 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Zero-Shot Language Agent for Computer Control with Structured Reflection
Oct 12, 2023

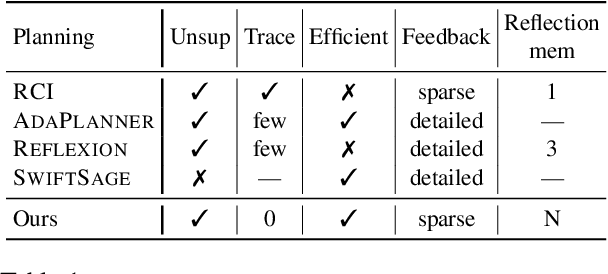
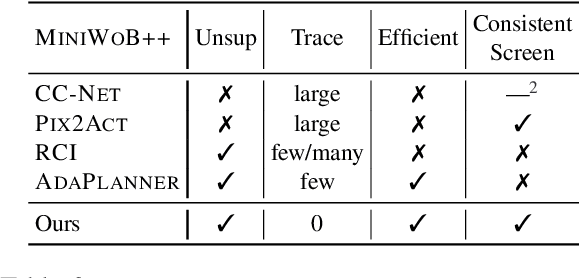

Large language models (LLMs) have shown increasing capacity at planning and executing a high-level goal in a live computer environment (e.g. MiniWoB++). To perform a task, recent works often require a model to learn from trace examples of the task via either supervised learning or few/many-shot prompting. Without these trace examples, it remains a challenge how an agent can autonomously learn and improve its control on a computer, which limits the ability of an agent to perform a new task. We approach this problem with a zero-shot agent that requires no given expert traces. Our agent plans for executable actions on a partially observed environment, and iteratively progresses a task by identifying and learning from its mistakes via self-reflection and structured thought management. On the easy tasks of MiniWoB++, we show that our zero-shot agent often outperforms recent SoTAs, with more efficient reasoning. For tasks with more complexity, our reflective agent performs on par with prior best models, even though previous works had the advantages of accessing expert traces or additional screen information.
Harnessing Large Language Models' Empathetic Response Generation Capabilities for Online Mental Health Counselling Support
Oct 12, 2023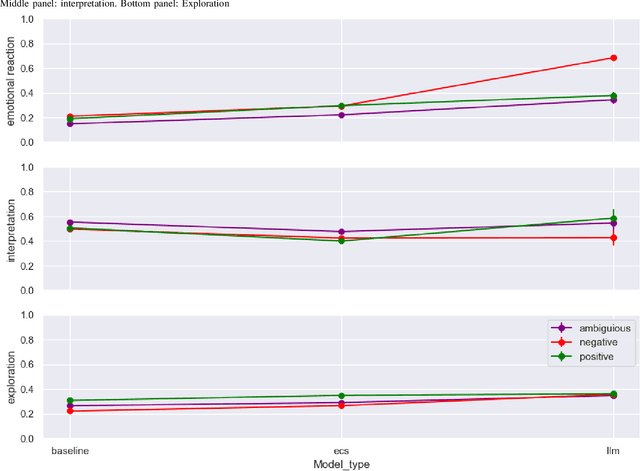
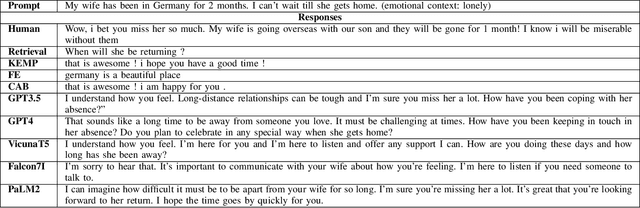
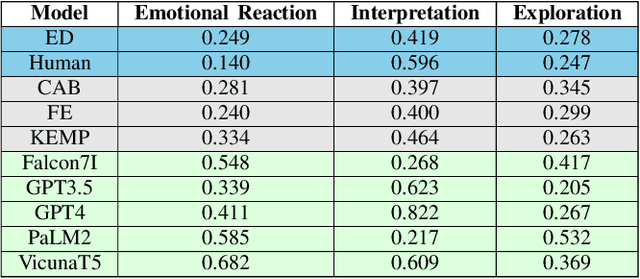
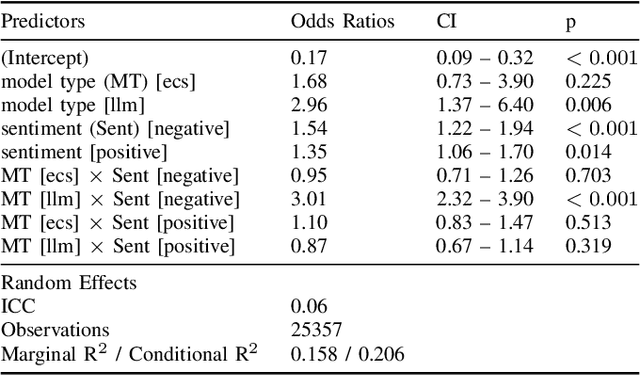
Large Language Models (LLMs) have demonstrated remarkable performance across various information-seeking and reasoning tasks. These computational systems drive state-of-the-art dialogue systems, such as ChatGPT and Bard. They also carry substantial promise in meeting the growing demands of mental health care, albeit relatively unexplored. As such, this study sought to examine