 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Leveraging Large Language Models (LLMs) to Empower Training-Free Dataset Condensation for Content-Based Recommendation
Oct 15, 2023
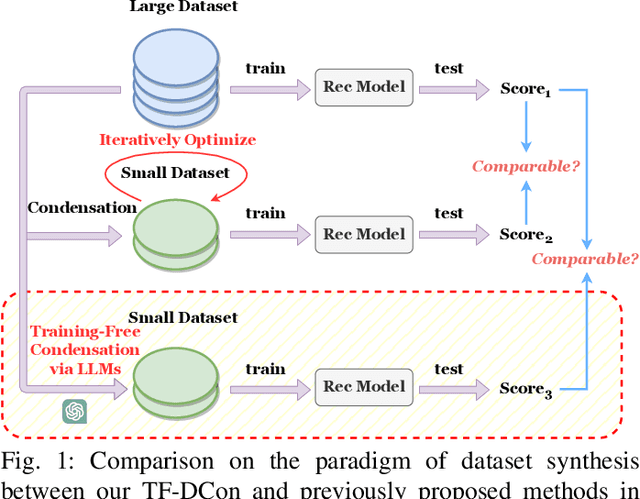
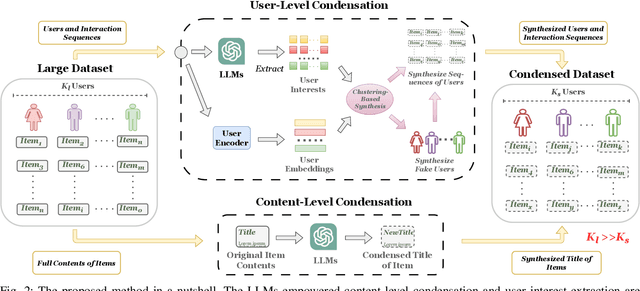

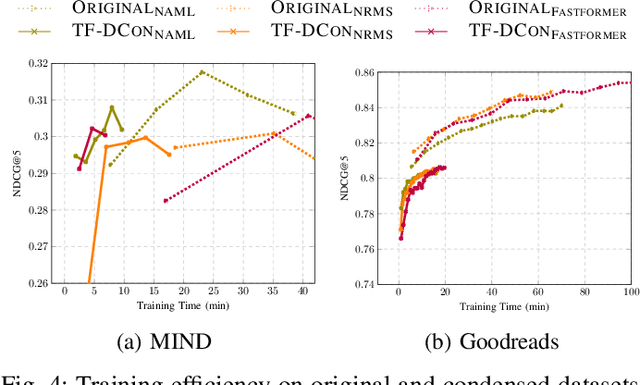
Modern techniques in Content-based Recommendation (CBR) leverage item content information to provide personalized services to users, but suffer from resource-intensive training on large datasets. To address this issue, we explore the dataset condensation for textual CBR in this paper. The goal of dataset condensation is to synthesize a small yet informative dataset, upon which models can achieve performance comparable to those trained on large datasets. While existing condensation approaches are tailored to classification tasks for continuous data like images or embeddings, direct application of them to CBR has limitations. To bridge this gap, we investigate efficient dataset condensation for content-based recommendation. Inspired by the remarkable abilities of large language models (LLMs) in text comprehension and generation, we leverage LLMs to empower the generation of textual content during condensation. To handle the interaction data involving both users and items, we devise a dual-level condensation method: content-level and user-level. At content-level, we utilize LLMs to condense all contents of an item into a new informative title. At user-level, we design a clustering-based synthesis module, where we first utilize LLMs to extract user interests. Then, the user interests and user embeddings are incorporated to condense users and generate interactions for condensed users. Notably, the condensation paradigm of this method is forward and free from iterative optimization on the synthesized dataset. Extensive empirical findings from our study, conducted on three authentic datasets, substantiate the efficacy of the proposed method. Particularly, we are able to approximate up to 97% of the original performance while reducing the dataset size by 95% (i.e., on dataset MIND).
