 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Perception Reinforcement Using Auxiliary Learning Feature Fusion: A Modified Yolov8 for Head Detection
Oct 14, 2023
Head detection provides distribution information of pedestrian, which is crucial for scene statistical analysis, traffic management, and risk assessment and early warning. However, scene complexity and large-scale variation in the real world make accurate detection more difficult. Therefore, we present a modified Yolov8 which improves head detection performance through reinforcing target perception. An Auxiliary Learning Feature Fusion (ALFF) module comprised of LSTM and convolutional blocks is used as the auxiliary task to help the model perceive targets. In addition, we introduce Noise Calibration into Distribution Focal Loss to facilitate model fitting and improve the accuracy of detection. Considering the requirements of high accuracy and speed for the head detection task, our method is adapted with two kinds of backbone, namely Yolov8n and Yolov8m. The results demonstrate the superior performance of our approach in improving detection accuracy and robustness.
X-ray phase and dark-field computed tomography without optical elements
Oct 14, 2023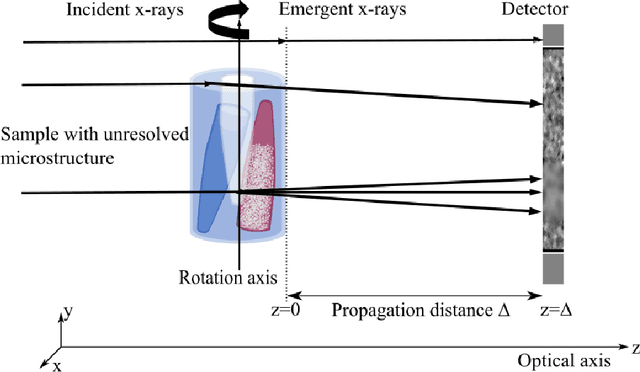
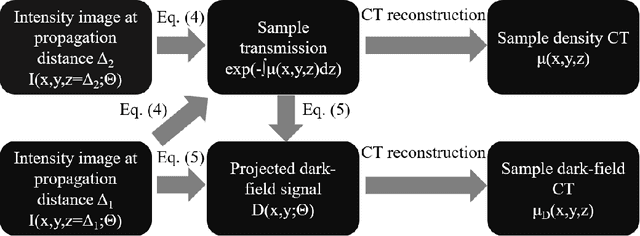
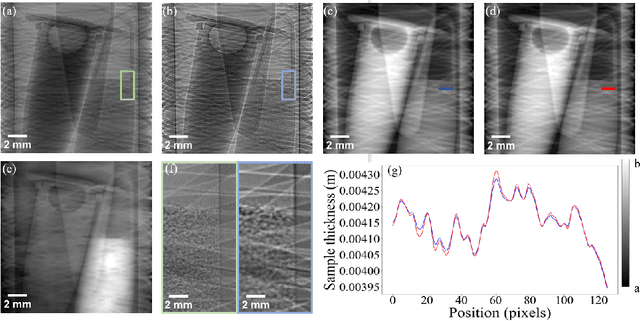
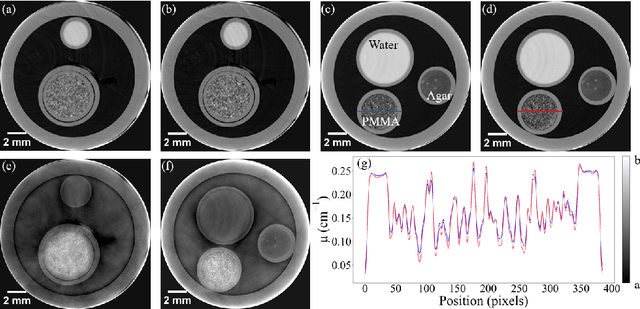
X-ray diffusive dark-field imaging, which allows spatially unresolved microstructure to be mapped across a sample, is an increasingly popular tool in an array of settings. Here, we present a new algorithm for phase and dark-field computed tomography based on the x-ray Fokker-Planck equation. Needing only a coherent x-ray source, sample, and detector, our propagation-based algorithm can map the sample density and dark-field/diffusion properties of the sample in 3D. Importantly, incorporating dark-field information in the density reconstruction process enables a higher spatial resolution reconstruction than possible with previous propagation-based approaches. Two sample exposures at each projection angle are sufficient for the successful reconstruction of both the sample density and dark-field Fokker-Planck diffusion coefficients. We anticipate that the proposed algorithm may be of benefit in biomedical imaging and industrial settings.