LLMs' capability to generate empathetic responses in conversations that emulate those in a mental health counselling setting. We selected five LLMs: version 3.5 and version 4 of the Generative Pre-training (GPT), Vicuna FastChat-T5, Pathways Language Model (PaLM) version 2, and Falcon-7B-Instruct. Based on a simple instructional prompt, these models responded to utterances derived from the EmpatheticDialogues (ED) dataset. Using three empathy-related metrics, we compared their responses to those from traditional response generation dialogue systems, which were fine-tuned on the ED dataset, along with human-generated responses. Notably, we discovered that responses from the LLMs were remarkably more empathetic in most scenarios. We position our findings in light of catapulting advancements in creating empathetic conversational systems.
Towards an Interpretable Representation of Speaker Identity via Perceptual Voice Qualities
Oct 04, 2023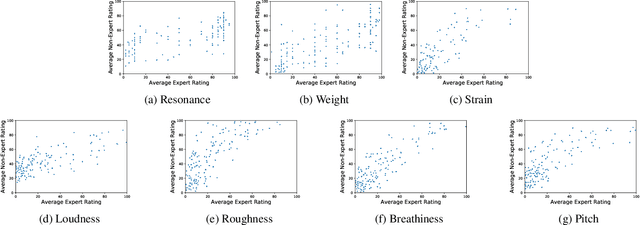

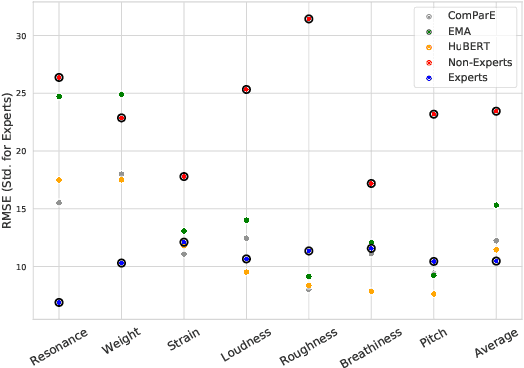
Unlike other data modalities such as text and vision, speech does not lend itself to easy interpretation. While lay people can understand how to describe an image or sentence via perception, non-expert descriptions of speech often end at high-level demographic information, such as gender or age. In this paper, we propose a possible interpretable representation of speaker identity based on perceptual voice qualities (PQs). By adding gendered PQs to the pathology-focused Consensus Auditory-Perceptual Evaluation of Voice (CAPE-V) protocol, our PQ-based approach provides a perceptual latent space of the character of adult voices that is an intermediary of abstraction between high-level demographics and low-level acoustic, physical, or learned representations. Contrary to prior belief, we demonstrate that these PQs are hearable by ensembles of non-experts, and further demonstrate that the information encoded in a PQ-based representation is predictable by various speech representations.
