 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving HEVC Encoding of Rendered Video Data Using True Motion Information
Sep 13, 2023
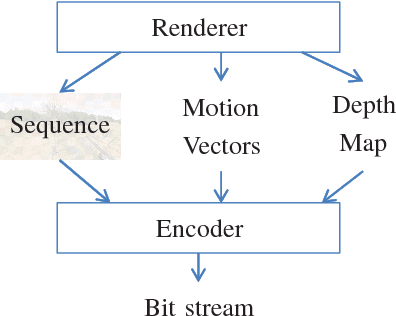
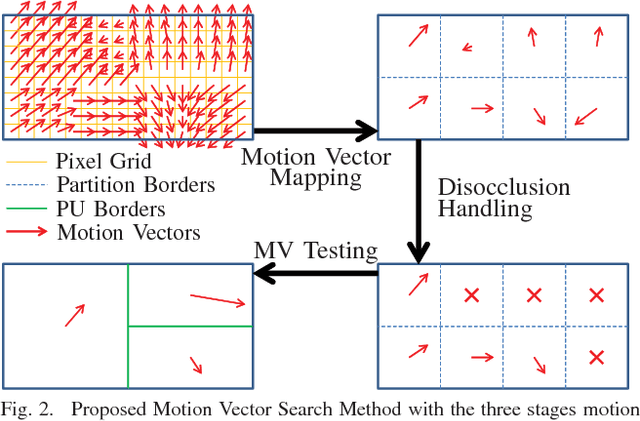
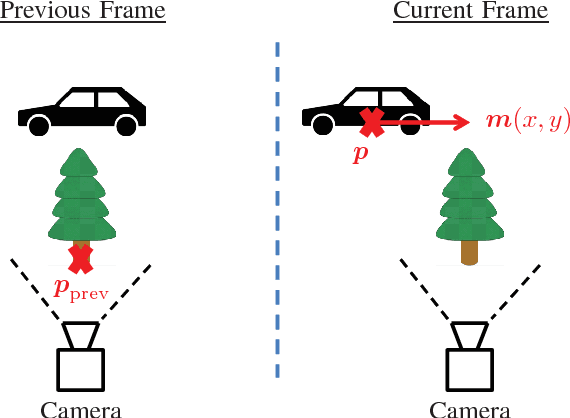

This paper shows that motion vectors representing the true motion of an object in a scene can be exploited to improve the encoding process of computer generated video sequences. Therefore, a set of sequences is presented for which the true motion vectors of the corresponding objects were generated on a per-pixel basis during the rendering process. In addition to conventional motion estimation methods, it is proposed to exploit the computer generated motion vectors to enhance the ratedistortion performance. To this end, a motion vector mapping method including disocclusion handling is presented. It is shown that mean rate savings of 3.78% can be achieved.
* 4 pages, 4 figures
Personality Profiling: How informative are social media profiles in predicting personal information?
Sep 15, 2023Personality profiling has been utilised by companies for targeted advertising, political campaigns and vaccine campaigns. However, the accuracy and versatility of such models still remains relatively unknown. Consequently, we aim to explore the extent to which peoples' online digital footprints can be used to profile their Myers-Briggs personality type. We analyse and compare the results of four models: logistic regression, naive Bayes, support vector machines (SVMs) and random forests. We discover that a SVM model achieves the best accuracy of 20.95% for predicting someones complete personality type. However, logistic regression models perform only marginally worse and are significantly faster to train and perform predictions. We discover that many labelled datasets present substantial class imbalances of personal characteristics on social media, including our own. As a result, we highlight the need for attentive consideration when reporting model performance on these datasets and compare a number of methods for fixing the class-imbalance problems. Moreover, we develop a statistical framework for assessing the importance of different sets of features in our models. We discover some features to be more informative than others in the Intuitive/Sensory (p = 0.032) and Thinking/Feeling (p = 0.019) models. While we apply these methods to Myers-Briggs personality profiling, they could be more generally used for any labelling of individuals on social media.