MuseChat: A Conversational Music Recommendation System for Videos
Oct 11, 2023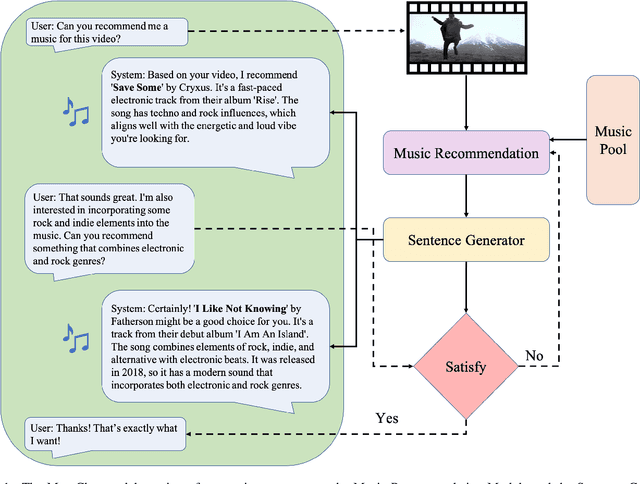

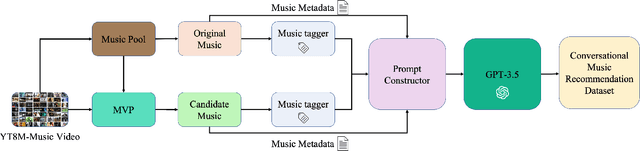

We introduce MuseChat, an innovative dialog-based music recommendation system. This unique platform not only offers interactive user engagement but also suggests music tailored for input videos, so that users can refine and personalize their music selections. In contrast, previous systems predominantly emphasized content compatibility, often overlooking the nuances of users' individual preferences. For example, all the datasets only provide basic music-video pairings or such pairings with textual music descriptions. To address this gap, our research offers three contributions. First, we devise a conversation-synthesis method that simulates a two-turn interaction between a user and a recommendation system, which leverages pre-trained music tags and artist information. In this interaction, users submit a video to the system, which then suggests a suitable music piece with a rationale. Afterwards, users communicate their musical preferences, and the system presents a refined music recommendation with reasoning. Second, we introduce a multi-modal recommendation engine that matches music either by aligning it with visual cues from the video or by harmonizing visual information, feedback from previously recommended music, and the user's textual input. Third, we bridge music representations and textual data with a Large Language Model(Vicuna-7B). This alignment equips MuseChat to deliver music recommendations and their underlying reasoning in a manner resembling human communication. Our evaluations show that MuseChat surpasses existing state-of-the-art models in music retrieval tasks and pioneers the integration of the recommendation process within a natural language framework.
FGPrompt: Fine-grained Goal Prompting for Image-goal Navigation
Oct 11, 2023Learning to navigate to an image-specified goal is an important but challenging task for autonomous systems. The agent is required to reason the goal location from where a picture is shot. Existing methods try to solve this problem by learning a navigation policy, which captures semantic features of the goal image and observation image independently and lastly fuses them for predicting a sequence of navigation actions. However, these methods suffer from two major limitations. 1) They may miss detailed information in the goal image, and thus fail to reason the goal location. 2) More critically, it is hard to focus on the goal-relevant regions in the observation image, because they attempt to understand observation without goal conditioning. In this paper, we aim to overcome these limitations by designing a Fine-grained Goal Prompting (FGPrompt) method for image-goal navigation. In particular, we leverage fine-grained and high-resolution feature maps in the goal image as prompts to perform conditioned embedding, which preserves detailed information in the goal image and guides the observation encoder to pay attention to goal-relevant regions. Compared with existing methods on the image-goal navigation benchmark, our method brings significant performance improvement on 3 benchmark datasets (i.e., Gibson, MP3D, and HM3D). Especially on Gibson, we surpass the state-of-the-art success rate by 8% with only 1/50 model size. Project page: https://xinyusun.github.io/fgprompt-pages
Attention-Map Augmentation for Hypercomplex Breast Cancer Classification
Oct 11, 2023Breast cancer is the most widespread neoplasm among women and early detection of this disease is critical. Deep learning techniques have become of great interest to improve diagnostic performance. Nonetheless, discriminating between malignant and benign masses from whole mammograms remains challenging due to them being almost identical to an untrained eye and the region of interest (ROI) occupying a minuscule portion of the entire image. In this paper, we propose a framework, parameterized hypercomplex attention maps (PHAM), to overcome these problems. Specifically, we deploy an augmentation step based on computing attention maps. Then, the attention maps are used to condition the classification step by constructing a multi-dimensional input comprised of the original breast cancer image and the corresponding attention map. In this step, a parameterized hypercomplex neural network (PHNN) is employed to perform breast cancer classification. The framework offers two main advantages. First, attention maps provide critical information regarding the ROI and allow the neural model to concentrate on it. Second, the hypercomplex architecture has the ability to model local relations between input dimensions thanks to hypercomplex algebra rules, thus properly exploiting the information provided by the attention map. We demonstrate the efficacy of the proposed framework on both mammography images as well as histopathological ones, surpassing attention-based state-of-the-art networks and the real-valued counterpart of our method. The code of our work is available at https://github.com/elelo22/AttentionBCS.