The Fisher-Rao geometry of CES distributions
Oct 02, 2023When dealing with a parametric statistical model, a Riemannian manifold can naturally appear by endowing the parameter space with the Fisher information metric. The geometry induced on the parameters by this metric is then referred to as the Fisher-Rao information geometry. Interestingly, this yields a point of view that allows for leveragingmany tools from differential geometry. After a brief introduction about these concepts, we will present some practical uses of these geometric tools in the framework of elliptical distributions. This second part of the exposition is divided into three main axes: Riemannian optimization for covariance matrix estimation, Intrinsic Cram\'er-Rao bounds, and classification using Riemannian distances.
Linear Progressive Coding for Semantic Communication using Deep Neural Networks
Sep 27, 2023We propose a general method for semantic representation of images and other data using progressive coding. Semantic coding allows for specific pieces of information to be selectively encoded into a set of measurements that can be highly compressed compared to the size of the original raw data. We consider a hierarchical method of coding where a partial amount of semantic information is first encoded a into a coarse representation of the data, which is then refined by additional encodings that add additional semantic information. Such hierarchical coding is especially well-suited for semantic communication i.e. transferring semantic information over noisy channels. Our proposed method can be considered as a generalization of both progressive image compression and source coding for semantic communication. We present results from experiments on the MNIST and CIFAR-10 datasets that show that progressive semantic coding can provide timely previews of semantic information with a small number of initial measurements while achieving overall accuracy and efficiency comparable to non-progressive methods.
A predict-and-optimize approach to profit-driven churn prevention
Oct 10, 2023In this paper, we introduce a novel predict-and-optimize method for profit-driven churn prevention. We frame the task of targeting customers for a retention campaign as a regret minimization problem. The main objective is to leverage individual customer lifetime values (CLVs) to ensure that only the most valuable customers are targeted. In contrast, many profit-driven strategies focus on churn probabilities while considering average CLVs. This often results in significant information loss due to data aggregation. Our proposed model aligns with the guidelines of Predict-and-Optimize (PnO) frameworks and can be efficiently solved using stochastic gradient descent methods. Results from 12 churn prediction datasets underscore the effectiveness of our approach, which achieves the best average performance compared to other well-established strategies in terms of average profit.
Discriminative Speech Recognition Rescoring with Pre-trained Language Models
Oct 10, 2023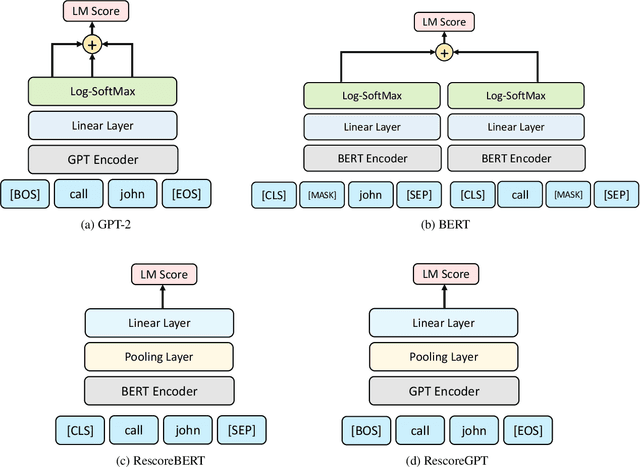
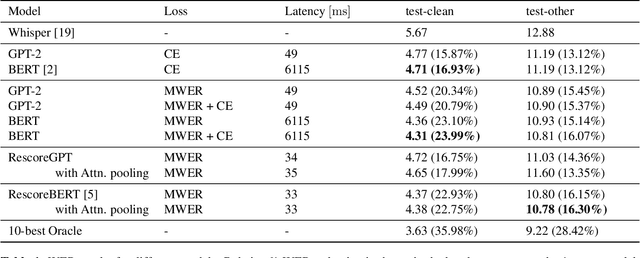
Second pass rescoring is a critical component of competitive automatic speech recognition (ASR) systems. Large language models have demonstrated their ability in using pre-trained information for better rescoring of ASR hypothesis. Discriminative training, directly optimizing the minimum word-error-rate (MWER) criterion typically improves rescoring. In this study, we propose and explore several discriminative fine-tuning schemes for pre-trained LMs. We propose two architectures based on different pooling strategies of output embeddings and compare with probability based MWER. We conduct detailed comparisons between pre-trained causal and bidirectional LMs in discriminative settings. Experiments on LibriSpeech demonstrate that all MWER training schemes are beneficial, giving additional gains upto 8.5\% WER. Proposed pooling variants achieve lower latency while retaining most improvements. Finally, our study concludes that bidirectionality is better utilized with discriminative training.
