 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Leave-one-out Distinguishability in Machine Learning
Sep 29, 2023
We introduce a new analytical framework to quantify the changes in a machine learning algorithm's output distribution following the inclusion of a few data points in its training set, a notion we define as leave-one-out distinguishability (LOOD). This problem is key to measuring data **memorization** and **information leakage** in machine learning, and the **influence** of training data points on model predictions. We illustrate how our method broadens and refines existing empirical measures of memorization and privacy risks associated with training data. We use Gaussian processes to model the randomness of machine learning algorithms, and validate LOOD with extensive empirical analysis of information leakage using membership inference attacks. Our theoretical framework enables us to investigate the causes of information leakage and where the leakage is high. For example, we analyze the influence of activation functions, on data memorization. Additionally, our method allows us to optimize queries that disclose the most significant information about the training data in the leave-one-out setting. We illustrate how optimal queries can be used for accurate **reconstruction** of training data.
Fine-tuned vs. Prompt-tuned Supervised Representations: Which Better Account for Brain Language Representations?
Oct 03, 2023To decipher the algorithm underlying the human brain's language representation, previous work probed brain responses to language input with pre-trained artificial neural network (ANN) models fine-tuned on NLU tasks. However, full fine-tuning generally updates the entire parametric space and distorts pre-trained features, cognitively inconsistent with the brain's robust multi-task learning ability. Prompt-tuning, in contrast, protects pre-trained weights and learns task-specific embeddings to fit a task. Could prompt-tuning generate representations that better account for the brain's language representations than fine-tuning? If so, what kind of NLU task leads a pre-trained model to better decode the information represented in the human brain? We investigate these questions by comparing prompt-tuned and fine-tuned representations in neural decoding, that is predicting the linguistic stimulus from the brain activities evoked by the stimulus. We find that on none of the 10 NLU tasks, full fine-tuning significantly outperforms prompt-tuning in neural decoding, implicating that a more brain-consistent tuning method yields representations that better correlate with brain data. Moreover, we identify that tasks dealing with fine-grained concept meaning yield representations that better decode brain activation patterns than other tasks, especially the syntactic chunking task. This indicates that our brain encodes more fine-grained concept information than shallow syntactic information when representing languages.
Resilient Legged Local Navigation: Learning to Traverse with Compromised Perception End-to-End
Oct 05, 2023

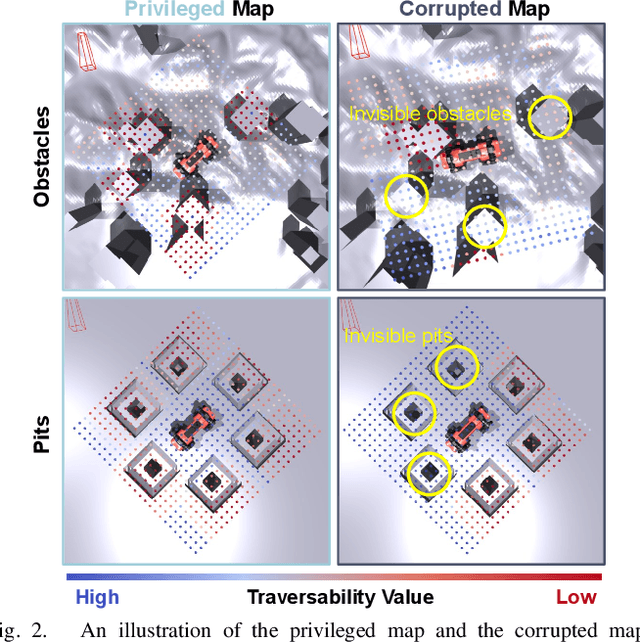
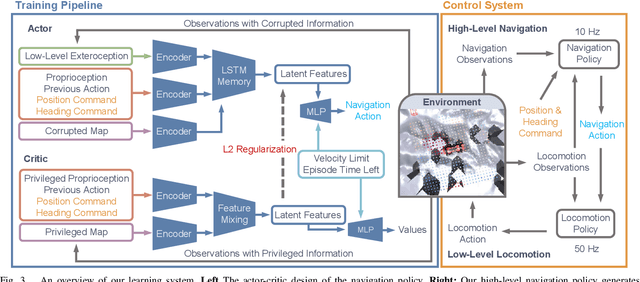
Autonomous robots must navigate reliably in unknown environments even under compromised exteroceptive perception, or perception failures. Such failures often occur when harsh environments lead to degraded sensing, or when the perception algorithm misinterprets the scene due to limited generalization. In this paper, we model perception failures as invisible obstacles and pits, and train a reinforcement learning (RL) based local navigation policy to guide our legged robot. Unlike previous works relying on heuristics and anomaly detection to update navigational information, we train our navigation policy to reconstruct the environment information in the latent space from corrupted perception and react to perception failures end-to-end. To this end, we incorporate both proprioception and exteroception into our policy inputs, thereby enabling the policy to sense collisions on different body parts and pits, prompting corresponding reactions. We validate our approach in simulation and on the real quadruped robot ANYmal running in real-time (<10 ms CPU inference). In a quantitative comparison with existing heuristic-based locally reactive planners, our policy increases the success rate over 30% when facing perception failures. Project Page: https://bit.ly/45NBTuh.
