 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Zero-Shot Object Goal Visual Navigation With Class-Independent Relationship Network
Oct 15, 2023
This paper investigates the zero-shot object goal visual navigation problem. In the object goal visual navigation task, the agent needs to locate navigation targets from its egocentric visual input. "Zero-shot" means that the target the agent needs to find is not trained during the training phase. To address the issue of coupling navigation ability with target features during training, we propose the Class-Independent Relationship Network (CIRN). This method combines target detection information with the relative semantic similarity between the target and the navigation target, and constructs a brand new state representation based on similarity ranking, this state representation does not include target feature or environment feature, effectively decoupling the agent's navigation ability from target features. And a Graph Convolutional Network (GCN) is employed to learn the relationships between different objects based on their similarities. During testing, our approach demonstrates strong generalization capabilities, including zero-shot navigation tasks with different targets and environments. Through extensive experiments in the AI2-THOR virtual environment, our method outperforms the current state-of-the-art approaches in the zero-shot object goal visual navigation task. Furthermore, we conducted experiments in more challenging cross-target and cross-scene settings, which further validate the robustness and generalization ability of our method. Our code is available at: https://github.com/SmartAndCleverRobot/ICRA-CIRN.
Reconstructing 3D Human Pose from RGB-D Data with Occlusions
Oct 15, 2023We propose a new method to reconstruct the 3D human body from RGB-D images with occlusions. The foremost challenge is the incompleteness of the RGB-D data due to occlusions between the body and the environment, leading to implausible reconstructions that suffer from severe human-scene penetration. To reconstruct a semantically and physically plausible human body, we propose to reduce the solution space based on scene information and prior knowledge. Our key idea is to constrain the solution space of the human body by considering the occluded body parts and visible body parts separately: modeling all plausible poses where the occluded body parts do not penetrate the scene, and constraining the visible body parts using depth data. Specifically, the first component is realized by a neural network that estimates the candidate region named the "free zone", a region carved out of the open space within which it is safe to search for poses of the invisible body parts without concern for penetration. The second component constrains the visible body parts using the "truncated shadow volume" of the scanned body point cloud. Furthermore, we propose to use a volume matching strategy, which yields better performance than surface matching, to match the human body with the confined region. We conducted experiments on the PROX dataset, and the results demonstrate that our method produces more accurate and plausible results compared with other methods.
RSVP: Customer Intent Detection via Agent Response Contrastive and Generative Pre-Training
Oct 15, 2023The dialogue systems in customer services have been developed with neural models to provide users with precise answers and round-the-clock support in task-oriented conversations by detecting customer intents based on their utterances. Existing intent detection approaches have highly relied on adaptively pre-training language models with large-scale datasets, yet the predominant cost of data collection may hinder their superiority. In addition, they neglect the information within the conversational responses of the agents, which have a lower collection cost, but are significant to customer intent as agents must tailor their replies based on the customers' intent. In this paper, we propose RSVP, a self-supervised framework dedicated to task-oriented dialogues, which utilizes agent responses for pre-training in a two-stage manner. Specifically, we introduce two pre-training tasks to incorporate the relations of utterance-response pairs: 1) Response Retrieval by selecting a correct response from a batch of candidates, and 2) Response Generation by mimicking agents to generate the response to a given utterance. Our benchmark results for two real-world customer service datasets show that RSVP significantly outperforms the state-of-the-art baselines by 4.95% for accuracy, 3.4% for MRR@3, and 2.75% for MRR@5 on average. Extensive case studies are investigated to show the validity of incorporating agent responses into the pre-training stage.
