 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DSG: An End-to-End Document Structure Generator
Oct 13, 2023
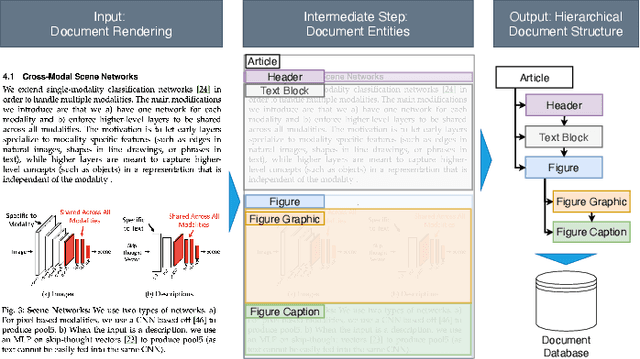
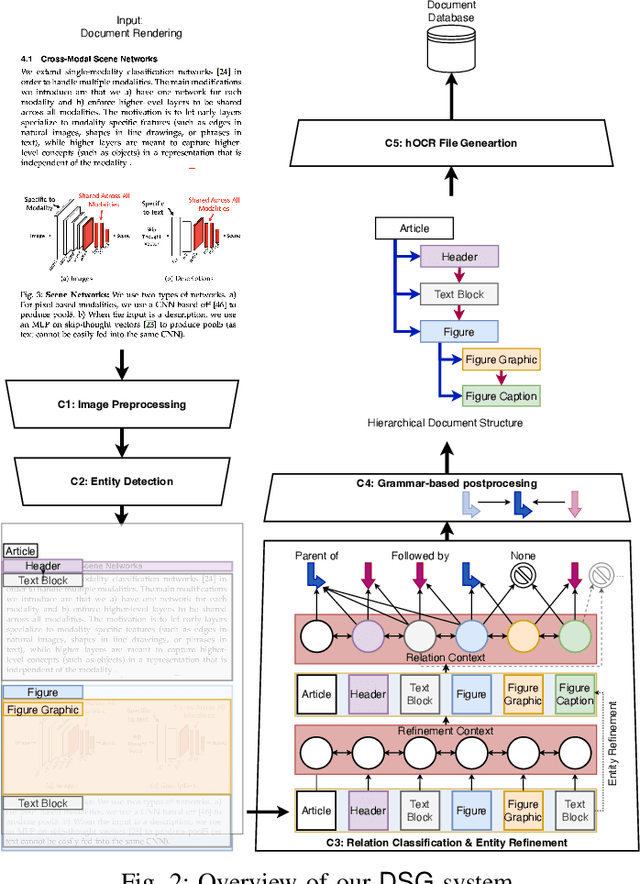
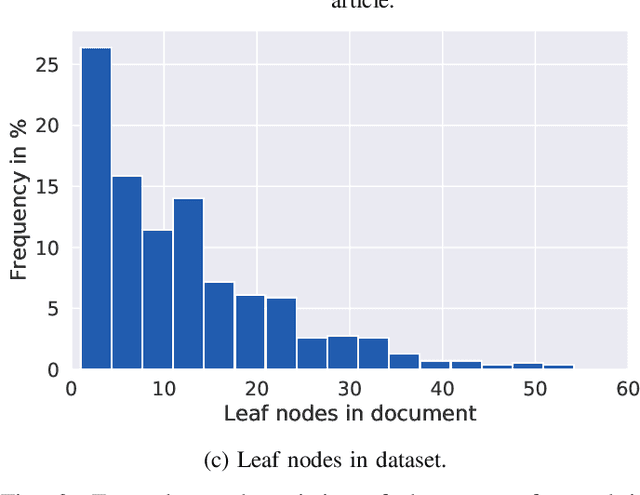
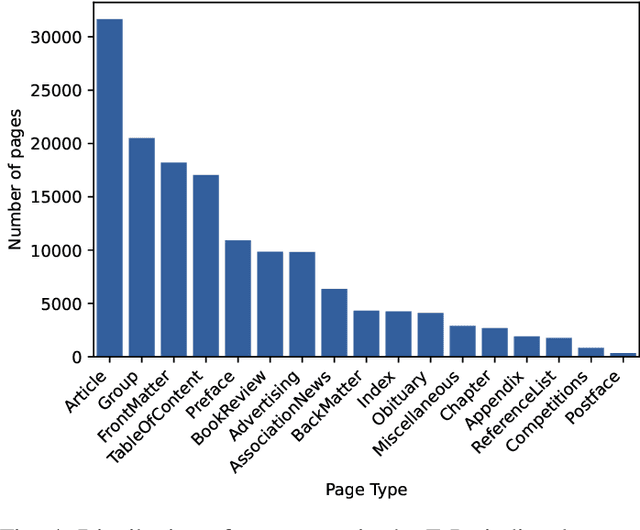
Information in industry, research, and the public sector is widely stored as rendered documents (e.g., PDF files, scans). Hence, to enable downstream tasks, systems are needed that map rendered documents onto a structured hierarchical format. However, existing systems for this task are limited by heuristics and are not end-to-end trainable. In this work, we introduce the Document Structure Generator (DSG), a novel system for document parsing that is fully end-to-end trainable. DSG combines a deep neural network for parsing (i) entities in documents (e.g., figures, text blocks, headers, etc.) and (ii) relations that capture the sequence and nested structure between entities. Unlike existing systems that rely on heuristics, our DSG is trained end-to-end, making it effective and flexible for real-world applications. We further contribute a new, large-scale dataset called E-Periodica comprising real-world magazines with complex document structures for evaluation. Our results demonstrate that our DSG outperforms commercial OCR tools and, on top of that, achieves state-of-the-art performance. To the best of our knowledge, our DSG system is the first end-to-end trainable system for hierarchical document parsing.
