 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Instruction Tuning with Human Curriculum
Oct 14, 2023
The dominant paradigm for instruction tuning is the random-shuffled training of maximally diverse instruction-response pairs. This paper explores the potential benefits of applying a structured cognitive learning approach to instruction tuning in contemporary large language models like ChatGPT and GPT-4. Unlike the previous conventional randomized instruction dataset, we propose a highly structured synthetic dataset that mimics the progressive and organized nature of human education. We curate our dataset by aligning it with educational frameworks, incorporating meta information including its topic and cognitive rigor level for each sample. Our dataset covers comprehensive fine-grained topics spanning diverse educational stages (from middle school to graduate school) with various questions for each topic to enhance conceptual depth using Bloom's taxonomy-a classification framework distinguishing various levels of human cognition for each concept. The results demonstrate that this cognitive rigorous training approach yields significant performance enhancements - +3.06 on the MMLU benchmark and an additional +1.28 on AI2 Reasoning Challenge (hard set) - compared to conventional randomized training, all while avoiding additional computational costs. This research highlights the potential of leveraging human learning principles to enhance the capabilities of language models in comprehending and responding to complex instructions and tasks.
Causally Linking Health Application Data and Personal Information Management Tools
Aug 11, 2023The proliferation of consumer health devices such as smart watches, sleep monitors, smart scales, etc, in many countries, has not only led to growing interest in health monitoring, but also to the development of a countless number of ``smart'' applications to support the exploration of such data by members of the general public, sometimes with integration into professional health services. While a variety of health data streams has been made available by such devices to users, these streams are often presented as separate time-series visualizations, in which the potential relationships between health variables are not explicitly made visible. Furthermore, despite the fact that other aspects of life, such as work and social connectivity, have become increasingly digitised, health and well-being applications make little use of the potentially useful contextual information provided by widely used personal information management tools, such as shared calendar and email systems. This paper presents a framework for the integration of these diverse data sources, analytic and visualization tools, with inference methods and graphical user interfaces to help users by highlighting causal connections among such time-series.
Harnessing Administrative Data Inventories to Create a Reliable Transnational Reference Database for Crop Type Monitoring
Oct 10, 2023With leaps in machine learning techniques and their applicationon Earth observation challenges has unlocked unprecedented performance across the domain. While the further development of these methods was previously limited by the availability and volume of sensor data and computing resources, the lack of adequate reference data is now constituting new bottlenecks. Since creating such ground-truth information is an expensive and error-prone task, new ways must be devised to source reliable, high-quality reference data on large scales. As an example, we showcase E URO C ROPS, a reference dataset for crop type classification that aggregates and harmonizes administrative data surveyed in different countries with the goal of transnational interoperability.
Learning bounded-degree polytrees with known skeleton
Oct 10, 2023We establish finite-sample guarantees for efficient proper learning of bounded-degree polytrees, a rich class of high-dimensional probability distributions and a subclass of Bayesian networks, a widely-studied type of graphical model. Recently, Bhattacharyya et al. (2021) obtained finite-sample guarantees for recovering tree-structured Bayesian networks, i.e., 1-polytrees. We extend their results by providing an efficient algorithm which learns $d$-polytrees in polynomial time and sample complexity for any bounded $d$ when the underlying undirected graph (skeleton) is known. We complement our algorithm with an information-theoretic sample complexity lower bound, showing that the dependence on the dimension and target accuracy parameters are nearly tight.
