 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AutoCycle-VC: Towards Bottleneck-Independent Zero-Shot Cross-Lingual Voice Conversion
Oct 10, 2023
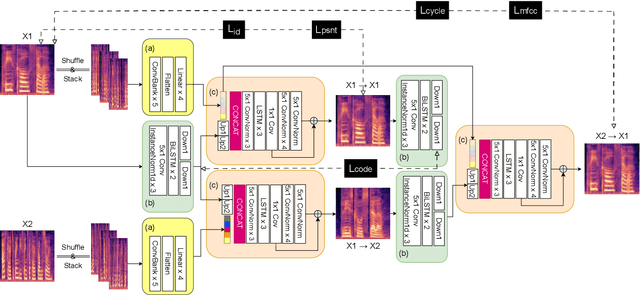
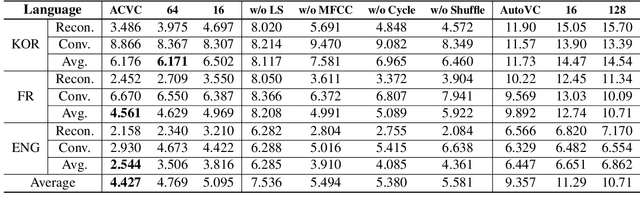
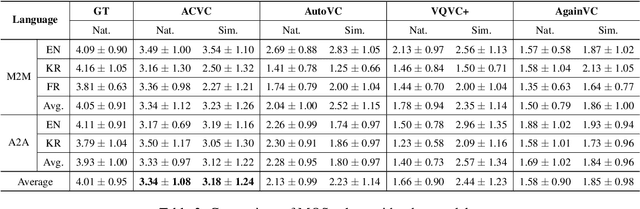

This paper proposes a simple and robust zero-shot voice conversion system with a cycle structure and mel-spectrogram pre-processing. Previous works suffer from information loss and poor synthesis quality due to their reliance on a carefully designed bottleneck structure. Moreover, models relying solely on self-reconstruction loss struggled with reproducing different speakers' voices. To address these issues, we suggested a cycle-consistency loss that considers conversion back and forth between target and source speakers. Additionally, stacked random-shuffled mel-spectrograms and a label smoothing method are utilized during speaker encoder training to extract a time-independent global speaker representation from speech, which is the key to a zero-shot conversion. Our model outperforms existing state-of-the-art results in both subjective and objective evaluations. Furthermore, it facilitates cross-lingual voice conversions and enhances the quality of synthesized speech.
Integrating Contrastive Learning into a Multitask Transformer Model for Effective Domain Adaptation
Oct 07, 2023While speech emotion recognition (SER) research has made significant progress, achieving generalization across various corpora continues to pose a problem. We propose a novel domain adaptation technique that embodies a multitask framework with SER as the primary task, and contrastive learning and information maximisation loss as auxiliary tasks, underpinned by fine-tuning of transformers pre-trained on large language models. Empirical results obtained through experiments on well-established datasets like IEMOCAP and MSP-IMPROV, illustrate that our proposed model achieves state-of-the-art performance in SER within cross-corpus scenarios.
Pubic Symphysis-Fetal Head Segmentation Using Pure Transformer with Bi-level Routing Attention
Oct 07, 2023In this paper, we propose a method, named BRAU-Net, to solve the pubic symphysis-fetal head segmentation task. The method adopts a U-Net-like pure Transformer architecture with bi-level routing attention and skip connections, which effectively learns local-global semantic information. The proposed BRAU-Net was evaluated on transperineal Ultrasound images dataset from the pubic symphysis-fetal head segmentation and angle of progression (FH-PS-AOP) challenge. The results demonstrate that the proposed BRAU-Net achieves comparable a final score. The codes will be available at https://github.com/Caipengzhou/BRAU-Net.