Ultrasound Image Segmentation of Thyroid Nodule via Latent Semantic Feature Co-Registration
Oct 13, 2023
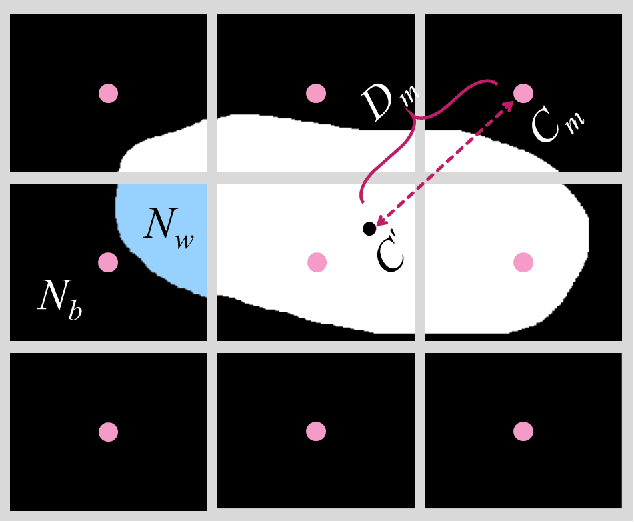
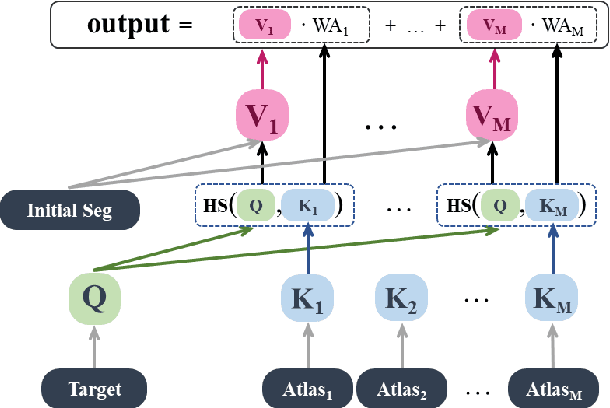
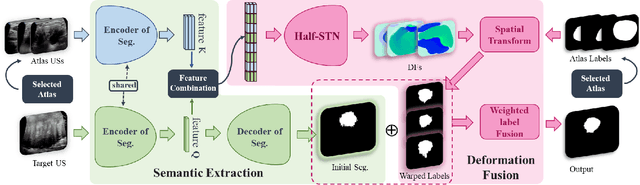
Segmentation of nodules in thyroid ultrasound imaging plays a crucial role in the detection and treatment of thyroid cancer. However, owing to the diversity of scanner vendors and imaging protocols in different hospitals, the automatic segmentation model, which has already demonstrated expert-level accuracy in the field of medical image segmentation, finds its accuracy reduced as the result of its weak generalization performance when being applied in clinically realistic environments. To address this issue, the present paper proposes ASTN, a framework for thyroid nodule segmentation achieved through a new type co-registration network. By extracting latent semantic information from the atlas and target images and utilizing in-depth features to accomplish the co-registration of nodules in thyroid ultrasound images, this framework can ensure the integrity of anatomical structure and reduce the impact on segmentation as the result of overall differences in image caused by different devices. In addition, this paper also provides an atlas selection algorithm to mitigate the difficulty of co-registration. As shown by the evaluation results collected from the datasets of different devices, thanks to the method we proposed, the model generalization has been greatly improved while maintaining a high level of segmentation accuracy.