Transformer-Based Neural Surrogate for Link-Level Path Loss Prediction from Variable-Sized Maps
Oct 10, 2023Estimating path loss for a transmitter-receiver location is key to many use-cases including network planning and handover. Machine learning has become a popular tool to predict wireless channel properties based on map data. In this work, we present a transformer-based neural network architecture that enables predicting link-level properties from maps of various dimensions and from sparse measurements. The map contains information about buildings and foliage. The transformer model attends to the regions that are relevant for path loss prediction and, therefore, scales efficiently to maps of different size. Further, our approach works with continuous transmitter and receiver coordinates without relying on discretization. In experiments, we show that the proposed model is able to efficiently learn dominant path losses from sparse training data and generalizes well when tested on novel maps.
Rephrase, Augment, Reason: Visual Grounding of Questions for Vision-Language Models
Oct 09, 2023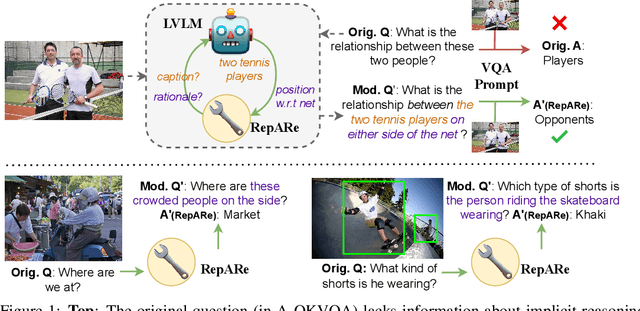
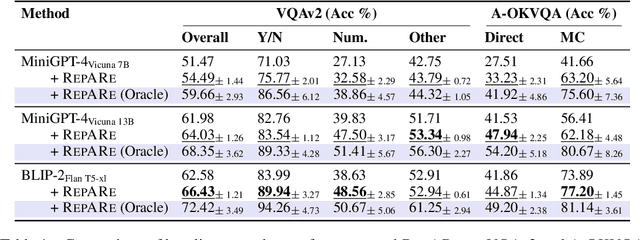
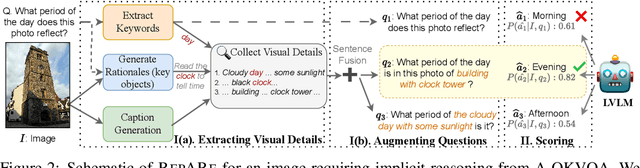
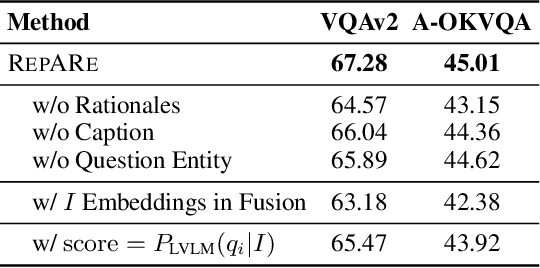
An increasing number of vision-language tasks can be handled with little to no training, i.e., in a zero and few-shot manner, by marrying large language models (LLMs) to vision encoders, resulting in large vision-language models (LVLMs). While this has huge upsides, such as not requiring training data or custom architectures, how an input is presented to a LVLM can have a major impact on zero-shot model performance. In particular, inputs phrased in an underspecified way can result in incorrect answers due to factors like missing visual information, complex implicit reasoning, or linguistic ambiguity. Therefore, adding visually grounded information to the input as a preemptive clarification should improve model performance by reducing underspecification, e.g., by localizing objects and disambiguating references. Similarly, in the VQA setting, changing the way questions are framed can make them easier for models to answer. To this end, we present Rephrase, Augment and Reason (RepARe), a gradient-free framework that extracts salient details about the image using the underlying LVLM as a captioner and reasoner, in order to propose modifications to the original question. We then use the LVLM's confidence over a generated answer as an unsupervised scoring function to select the rephrased question most likely to improve zero-shot performance. Focusing on two visual question answering tasks, we show that RepARe can result in a 3.85% (absolute) increase in zero-shot performance on VQAv2 and a 6.41% point increase on A-OKVQA. Additionally, we find that using gold answers for oracle question candidate selection achieves a substantial gain in VQA accuracy by up to 14.41%. Through extensive analysis, we demonstrate that outputs from RepARe increase syntactic complexity, and effectively utilize vision-language interaction and the frozen language model in LVLMs.