Spatial-information Guided Adaptive Context-aware Network for Efficient RGB-D Semantic Segmentation
Aug 11, 2023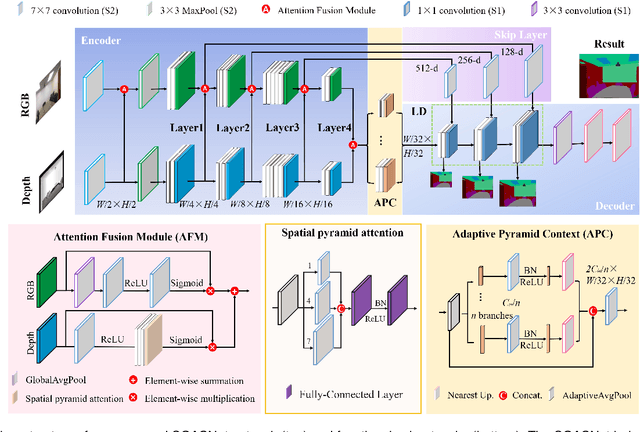
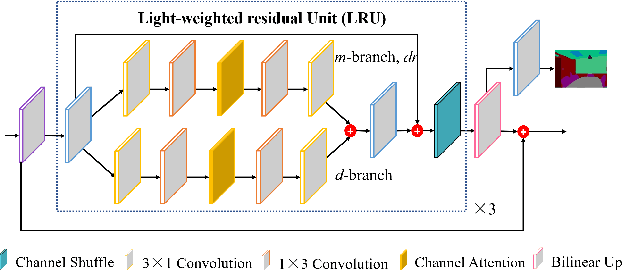
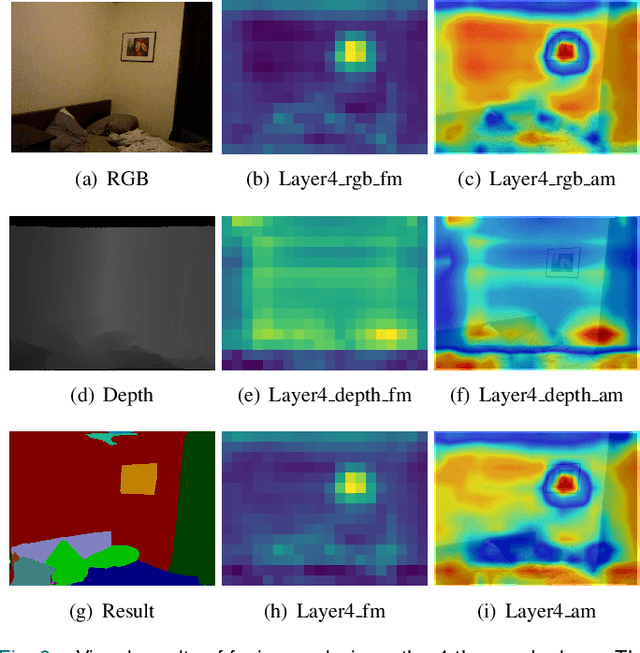
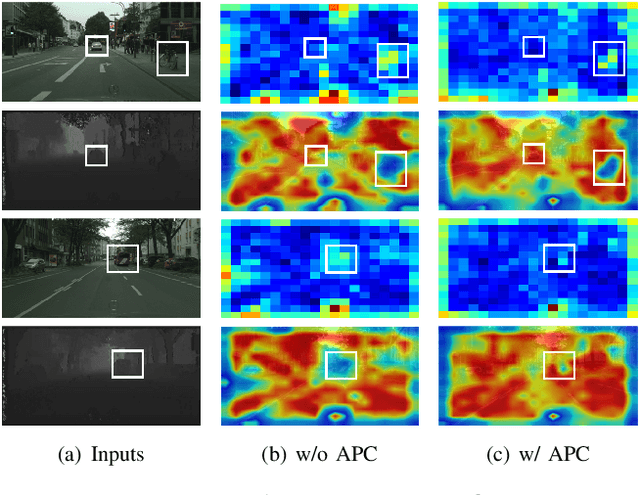
Efficient RGB-D semantic segmentation has received considerable attention in mobile robots, which plays a vital role in analyzing and recognizing environmental information. According to previous studies, depth information can provide corresponding geometric relationships for objects and scenes, but actual depth data usually exist as noise. To avoid unfavorable effects on segmentation accuracy and computation, it is necessary to design an efficient framework to leverage cross-modal correlations and complementary cues. In this paper, we propose an efficient lightweight encoder-decoder network that reduces the computational parameters and guarantees the robustness of the algorithm. Working with channel and spatial fusion attention modules, our network effectively captures multi-level RGB-D features. A globally guided local affinity context module is proposed to obtain sufficient high-level context information. The decoder utilizes a lightweight residual unit that combines short- and long-distance information with a few redundant computations. Experimental results on NYUv2, SUN RGB-D, and Cityscapes datasets show that our method achieves a better trade-off among segmentation accuracy, inference time, and parameters than the state-of-the-art methods. The source code will be at https://github.com/MVME-HBUT/SGACNet
Integrating 3D City Data through Knowledge Graphs
Oct 17, 2023CityGML is a widely adopted standard by the Open Geospatial Consortium (OGC) for representing and exchanging 3D city models. The representation of semantic and topological properties in CityGML makes it possible to query such 3D city data to perform analysis in various applications, e.g., security management and emergency response, energy consumption and estimation, and occupancy measurement. However, the potential of querying CityGML data has not been fully exploited. The official GML/XML encoding of CityGML is only intended as an exchange format but is not suitable for query answering. The most common way of dealing with CityGML data is to store them in the 3DCityDB system as relational tables and then query them with the standard SQL query language. Nevertheless, for end users, it remains a challenging task to formulate queries over 3DCityDB directly for their ad-hoc analytical tasks, because there is a gap between the conceptual semantics of CityGML and the relational schema adopted in 3DCityDB. In fact, the semantics of CityGML itself can be modeled as a suitable ontology. The technology of Knowledge Graphs (KGs), where an ontology is at the core, is a good solution to bridge such a gap. Moreover, embracing KGs makes it easier to integrate with other spatial data sources, e.g., OpenStreetMap and existing (Geo)KGs (e.g., Wikidata, DBPedia, and GeoNames), and to perform queries combining information from multiple data sources. In this work, we describe a CityGML KG framework to populate the concepts in the CityGML ontology using declarative mappings to 3DCityDB, thus exposing the CityGML data therein as a KG. To demonstrate the feasibility of our approach, we use CityGML data from the city of Munich as test data and integrate OpenStreeMap data in the same area.
