 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Super Denoise Net: Speech Super Resolution with Noise Cancellation in Low Sampling Rate Noisy Environments
Oct 10, 2023
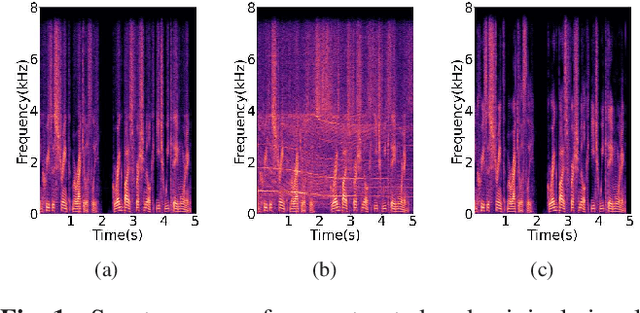
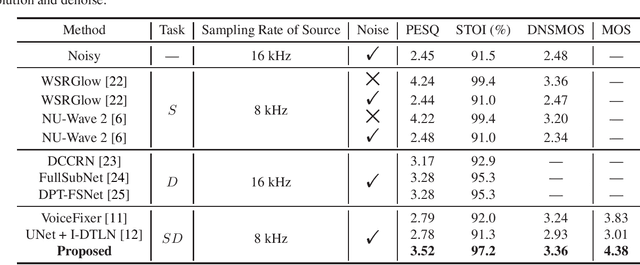
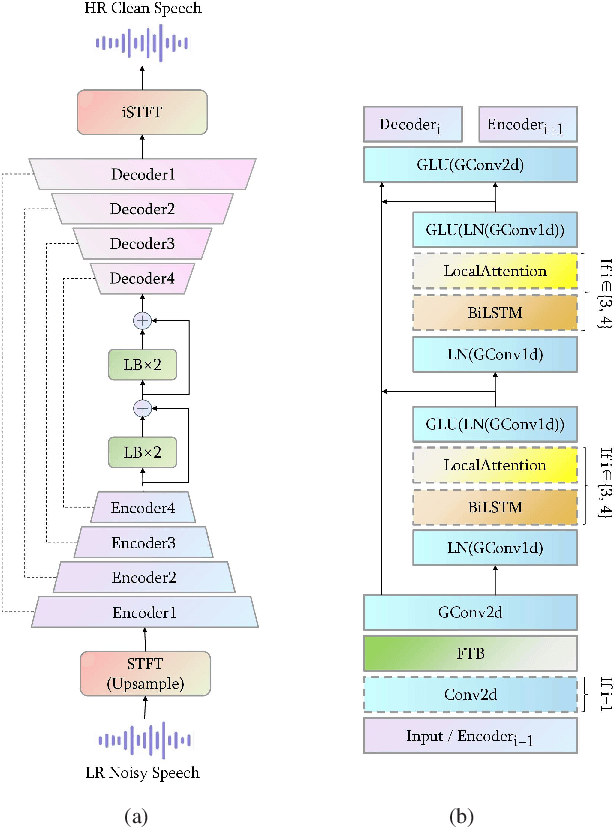
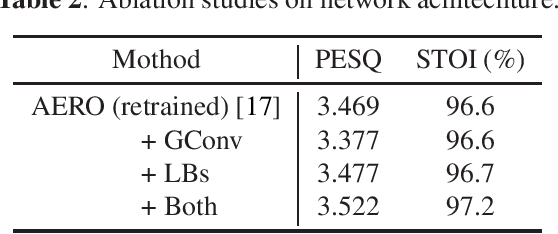
Speech super-resolution (SSR) aims to predict a high resolution (HR) speech signal from its low resolution (LR) corresponding part. Most neural SSR models focus on producing the final result in a noise-free environment by recovering the spectrogram of high-frequency part of the signal and concatenating it with the original low-frequency part. Although these methods achieve high accuracy, they become less effective when facing the real-world scenario, where unavoidable noise is present. To address this problem, we propose a Super Denoise Net (SDNet), a neural network for a joint task of super-resolution and noise reduction from a low sampling rate signal. To that end, we design gated convolution and lattice convolution blocks to enhance the repair capability and capture information in the time-frequency axis, respectively. The experiments show our method outperforms baseline speech denoising and SSR models on DNS 2020 no-reverb test set with higher objective and subjective scores.