Jointly-Learned Exit and Inference for a Dynamic Neural Network : JEI-DNN
Oct 13, 2023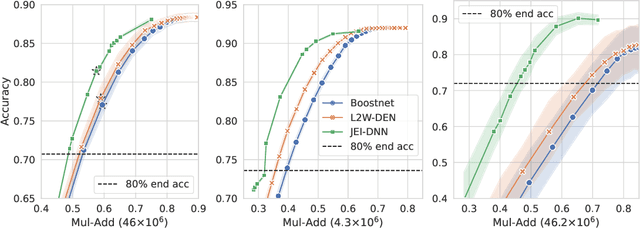
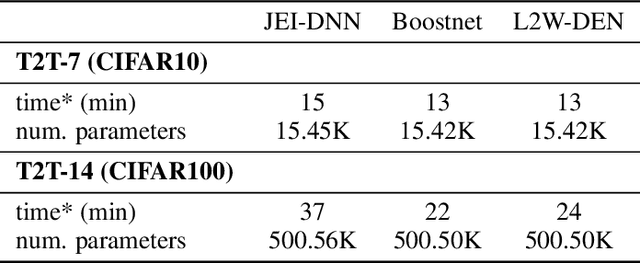
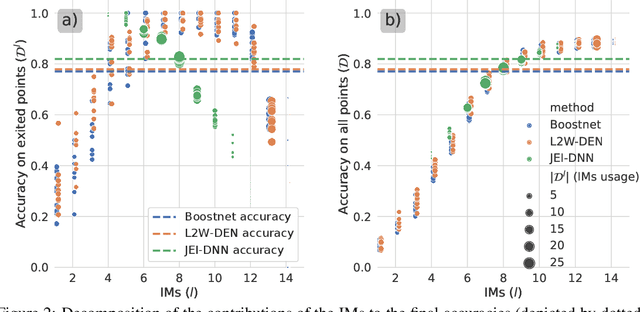

Large pretrained models, coupled with fine-tuning, are slowly becoming established as the dominant architecture in machine learning. Even though these models offer impressive performance, their practical application is often limited by the prohibitive amount of resources required for every inference. Early-exiting dynamic neural networks (EDNN) circumvent this issue by allowing a model to make some of its predictions from intermediate layers (i.e., early-exit). Training an EDNN architecture is challenging as it consists of two intertwined components: the gating mechanism (GM) that controls early-exiting decisions and the intermediate inference modules (IMs) that perform inference from intermediate representations. As a result, most existing approaches rely on thresholding confidence metrics for the gating mechanism and strive to improve the underlying backbone network and the inference modules. Although successful, this approach has two fundamental shortcomings: 1) the GMs and the IMs are decoupled during training, leading to a train-test mismatch; and 2) the thresholding gating mechanism introduces a positive bias into the predictive probabilities, making it difficult to readily extract uncertainty information. We propose a novel architecture that connects these two modules. This leads to significant performance improvements on classification datasets and enables better uncertainty characterization capabilities.
