 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
High-Fidelity 3D Head Avatars Reconstruction through Spatially-Varying Expression Conditioned Neural Radiance Field
Oct 10, 2023
One crucial aspect of 3D head avatar reconstruction lies in the details of facial expressions. Although recent NeRF-based photo-realistic 3D head avatar methods achieve high-quality avatar rendering, they still encounter challenges retaining intricate facial expression details because they overlook the potential of specific expression variations at different spatial positions when conditioning the radiance field. Motivated by this observation, we introduce a novel Spatially-Varying Expression (SVE) conditioning. The SVE can be obtained by a simple MLP-based generation network, encompassing both spatial positional features and global expression information. Benefiting from rich and diverse information of the SVE at different positions, the proposed SVE-conditioned neural radiance field can deal with intricate facial expressions and achieve realistic rendering and geometry details of high-fidelity 3D head avatars. Additionally, to further elevate the geometric and rendering quality, we introduce a new coarse-to-fine training strategy, including a geometry initialization strategy at the coarse stage and an adaptive importance sampling strategy at the fine stage. Extensive experiments indicate that our method outperforms other state-of-the-art (SOTA) methods in rendering and geometry quality on mobile phone-collected and public datasets.
Joint Coding-Modulation for Digital Semantic Communications via Variational Autoencoder
Oct 10, 2023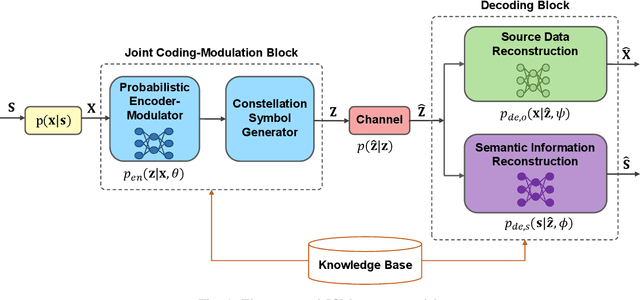
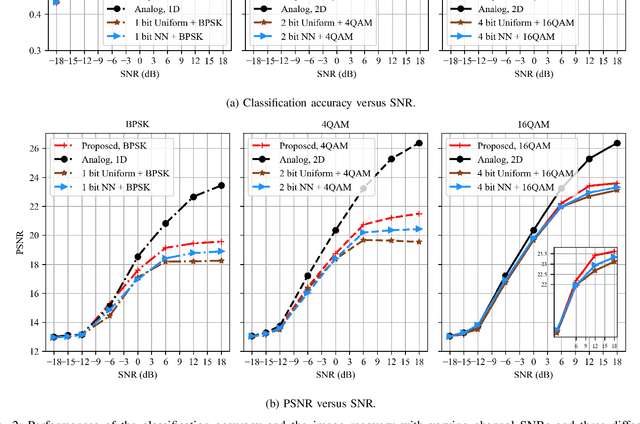

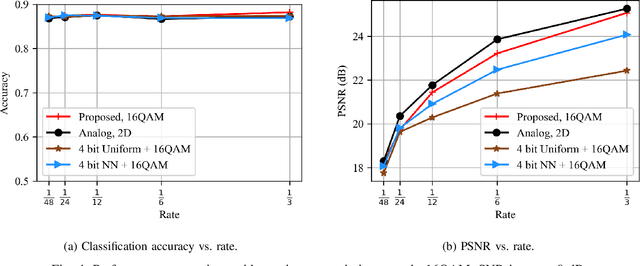
Semantic communications have emerged as a new paradigm for improving communication efficiency by transmitting the semantic information of a source message that is most relevant to a desired task at the receiver. Most existing approaches typically utilize neural networks (NNs) to design end-to-end semantic communication systems, where NN-based semantic encoders output continuously distributed signals to be sent directly to the channel in an analog communication fashion. In this work, we propose a joint coding-modulation framework for digital semantic communications by using variational autoencoder (VAE). Our approach learns the transition probability from source data to discrete constellation symbols, thereby avoiding the non-differentiability problem of digital modulation. Meanwhile, by jointly designing the coding and modulation process together, we can match the obtained modulation strategy with the operating channel condition. We also derive a matching loss function with information-theoretic meaning for end-to-end training. Experiments conducted on image semantic communication validate that our proposed joint coding-modulation framework outperforms separate design of semantic coding and modulation under various channel conditions, transmission rates, and modulation orders. Furthermore, its performance gap to analog semantic communication reduces as the modulation order increases while enjoying the hardware implementation convenience.