Interpretable Traffic Event Analysis with Bayesian Networks
Oct 10, 2023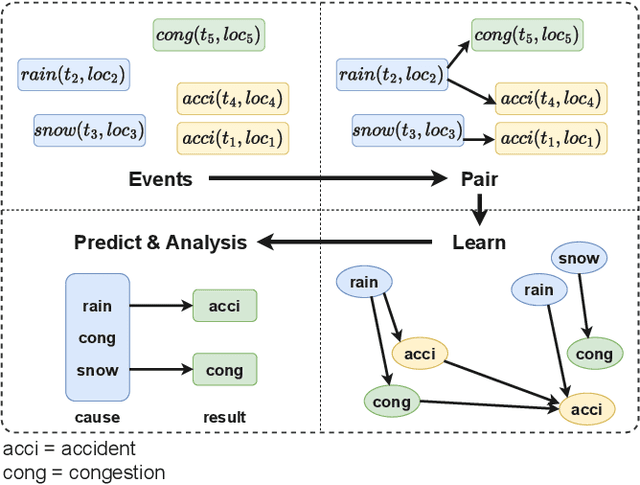
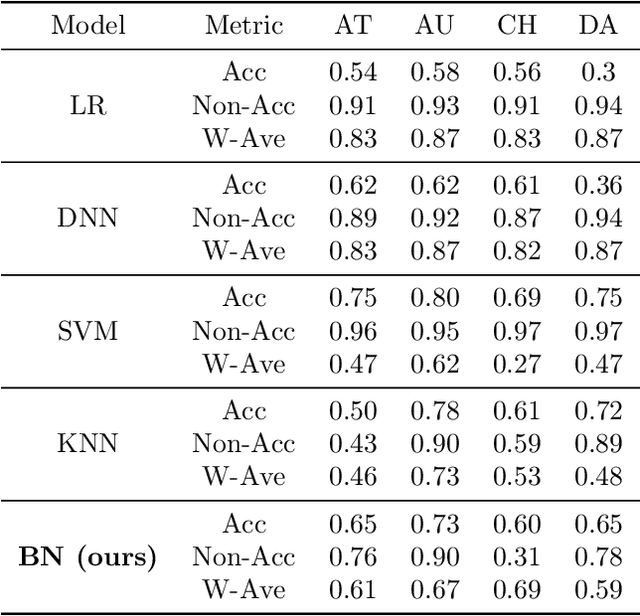
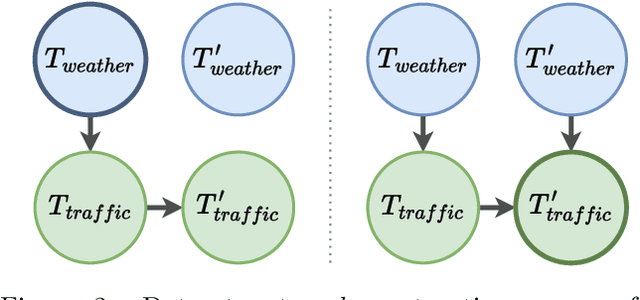
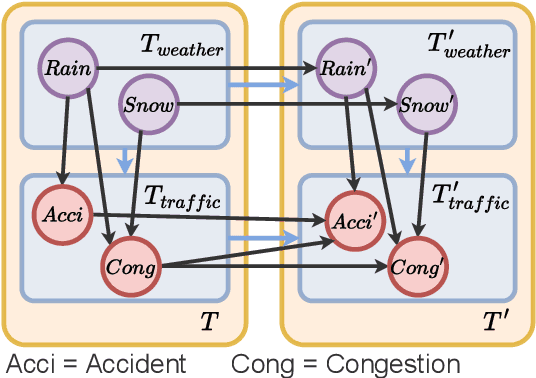
Although existing machine learning-based methods for traffic accident analysis can provide good quality results to downstream tasks, they lack interpretability which is crucial for this critical problem. This paper proposes an interpretable framework based on Bayesian Networks for traffic accident prediction. To enable the ease of interpretability, we design a dataset construction pipeline to feed the traffic data into the framework while retaining the essential traffic data information. With a concrete case study, our framework can derive a Bayesian Network from a dataset based on the causal relationships between weather and traffic events across the United States. Consequently, our framework enables the prediction of traffic accidents with competitive accuracy while examining how the probability of these events changes under different conditions, thus illustrating transparent relationships between traffic and weather events. Additionally, the visualization of the network simplifies the analysis of relationships between different variables, revealing the primary causes of traffic accidents and ultimately providing a valuable reference for reducing traffic accidents.