DiPmark: A Stealthy, Efficient and Resilient Watermark for Large Language Models
Oct 11, 2023Watermarking techniques offer a promising way to secure data via embedding covert information into the data. A paramount challenge in the domain lies in preserving the distribution of original data during watermarking. Our research extends and refines existing watermarking framework, placing emphasis on the importance of a distribution-preserving (DiP) watermark. Contrary to the current strategies, our proposed DiPmark preserves the original token distribution during watermarking (stealthy), is detectable without access to the language model API or weights (efficient), and is robust to moderate changes of tokens (resilient). This is achieved by incorporating a novel reweight strategy, combined with a hash function that assigns unique \textit{i.i.d.} ciphers based on the context. The empirical benchmarks of our approach underscore its stealthiness, efficiency, and resilience, making it a robust solution for watermarking tasks that demand impeccable quality preservation.
Enhancing expressivity transfer in textless speech-to-speech translation
Oct 11, 2023Textless speech-to-speech translation systems are rapidly advancing, thanks to the integration of self-supervised learning techniques. However, existing state-of-the-art systems fall short when it comes to capturing and transferring expressivity accurately across different languages. Expressivity plays a vital role in conveying emotions, nuances, and cultural subtleties, thereby enhancing communication across diverse languages. To address this issue this study presents a novel method that operates at the discrete speech unit level and leverages multilingual emotion embeddings to capture language-agnostic information. Specifically, we demonstrate how these embeddings can be used to effectively predict the pitch and duration of speech units in the target language. Through objective and subjective experiments conducted on a French-to-English translation task, our findings highlight the superior expressivity transfer achieved by our approach compared to current state-of-the-art systems.
Time and Frequency Offset Estimation and Intercarrier Interference Cancellation for AFDM Systems
Oct 11, 2023

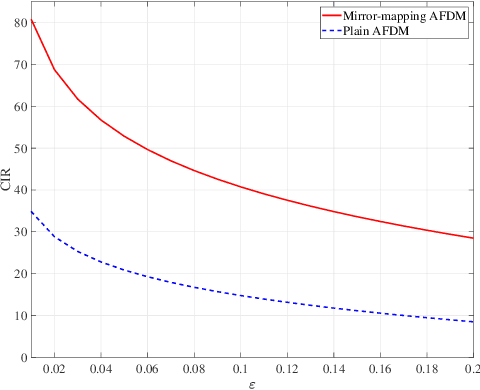
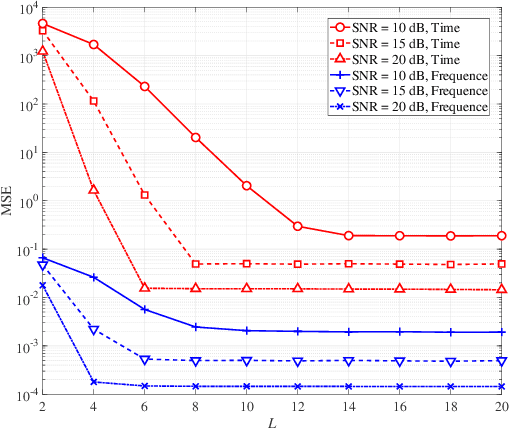
Affine frequency division multiplexing (AFDM) is an emerging multicarrier waveform that offers a potential solution for achieving reliable communication for time-varying channels. This paper proposes two maximum likelihood (ML) estimators of symbol time offset and carrier frequency offset for AFDM systems. The joint ML estimator evaluates the arrival time and frequency offset by comparing the correlations of samples. Moreover, we propose the stepwise ML estimator to reduce the complexity. The proposed estimators exploit the redundant information contained within the chirp-periodic prefix inherent in AFDM symbols, thus dispensing with any additional pilots. To further mitigate the intercarrier interference resulting from the residual frequency offset, we design a mirror-mappingbased scheme for AFDM systems. Numerical results verify the effectiveness of the proposed time and frequency offset estimation criteria and the mirror-mapping-based modulation for AFDM systems.