Cell-Free Massive MIMO Surveillance Systems
Oct 15, 2023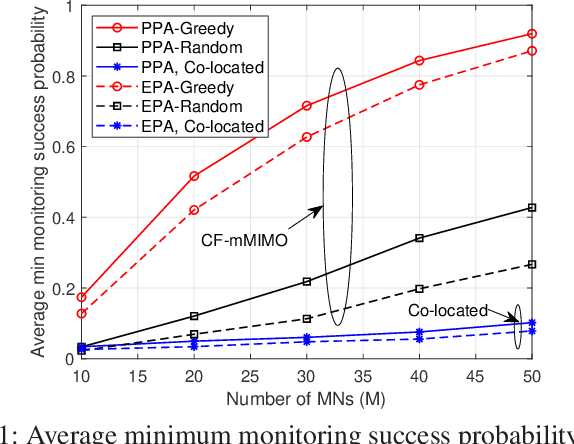
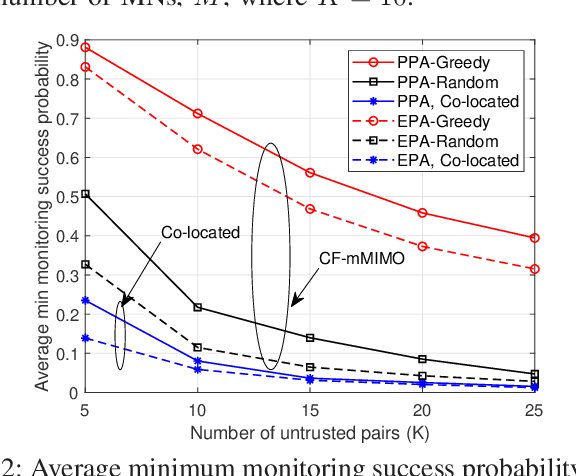
Wireless surveillance, in which untrusted communications links are proactively monitored by legitimate agencies, has started to garner a lot of interest for enhancing the national security. In this paper, we propose a new cell-free massive multiple-input multiple-output (CF-mMIMO) wireless surveillance system, where a large number of distributed multi-antenna aided legitimate monitoring nodes (MNs) embark on either observing or jamming untrusted communication links. To facilitate concurrent observing and jamming, a subset of the MNs is selected for monitoring the untrusted transmitters (UTs), while the remaining MNs are selected for jamming the untrusted receivers (URs). We analyze the performance of CF-mMIMO wireless surveillance and derive a closed-form expression for the monitoring success probability of MNs. We then propose a greedy algorithm for the observing vs, jamming mode assignment of MNs, followed by the conception of a jamming transmit power allocation algorithm for maximizing the minimum monitoring success probability concerning all the UT and UR pairs based on the associated long-term channel state information knowledge. In conclusion, our proposed CF-mMIMO system is capable of significantly improving the performance of the MNs compared to that of the state-of-the-art baseline. In scenarios of a mediocre number of MNs, our proposed scheme provides an 11-fold improvement in the minimum monitoring success probability compared to its co-located mMIMO benchmarker.
LOVECon: Text-driven Training-Free Long Video Editing with ControlNet
Oct 15, 2023Leveraging pre-trained conditional diffusion models for video editing without further tuning has gained increasing attention due to its promise in film production, advertising, etc. Yet, seminal works in this line fall short in generation length, temporal coherence, or fidelity to the source video. This paper aims to bridge the gap, establishing a simple and effective baseline for training-free diffusion model-based long video editing. As suggested by prior arts, we build the pipeline upon ControlNet, which excels at various image editing tasks based on text prompts. To break down the length constraints caused by limited computational memory, we split the long video into consecutive windows and develop a novel cross-window attention mechanism to ensure the consistency of global style and maximize the smoothness among windows. To achieve more accurate control, we extract the information from the source video via DDIM inversion and integrate the outcomes into the latent states of the generations. We also incorporate a video frame interpolation model to mitigate the frame-level flickering issue. Extensive empirical studies verify the superior efficacy of our method over competing baselines across scenarios, including the replacement of the attributes of foreground objects, style transfer, and background replacement. In particular, our method manages to edit videos with up to 128 frames according to user requirements. Code is available at https://github.com/zhijie-group/LOVECon.
FuseSR: Super Resolution for Real-time Rendering through Efficient Multi-resolution Fusion
Oct 15, 2023The workload of real-time rendering is steeply increasing as the demand for high resolution, high refresh rates, and high realism rises, overwhelming most graphics cards. To mitigate this problem, one of the most popular solutions is to render images at a low resolution to reduce rendering overhead, and then manage to accurately upsample the low-resolution rendered image to the target resolution, a.k.a. super-resolution techniques. Most existing methods focus on exploiting information from low-resolution inputs, such as historical frames. The absence of high frequency details in those LR inputs makes them hard to recover fine details in their high-resolution predictions. In this paper, we propose an efficient and effective super-resolution method that predicts high-quality upsampled reconstructions utilizing low-cost high-resolution auxiliary G-Buffers as additional input. With LR images and HR G-buffers as input, the network requires to align and fuse features at multi resolution levels. We introduce an efficient and effective H-Net architecture to solve this problem and significantly reduce rendering overhead without noticeable quality deterioration. Experiments show that our method is able to produce temporally consistent reconstructions in $4 \times 4$ and even challenging $8 \times 8$ upsampling cases at 4K resolution with real-time performance, with substantially improved quality and significant performance boost compared to existing works.