Alzheimer's Disease Prediction via Brain Structural-Functional Deep Fusing Network
Oct 05, 2023Fusing structural-functional images of the brain has shown great potential to analyze the deterioration of Alzheimer's disease (AD). However, it is a big challenge to effectively fuse the correlated and complementary information from multimodal neuroimages. In this paper, a novel model termed cross-modal transformer generative adversarial network (CT-GAN) is proposed to effectively fuse the functional and structural information contained in functional magnetic resonance imaging (fMRI) and diffusion tensor imaging (DTI). The CT-GAN can learn topological features and generate multimodal connectivity from multimodal imaging data in an efficient end-to-end manner. Moreover, the swapping bi-attention mechanism is designed to gradually align common features and effectively enhance the complementary features between modalities. By analyzing the generated connectivity features, the proposed model can identify AD-related brain connections. Evaluations on the public ADNI dataset show that the proposed CT-GAN can dramatically improve prediction performance and detect AD-related brain regions effectively. The proposed model also provides new insights for detecting AD-related abnormal neural circuits.
Dual Quaternion Rotational and Translational Equivariance in 3D Rigid Motion Modelling
Oct 11, 2023

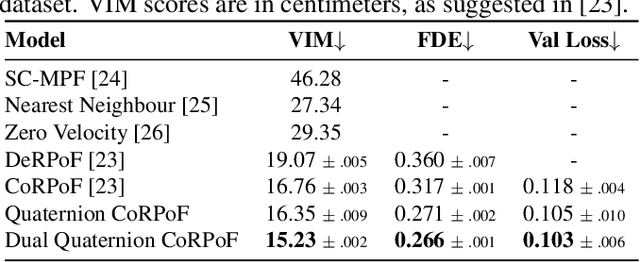
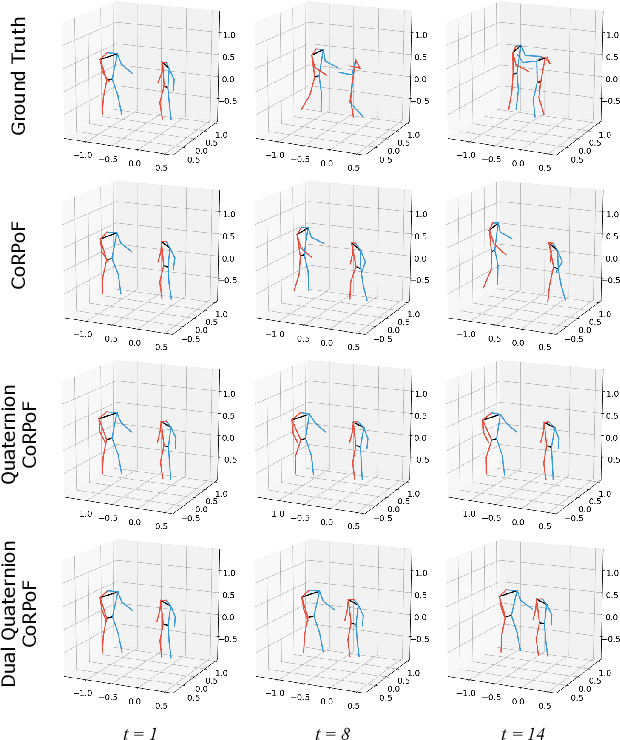
Objects' rigid motions in 3D space are described by rotations and translations of a highly-correlated set of points, each with associated $x,y,z$ coordinates that real-valued networks consider as separate entities, losing information. Previous works exploit quaternion algebra and their ability to model rotations in 3D space. However, these algebras do not properly encode translations, leading to sub-optimal performance in 3D learning tasks. To overcome these limitations, we employ a dual quaternion representation of rigid motions in the 3D space that jointly describes rotations and translations of point sets, processing each of the points as a single entity. Our approach is translation and rotation equivariant, so it does not suffer from shifts in the data and better learns object trajectories, as we validate in the experimental evaluations. Models endowed with this formulation outperform previous approaches in a human pose forecasting application, attesting to the effectiveness of the proposed dual quaternion formulation for rigid motions in 3D space.