TransCC: Transformer Network for Coronary Artery CCTA Segmentation
Oct 07, 2023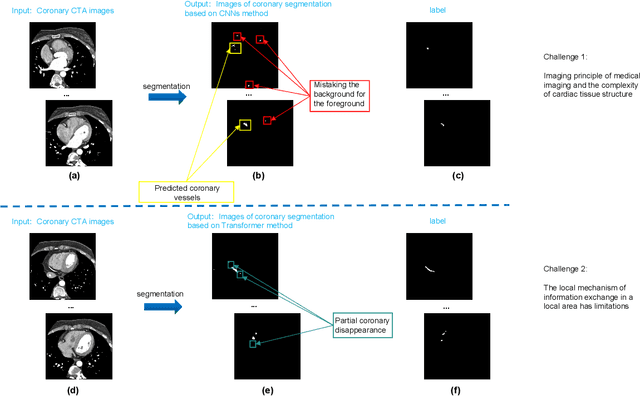
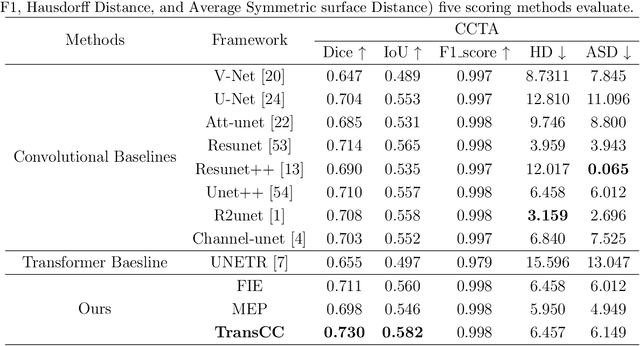
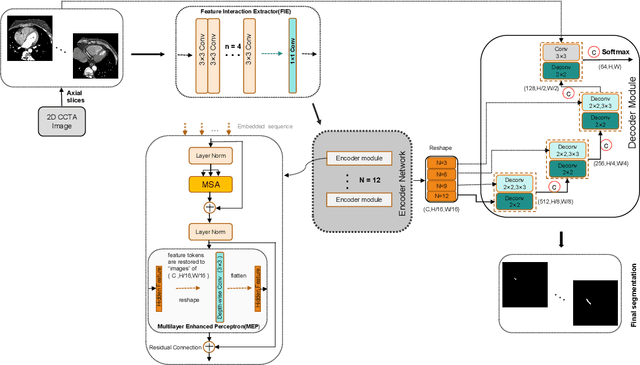
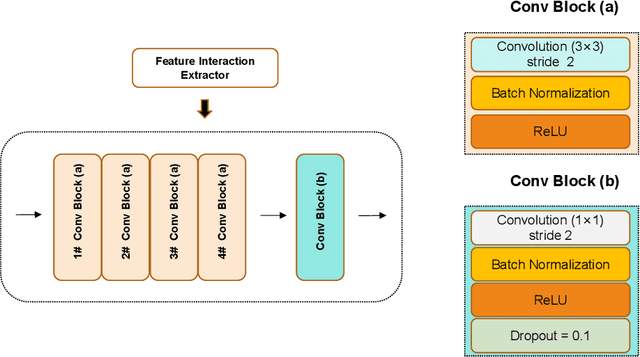
The accurate segmentation of Coronary Computed Tomography Angiography (CCTA) images holds substantial clinical value for the early detection and treatment of Coronary Heart Disease (CHD). The Transformer, utilizing a self-attention mechanism, has demonstrated commendable performance in the realm of medical image processing. However, challenges persist in coronary segmentation tasks due to (1) the damage to target local structures caused by fixed-size image patch embedding, and (2) the critical role of both global and local features in medical image segmentation tasks.To address these challenges, we propose a deep learning framework, TransCC, that effectively amalgamates the Transformer and convolutional neural networks for CCTA segmentation. Firstly, we introduce a Feature Interaction Extraction (FIE) module designed to capture the characteristics of image patches, thereby circumventing the loss of semantic information inherent in the original method. Secondly, we devise a Multilayer Enhanced Perceptron (MEP) to augment attention to local information within spatial dimensions, serving as a complement to the self-attention mechanism. Experimental results indicate that TransCC outperforms existing methods in segmentation performance, boasting an average Dice coefficient of 0.730 and an average Intersection over Union (IoU) of 0.582. These results underscore the effectiveness of TransCC in CCTA image segmentation.