Forgetful Large Language Models: Lessons Learned from Using LLMs in Robot Programming
Oct 10, 2023Large language models offer new ways of empowering people to program robot applications-namely, code generation via prompting. However, the code generated by LLMs is susceptible to errors. This work reports a preliminary exploration that empirically characterizes common errors produced by LLMs in robot programming. We categorize these errors into two phases: interpretation and execution. In this work, we focus on errors in execution and observe that they are caused by LLMs being "forgetful" of key information provided in user prompts. Based on this observation, we propose prompt engineering tactics designed to reduce errors in execution. We then demonstrate the effectiveness of these tactics with three language models: ChatGPT, Bard, and LLaMA-2. Finally, we discuss lessons learned from using LLMs in robot programming and call for the benchmarking of LLM-powered end-user development of robot applications.
AutoCycle-VC: Towards Bottleneck-Independent Zero-Shot Cross-Lingual Voice Conversion
Oct 10, 2023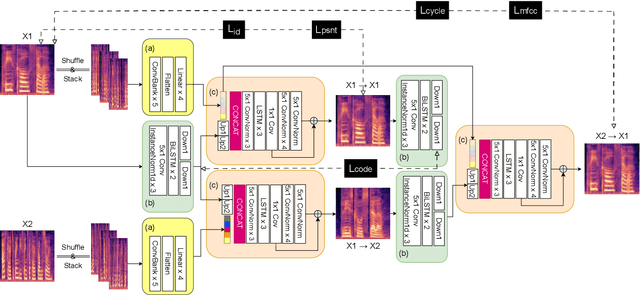
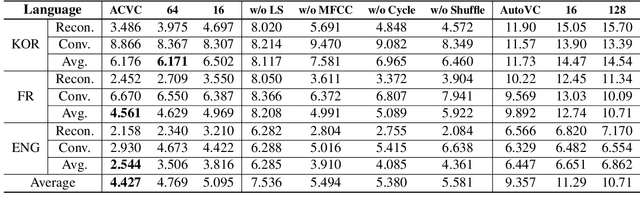
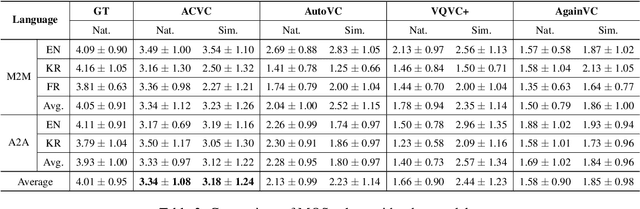

This paper proposes a simple and robust zero-shot voice conversion system with a cycle structure and mel-spectrogram pre-processing. Previous works suffer from information loss and poor synthesis quality due to their reliance on a carefully designed bottleneck structure. Moreover, models relying solely on self-reconstruction loss struggled with reproducing different speakers' voices. To address these issues, we suggested a cycle-consistency loss that considers conversion back and forth between target and source speakers. Additionally, stacked random-shuffled mel-spectrograms and a label smoothing method are utilized during speaker encoder training to extract a time-independent global speaker representation from speech, which is the key to a zero-shot conversion. Our model outperforms existing state-of-the-art results in both subjective and objective evaluations. Furthermore, it facilitates cross-lingual voice conversions and enhances the quality of synthesized speech.