Hypercomplex Multimodal Emotion Recognition from EEG and Peripheral Physiological Signals
Oct 11, 2023Multimodal emotion recognition from physiological signals is receiving an increasing amount of attention due to the impossibility to control them at will unlike behavioral reactions, thus providing more reliable information. Existing deep learning-based methods still rely on extracted handcrafted features, not taking full advantage of the learning ability of neural networks, and often adopt a single-modality approach, while human emotions are inherently expressed in a multimodal way. In this paper, we propose a hypercomplex multimodal network equipped with a novel fusion module comprising parameterized hypercomplex multiplications. Indeed, by operating in a hypercomplex domain the operations follow algebraic rules which allow to model latent relations among learned feature dimensions for a more effective fusion step. We perform classification of valence and arousal from electroencephalogram (EEG) and peripheral physiological signals, employing the publicly available database MAHNOB-HCI surpassing a multimodal state-of-the-art network. The code of our work is freely available at https://github.com/ispamm/MHyEEG.
Spike-time encoding of gas concentrations using neuromorphic analog sensory front-end
Oct 11, 2023Gas concentration detection is important for applications such as gas leakage monitoring. Metal Oxide (MOx) sensors show high sensitivities for specific gases, which makes them particularly useful for such monitoring applications. However, how to efficiently sample and further process the sensor responses remains an open question. Here we propose a simple analog circuit design inspired by the spiking output of the mammalian olfactory bulb and by event-based vision sensors. Our circuit encodes the gas concentration in the time difference between the pulses of two separate pathways. We show that in the setting of controlled