Federated Multi-Level Optimization over Decentralized Networks
Oct 10, 2023Multi-level optimization has gained increasing attention in recent years, as it provides a powerful framework for solving complex optimization problems that arise in many fields, such as meta-learning, multi-player games, reinforcement learning, and nested composition optimization. In this paper, we study the problem of distributed multi-level optimization over a network, where agents can only communicate with their immediate neighbors. This setting is motivated by the need for distributed optimization in large-scale systems, where centralized optimization may not be practical or feasible. To address this problem, we propose a novel gossip-based distributed multi-level optimization algorithm that enables networked agents to solve optimization problems at different levels in a single timescale and share information through network propagation. Our algorithm achieves optimal sample complexity, scaling linearly with the network size, and demonstrates state-of-the-art performance on various applications, including hyper-parameter tuning, decentralized reinforcement learning, and risk-averse optimization.
Factuality Challenges in the Era of Large Language Models
Oct 10, 2023The emergence of tools based on Large Language Models (LLMs), such as OpenAI's ChatGPT, Microsoft's Bing Chat, and Google's Bard, has garnered immense public attention. These incredibly useful, natural-sounding tools mark significant advances in natural language generation, yet they exhibit a propensity to generate false, erroneous, or misleading content -- commonly referred to as "hallucinations." Moreover, LLMs can be exploited for malicious applications, such as generating false but credible-sounding content and profiles at scale. This poses a significant challenge to society in terms of the potential deception of users and the increasing dissemination of inaccurate information. In light of these risks, we explore the kinds of technological innovations, regulatory reforms, and AI literacy initiatives needed from fact-checkers, news organizations, and the broader research and policy communities. By identifying the risks, the imminent threats, and some viable solutions, we seek to shed light on navigating various aspects of veracity in the era of generative AI.
Distilling Inductive Bias: Knowledge Distillation Beyond Model Compression
Oct 10, 2023
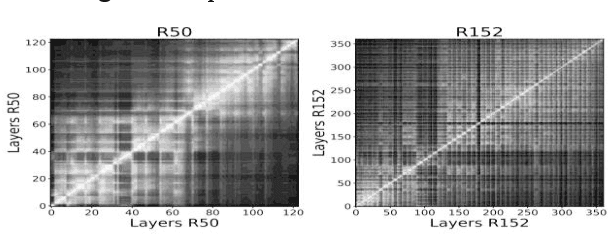
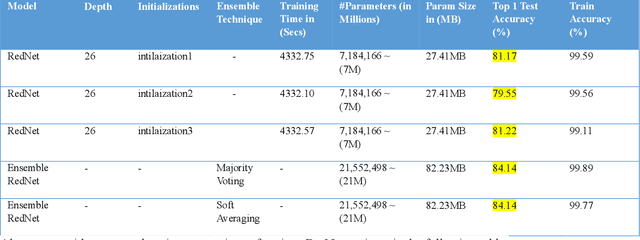

With the rapid development of computer vision, Vision Transformers (ViTs) offer the tantalizing prospect of unified information processing across visual and textual domains. But due to the lack of inherent inductive biases in ViTs, they require enormous amount of data for training. To make their applications practical, we introduce an innovative ensemble-based distillation approach distilling inductive bias from complementary lightweight teacher models. Prior systems relied solely on convolution-based teaching. However, this method incorporates an ensemble of light teachers with different architectural tendencies, such as convolution and involution, to instruct the student transformer jointly. Because of these unique inductive biases, instructors can accumulate a wide range of knowledge, even from readily identifiable stored datasets, which leads to enhanced student performance. Our proposed framework also involves precomputing and storing logits in advance, essentially the unnormalized predictions of the model. This optimization can accelerate the distillation process by eliminating the need for repeated forward passes during knowledge distillation, significantly reducing the computational burden and enhancing efficiency.