Whispering LLaMA: A Cross-Modal Generative Error Correction Framework for Speech Recognition
Oct 10, 2023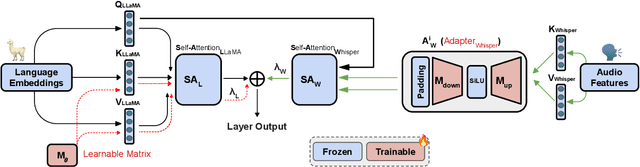
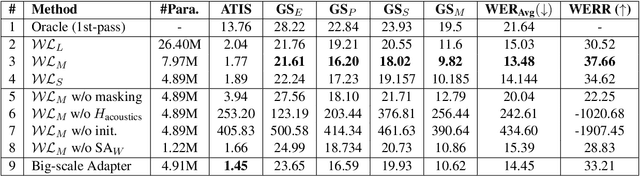
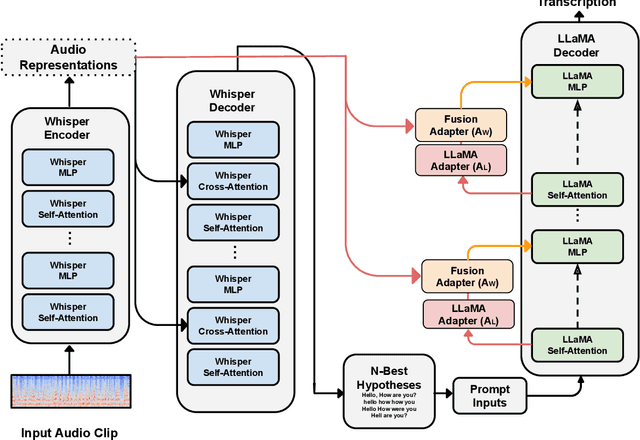
We introduce a new cross-modal fusion technique designed for generative error correction in automatic speech recognition (ASR). Our methodology leverages both acoustic information and external linguistic representations to generate accurate speech transcription contexts. This marks a step towards a fresh paradigm in generative error correction within the realm of n-best hypotheses. Unlike the existing ranking-based rescoring methods, our approach adeptly uses distinct initialization techniques and parameter-efficient algorithms to boost ASR performance derived from pre-trained speech and text models. Through evaluation across diverse ASR datasets, we evaluate the stability and reproducibility of our fusion technique, demonstrating its improved word error rate relative (WERR) performance in comparison to n-best hypotheses by relatively 37.66%. To encourage future research, we have made our code and pre-trained models open source at https://github.com/Srijith-rkr/Whispering-LLaMA.
FOSA: Full Information Maximum Likelihood (FIML) Optimized Self-Attention Imputation for Missing Data
Aug 23, 2023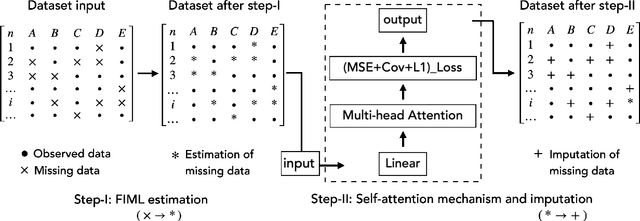

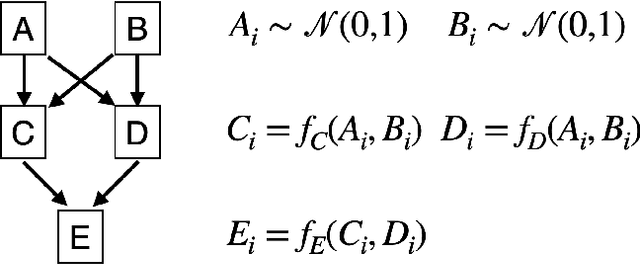
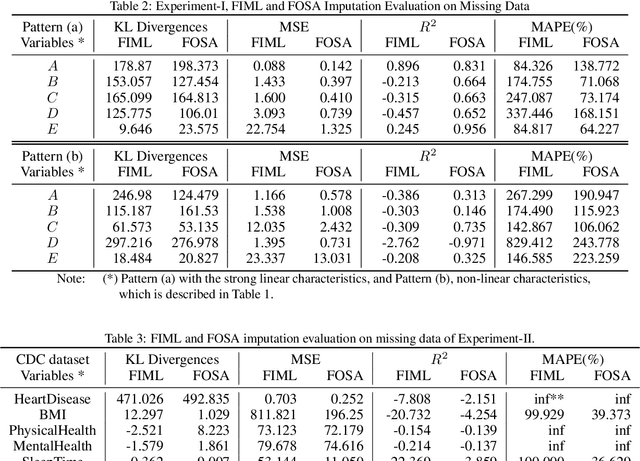
In data imputation, effectively addressing missing values is pivotal, especially in intricate datasets. This paper delves into the FIML Optimized Self-attention (FOSA) framework, an innovative approach that amalgamates the strengths of Full Information Maximum Likelihood (FIML) estimation with the capabilities of self-attention neural networks. Our methodology commences with an initial estimation of missing values via FIML, subsequently refining these estimates by leveraging the self-attention mechanism. Our comprehensive experiments on both simulated and real-world datasets underscore FOSA's pronounced advantages over traditional FIML techniques, encapsulating facets of accuracy, computational efficiency, and adaptability to diverse data structures. Intriguingly, even in scenarios where the Structural Equation Model (SEM) might be mis-specified, leading to suboptimal FIML estimates, the robust architecture of FOSA's self-attention component adeptly rectifies and optimizes the imputation outcomes. Our empirical tests reveal that FOSA consistently delivers commendable predictions, even in the face of up to 40% random missingness, highlighting its robustness and potential for wide-scale applications in data imputation.