MAGIC: Detecting Advanced Persistent Threats via Masked Graph Representation Learning
Oct 15, 2023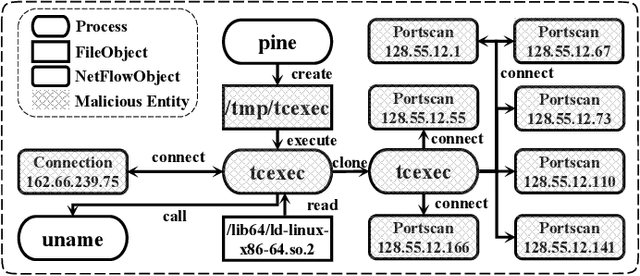
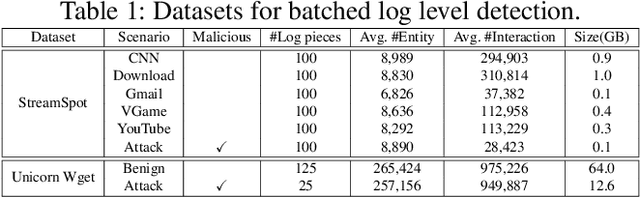
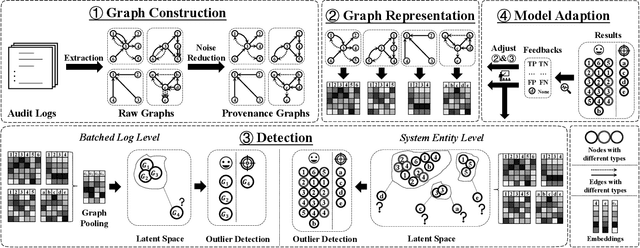
Advance Persistent Threats (APTs), adopted by most delicate attackers, are becoming increasing common and pose great threat to various enterprises and institutions. Data provenance analysis on provenance graphs has emerged as a common approach in APT detection. However, previous works have exhibited several shortcomings: (1) requiring attack-containing data and a priori knowledge of APTs, (2) failing in extracting the rich contextual information buried within provenance graphs and (3) becoming impracticable due to their prohibitive computation overhead and memory consumption. In this paper, we introduce MAGIC, a novel and flexible self-supervised APT detection approach capable of performing multi-granularity detection under different level of supervision. MAGIC leverages masked graph representation learning to model benign system entities and behaviors, performing efficient deep feature extraction and structure abstraction on provenance graphs. By ferreting out anomalous system behaviors via outlier detection methods, MAGIC is able to perform both system entity level and batched log level APT detection. MAGIC is specially designed to handle concept drift with a model adaption mechanism and successfully applies to universal conditions and detection scenarios. We evaluate MAGIC on three widely-used datasets, including both real-world and simulated attacks. Evaluation results indicate that MAGIC achieves promising detection results in all scenarios and shows enormous advantage over state-of-the-art APT detection approaches in performance overhead.
Uncertainty-Aware Planning for Heterogeneous Robot Teams using Dynamic Topological Graphs and Mixed-Integer Programming
Oct 12, 2023Planning under uncertainty is a fundamental challenge in robotics. For multi-robot teams, the challenge is further exacerbated, since the planning problem can quickly become computationally intractable as the number of robots increase. In this paper, we propose a novel approach for planning under uncertainty using heterogeneous multi-robot teams. In particular, we leverage the notion of a dynamic topological graph and mixed-integer programming to generate multi-robot plans that deploy fast scout team members to reduce uncertainty about the environment. We test our approach in a number of representative scenarios where the robot team must move through an environment while minimizing detection in the presence of uncertain observer positions. We demonstrate that our approach is sufficiently computationally tractable for real-time re-planning in changing environments, can improve performance in the presence of imperfect information, and can be adjusted to accommodate different risk profiles.
ClothesNet: An Information-Rich 3D Garment Model Repository with Simulated Clothes Environment
Aug 19, 2023
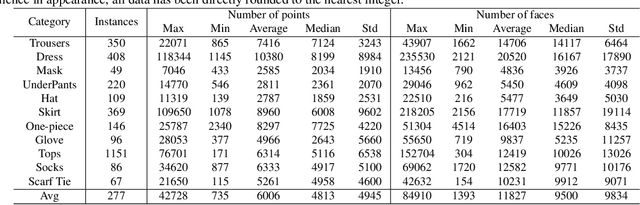


We present ClothesNet: a large-scale dataset of 3D clothes objects with information-rich annotations. Our dataset consists of around 4400 models covering 11 categories annotated with clothes features, boundary lines, and keypoints. ClothesNet can be used to facilitate a variety of computer vision and robot interaction tasks. Using our dataset, we establish benchmark tasks for clothes perception, including classification, boundary line segmentation, and keypoint detection, and develop simulated clothes environments for robotic interaction tasks, including rearranging, folding, hanging, and dressing. We also demonstrate the efficacy of our ClothesNet in real-world experiments. Supplemental materials and dataset are available on our project webpage.