Revisiting Mobility Modeling with Graph: A Graph Transformer Model for Next Point-of-Interest Recommendation
Oct 02, 2023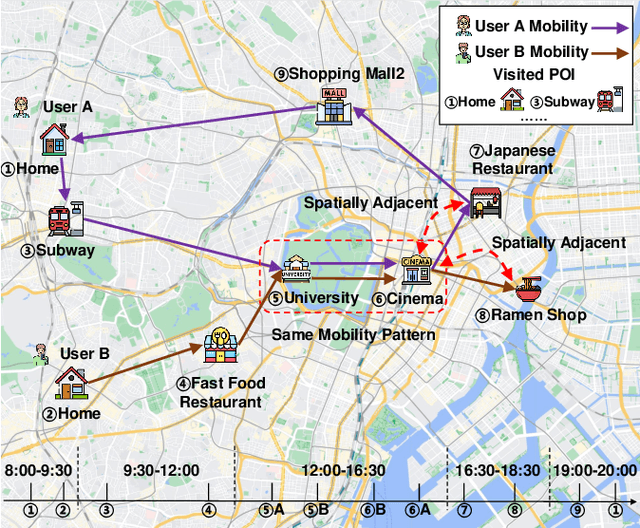
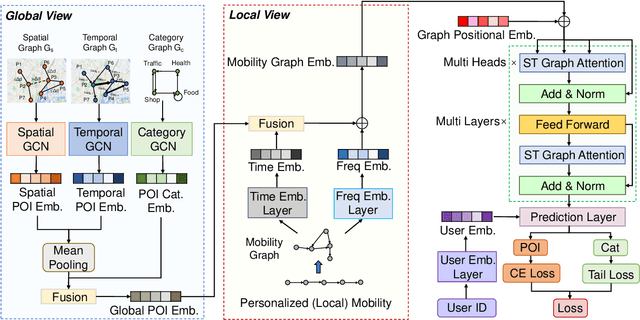
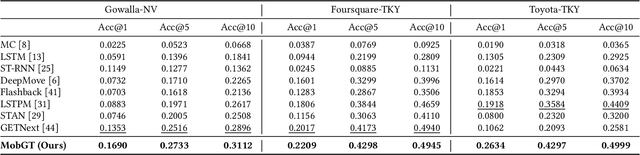
Next Point-of-Interest (POI) recommendation plays a crucial role in urban mobility applications. Recently, POI recommendation models based on Graph Neural Networks (GNN) have been extensively studied and achieved, however, the effective incorporation of both spatial and temporal information into such GNN-based models remains challenging. Extracting distinct fine-grained features unique to each piece of information is difficult since temporal information often includes spatial information, as users tend to visit nearby POIs. To address the challenge, we propose \textbf{\underline{Mob}}ility \textbf{\underline{G}}raph \textbf{\underline{T}}ransformer (MobGT) that enables us to fully leverage graphs to capture both the spatial and temporal features in users' mobility patterns. MobGT combines individual spatial and temporal graph encoders to capture unique features and global user-location relations. Additionally, it incorporates a mobility encoder based on Graph Transformer to extract higher-order information between POIs. To address the long-tailed problem in spatial-temporal data, MobGT introduces a novel loss function, Tail Loss. Experimental results demonstrate that MobGT outperforms state-of-the-art models on various datasets and metrics, achieving 24\% improvement on average. Our codes are available at \url{https://github.com/Yukayo/MobGT}.
Can LSH (Locality-Sensitive Hashing) Be Replaced by Neural Network?