A Learning Based Scheme for Fair Timeliness in Sparse Gossip Networks
Oct 02, 2023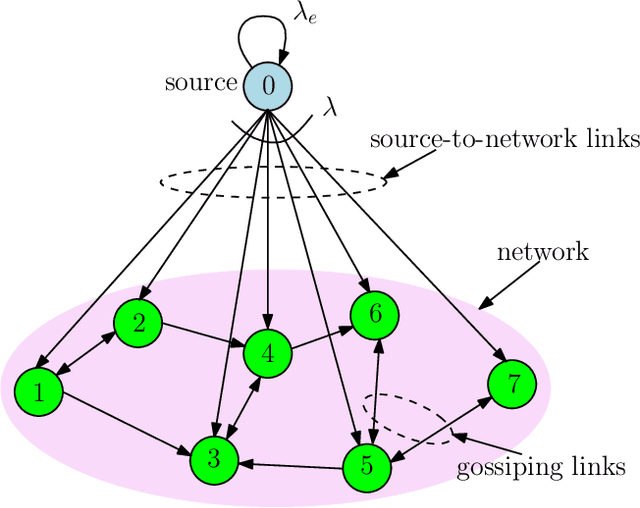
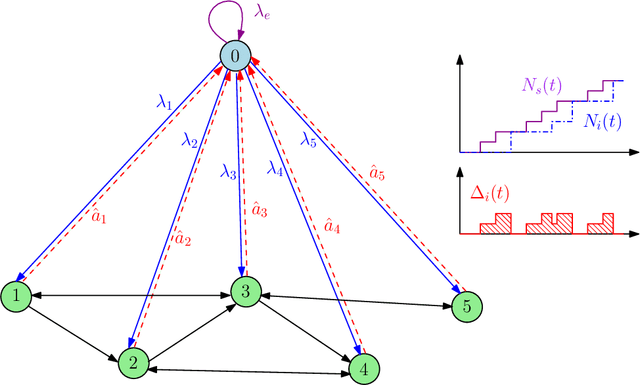
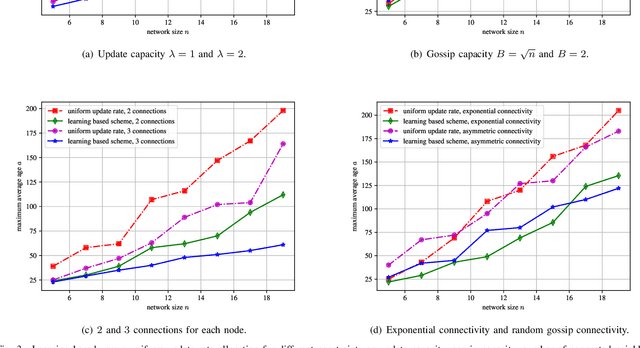
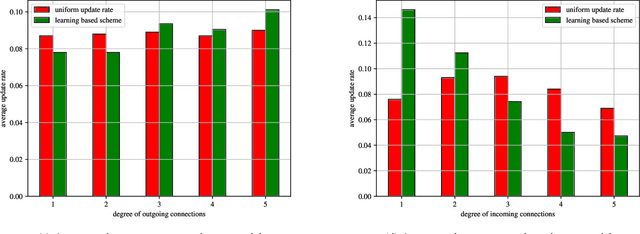
We consider a gossip network, consisting of $n$ nodes, which tracks the information at a source. The source updates its information with a Poisson arrival process and also sends updates to the nodes in the network. The nodes themselves can exchange information among themselves to become as timely as possible. However, the network structure is sparse and irregular, i.e., not every node is connected to every other node in the network, rather, the order of connectivity is low, and varies across different nodes. This asymmetry of the network implies that the nodes in the network do not perform equally in terms of timelines. Due to the gossiping nature of the network, some nodes are able to track the source very timely, whereas, some nodes fall behind versions quite often. In this work, we investigate how the rate-constrained source should distribute its update rate across the network to maintain fairness regarding timeliness, i.e., the overall worst case performance of the network can be minimized. Due to the continuous search space for optimum rate allocation, we formulate this problem as a continuum-armed bandit problem and employ Gaussian process based Bayesian optimization to meet a trade-off between exploration and exploitation sequentially.