S4C: Self-Supervised Semantic Scene Completion with Neural Fields
Oct 12, 2023


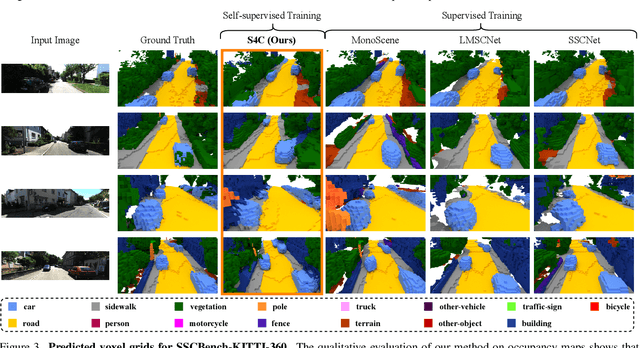
3D semantic scene understanding is a fundamental challenge in computer vision. It enables mobile agents to autonomously plan and navigate arbitrary environments. SSC formalizes this challenge as jointly estimating dense geometry and semantic information from sparse observations of a scene. Current methods for SSC are generally trained on 3D ground truth based on aggregated LiDAR scans. This process relies on special sensors and annotation by hand which are costly and do not scale well. To overcome this issue, our work presents the first self-supervised approach to SSC called S4C that does not rely on 3D ground truth data. Our proposed method can reconstruct a scene from a single image and only relies on videos and pseudo segmentation ground truth generated from off-the-shelf image segmentation network during training. Unlike existing methods, which use discrete voxel grids, we represent scenes as implicit semantic fields. This formulation allows querying any point within the camera frustum for occupancy and semantic class. Our architecture is trained through rendering-based self-supervised losses. Nonetheless, our method achieves performance close to fully supervised state-of-the-art methods. Additionally, our method demonstrates strong generalization capabilities and can synthesize accurate segmentation maps for far away viewpoints.
PoRF: Pose Residual Field for Accurate Neural Surface Reconstruction
Oct 12, 2023
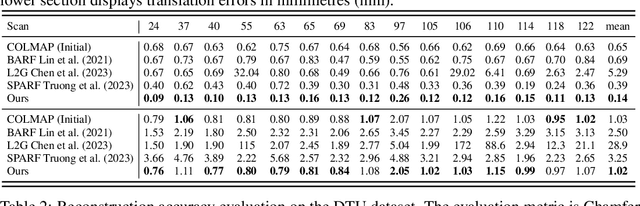
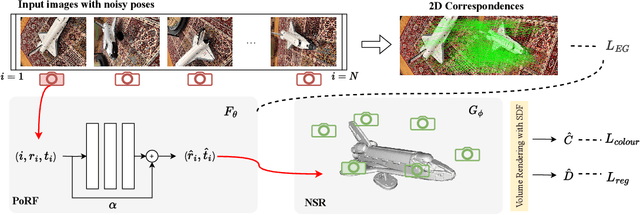
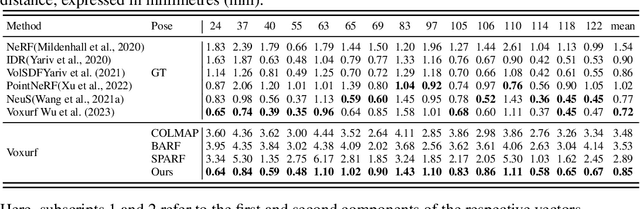
Neural surface reconstruction is sensitive to the camera pose noise, even if state-of-the-art pose estimators like COLMAP or ARKit are used. More importantly, existing Pose-NeRF joint optimisation methods have struggled to improve pose accuracy in challenging real-world scenarios. To overcome the challenges, we introduce the pose residual field (\textbf{PoRF}), a novel implicit representation that uses an MLP for regressing pose updates. This is more robust than the conventional pose parameter optimisation due to parameter sharing that leverages global information over the entire sequence. Furthermore, we propose an epipolar geometry loss to enhance the supervision that leverages the correspondences exported from COLMAP results without the extra computational overhead. Our method yields promising results. On the DTU dataset, we reduce the rotation error by 78\% for COLMAP poses, leading to the decreased reconstruction Chamfer distance from 3.48mm to 0.85mm. On the MobileBrick dataset that contains casually captured unbounded 360-degree videos, our method refines ARKit poses and improves the reconstruction F1 score from 69.18 to 75.67, outperforming that with the dataset provided ground-truth pose (75.14). These achievements demonstrate the efficacy of our approach in refining camera poses and improving the accuracy of neural surface reconstruction in real-world scenarios.