Radar Instance Transformer: Reliable Moving Instance Segmentation in Sparse Radar Point Clouds
Sep 28, 2023The perception of moving objects is crucial for autonomous robots performing collision avoidance in dynamic environments. LiDARs and cameras tremendously enhance scene interpretation but do not provide direct motion information and face limitations under adverse weather. Radar sensors overcome these limitations and provide Doppler velocities, delivering direct information on dynamic objects. In this paper, we address the problem of moving instance segmentation in radar point clouds to enhance scene interpretation for safety-critical tasks. Our Radar Instance Transformer enriches the current radar scan with temporal information without passing aggregated scans through a neural network. We propose a full-resolution backbone to prevent information loss in sparse point cloud processing. Our instance transformer head incorporates essential information to enhance segmentation but also enables reliable, class-agnostic instance assignments. In sum, our approach shows superior performance on the new moving instance segmentation benchmarks, including diverse environments, and provides model-agnostic modules to enhance scene interpretation. The benchmark is based on the RadarScenes dataset and will be made available upon acceptance.
LANCAR: Leveraging Language for Context-Aware Robot Locomotion in Unstructured Environments
Sep 30, 2023Robotic locomotion is a challenging task, especially in unstructured terrains. In practice, the optimal locomotion policy can be context-dependent by using the contextual information of encountered terrains in decision-making. Humans can interpret the environmental context for robots, but the ambiguity of human language makes it challenging to use in robot locomotion directly. In this paper, we propose a novel approach, LANCAR, that introduces a context translator that works with reinforcement learning (RL) agents for context-aware locomotion. Our formulation allows a robot to interpret the contextual information from environments generated by human observers or Vision-Language Models (VLM) with Large Language Models (LLM) and use this information to generate contextual embeddings. We incorporate the contextual embeddings with the robot's internal environmental observations as the input to the RL agent's decision neural network. We evaluate LANCAR with contextual information in varying ambiguity levels and compare its performance using several alternative approaches. Our experimental results demonstrate that our approach exhibits good generalizability and adaptability across diverse terrains, by achieving at least 10% of performance improvement in episodic reward over baselines. The experiment video can be found at the following link: https://raaslab.org/projects/LLM_Context_Estimation/.
EfficientOCR: An Extensible, Open-Source Package for Efficiently Digitizing World Knowledge
Oct 16, 2023Billions of public domain documents remain trapped in hard copy or lack an accurate digitization. Modern natural language processing methods cannot be used to index, retrieve, and summarize their texts; conduct computational textual analyses; or extract information for statistical analyses, and these texts cannot be incorporated into language model training. Given the diversity and sheer quantity of public domain texts, liberating them at scale requires optical character recognition (OCR) that is accurate, extremely cheap to deploy, and sample-efficient to customize to novel collections, languages, and character sets. Existing OCR engines, largely designed for small-scale commercial applications in high resource languages, often fall short of these requirements. EffOCR (EfficientOCR), a novel open-source OCR package, meets both the computational and sample efficiency requirements for liberating texts at scale by abandoning the sequence-to-sequence architecture typically used for OCR, which takes representations from a learned vision model as inputs to a learned language model. Instead, EffOCR models OCR as a character or word-level image retrieval problem. EffOCR is cheap and sample efficient to train, as the model only needs to learn characters' visual appearance and not how they are used in sequence to form language. Models in the EffOCR model zoo can be deployed off-the-shelf with only a few lines of code. Importantly, EffOCR also allows for easy, sample efficient customization with a simple model training interface and minimal labeling requirements due to its sample efficiency. We illustrate the utility of EffOCR by cheaply and accurately digitizing 20 million historical U.S. newspaper scans, evaluating zero-shot performance on randomly selected documents from the U.S. National Archives, and accurately digitizing Japanese documents for which all other OCR solutions failed.