airflow-embedded gas injections, the time difference between the two generated pulses varies inversely with gas concentration, which is in agreement with the spike timing difference between tufted cells and mitral cells of the mammalian olfactory bulb. Encoding concentration information in analog spike timings may pave the way for rapid and efficient gas detection, and ultimately lead to data- and power-efficient monitoring devices to be deployed in uncontrolled and turbulent environments.
Multichannel consecutive data cross-extraction with 1DCNN-attention for diagnosis of power transformer
Oct 11, 2023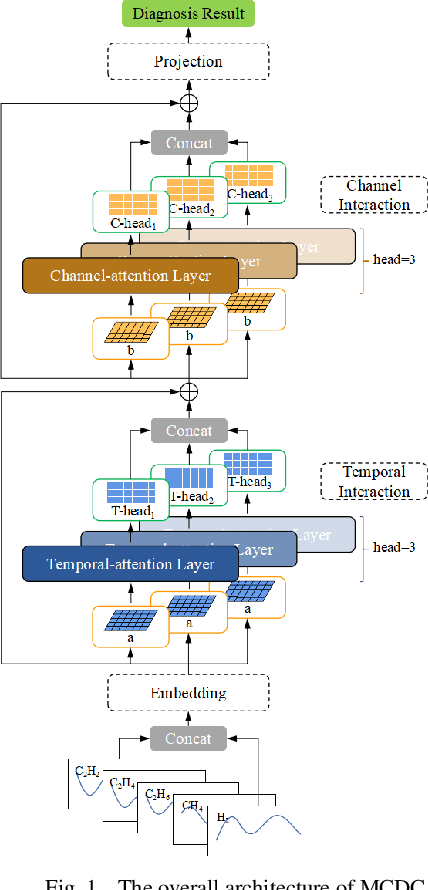
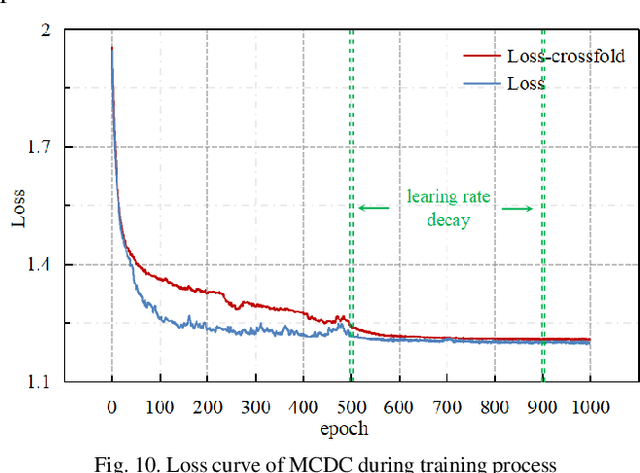
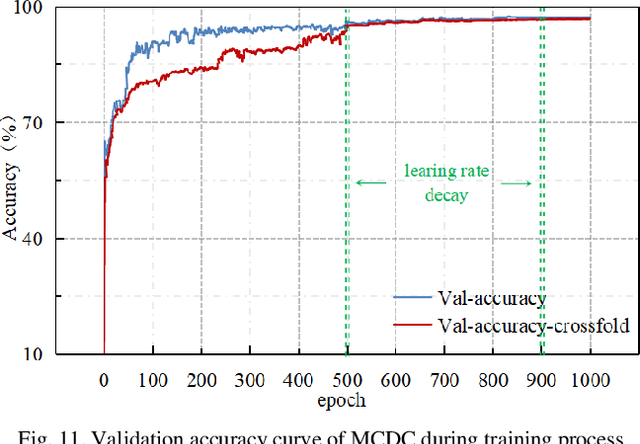
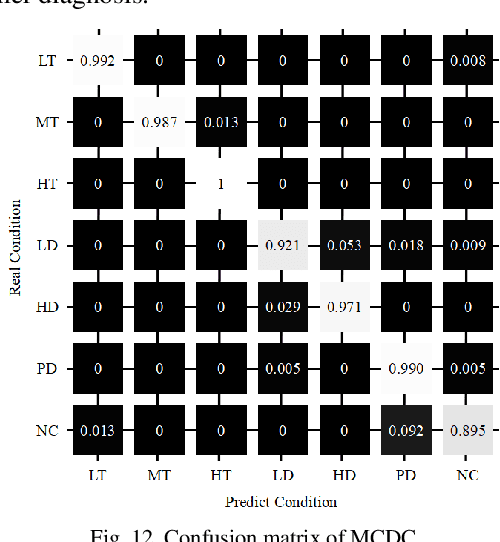
Power transformer plays a critical role in grid infrastructure, and its diagnosis is paramount for maintaining stable operation. However, the current methods for transformer diagnosis focus on discrete dissolved gas analysis, neglecting deep feature extraction of multichannel consecutive data. The unutilized sequential data contains the significant temporal information reflecting the transformer condition. In light of this, the structure of multichannel consecutive data cross-extraction (MCDC) is proposed in this article in order to comprehensively exploit the intrinsic characteristic and evaluate the states of transformer. Moreover, for the better accommodation in scenario of transformer diagnosis, one dimensional convolution neural network attention (1DCNN-attention) mechanism is introduced and offers a more efficient solution given the simplified spatial complexity. Finally, the effectiveness of MCDC and the superior generalization ability, compared with other algorithms, are validated in experiments conducted on a dataset collected from real operation cases of power transformer. Additionally, the better stability of 1DCNN-attention has also been certified.