Radar Instance Transformer: Reliable Moving Instance Segmentation in Sparse Radar Point Clouds
Sep 28, 2023The perception of moving objects is crucial for autonomous robots performing collision avoidance in dynamic environments. LiDARs and cameras tremendously enhance scene interpretation but do not provide direct motion information and face limitations under adverse weather. Radar sensors overcome these limitations and provide Doppler velocities, delivering direct information on dynamic objects. In this paper, we address the problem of moving instance segmentation in radar point clouds to enhance scene interpretation for safety-critical tasks. Our Radar Instance Transformer enriches the current radar scan with temporal information without passing aggregated scans through a neural network. We propose a full-resolution backbone to prevent information loss in sparse point cloud processing. Our instance transformer head incorporates essential information to enhance segmentation but also enables reliable, class-agnostic instance assignments. In sum, our approach shows superior performance on the new moving instance segmentation benchmarks, including diverse environments, and provides model-agnostic modules to enhance scene interpretation. The benchmark is based on the RadarScenes dataset and will be made available upon acceptance.
Extraction of Medication and Temporal Relation from Clinical Text by Harnessing Different Deep Learning Models
Oct 03, 2023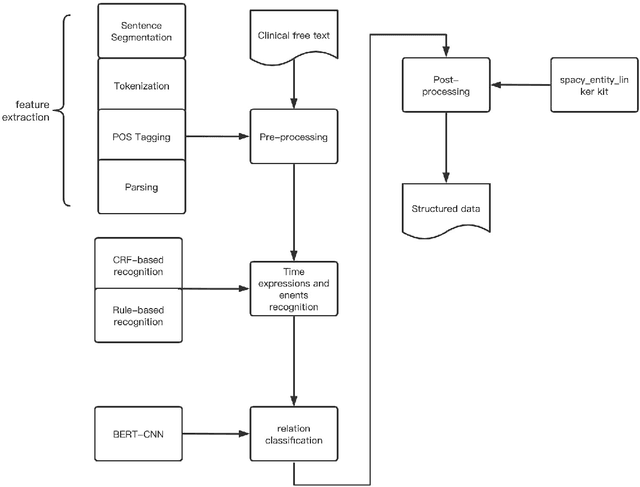
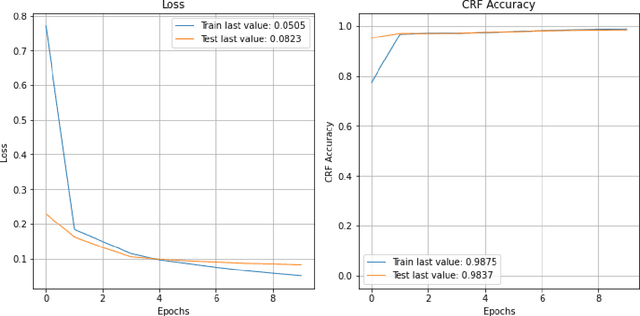
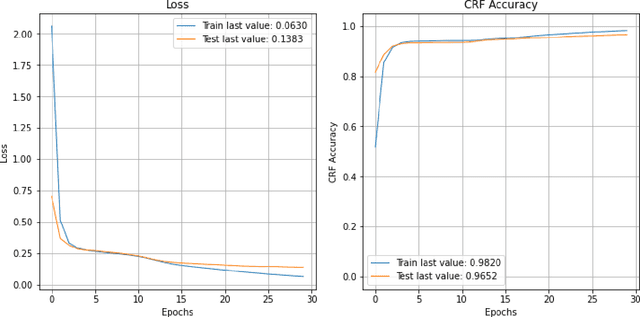
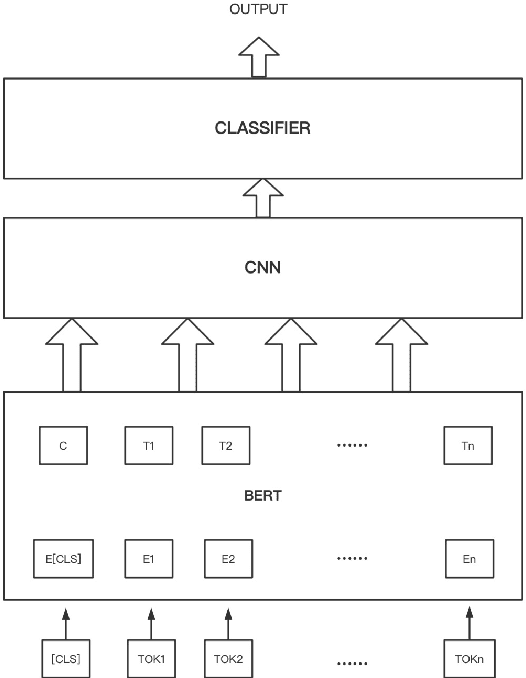
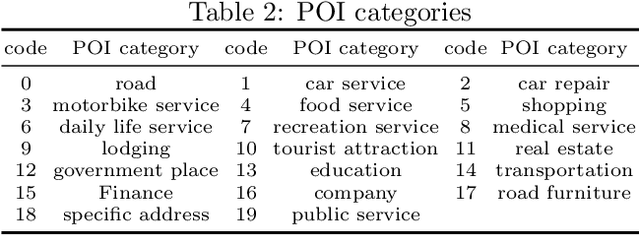
Clinical texts, represented in electronic medical records (EMRs), contain rich medical information and are essential for disease prediction, personalised information recommendation, clinical decision support, and medication pattern mining and measurement. Relation extractions between medication mentions and temporal information can further help clinicians better understand the patients' treatment history. To evaluate the performances of deep learning (DL) and large language models (LLMs) in medication extraction and temporal relations classification, we carry out an empirical investigation of \textbf{MedTem} project using several advanced learning structures including BiLSTM-CRF and