Oct 15, 2023With the rapid development of GPU (Graphics Processing Unit) technologies and neural networks, we can explore more appropriate data structures and algorithms. Recent progress shows that neural networks can partly replace traditional data structures. In this paper, we proposed a novel DNN (Deep Neural Network)-based learned locality-sensitive hashing, called LLSH, to efficiently and flexibly map high-dimensional data to low-dimensional space. LLSH replaces the traditional LSH (Locality-sensitive Hashing) function families with parallel multi-layer neural networks, which reduces the time and memory consumption and guarantees query accuracy simultaneously. The proposed LLSH demonstrate the feasibility of replacing the hash index with learning-based neural networks and open a new door for developers to design and configure data organization more accurately to improve information-searching performance. Extensive experiments on different types of datasets show the superiority of the proposed method in query accuracy, time consumption, and memory usage.
VLIS: Unimodal Language Models Guide Multimodal Language Generation
Oct 15, 2023Multimodal language generation, which leverages the synergy of language and vision, is a rapidly expanding field. However, existing vision-language models face challenges in tasks that require complex linguistic understanding. To address this issue, we introduce Visual-Language models as Importance Sampling weights (VLIS), a novel framework that combines the visual conditioning capability of vision-language models with the language understanding of unimodal text-only language models without further training. It extracts pointwise mutual information of each image and text from a visual-language model and uses the value as an importance sampling weight to adjust the token likelihood from a text-only model. VLIS improves vision-language models on diverse tasks, including commonsense understanding (WHOOPS, OK-VQA, and ScienceQA) and complex text generation (Concadia, Image Paragraph Captioning, and ROCStories). Our results suggest that VLIS represents a promising new direction for multimodal language generation.
Localizing and Editing Knowledge in Text-to-Image Generative Models
Oct 20, 2023Text-to-Image Diffusion Models such as Stable-Diffusion and Imagen have achieved unprecedented quality of photorealism with state-of-the-art FID scores on MS-COCO and other generation benchmarks. Given a caption, image generation requires fine-grained knowledge about attributes such as object structure, style, and viewpoint amongst others. Where does this information reside in text-to-image generative models? In our paper, we tackle this question and understand how knowledge corresponding to distinct visual attributes is stored in large-scale text-to-image diffusion models. We adapt Causal Mediation Analysis for text-to-image models and trace knowledge about distinct visual attributes to various (causal) components in the (i) UNet and (ii) text-encoder of the diffusion model. In particular, we show that unlike generative large-language models, knowledge about different attributes is not localized in isolated components, but is instead distributed amongst a set of components in the conditional UNet. These sets of components are often distinct for different visual attributes. Remarkably, we find that the CLIP text-encoder in public text-to-image models such as Stable-Diffusion contains only one causal state across different visual attributes, and this is the first self-attention layer corresponding to the last subject token of the attribute in the caption. This is in stark contrast to the causal states in other language models which are often the mid-MLP layers. Based on this observation of only one causal state in the text-encoder, we introduce a fast, data-free model editing method Diff-QuickFix which can effectively edit concepts in text-to-image models. DiffQuickFix can edit (ablate) concepts in under a second with a closed-form update, providing a significant 1000x speedup and comparable editing performance to existing fine-tuning based editing methods.
Identification of Abnormality in Maize Plants From UAV Images Using Deep Learning Approaches
Oct 20, 2023Early identification of abnormalities in plants is an important task for ensuring proper growth and achieving high yields from crops. Precision agriculture can significantly benefit from modern computer vision tools to make farming strategies addressing these issues efficient and effective. As farming lands are typically quite large, farmers have to manually check vast areas to determine the status of the plants and apply proper treatments. In this work, we consider the problem of automatically identifying abnormal regions in maize plants from images captured by a UAV. Using deep learning techniques, we have developed a methodology which can detect different levels of abnormality (i.e., low, medium, high or no abnormality) in maize plants independently of their growth stage. The primary goal is to identify anomalies at the earliest possible stage in order to maximize the effectiveness of potential treatments. At the same time, the proposed system can provide valuable information to human annotators for ground truth data collection by helping them to focus their attention on a much smaller set of images only. We have experimented with two different but complimentary approaches, the first considering abnormality detection as a classification problem and the second considering it as a regression problem. Both approaches can be generalized to different types of abnormalities and do not make any assumption about the abnormality occurring at an early plant growth stage which might be easier to detect due to the plants being smaller and easier to separate. As a case study, we have considered a publicly available data set which exhibits mostly Nitrogen deficiency in maize plants of various growth stages. We are reporting promising preliminary results with an 88.89\% detection accuracy of low abnormality and 100\% detection accuracy of no abnormality.
