 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generative Modeling with Phase Stochastic Bridges
Oct 13, 2023
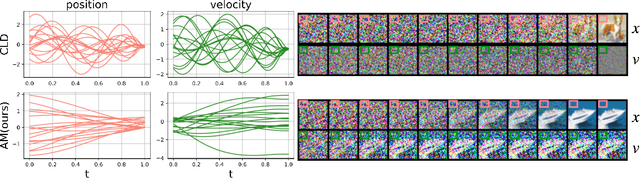

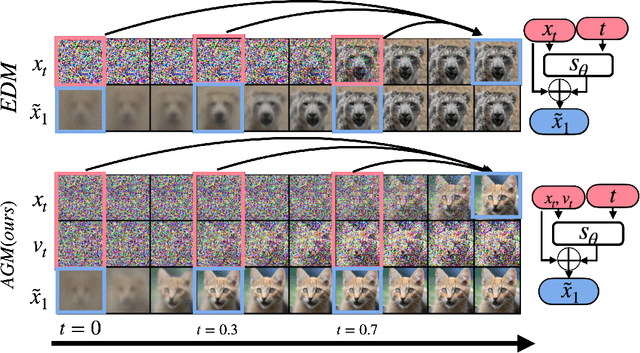

Diffusion models (DMs) represent state-of-the-art generative models for continuous inputs. DMs work by constructing a Stochastic Differential Equation (SDE) in the input space (ie, position space), and using a neural network to reverse it. In this work, we introduce a novel generative modeling framework grounded in \textbf{phase space dynamics}, where a phase space is defined as {an augmented space encompassing both position and velocity.} Leveraging insights from Stochastic Optimal Control, we construct a path measure in the phase space that enables efficient sampling. {In contrast to DMs, our framework demonstrates the capability to generate realistic data points at an early stage of dynamics propagation.} This early prediction sets the stage for efficient data generation by leveraging additional velocity information along the trajectory. On standard image generation benchmarks, our model yields favorable performance over baselines in the regime of small Number of Function Evaluations (NFEs). Furthermore, our approach rivals the performance of diffusion models equipped with efficient sampling techniques, underscoring its potential as a new tool generative modeling.
A Hybrid Approach for Depression Classification: Random Forest-ANN Ensemble on Motor Activity Signals
Oct 13, 2023
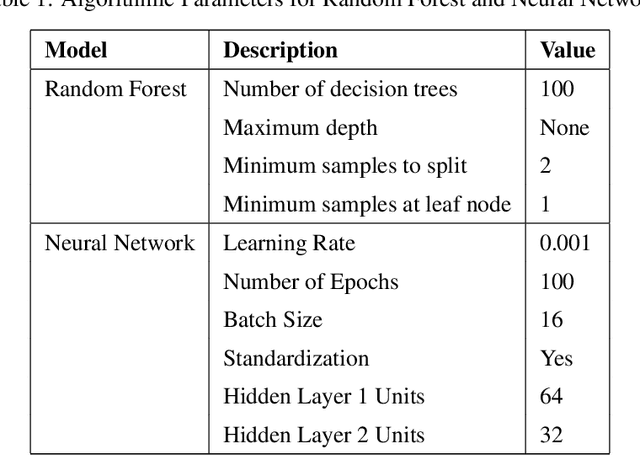
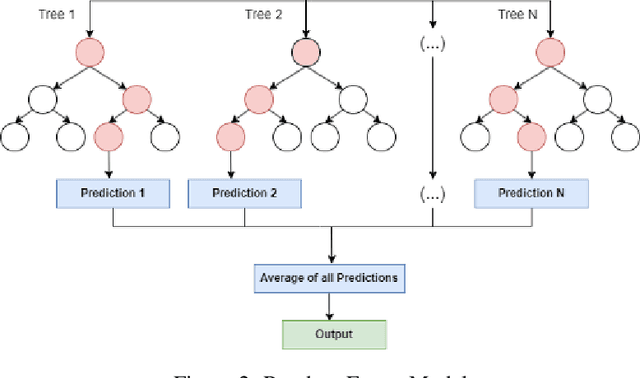
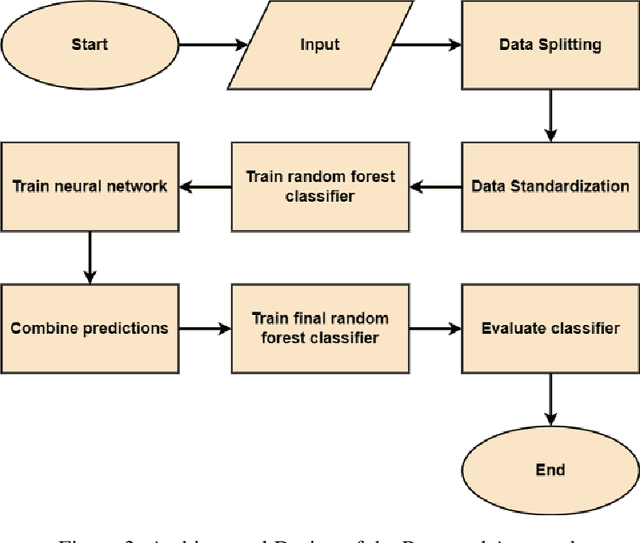
Regarding the rising number of people suffering from mental health illnesses in today's society, the importance of mental health cannot be overstated. Wearable sensors, which are increasingly widely available, provide a potential way to track and comprehend mental health issues. These gadgets not only monitor everyday activities but also continuously record vital signs like heart rate, perhaps providing information on a person's mental state. Recent research has used these sensors in conjunction with machine learning methods to identify patterns relating to different mental health conditions, highlighting the immense potential of this data beyond simple activity monitoring. In this research, we present a novel algorithm called the Hybrid Random forest - Neural network that has been tailored to evaluate sensor data from depressed patients. Our method has a noteworthy accuracy of 80\% when evaluated on a special dataset that included both unipolar and bipolar depressive patients as well as healthy controls. The findings highlight the algorithm's potential for reliably determining a person's depression condition using sensor data, making a substantial contribution to the area of mental health diagnostics.
CIDER: Category-Guided Intent Disentanglement for Accurate Personalized News Recommendation