Beyond Sharing Weights in Decoupling Feature Learning Network for UAV RGB-Infrared Vehicle Re-Identification
Oct 12, 2023

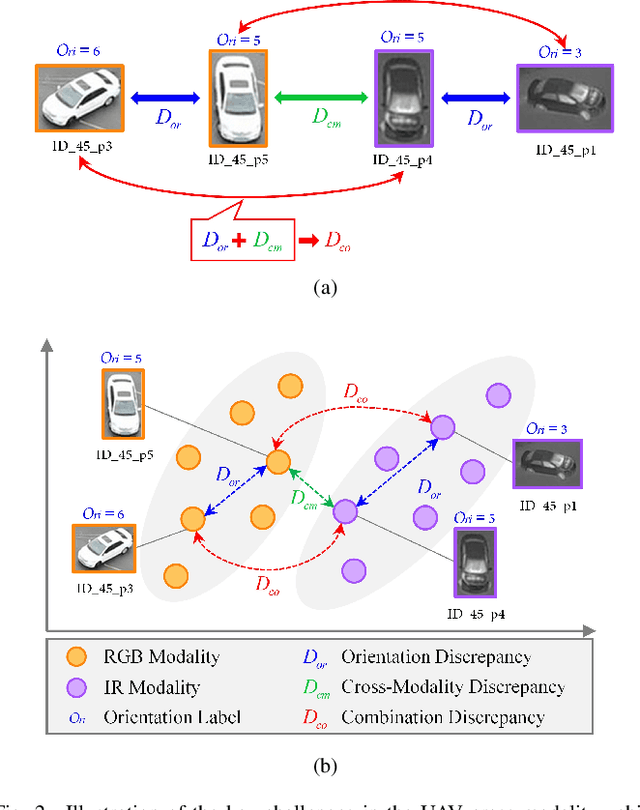

Owing to the capacity of performing full-time target search, cross-modality vehicle re-identification (Re-ID) based on unmanned aerial vehicle (UAV) is gaining more attention in both video surveillance and public security. However, this promising and innovative research has not been studied sufficiently due to the data inadequacy issue. Meanwhile, the cross-modality discrepancy and orientation discrepancy challenges further aggravate the difficulty of this task. To this end, we pioneer a cross-modality vehicle Re-ID benchmark named UAV Cross-Modality Vehicle Re-ID (UCM-VeID), containing 753 identities with 16015 RGB and 13913 infrared images. Moreover, to meet cross-modality discrepancy and orientation discrepancy challenges, we present a hybrid weights decoupling network (HWDNet) to learn the shared discriminative orientation-invariant features. For the first challenge, we proposed a hybrid weights siamese network with a well-designed weight restrainer and its corresponding objective function to learn both modality-specific and modality shared information. In terms of the second challenge, three effective decoupling structures with two pretext tasks are investigated to learn orientation-invariant feature. Comprehensive experiments are carried out to validate the effectiveness of the proposed method. The dataset and codes will be released at https://github.com/moonstarL/UAV-CM-VeID.