Towards Lossless Dataset Distillation via Difficulty-Aligned Trajectory Matching
Oct 09, 2023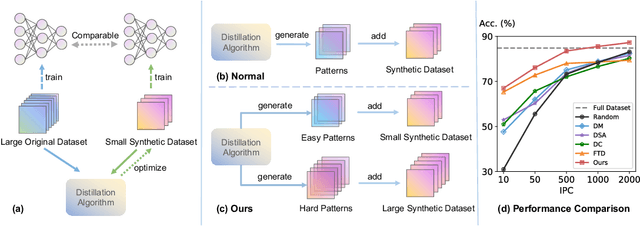
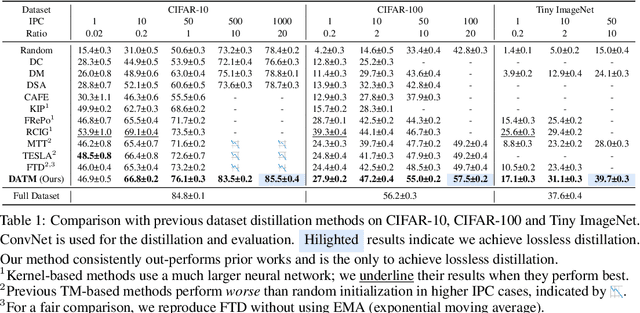
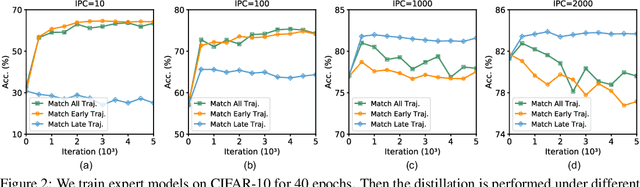

The ultimate goal of Dataset Distillation is to synthesize a small synthetic dataset such that a model trained on this synthetic set will perform equally well as a model trained on the full, real dataset. Until now, no method of Dataset Distillation has reached this completely lossless goal, in part due to the fact that previous methods only remain effective when the total number of synthetic samples is extremely small. Since only so much information can be contained in such a small number of samples, it seems that to achieve truly loss dataset distillation, we must develop a distillation method that remains effective as the size of the synthetic dataset grows. In this work, we present such an algorithm and elucidate why existing methods fail to generate larger, high-quality synthetic sets. Current state-of-the-art methods rely on trajectory-matching, or optimizing the synthetic data to induce similar long-term training dynamics as the real data. We empirically find that the training stage of the trajectories we choose to match (i.e., early or late) greatly affects the effectiveness of the distilled dataset. Specifically, early trajectories (where the teacher network learns easy patterns) work well for a low-cardinality synthetic set since there are fewer examples wherein to distribute the necessary information. Conversely, late trajectories (where the teacher network learns hard patterns) provide better signals for larger synthetic sets since there are now enough samples to represent the necessary complex patterns. Based on our findings, we propose to align the difficulty of the generated patterns with the size of the synthetic dataset. In doing so, we successfully scale trajectory matching-based methods to larger synthetic datasets, achieving lossless dataset distillation for the very first time. Code and distilled datasets are available at https://gzyaftermath.github.io/DATM.