Oct 13, 2023Personalized news recommendation aims to assist users in finding news articles that align with their interests, which plays a pivotal role in mitigating users' information overload problem. Although many recent works have been studied for better user and news representations, the following challenges have been rarely studied: (C1) How to precisely comprehend a range of intents coupled within a news article? and (C2) How to differentiate news articles with varying post-read preferences in users' click history? To tackle both challenges together, in this paper, we propose a novel personalized news recommendation framework (CIDER) that employs (1) category-guided intent disentanglement for (C1) and (2) consistency-based news representation for (C2). Furthermore, we incorporate a category prediction into the training process of CIDER as an auxiliary task, which provides supplementary supervisory signals to enhance intent disentanglement. Extensive experiments on two real-world datasets reveal that (1) CIDER provides consistent performance improvements over seven state-of-the-art news recommendation methods and (2) the proposed strategies significantly improve the model accuracy of CIDER.
Protecting Sensitive Data through Federated Co-Training
Oct 09, 2023


In many critical applications, sensitive data is inherently distributed. Federated learning trains a model collaboratively by aggregating the parameters of locally trained models. This avoids exposing sensitive local data. It is possible, though, to infer upon the sensitive data from the shared model parameters. At the same time, many types of machine learning models do not lend themselves to parameter aggregation, such as decision trees, or rule ensembles. It has been observed that in many applications, in particular healthcare, large unlabeled datasets are publicly available. They can be used to exchange information between clients by distributed distillation, i.e., co-regularizing local training via the discrepancy between the soft predictions of each local client on the unlabeled dataset. This, however, still discloses private information and restricts the types of models to those trainable via gradient-based methods. We propose to go one step further and use a form of federated co-training, where local hard labels on the public unlabeled datasets are shared and aggregated into a consensus label. This consensus label can be used for local training by any supervised machine learning model. We show that this federated co-training approach achieves a model quality comparable to both federated learning and distributed distillation on a set of benchmark datasets and real-world medical datasets. It improves privacy over both approaches, protecting against common membership inference attacks to the highest degree. Furthermore, we show that federated co-training can collaboratively train interpretable models, such as decision trees and rule ensembles, achieving a model quality comparable to centralized training.