A representation learning approach to probe for dynamical dark energy in matter power spectra
Oct 16, 2023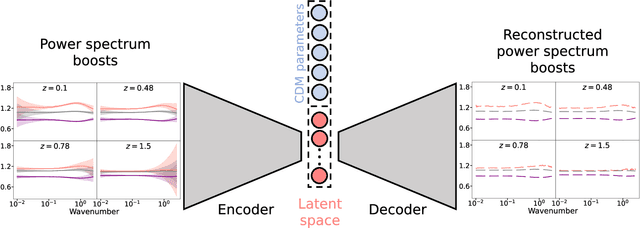
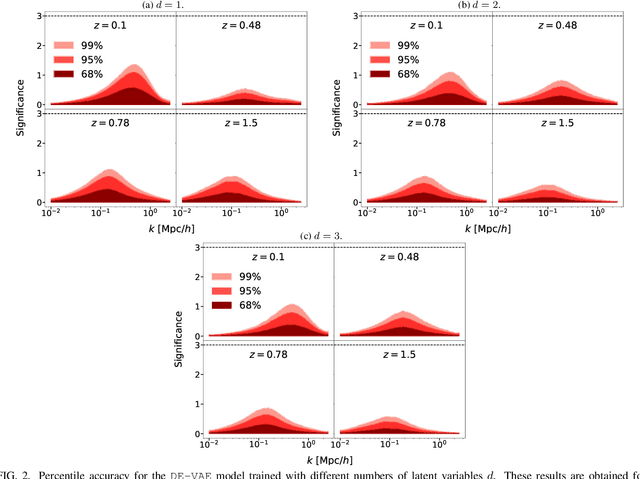
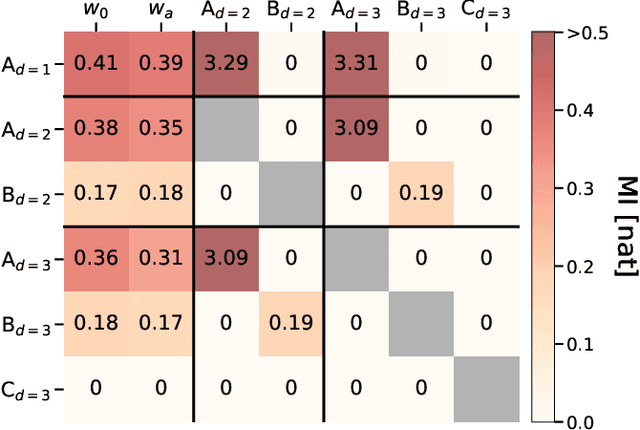
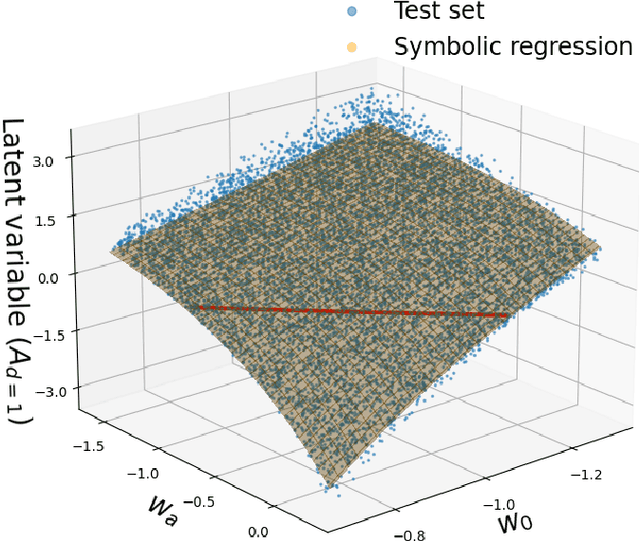
We present DE-VAE, a variational autoencoder (VAE) architecture to search for a compressed representation of dynamical dark energy (DE) models in observational studies of the cosmic large-scale structure. DE-VAE is trained on matter power spectra boosts generated at wavenumbers $k\in(0.01-2.5) \ h/\rm{Mpc}$ and at four redshift values $z\in(0.1,0.48,0.78,1.5)$ for the most typical dynamical DE parametrization with two extra parameters describing an evolving DE equation of state. The boosts are compressed to a lower-dimensional representation, which is concatenated with standard cold dark matter (CDM) parameters and then mapped back to reconstructed boosts; both the compression and the reconstruction components are parametrized as neural networks. Remarkably, we find that a single latent parameter is sufficient to predict 95% (99%) of DE power spectra generated over a broad range of cosmological parameters within $1\sigma$ ($2\sigma$) of a Gaussian error which includes cosmic variance, shot noise and systematic effects for a Stage IV-like survey. This single parameter shows a high mutual information with the two DE parameters, and these three variables can be linked together with an explicit equation through symbolic regression. Considering a model with two latent variables only marginally improves the accuracy of the predictions, and adding a third latent variable has no significant impact on the model's performance. We discuss how the DE-VAE architecture can be extended from a proof of concept to a general framework to be employed in the search for a common lower-dimensional parametrization of a wide range of beyond-$\Lambda$CDM models and for different cosmological datasets. Such a framework could then both inform the development of cosmological surveys by targeting optimal probes, and provide theoretical insight into the common phenomenological aspects of beyond-$\Lambda$CDM models.