Leveraging Large Language Models (LLMs) to Empower Training-Free Dataset Condensation for Content-Based Recommendation
Oct 15, 2023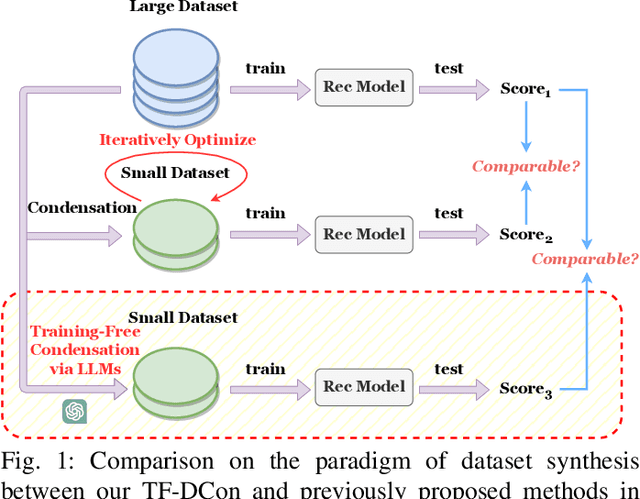
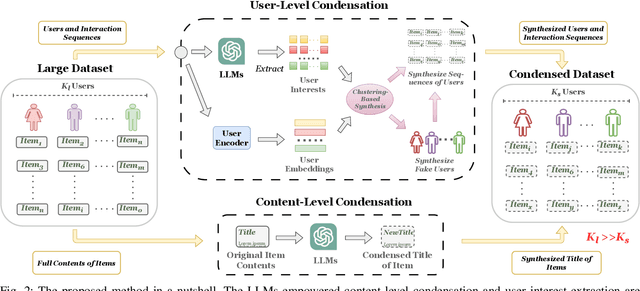

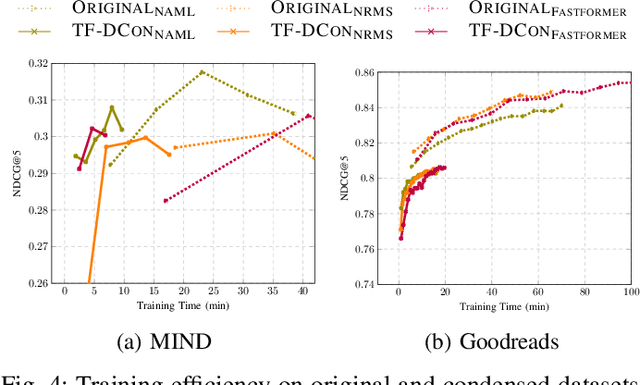
Modern techniques in Content-based Recommendation (CBR) leverage item content information to provide personalized services to users, but suffer from resource-intensive training on large datasets. To address this issue, we explore the dataset condensation for textual CBR in this paper. The goal of dataset condensation is to synthesize a small yet informative dataset, upon which models can achieve performance comparable to those trained on large datasets. While existing condensation approaches are tailored to classification tasks for continuous data like images or embeddings, direct application of them to CBR has limitations. To bridge this gap, we investigate efficient dataset condensation for content-based recommendation. Inspired by the remarkable abilities of large language models (LLMs) in text comprehension and generation, we leverage LLMs to empower the generation of textual content during condensation. To handle the interaction data involving both users and items, we devise a dual-level condensation method: content-level and user-level. At content-level, we utilize LLMs to condense all contents of an item into a new informative title. At user-level, we design a clustering-based synthesis module, where we first utilize LLMs to extract user interests. Then, the user interests and user embeddings are incorporated to condense users and generate interactions for condensed users. Notably, the condensation paradigm of this method is forward and free from iterative optimization on the synthesized dataset. Extensive empirical findings from our study, conducted on three authentic datasets, substantiate the efficacy of the proposed method. Particularly, we are able to approximate up to 97% of the original performance while reducing the dataset size by 95% (i.e., on dataset MIND).