Topological data analysis of human vowels: Persistent homologies across representation spaces
Oct 10, 2023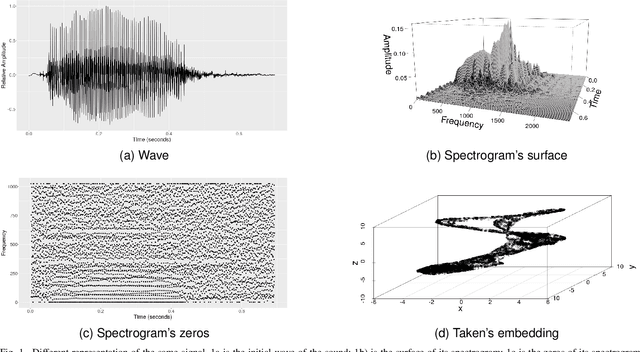
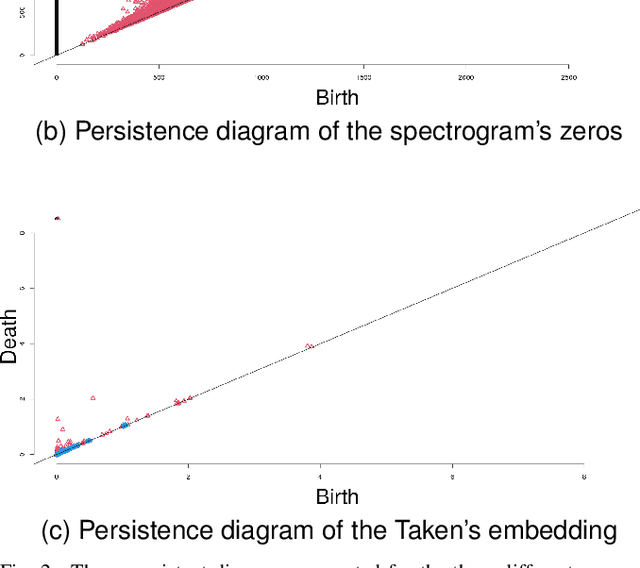
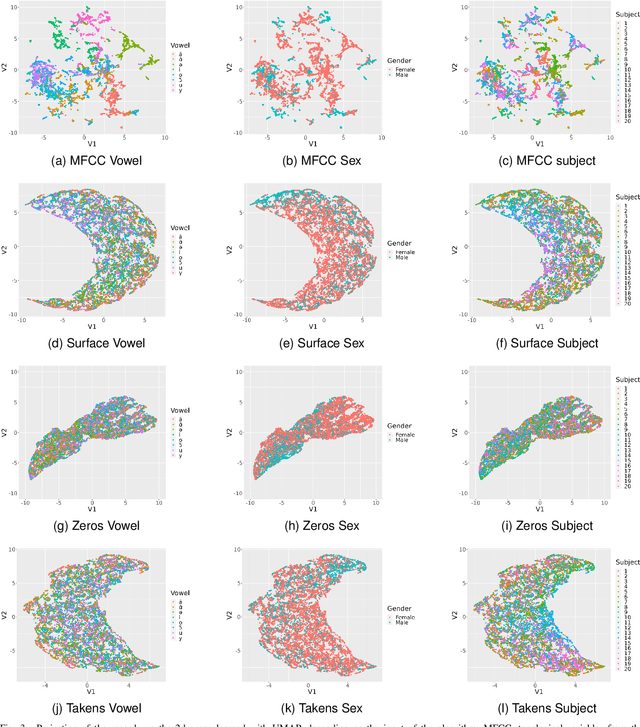
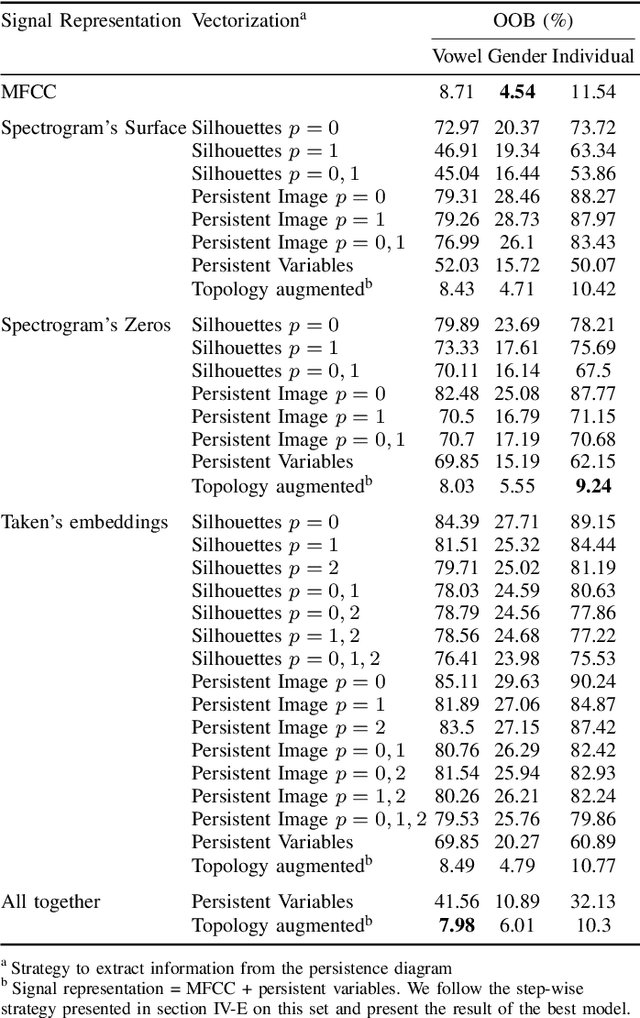
Topological Data Analysis (TDA) has been successfully used for various tasks in signal/image processing, from visualization to supervised/unsupervised classification. Often, topological characteristics are obtained from persistent homology theory. The standard TDA pipeline starts from the raw signal data or a representation of it. Then, it consists in building a multiscale topological structure on the top of the data using a pre-specified filtration, and finally to compute the topological signature to be further exploited. The commonly used topological signature is a persistent diagram (or transformations of it). Current research discusses the consequences of the many ways to exploit topological signatures, much less often the choice of the filtration, but to the best of our knowledge, the choice of the representation of a signal has not been the subject of any study yet. This paper attempts to provide some answers on the latter problem. To this end, we collected real audio data and built a comparative study to assess the quality of the discriminant information of the topological signatures extracted from three different representation spaces. Each audio signal is represented as i) an embedding of observed data in a higher dimensional space using Taken's representation, ii) a spectrogram viewed as a surface in a 3D ambient space, iii) the set of spectrogram's zeroes. From vowel audio recordings, we use topological signature for three prediction problems: speaker gender, vowel type, and individual. We show that topologically-augmented random forest improves the Out-of-Bag Error (OOB) over solely based Mel-Frequency Cepstral Coefficients (MFCC) for the last two problems. Our results also suggest that the topological information extracted from different signal representations is complementary, and that spectrogram's zeros offers the best improvement for gender prediction.
A Machine Learning Approach to Predicting Single Event Upsets
Oct 09, 2023A single event upset (SEU) is a critical soft error that occurs in semiconductor devices on exposure to ionising particles from space environments. SEUs cause bit flips in the memory component of semiconductors. This creates a multitude of safety hazards as stored information becomes less reliable. Currently, SEUs are only detected several hours after their occurrence. CREMER, the model presented in this paper, predicts SEUs in advance using machine learning. CREMER uses only positional data to predict SEU occurrence, making it robust, inexpensive and scalable. Upon implementation, the improved reliability of memory devices will create a digitally safer environment onboard space vehicles.