The Road to On-board Change Detection: A Lightweight Patch-Level Change Detection Network via Exploring the Potential of Pruning and Pooling
Oct 16, 2023Existing satellite remote sensing change detection (CD) methods often crop original large-scale bi-temporal image pairs into small patch pairs and then use pixel-level CD methods to fairly process all the patch pairs. However, due to the sparsity of change in large-scale satellite remote sensing images, existing pixel-level CD methods suffer from a waste of computational cost and memory resources on lots of unchanged areas, which reduces the processing efficiency of on-board platform with extremely limited computation and memory resources. To address this issue, we propose a lightweight patch-level CD network (LPCDNet) to rapidly remove lots of unchanged patch pairs in large-scale bi-temporal image pairs. This is helpful to accelerate the subsequent pixel-level CD processing stage and reduce its memory costs. In our LPCDNet, a sensitivity-guided channel pruning method is proposed to remove unimportant channels and construct the lightweight backbone network on basis of ResNet18 network. Then, the multi-layer feature compression (MLFC) module is designed to compress and fuse the multi-level feature information of bi-temporal image patch. The output of MLFC module is fed into the fully-connected decision network to generate the predicted binary label. Finally, a weighted cross-entropy loss is utilized in the training process of network to tackle the change/unchange class imbalance problem. Experiments on two CD datasets demonstrate that our LPCDNet achieves more than 1000 frames per second on an edge computation platform, i.e., NVIDIA Jetson AGX Orin, which is more than 3 times that of the existing methods without noticeable CD performance loss. In addition, our method reduces more than 60% memory costs of the subsequent pixel-level CD processing stage.
Robust Collaborative Filtering to Popularity Distribution Shift
Oct 16, 2023In leading collaborative filtering (CF) models, representations of users and items are prone to learn popularity bias in the training data as shortcuts. The popularity shortcut tricks are good for in-distribution (ID) performance but poorly generalized to out-of-distribution (OOD) data, i.e., when popularity distribution of test data shifts w.r.t. the training one. To close the gap, debiasing strategies try to assess the shortcut degrees and mitigate them from the representations. However, there exist two deficiencies: (1) when measuring the shortcut degrees, most strategies only use statistical metrics on a single aspect (i.e., item frequency on item and user frequency on user aspect), failing to accommodate the compositional degree of a user-item pair; (2) when mitigating shortcuts, many strategies assume that the test distribution is known in advance. This results in low-quality debiased representations. Worse still, these strategies achieve OOD generalizability with a sacrifice on ID performance. In this work, we present a simple yet effective debiasing strategy, PopGo, which quantifies and reduces the interaction-wise popularity shortcut without any assumptions on the test data. It first learns a shortcut model, which yields a shortcut degree of a user-item pair based on their popularity representations. Then, it trains the CF model by adjusting the predictions with the interaction-wise shortcut degrees. By taking both causal- and information-theoretical looks at PopGo, we can justify why it encourages the CF model to capture the critical popularity-agnostic features while leaving the spurious popularity-relevant patterns out. We use PopGo to debias two high-performing CF models (MF, LightGCN) on four benchmark datasets. On both ID and OOD test sets, PopGo achieves significant gains over the state-of-the-art debiasing strategies (e.g., DICE, MACR).