CAW-coref: Conjunction-Aware Word-level Coreference Resolution
Oct 09, 2023State-of-the-art coreference resolutions systems depend on multiple LLM calls per document and are thus prohibitively expensive for many use cases (e.g., information extraction with large corpora). The leading word-level coreference system (WL-coref) attains 96.6% of these SOTA systems' performance while being much more efficient. In this work, we identify a routine yet important failure case of WL-coref: dealing with conjoined mentions such as 'Tom and Mary'. We offer a simple yet effective solution that improves the performance on the OntoNotes test set by 0.9% F1, shrinking the gap between efficient word-level coreference resolution and expensive SOTA approaches by 34.6%. Our Conjunction-Aware Word-level coreference model (CAW-coref) and code is available at https://github.com/KarelDO/wl-coref.
Unlearning with Fisher Masking
Oct 09, 2023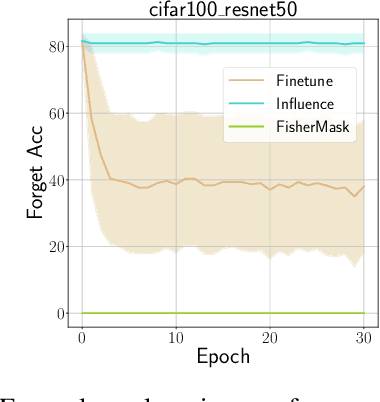
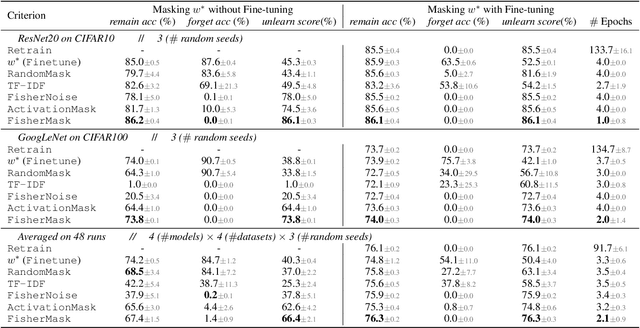

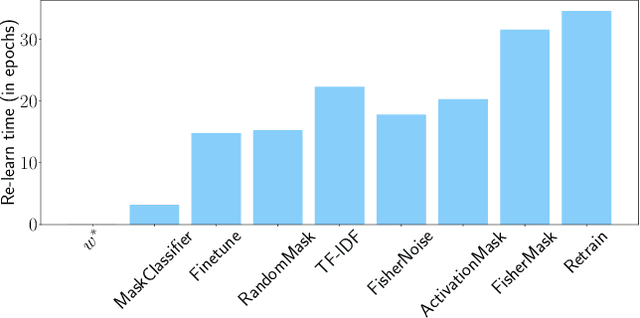
Machine unlearning aims to revoke some training data after learning in response to requests from users, model developers, and administrators. Most previous methods are based on direct fine-tuning, which may neither remove data completely nor retain full performances on the remain data. In this work, we find that, by first masking some important parameters before fine-tuning, the performances of unlearning could be significantly improved. We propose a new masking strategy tailored to unlearning based on Fisher information. Experiments on various datasets and network structures show the effectiveness of the method: without any fine-tuning, the proposed Fisher masking could unlearn almost completely while maintaining most of the performance on the remain data. It also exhibits stronger stability compared to other unlearning baselines
LD4MRec: Simplifying and Powering Diffusion Model for Multimedia Recommendation
Sep 27, 2023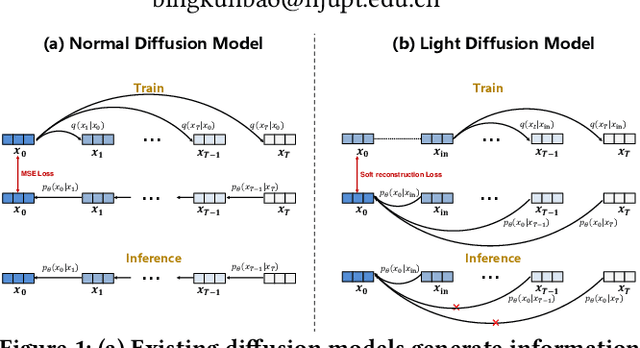
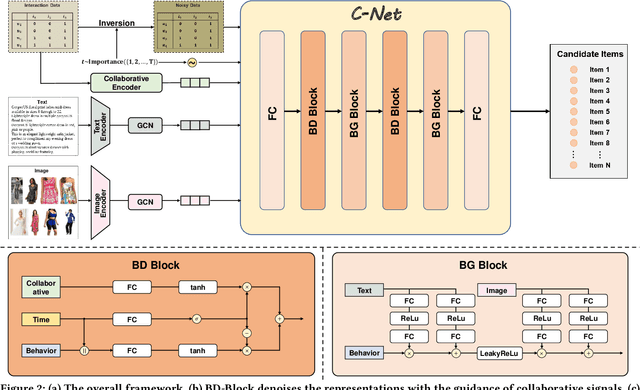
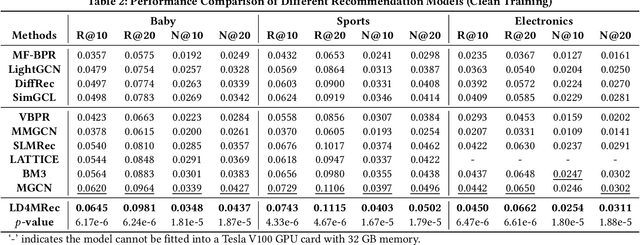
Multimedia recommendation aims to predict users' future behaviors based on historical behavioral data and item's multimodal information. However, noise inherent in behavioral data, arising from unintended user interactions with uninteresting items, detrimentally impacts recommendation performance. Recently, diffusion models have achieved high-quality information generation, in which the reverse process iteratively infers future information based on the corrupted state. It meets the need of predictive tasks under noisy conditions, and inspires exploring their application to predicting user behaviors. Nonetheless, several challenges must be addressed: 1) Classical diffusion models require excessive computation, which does not meet the efficiency requirements of recommendation systems. 