Towards Real-Time Neural Video Codec for Cross-Platform Application Using Calibration Information
Sep 20, 2023
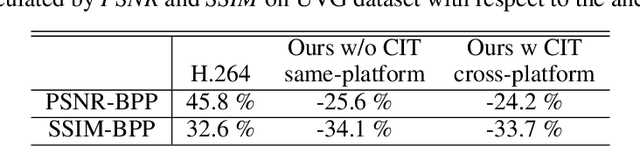
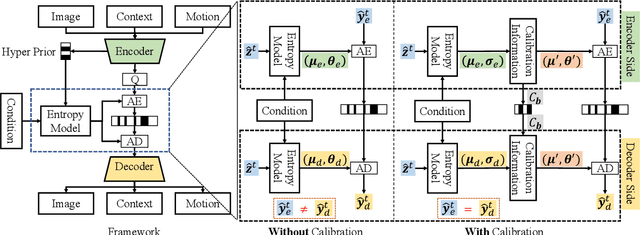

The state-of-the-art neural video codecs have outperformed the most sophisticated traditional codecs in terms of RD performance in certain cases. However, utilizing them for practical applications is still challenging for two major reasons. 1) Cross-platform computational errors resulting from floating point operations can lead to inaccurate decoding of the bitstream. 2) The high computational complexity of the encoding and decoding process poses a challenge in achieving real-time performance. In this paper, we propose a real-time cross-platform neural video codec, which is capable of efficiently decoding of 720P video bitstream from other encoding platforms on a consumer-grade GPU. First, to solve the problem of inconsistency of codec caused by the uncertainty of floating point calculations across platforms, we design a calibration transmitting system to guarantee the consistent quantization of entropy parameters between the encoding and decoding stages. The parameters that may have transboundary quantization between encoding and decoding are identified in the encoding stage, and their coordinates will be delivered by auxiliary transmitted bitstream. By doing so, these inconsistent parameters can be processed properly in the decoding stage. Furthermore, to reduce the bitrate of the auxiliary bitstream, we rectify the distribution of entropy parameters using a piecewise Gaussian constraint. Second, to match the computational limitations on the decoding side for real-time video codec, we design a lightweight model. A series of efficiency techniques enable our model to achieve 25 FPS decoding speed on NVIDIA RTX 2080 GPU. Experimental results demonstrate that our model can achieve real-time decoding of 720P videos while encoding on another platform. Furthermore, the real-time model brings up to a maximum of 24.2\% BD-rate improvement from the perspective of PSNR with the anchor H.265.
Low-Resolution Self-Attention for Semantic Segmentation
Oct 08, 2023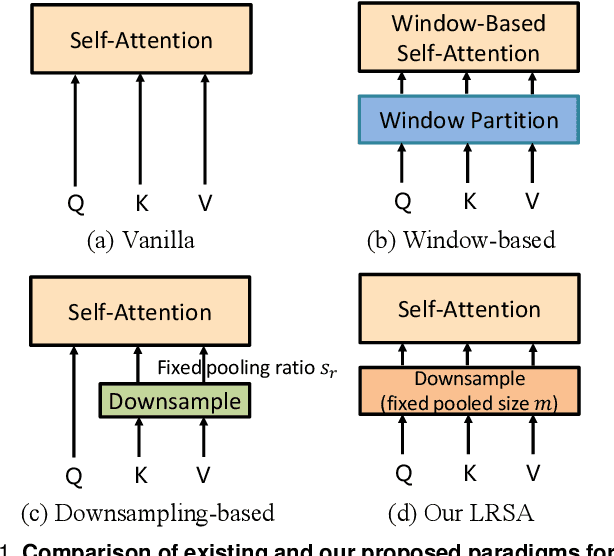
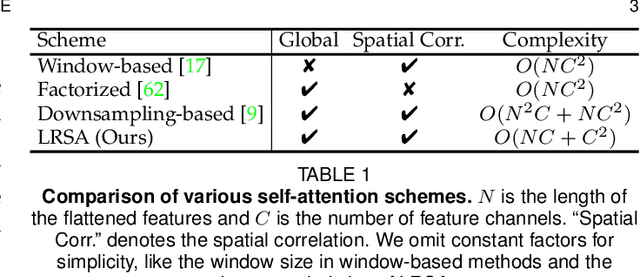
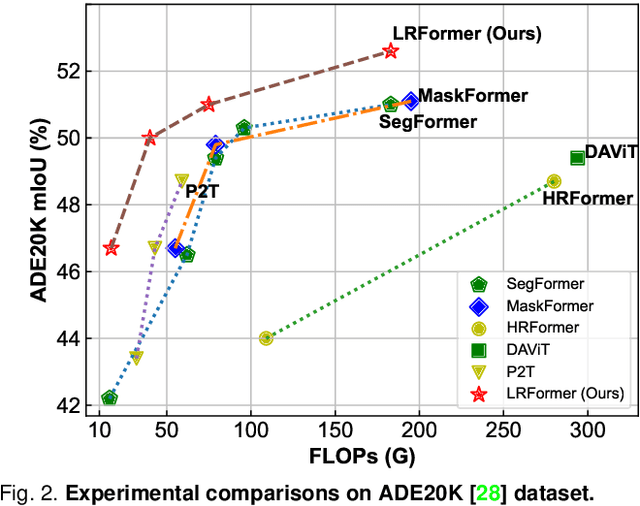