Space Observation by the Australia Telescope Compact Array: Performance Characterization using GPS Satellite Observation
Oct 07, 2023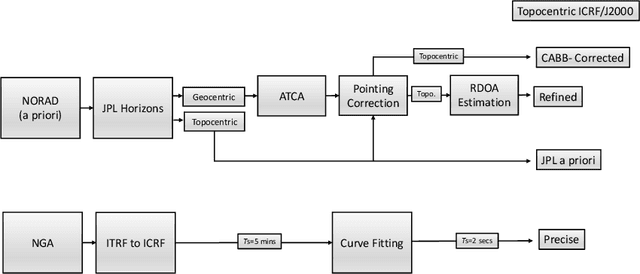
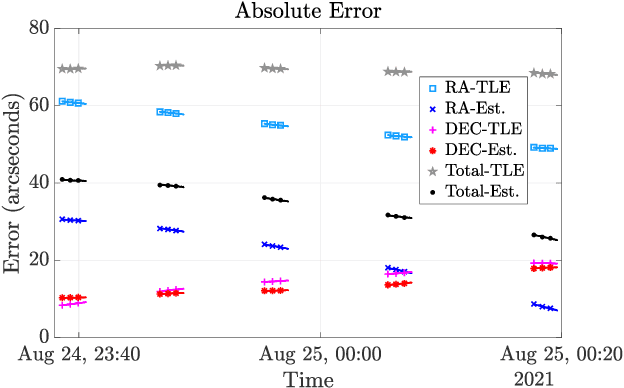
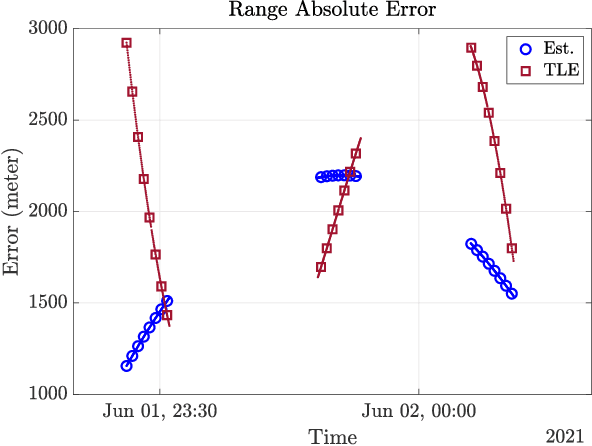
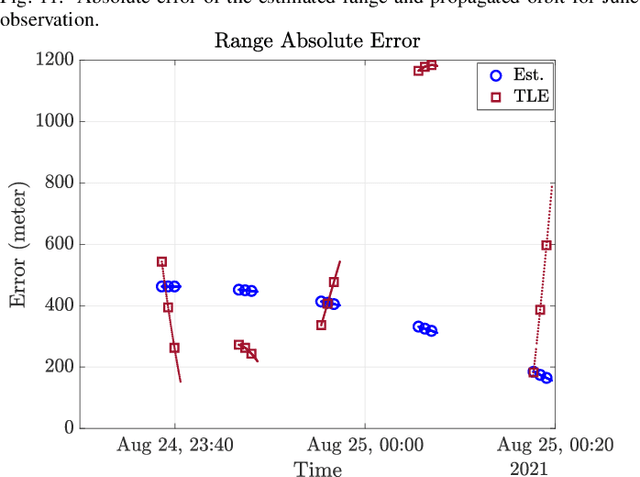
In order to operationalize the Australia Telescope Compact Array (ATCA) for space situational awareness (SSA) applications, we develop a system model for range and direction of arrival (DOA) estimation based on the interferometric data. We employ the observational data collected from global positioning system (GPS) satellites to evaluate the developed model and demonstrate that, compared to a priori location propagated from the most recent two-line element (TLE), both range and direction information are improved significantly.