2) Existing reverse processes are mainly designed for continuous data, whereas behavioral information is discrete in nature. Therefore, an effective method is needed for the generation of discrete behavioral information. To tackle the aforementioned issues, we propose a Light Diffusion model for Multimedia Recommendation. First, to reduce computational complexity, we simplify the formula of the reverse process, enabling one-step inference instead of multi-step inference. Second, to achieve effective behavioral information generation, we propose a novel Conditional neural Network. It maps the discrete behavior data into a continuous latent space, and generates behaviors with the guidance of collaborative signals and user multimodal preference. Additionally, considering that completely clean behavior data is inaccessible, we introduce a soft behavioral reconstruction constraint during model training, facilitating behavior prediction with noisy data. Empirical studies conducted on three public datasets demonstrate the effectiveness of LD4MRec.
Graph-based Simultaneous Localization and Bias Tracking
Oct 05, 2023We present a factor graph formulation and particle-based sum-product algorithm for robust localization and tracking in multipath-prone environments. The proposed sequential algorithm jointly estimates the mobile agent's position together with a time-varying number of multipath components (MPCs). The MPCs are represented by "delay biases" corresponding to the offset between line-of-sight (LOS) component delay and the respective delays of all detectable MPCs. The delay biases of the MPCs capture the geometric features of the propagation environment with respect to the mobile agent. Therefore, they can provide position-related information contained in the MPCs without explicitly building a map of the environment. We demonstrate that the position-related information enables the algorithm to provide high-accuracy position estimates even in fully obstructed line-of-sight (OLOS) situations. Using simulated and real measurements in different scenarios we demonstrate the proposed algorithm to significantly outperform state-of-the-art multipath-aided tracking algorithms and show that the performance of our algorithm constantly attains the posterior Cramer-Rao lower bound (P-CRLB). Furthermore, we demonstrate the implicit capability of the proposed method to identify unreliable measurements and, thus, to mitigate lost tracks.