Semantic segmentation tasks naturally require high-resolution information for pixel-wise segmentation and global context information for class prediction. While existing vision transformers demonstrate promising performance, they often utilize high resolution context modeling, resulting in a computational bottleneck. In this work, we challenge conventional wisdom and introduce the Low-Resolution Self-Attention (LRSA) mechanism to capture global context at a significantly reduced computational cost. Our approach involves computing self-attention in a fixed low-resolution space regardless of the input image's resolution, with additional 3x3 depth-wise convolutions to capture fine details in the high-resolution space. We demonstrate the effectiveness of our LRSA approach by building the LRFormer, a vision transformer with an encoder-decoder structure. Extensive experiments on the ADE20K, COCO-Stuff, and Cityscapes datasets demonstrate that LRFormer outperforms state-of-the-art models. The code will be made available at https://github.com/yuhuan-wu/LRFormer.
Indoor Localization for an Autonomous Model Car: A Marker-Based Multi-Sensor Fusion Framework
Oct 08, 2023
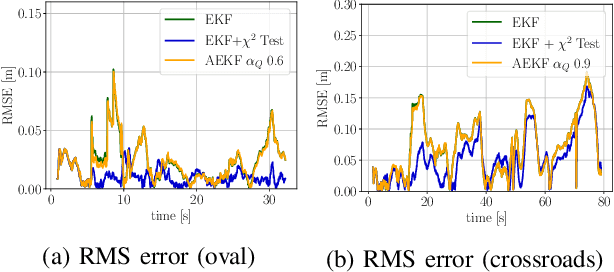
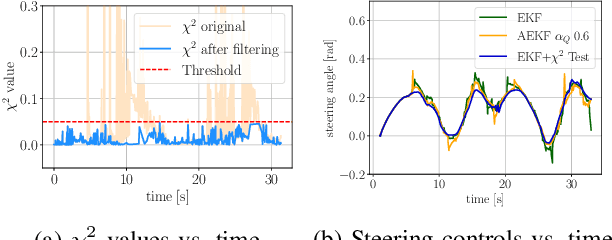

Global navigation satellite systems readily provide accurate position information when localizing a robot outdoors. However, an analogous standard solution does not exist yet for mobile robots operating indoors. This paper presents an integrated framework for indoor localization and experimental validation of an autonomous driving system based on an advanced driver-assistance system (ADAS) model car. The global pose of the model car is obtained by fusing information from fiducial markers, inertial sensors and wheel odometry. In order to achieve robust localization, we investigate and compare two extensions to the Extended Kalman Filter; first with adaptive noise tuning and second with Chi-squared test for measurement outlier detection. An efficient and low-cost ground truth measurement method using a single LiDAR sensor is also proposed to validate the results. The performance of the localization algorithms is tested on a complete autonomous driving system with trajectory planning and model predictive control.