ForeSeer: Product Aspect Forecasting Using Temporal Graph Embedding
Oct 07, 2023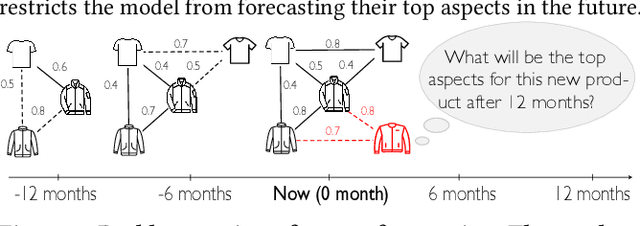
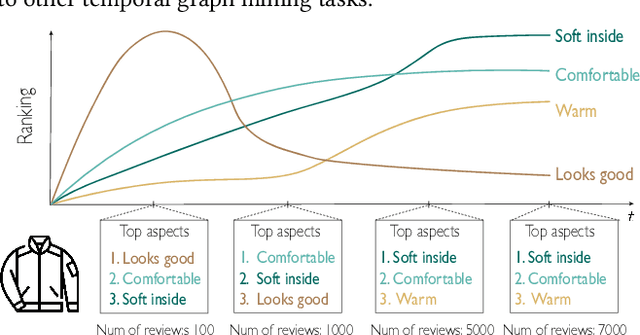
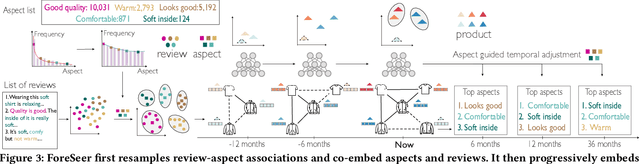
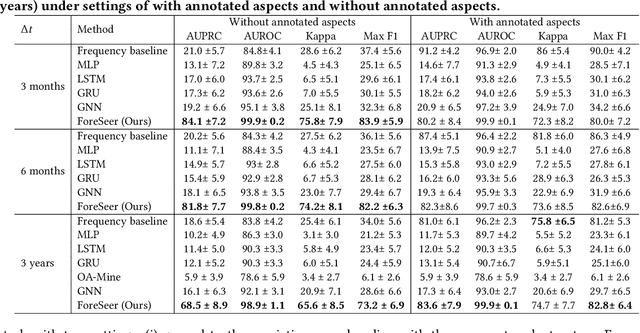
Developing text mining approaches to mine aspects from customer reviews has been well-studied due to its importance in understanding customer needs and product attributes. In contrast, it remains unclear how to predict the future emerging aspects of a new product that currently has little review information. This task, which we named product aspect forecasting, is critical for recommending new products, but also challenging because of the missing reviews. Here, we propose ForeSeer, a novel textual mining and product embedding approach progressively trained on temporal product graphs for this novel product aspect forecasting task. ForeSeer transfers reviews from similar products on a large product graph and exploits these reviews to predict aspects that might emerge in future reviews. A key novelty of our method is to jointly provide review, product, and aspect embeddings that are both time-sensitive and less affected by extremely imbalanced aspect frequencies. We evaluated ForeSeer on a real-world product review system containing 11,536,382 reviews and 11,000 products over 3 years. We observe that ForeSeer substantially outperformed existing approaches with at least 49.1\% AUPRC improvement under the real setting where aspect associations are not given. ForeSeer further improves future link prediction on the product graph and the review aspect association prediction. Collectively, Foreseer offers a novel framework for review forecasting by effectively integrating review text, product network, and temporal information, opening up new avenues for online shopping recommendation and e-commerce applications.