Speaker localization using direct path dominance test based on sound field directivity
Oct 05, 2023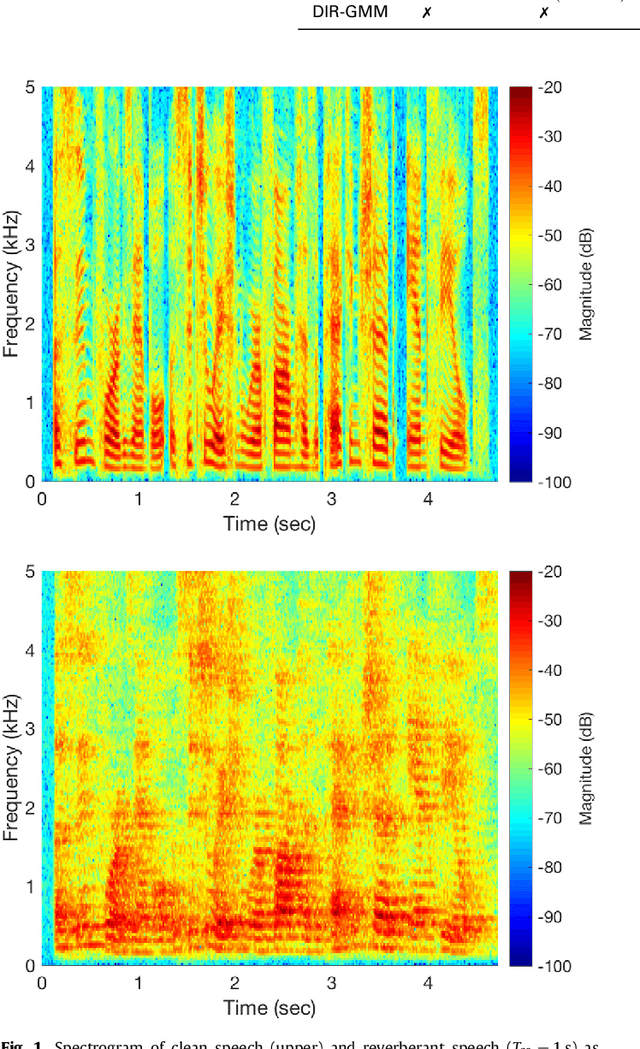
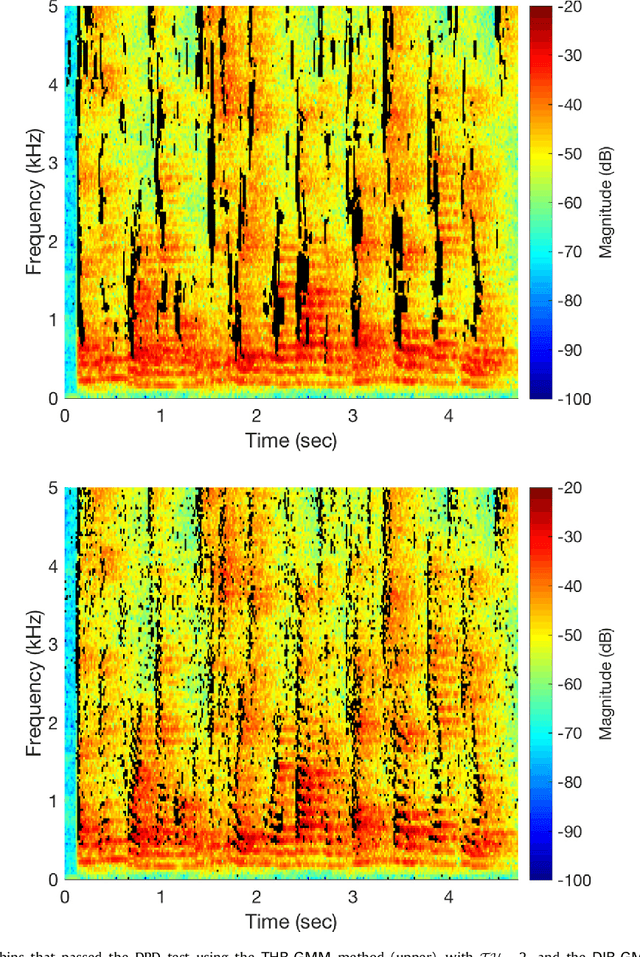

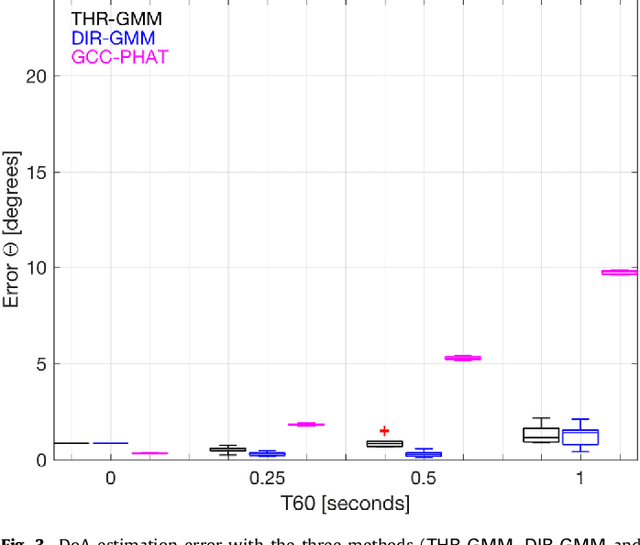
Estimation of the direction-of-arrival (DoA) of a speaker in a room is important in many audio signal processing applications. Environments with reverberation that masks the DoA information are particularly challenging. Recently, a DoA estimation method that is robust to reverberation has been developed. This method identifies time-frequency bins dominated by the contribution from the direct path, which carries the correct DoA information. However, its implementation is computationally demanding as it requires frequency smoothing to overcome the effect of coherent early reflections and matrix decomposition to apply the direct-path dominance (DPD) test. In this work, a novel computationally-efficient alternative to the DPD test is proposed, based on the directivity measure for sensor arrays, which requires neither frequency smoothing nor matrix decomposition, and which has been reformulated for sound field directivity with spherical microphone arrays. The paper presents the proposed method and a comparison to previous methods under a range of reverberation and noise conditions. Result demonstrate that the proposed method shows comparable performance to the original method in terms of robustness to reverberation and noise, and is about four times more computationally efficient for the given experiment.