Classification Method of Road Surface Condition and Type with LiDAR Using Spatiotemporal Information
Aug 11, 2023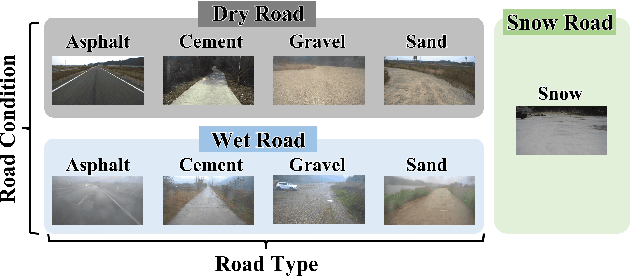

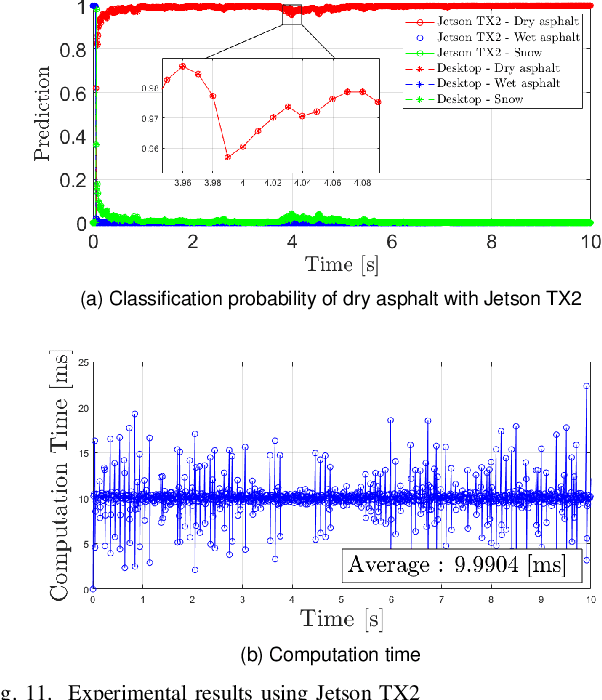
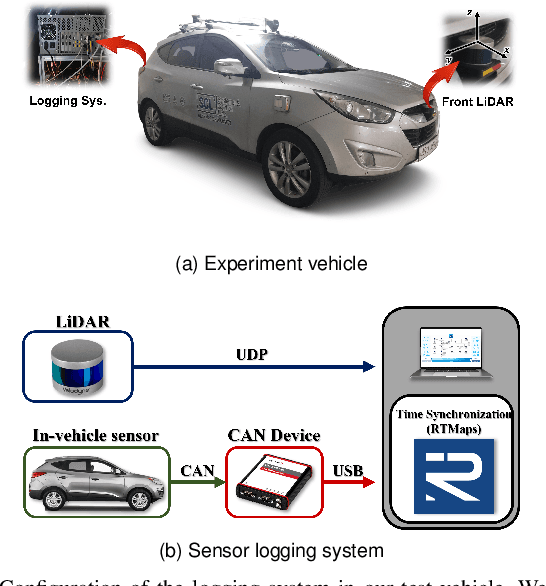
This paper proposes a spatiotemporal architecture with a deep neural network (DNN) for road surface conditions and types classification using LiDAR. It is known that LiDAR provides information on the reflectivity and number of point clouds depending on a road surface. Thus, this paper utilizes the information to classify the road surface. We divided the front road area into four subregions. First, we constructed feature vectors using each subregion's reflectivity, number of point clouds, and in-vehicle information. Second, the DNN classifies road surface conditions and types for each subregion. Finally, the output of the DNN feeds into the spatiotemporal process to make the final classification reflecting vehicle speed and probability given by the outcomes of softmax functions of the DNN output layer. To validate the effectiveness of the proposed method, we performed a comparative study with five other algorithms. With the proposed DNN, we obtained the highest accuracy of 98.0\% and 98.6\% for two subregions near the vehicle. In addition, we implemented the proposed method on the Jetson TX2 board to confirm that it is applicable in real-time.
Get the gist? Using large language models for few-shot decontextualization
Oct 10, 2023
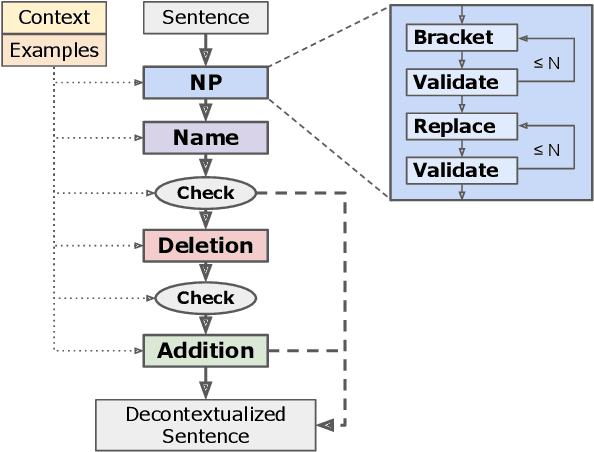
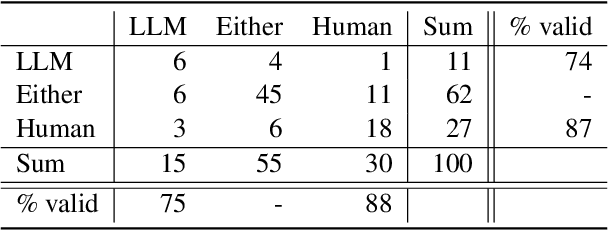
In many NLP applications that involve interpreting sentences within a rich context -- for instance, information retrieval systems or dialogue systems -- it is desirable to be able to preserve the sentence in a form that can be readily understood without context, for later reuse -- a process known as ``decontextualization''. While previous work demonstrated that generative Seq2Seq models could effectively perform decontextualization after being fine-tuned on a specific dataset, this approach requires expensive human annotations and may not transfer to other domains. We propose a few-shot method of decontextualization using a large language model, and present preliminary results showing that this method achieves viable performance on multiple domains using only a small set of examples.