Adaptive Visual Scene Understanding: Incremental Scene Graph Generation
Oct 11, 2023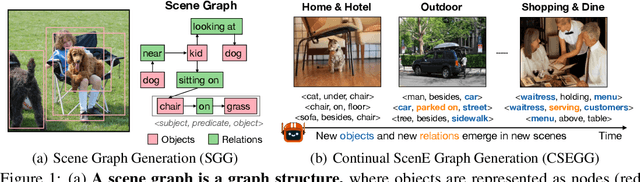
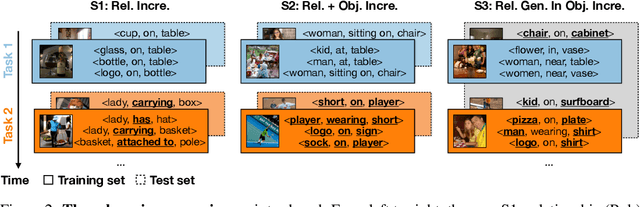
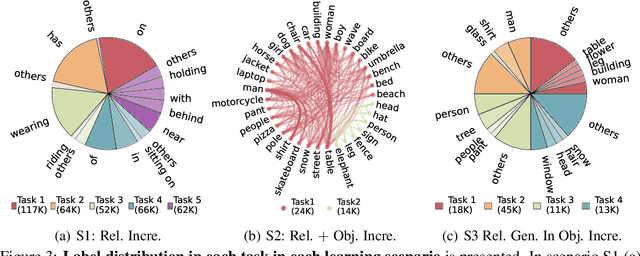
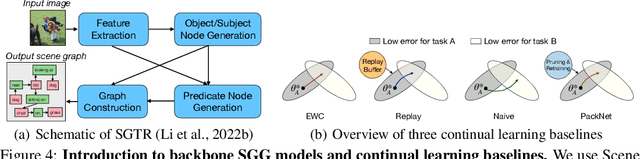
Scene graph generation (SGG) involves analyzing images to extract meaningful information about objects and their relationships. Given the dynamic nature of the visual world, it becomes crucial for AI systems to detect new objects and establish their new relationships with existing objects. To address the lack of continual learning methodologies in SGG, we introduce the comprehensive Continual ScenE Graph Generation (CSEGG) dataset along with 3 learning scenarios and 8 evaluation metrics. Our research investigates the continual learning performances of existing SGG methods on the retention of previous object entities and relationships as they learn new ones. Moreover, we also explore how continual object detection enhances generalization in classifying known relationships on unknown objects. We conduct extensive experiments benchmarking and analyzing the classical two-stage SGG methods and the most recent transformer-based SGG methods in continual learning settings, and gain valuable insights into the CSEGG problem. We invite the research community to explore this emerging field of study.
Understanding and Modeling the Effects of Task and Context on Drivers' Gaze Allocation
Oct 13, 2023
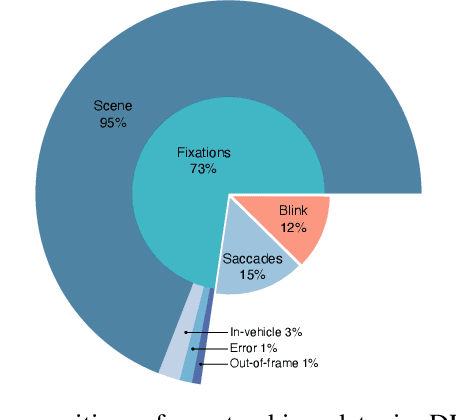

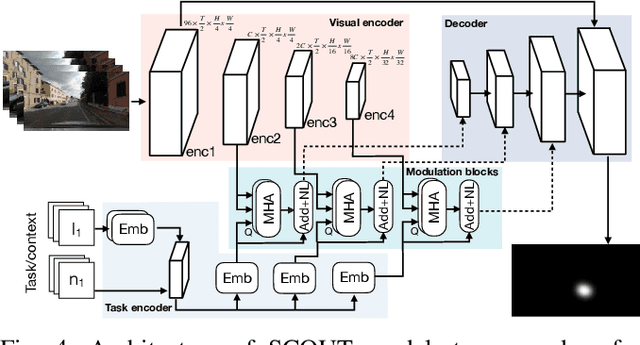
Understanding what drivers look at is important for many applications, including driver training, monitoring, and assistance, as well as self-driving. Traditionally, factors affecting human visual attention have been divided into bottom-up (involuntary attraction to salient regions) and top-down (task- and context-driven). Although both play a role in drivers' gaze allocation, most of the existing modeling approaches apply techniques developed for bottom-up saliency and do not consider task and context influences explicitly. Likewise, common driving attention benchmarks lack relevant task and context annotations. Therefore, to enable analysis and modeling of these factors for drivers' gaze prediction, we propose the following: 1) address some shortcomings of the popular DR(eye)VE dataset and extend it with per-frame annotations for driving task and context; 2) benchmark a number of baseline and SOTA models for saliency and driver gaze prediction and analyze them w.r.t. the new annotations; and finally, 3) a novel model that modulates drivers' gaze prediction with explicit action and context information, and as a result significantly improves SOTA performance on DR(eye)VE overall (by 24\% KLD and 89\% NSS) and on a subset of action and safety-critical intersection scenarios (by 10--30\% KLD). Extended annotations, code for model and evaluation will be made publicly available.