LatEval: An Interactive LLMs Evaluation Benchmark with Incomplete Information from Lateral Thinking Puzzles
Aug 21, 2023
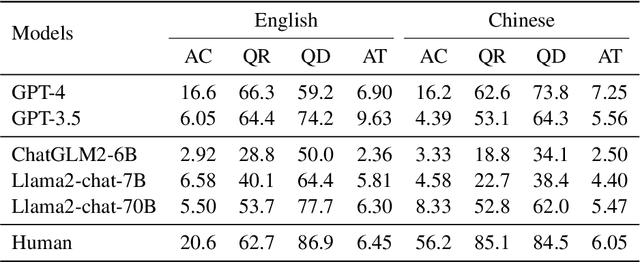
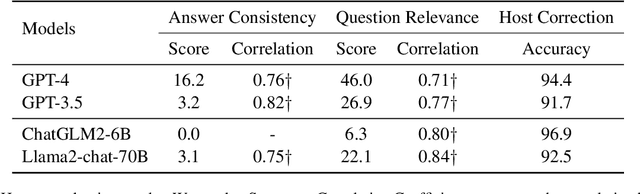
With the continuous evolution and refinement of LLMs, they are endowed with impressive logical reasoning or vertical thinking capabilities. But can they think out of the box? Do they possess proficient lateral thinking abilities? Following the setup of Lateral Thinking Puzzles, we propose a novel evaluation benchmark, LatEval, which assesses the model's lateral thinking within an interactive framework. In our benchmark, we challenge LLMs with 2 aspects: the quality of questions posed by the model and the model's capability to integrate information for problem-solving. We find that nearly all LLMs struggle with employing lateral thinking during interactions. For example, even the most advanced model, GPT-4, exhibits the advantage to some extent, yet still maintain a noticeable gap when compared to human. This evaluation benchmark provides LLMs with a highly challenging and distinctive task that is crucial to an effective AI assistant.