Language Models As Semantic Indexers
Oct 11, 2023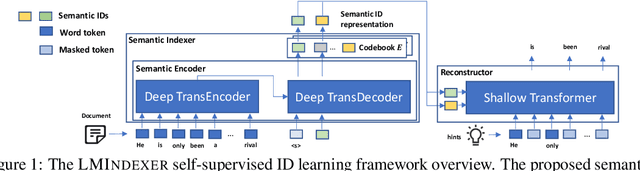
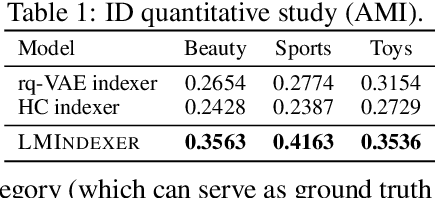
Semantic identifier (ID) is an important concept in information retrieval that aims to preserve the semantics of objects such as documents and items inside their IDs. Previous studies typically adopt a two-stage pipeline to learn semantic IDs by first procuring embeddings using off-the-shelf text encoders and then deriving IDs based on the embeddings. However, each step introduces potential information loss and there is usually an inherent mismatch between the distribution of embeddings within the latent space produced by text encoders and the anticipated distribution required for semantic indexing. Nevertheless, it is non-trivial to design a method that can learn the document's semantic representations and its hierarchical structure simultaneously, given that semantic IDs are discrete and sequentially structured, and the semantic supervision is deficient. In this paper, we introduce LMINDEXER, a self-supervised framework to learn semantic IDs with a generative language model. We tackle the challenge of sequential discrete ID by introducing a semantic indexer capable of generating neural sequential discrete representations with progressive training and contrastive learning. In response to the semantic supervision deficiency, we propose to train the model with a self-supervised document reconstruction objective. The learned semantic indexer can facilitate various downstream tasks, such as recommendation and retrieval. We conduct experiments on three tasks including recommendation, product search, and document retrieval on five datasets from various domains, where LMINDEXER outperforms competitive baselines significantly and consistently.
An Ontology of Co-Creative AI Systems
Oct 11, 2023The term co-creativity has been used to describe a wide variety of human-AI assemblages in which human and AI are both involved in a creative endeavor. In order to assist with disambiguating research efforts, we present an ontology of co-creative systems, focusing on how responsibilities are divided between human and AI system and the information exchanged between them. We extend Lubart's original ontology of creativity support tools with three new categories emphasizing artificial intelligence: computer-as-subcontractor, computer-as-critic, and computer-as-teammate, some of which have sub-categorizations.
A Multi-Perspective Learning to Rank Approach to Support Children's Information Seeking in the Classroom
Aug 29, 2023
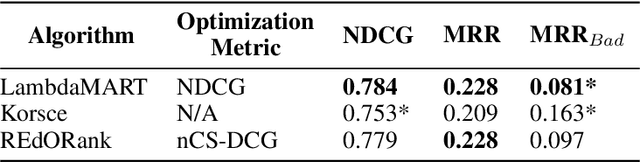
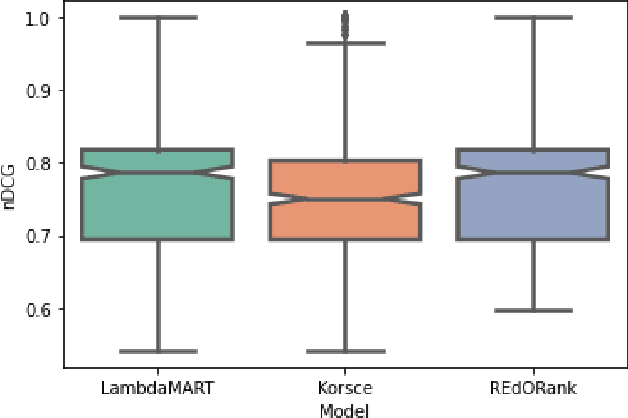
We introduce a novel re-ranking model that aims to augment the functionality of standard search engines to support classroom search activities for children (ages 6 to 11). This model extends the known listwise learning-to-rank framework by balancing risk and reward. Doing so enables the model to prioritize Web resources of high educational alignment, appropriateness, and adequate readability by analyzing the URLs, snippets, and page titles of Web resources retrieved by a given mainstream search engine. Experimental results, including an ablation study and comparisons with existing baselines, showcase the correctness of the proposed model. The outcomes of this work demonstrate the value of considering multiple perspectives inherent to the classroom setting, e.g., educational alignment, readability, and objectionability, when applied to the design of algorithms that can better support children's information discovery.