Zero-Shot Object Goal Visual Navigation With Class-Independent Relationship Network
Oct 15, 2023This paper investigates the zero-shot object goal visual navigation problem. In the object goal visual navigation task, the agent needs to locate navigation targets from its egocentric visual input. "Zero-shot" means that the target the agent needs to find is not trained during the training phase. To address the issue of coupling navigation ability with target features during training, we propose the Class-Independent Relationship Network (CIRN). This method combines target detection information with the relative semantic similarity between the target and the navigation target, and constructs a brand new state representation based on similarity ranking, this state representation does not include target feature or environment feature, effectively decoupling the agent's navigation ability from target features. And a Graph Convolutional Network (GCN) is employed to learn the relationships between different objects based on their similarities. During testing, our approach demonstrates strong generalization capabilities, including zero-shot navigation tasks with different targets and environments. Through extensive experiments in the AI2-THOR virtual environment, our method outperforms the current state-of-the-art approaches in the zero-shot object goal visual navigation task. Furthermore, we conducted experiments in more challenging cross-target and cross-scene settings, which further validate the robustness and generalization ability of our method. Our code is available at: https://github.com/SmartAndCleverRobot/ICRA-CIRN.
Reconstructing 3D Human Pose from RGB-D Data with Occlusions
Oct 15, 2023We propose a new method to reconstruct the 3D human body from RGB-D images with occlusions. The foremost challenge is the incompleteness of the RGB-D data due to occlusions between the body and the environment, leading to implausible reconstructions that suffer from severe human-scene penetration. To reconstruct a semantically and physically plausible human body, we propose to reduce the solution space based on scene information and prior knowledge. Our key idea is to constrain the solution space of the human body by considering the occluded body parts and visible body parts separately: modeling all plausible poses where the occluded body parts do not penetrate the scene, and constraining the visible body parts using depth data. Specifically, the first component is realized by a neural network that estimates the candidate region named the "free zone", a region carved out of the open space within which it is safe to search for poses of the invisible body parts without concern for penetration. The second component constrains the visible body parts using the "truncated shadow volume" of the scanned body point cloud. Furthermore, we propose to use a volume matching strategy, which yields better performance than surface matching, to match the human body with the confined region. We conducted experiments on the PROX dataset, and the results demonstrate that our method produces more accurate and plausible results compared with other methods.
RSVP: Customer Intent Detection via Agent Response Contrastive and Generative Pre-Training
Oct 15, 2023The dialogue systems in customer services have been developed with neural models to provide users with precise answers and round-the-clock support in task-oriented conversations by detecting customer intents based on their utterances. Existing intent detection approaches have highly relied on adaptively pre-training language models with large-scale datasets, yet the predominant cost of data collection may hinder their superiority. In addition, they neglect the information within the conversational responses of the agents, which have a lower collection cost, but are significant to customer intent as agents must tailor their replies based on the customers' intent. In this paper, we propose RSVP, a self-supervised framework dedicated to task-oriented dialogues, which utilizes agent responses for pre-training in a two-stage manner. Specifically, we introduce two pre-training tasks to incorporate the relations of utterance-response pairs: 1) Response Retrieval by selecting a correct response from a batch of candidates, and 2) Response Generation by mimicking agents to generate the response to a given utterance. Our benchmark results for two real-world customer service datasets show that RSVP significantly outperforms the state-of-the-art baselines by 4.95% for accuracy, 3.4% for MRR@3, and 2.75% for MRR@5 on average. Extensive case studies are investigated to show the validity of incorporating agent responses into the pre-training stage.