creating a new framework for multivariate time series anomaly detection, named Denoising Diffusion Mask Transformer (DDMT). The ADNM module is introduced to mitigate information leakage between input and output features during data reconstruction, thereby alleviating the problem of WIM during reconstruction. The Denoising Diffusion Transformer (DDT) employs the Transformer as an internal neural network structure for Denoising Diffusion Model. It learns the stepwise generation process of time series data to model the probability distribution of the data, capturing normal data patterns and progressively restoring time series data by removing noise, resulting in a clear recovery of anomalies. To the best of our knowledge, this is the first model that combines Denoising Diffusion Model and the Transformer for multivariate time series anomaly detection. Experimental evaluations were conducted on five publicly available multivariate time series anomaly detection datasets. The results demonstrate that the model effectively identifies anomalies in time series data, achieving state-of-the-art performance in anomaly detection.
Graph Condensation via Eigenbasis Matching
Oct 13, 2023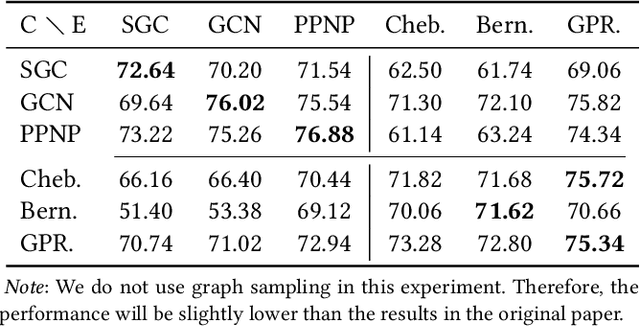
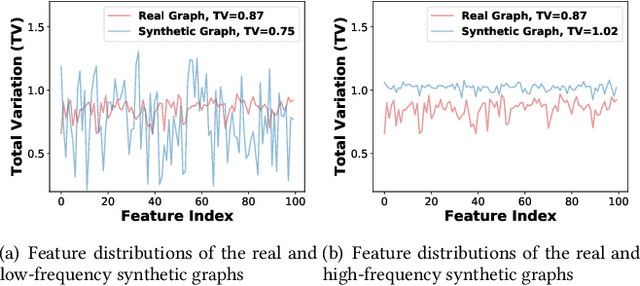

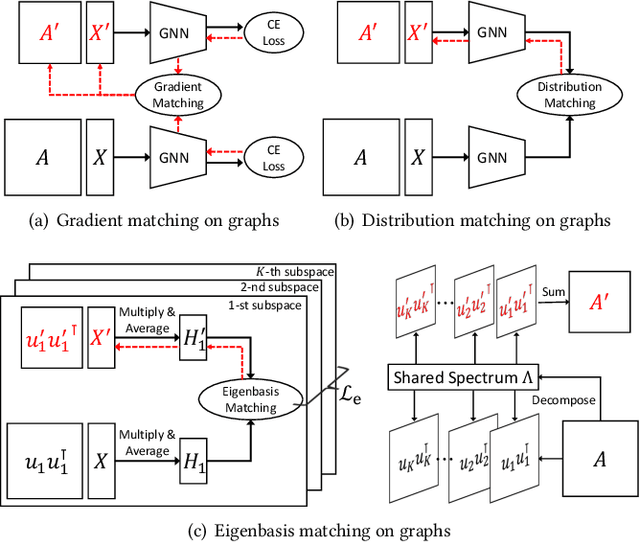
The increasing amount of graph data places requirements on the efficiency and scalability of graph neural networks (GNNs), despite their effectiveness in various graph-related applications. Recently, the emerging graph condensation (GC) sheds light on reducing the computational cost of GNNs from a data perspective. It aims to replace the real large graph with a significantly smaller synthetic graph so that GNNs trained on both graphs exhibit comparable performance. However, our empirical investigation reveals that existing GC methods suffer from poor generalization, i.e., different GNNs trained on the same synthetic graph have obvious performance gaps. What factors hinder the generalization of GC and how can we mitigate it? To answer this question, we commence with a detailed analysis and observe that GNNs will inject spectrum bias into the synthetic graph, resulting in a distribution shift. To tackle this issue, we propose eigenbasis matching for spectrum-free graph condensation, named GCEM, which has two key steps: First, GCEM matches the eigenbasis of the real and synthetic graphs, rather than the graph structure, which eliminates the spectrum bias of GNNs. Subsequently, GCEM leverages the spectrum of the real graph and the synthetic eigenbasis to construct the synthetic graph, thereby preserving the essential structural information. We theoretically demonstrate that the synthetic graph generated by GCEM maintains the spectral similarity, i.e., total variation, of the real graph. Extensive experiments conducted on five graph datasets verify that GCEM not only achieves state-of-the-art performance over baselines but also significantly narrows the performance gaps between different GNNs.