Low Complexity Algorithms for Mission Completion Time Minimization in UAV-Based ISAC Systems
Oct 12, 2023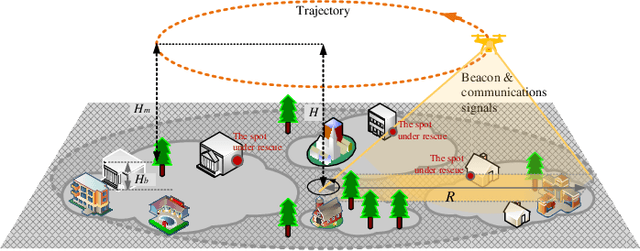
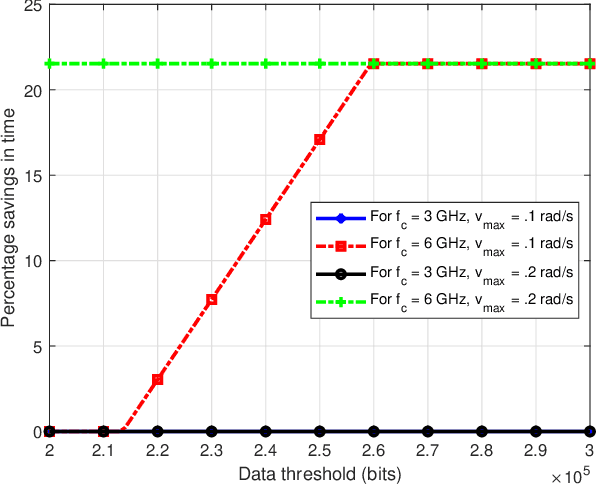
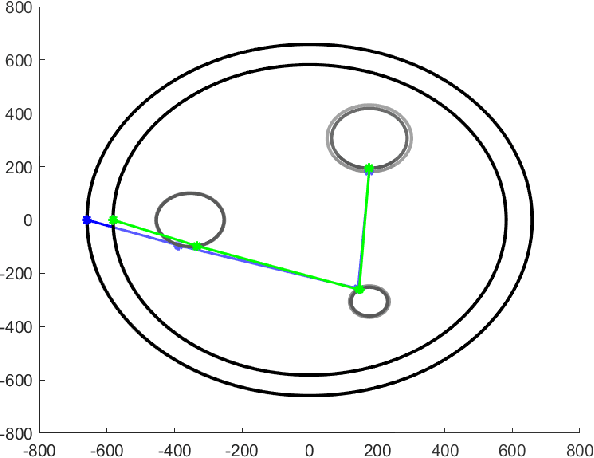
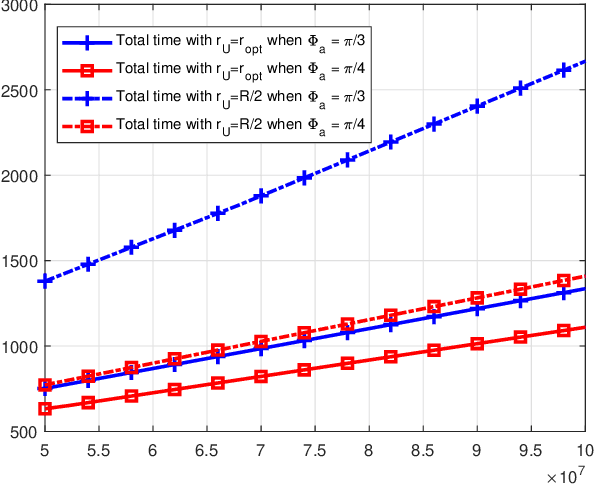
The inherent support of sixth-generation (6G) systems enabling integrated sensing and communications (ISAC) paradigm greatly enhances the application area of intelligent transportation systems (ITS). One of the mission-critical applications enabled by these systems is disaster management, where ISAC functionality may not only provide localization but also provide users with supplementary information such as escape routes, time to rescue, etc. In this paper, by considering a large area with several locations of interest, we formulate and solve the optimization problem of delivering task parameters of the ISAC system by optimizing the UAV speed and the order of visits to the locations of interest such that the mission time is minimized. The formulated problem is a mixed integer non-linear program which is quite challenging to solve. To reduce the complexity of the solution algorithms, we propose two circular trajectory designs. The first algorithm finds the optimal UAV velocity and radius of the circular trajectories. The second algorithm finds the optimal connecting points for joining the individual circular trajectories. Our numerical results reveal that, with practical simulation parameters, the first algorithm provides a time saving of at least $20\%$, while the second algorithm cuts down the total completion time by at least $7$ times.