CNN-BiLSTM for a clinical domain named entity recognition (NER), and BERT-CNN for temporal relation extraction (RE), in addition to the exploration of different word embedding techniques. Furthermore, we also designed a set of post-processing roles to generate structured output on medications and the temporal relation. Our experiments show that CNN-BiLSTM slightly wins the BiLSTM-CRF model on the i2b2-2009 clinical NER task yielding 75.67, 77.83, and 78.17 for precision, recall, and F1 scores using Macro Average. BERT-CNN model also produced reasonable evaluation scores 64.48, 67.17, and 65.03 for P/R/F1 using Macro Avg on the temporal relation extraction test set from i2b2-2012 challenges. Code and Tools from MedTem will be hosted at \url{https://github.com/HECTA-UoM/MedTem}
Dual-stage Flows-based Generative Modeling for Traceable Urban Planning
Oct 03, 2023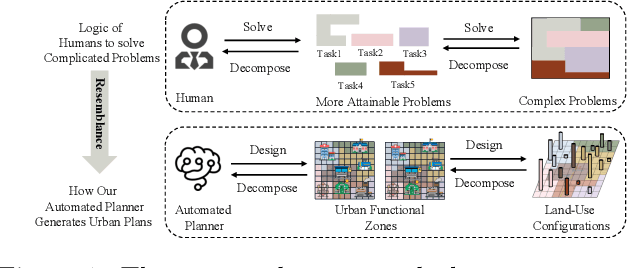


Urban planning, which aims to design feasible land-use configurations for target areas, has become increasingly essential due to the high-speed urbanization process in the modern era. However, the traditional urban planning conducted by human designers can be a complex and onerous task. Thanks to the advancement of deep learning algorithms, researchers have started to develop automated planning techniques. While these models have exhibited promising results, they still grapple with a couple of unresolved limitations: 1) Ignoring the relationship between urban functional zones and configurations and failing to capture the relationship among different functional zones. 2) Less interpretable and stable generation process. To overcome these limitations, we propose a novel generative framework based on normalizing flows, namely Dual-stage Urban Flows (DSUF) framework. Specifically, the first stage is to utilize zone-level urban planning flows to generate urban functional zones based on given surrounding contexts and human guidance. Then we employ an Information Fusion Module to capture the relationship among functional zones and fuse the information of different aspects. The second stage is to use configuration-level urban planning flows to obtain land-use configurations derived from fused information. We design several experiments to indicate that our framework can outperform compared to other generative models for the urban planning task.