Parameterizing Context: Unleashing the Power of Parameter-Efficient Fine-Tuning and In-Context Tuning for Continual Table Semantic Parsing
Oct 07, 2023Continual table semantic parsing aims to train a parser on a sequence of tasks, where each task requires the parser to translate natural language into SQL based on task-specific tables but only offers limited training examples. Conventional methods tend to suffer from overfitting with limited supervision, as well as catastrophic forgetting due to parameter updates. Despite recent advancements that partially alleviate these issues through semi-supervised data augmentation and retention of a few past examples, the performance is still limited by the volume of unsupervised data and stored examples. To overcome these challenges, this paper introduces a novel method integrating \textit{parameter-efficient fine-tuning} (PEFT) and \textit{in-context tuning} (ICT) for training a continual table semantic parser. Initially, we present a task-adaptive PEFT framework capable of fully circumventing catastrophic forgetting, which is achieved by freezing the pre-trained model backbone and fine-tuning small-scale prompts. Building on this, we propose a teacher-student framework-based solution. The teacher addresses the few-shot problem using ICT, which procures contextual information by demonstrating a few training examples. In turn, the student leverages the proposed PEFT framework to learn from the teacher's output distribution, and subsequently compresses and saves the contextual information to the prompts, eliminating the need to store any training examples. Experimental evaluations on two benchmarks affirm the superiority of our method over prevalent few-shot and continual learning baselines across various metrics.
Memory-Constrained Semantic Segmentation for Ultra-High Resolution UAV Imagery
Oct 07, 2023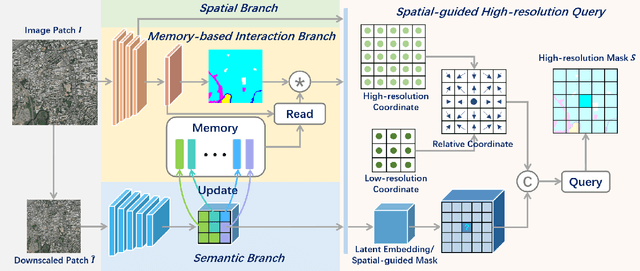
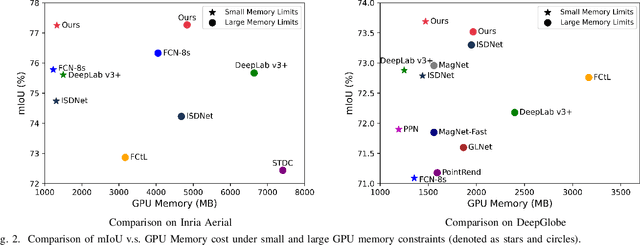
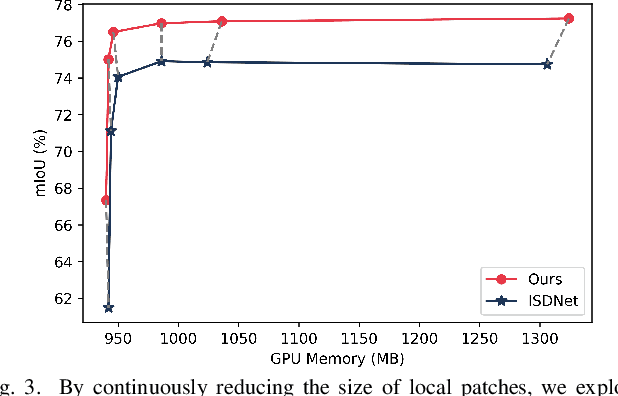

Amidst the swift advancements in photography and sensor technologies, high-definition cameras have become commonplace in the deployment of Unmanned Aerial Vehicles (UAVs) for diverse operational purposes. Within the domain of UAV imagery analysis, the segmentation of ultra-high resolution images emerges as a substantial and intricate challenge, especially when grappling with the constraints imposed by GPU memory-restricted computational devices. This paper delves into the intricate problem of achieving efficient and effective segmentation of ultra-high resolution UAV imagery, while operating under stringent GPU memory limitation. The strategy of existing approaches is to downscale the images to achieve computationally efficient segmentation. However, this strategy tends to overlook smaller, thinner, and curvilinear regions. To address this problem, we propose a GPU memory-efficient and effective framework for local inference without accessing the context beyond local patches. In particular, we introduce a novel spatial-guided high-resolution query module, which predicts pixel-wise segmentation results with high quality only by querying nearest latent embeddings with the guidance of high-resolution information. Additionally, we present an efficient memory-based interaction scheme to correct potential semantic bias of the underlying high-resolution information by associating cross-image contextual semantics. For evaluation of our approach, we perform comprehensive experiments over public benchmarks and achieve superior performance under both conditions of small and large GPU memory usage limitations. We will release the model and codes in the future.