Hilbert Space Embedding-based Trajectory Optimization for Multi-Modal Uncertain Obstacle Trajectory Prediction
Oct 12, 2023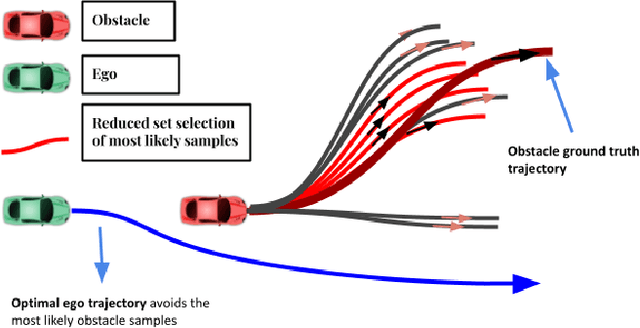

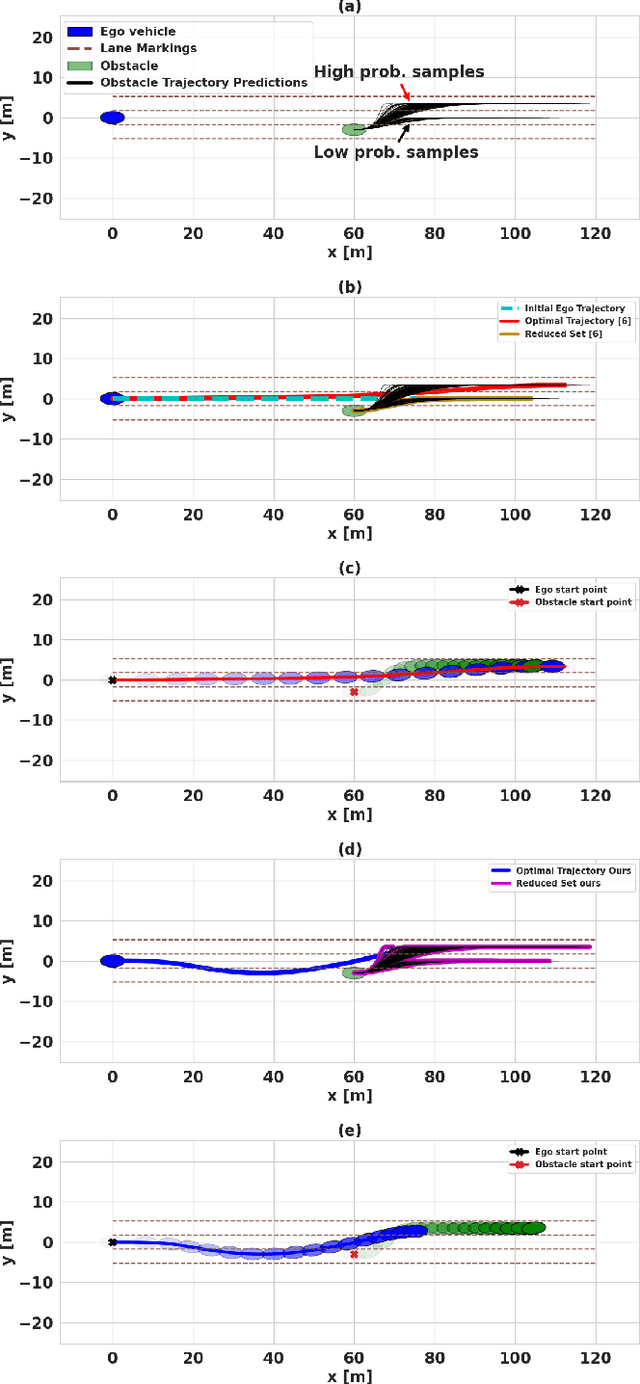
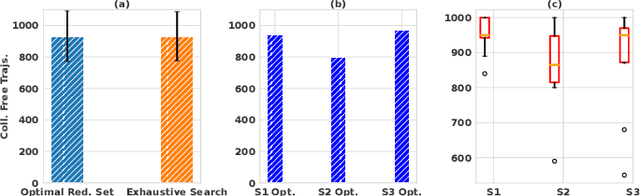
Safe autonomous driving critically depends on how well the ego-vehicle can predict the trajectories of neighboring vehicles. To this end, several trajectory prediction algorithms have been presented in the existing literature. Many of these approaches output a multi-modal distribution of obstacle trajectories instead of a single deterministic prediction to account for the underlying uncertainty. However, existing planners cannot handle the multi-modality based on just sample-level information of the predictions. With this motivation, this paper proposes a trajectory optimizer that can leverage the distributional aspects of the prediction in a computationally tractable and sample-efficient manner. Our optimizer can work with arbitrarily complex distributions and thus can be used with output distribution represented as a deep neural network. The core of our approach is built on embedding distribution in Reproducing Kernel Hilbert Space (RKHS), which we leverage in two ways. First, we propose an RKHS embedding approach to select probable samples from the obstacle trajectory distribution. Second, we rephrase chance-constrained optimization as distribution matching in RKHS and propose a novel sampling-based optimizer for its solution. We validate our approach with hand-crafted and neural network-based predictors trained on real-world datasets and show improvement over the existing stochastic optimization approaches in safety metrics.