LANCAR: Leveraging Language for Context-Aware Robot Locomotion in Unstructured Environments
Sep 30, 2023Robotic locomotion is a challenging task, especially in unstructured terrains. In practice, the optimal locomotion policy can be context-dependent by using the contextual information of encountered terrains in decision-making. Humans can interpret the environmental context for robots, but the ambiguity of human language makes it challenging to use in robot locomotion directly. In this paper, we propose a novel approach, LANCAR, that introduces a context translator that works with reinforcement learning (RL) agents for context-aware locomotion. Our formulation allows a robot to interpret the contextual information from environments generated by human observers or Vision-Language Models (VLM) with Large Language Models (LLM) and use this information to generate contextual embeddings. We incorporate the contextual embeddings with the robot's internal environmental observations as the input to the RL agent's decision neural network. We evaluate LANCAR with contextual information in varying ambiguity levels and compare its performance using several alternative approaches. Our experimental results demonstrate that our approach exhibits good generalizability and adaptability across diverse terrains, by achieving at least 10% of performance improvement in episodic reward over baselines. The experiment video can be found at the following link: https://raaslab.org/projects/LLM_Context_Estimation/.
IPMix: Label-Preserving Data Augmentation Method for Training Robust Classifiers
Oct 13, 2023
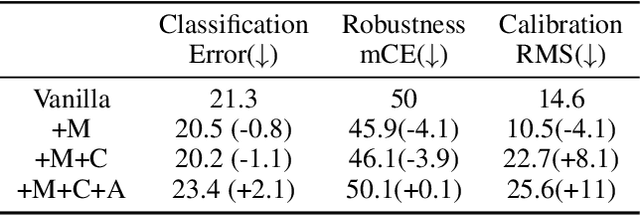
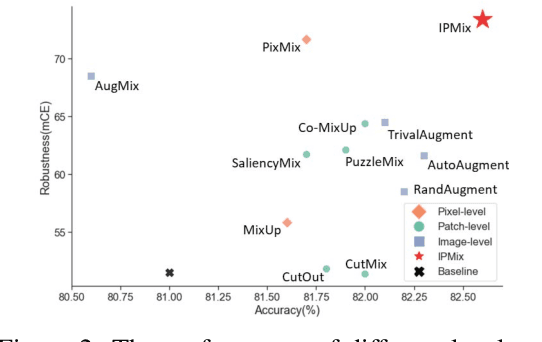
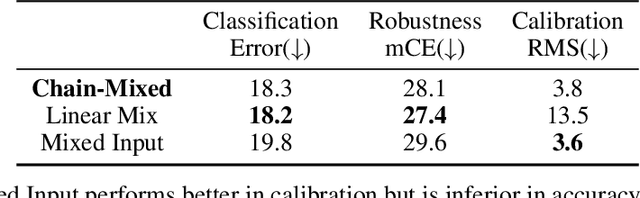
Data augmentation has been proven effective for training high-accuracy convolutional neural network classifiers by preventing overfitting. However, building deep neural networks in real-world scenarios requires not only high accuracy on clean data but also robustness when data distributions shift. While prior methods have proposed that there is a trade-off between accuracy and robustness, we propose IPMix, a simple data augmentation approach to improve robustness without hurting clean accuracy. IPMix integrates three levels of data augmentation (image-level, patch-level, and pixel-level) into a coherent and label-preserving technique to increase the diversity of training data with limited computational overhead. To further improve the robustness, IPMix introduces structural complexity at different levels to generate more diverse images and adopts the random mixing method for multi-scale information fusion. Experiments demonstrate that IPMix outperforms state-of-the-art corruption robustness on CIFAR-C and ImageNet-C. In addition, we show that IPMix also significantly improves the other safety measures, including robustness to adversarial perturbations, calibration, prediction consistency, and anomaly detection, achieving state-of-the-art or comparable results on several benchmarks, including ImageNet-R, ImageNet-A, and ImageNet-O.