Radar Instance Transformer: Reliable Moving Instance Segmentation in Sparse Radar Point Clouds
Sep 28, 2023The perception of moving objects is crucial for autonomous robots performing collision avoidance in dynamic environments. LiDARs and cameras tremendously enhance scene interpretation but do not provide direct motion information and face limitations under adverse weather. Radar sensors overcome these limitations and provide Doppler velocities, delivering direct information on dynamic objects. In this paper, we address the problem of moving instance segmentation in radar point clouds to enhance scene interpretation for safety-critical tasks. Our Radar Instance Transformer enriches the current radar scan with temporal information without passing aggregated scans through a neural network. We propose a full-resolution backbone to prevent information loss in sparse point cloud processing. Our instance transformer head incorporates essential information to enhance segmentation but also enables reliable, class-agnostic instance assignments. In sum, our approach shows superior performance on the new moving instance segmentation benchmarks, including diverse environments, and provides model-agnostic modules to enhance scene interpretation. The benchmark is based on the RadarScenes dataset and will be made available upon acceptance.
Accurate Cold-start Bundle Recommendation via Popularity-based Coalescence and Curriculum Heating
Oct 05, 2023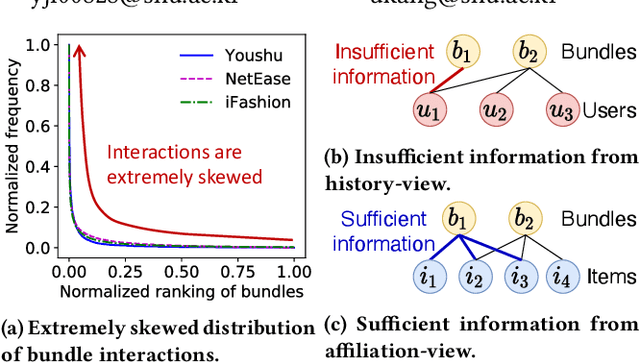

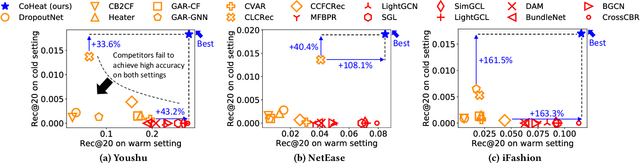
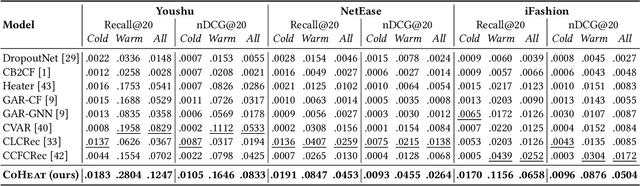
How can we accurately recommend cold-start bundles to users? The cold-start problem in bundle recommendation is critical in practical scenarios since new bundles are continuously created for various marketing purposes. Despite its importance, no previous studies have addressed cold-start bundle recommendation. Moreover, existing methods for cold-start item recommendation overly rely on historical information, even for unpopular bundles, failing to tackle the primary challenge of the highly skewed distribution of bundle interactions. In this work, we propose CoHeat (Popularity-based Coalescence and Curriculum Heating), an accurate approach for the cold-start bundle recommendation. CoHeat tackles the highly skewed distribution of bundle interactions by incorporating both historical and affiliation information based on the bundle's popularity when estimating the user-bundle relationship. Furthermore, CoHeat effectively learns latent representations by exploiting curriculum learning and contrastive learning. CoHeat demonstrates superior performance in cold-start bundle recommendation, achieving up to 193% higher nDCG@20 compared to the best competitor.