Belief formation and the persistence of biased beliefs
Oct 12, 2023We propose a belief-formation model where agents attempt to discriminate between two theories, and where the asymmetry in strength between confirming and disconfirming evidence tilts beliefs in favor of theories that generate strong (and possibly rare) confirming evidence and weak (and frequent) disconfirming evidence. In our model, limitations on information processing provide incentives to censor weak evidence, with the consequence that for some discrimination problems, evidence may become mostly one-sided, independently of the true underlying theory. Sophisticated agents who know the characteristics of the censored data-generating process are not lured by this accumulation of ``evidence'', but less sophisticated ones end up with biased beliefs.
Few-shot Action Recognition with Captioning Foundation Models
Oct 16, 2023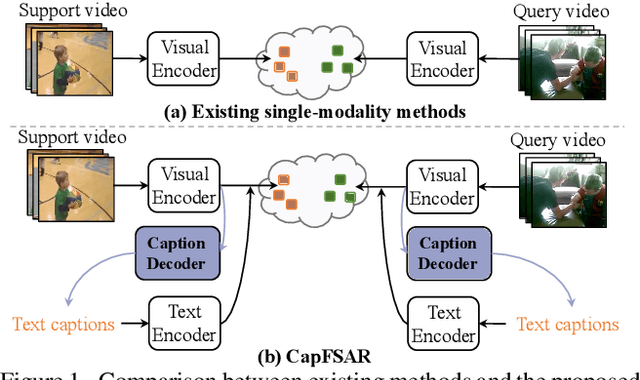
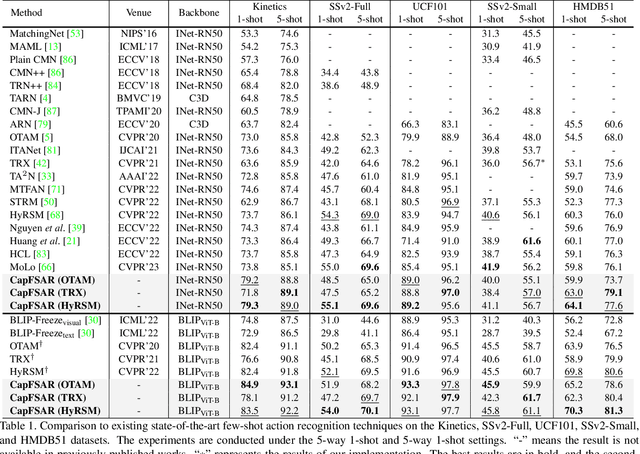
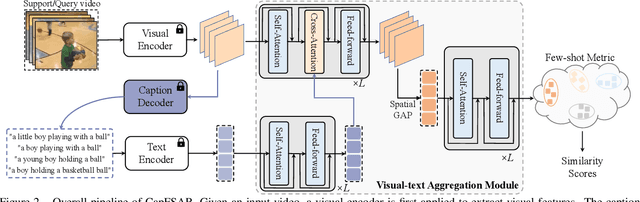
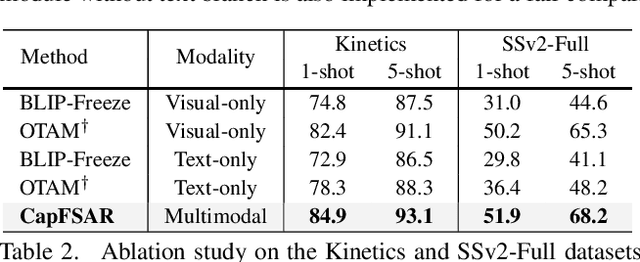
Transferring vision-language knowledge from pretrained multimodal foundation models to various downstream tasks is a promising direction. However, most current few-shot action recognition methods are still limited to a single visual modality input due to the high cost of annotating additional textual descriptions. In this paper, we develop an effective plug-and-play framework called CapFSAR to exploit the knowledge of multimodal models without manually annotating text. To be specific, we first utilize a captioning foundation model (i.e., BLIP) to extract visual features and automatically generate associated captions for input videos. Then, we apply a text encoder to the synthetic captions to obtain representative text embeddings. Finally, a visual-text aggregation module based on Transformer is further designed to incorporate cross-modal spatio-temporal complementary information for reliable few-shot matching. In this way, CapFSAR can benefit from powerful multimodal knowledge of pretrained foundation models, yielding more comprehensive classification in the low-shot regime. Extensive experiments on multiple standard few-shot benchmarks demonstrate that the proposed CapFSAR performs favorably against existing methods and achieves state-of-the-art performance. The code will be made publicly available.