Formalizing Natural Language Intent into Program Specifications via Large Language Models
Oct 03, 2023
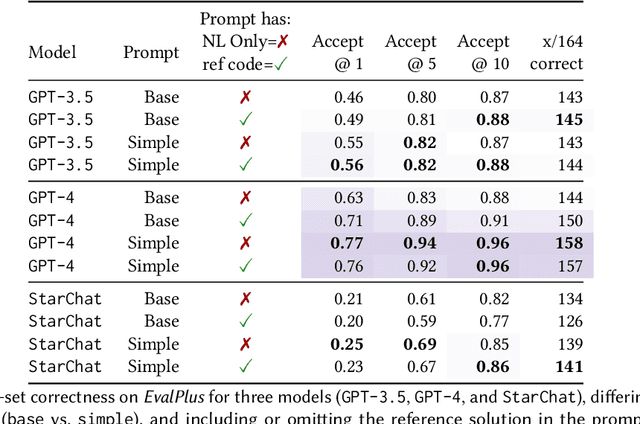
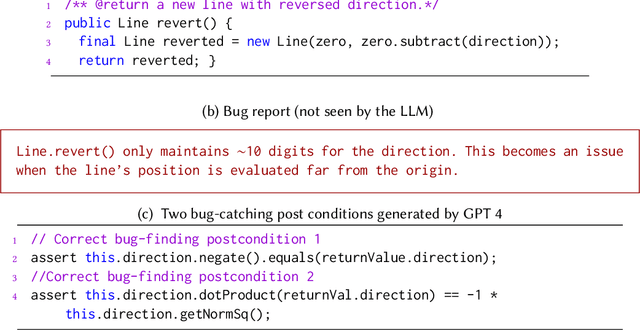
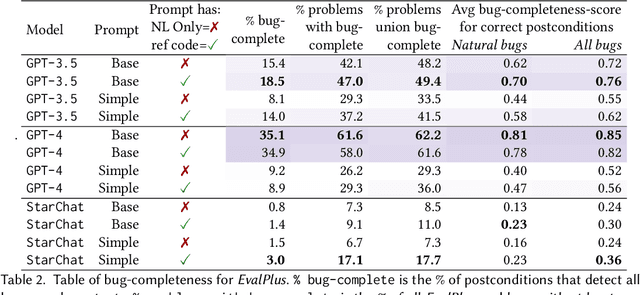
Informal natural language that describes code functionality, such as code comments or function documentation, may contain substantial information about a programs intent. However, there is typically no guarantee that a programs implementation and natural language documentation are aligned. In the case of a conflict, leveraging information in code-adjacent natural language has the potential to enhance fault localization, debugging, and code trustworthiness. In practice, however, this information is often underutilized due to the inherent ambiguity of natural language which makes natural language intent challenging to check programmatically. The "emergent abilities" of Large Language Models (LLMs) have the potential to facilitate the translation of natural language intent to programmatically checkable assertions. However, it is unclear if LLMs can correctly translate informal natural language specifications into formal specifications that match programmer intent. Additionally, it is unclear if such translation could be useful in practice. In this paper, we describe LLM4nl2post, the problem leveraging LLMs for transforming informal natural language to formal method postconditions, expressed as program assertions. We introduce and validate metrics to measure and compare different LLM4nl2post approaches, using the correctness and discriminative power of generated postconditions. We then perform qualitative and quantitative methods to assess the quality of LLM4nl2post postconditions, finding that they are generally correct and able to discriminate incorrect code. Finally, we find that LLM4nl2post via LLMs has the potential to be helpful in practice; specifications generated from natural language were able to catch 70 real-world historical bugs from Defects4J.