Large Models for Time Series and Spatio-Temporal Data: A Survey and Outlook
Oct 16, 2023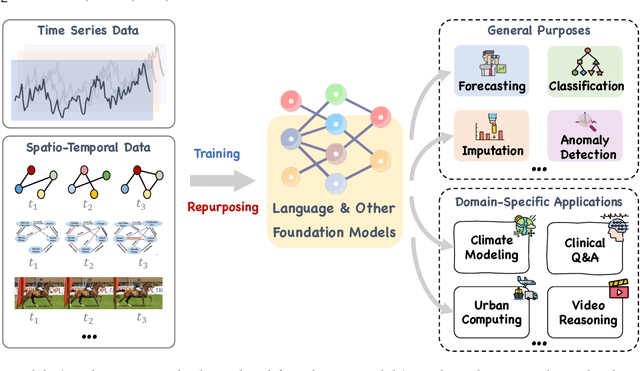
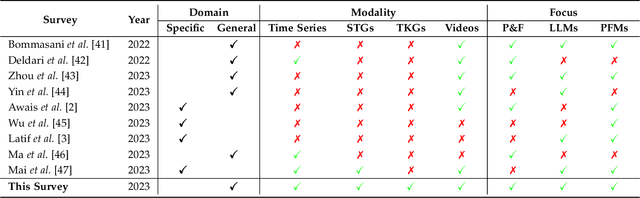
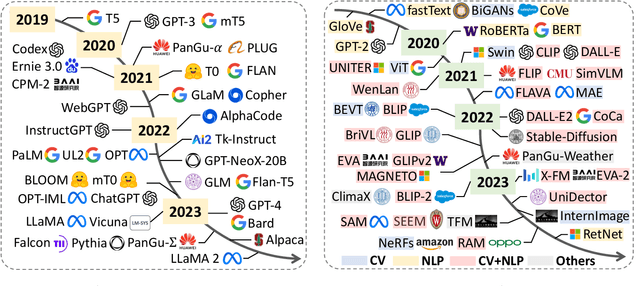
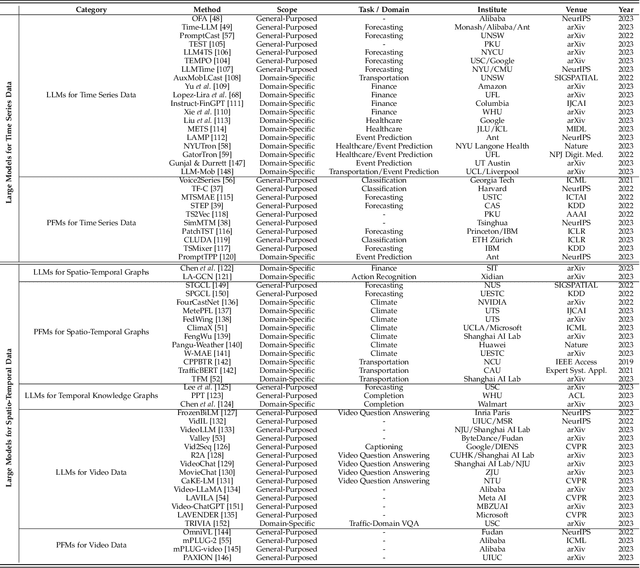
Temporal data, notably time series and spatio-temporal data, are prevalent in real-world applications. They capture dynamic system measurements and are produced in vast quantities by both physical and virtual sensors. Analyzing these data types is vital to harnessing the rich information they encompass and thus benefits a wide range of downstream tasks. Recent advances in large language and other foundational models have spurred increased use of these models in time series and spatio-temporal data mining. Such methodologies not only enable enhanced pattern recognition and reasoning across diverse domains but also lay the groundwork for artificial general intelligence capable of comprehending and processing common temporal data. In this survey, we offer a comprehensive and up-to-date review of large models tailored (or adapted) for time series and spatio-temporal data, spanning four key facets: data types, model categories, model scopes, and application areas/tasks. Our objective is to equip practitioners with the knowledge to develop applications and further research in this underexplored domain. We primarily categorize the existing literature into two major clusters: large models for time series analysis (LM4TS) and spatio-temporal data mining (LM4STD). On this basis, we further classify research based on model scopes (i.e., general vs. domain-specific) and application areas/tasks. We also provide a comprehensive collection of pertinent resources, including datasets, model assets, and useful tools, categorized by mainstream applications. This survey coalesces the latest strides in large model-centric research on time series and spatio-temporal data, underscoring the solid foundations, current advances, practical applications, abundant resources, and future research opportunities.