 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Comparing Comparators in Generalization Bounds
Oct 16, 2023
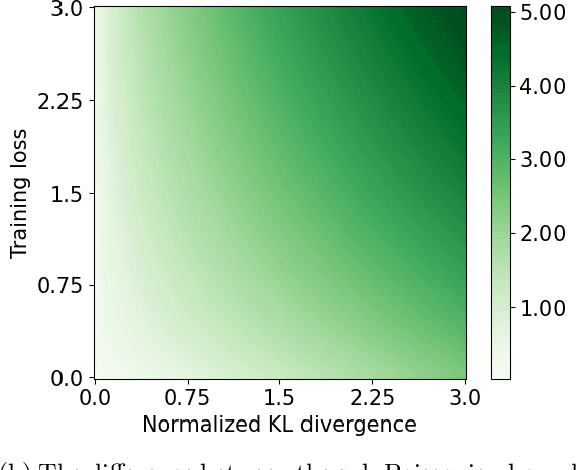

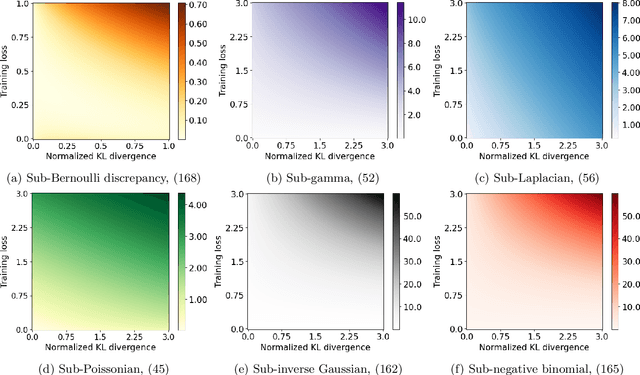
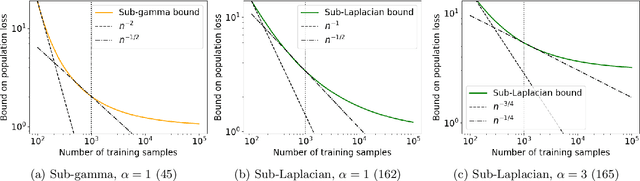
We derive generic information-theoretic and PAC-Bayesian generalization bounds involving an arbitrary convex comparator function, which measures the discrepancy between the training and population loss. The bounds hold under the assumption that the cumulant-generating function (CGF) of the comparator is upper-bounded by the corresponding CGF within a family of bounding distributions. We show that the tightest possible bound is obtained with the comparator being the convex conjugate of the CGF of the bounding distribution, also known as the Cram\'er function. This conclusion applies more broadly to generalization bounds with a similar structure. This confirms the near-optimality of known bounds for bounded and sub-Gaussian losses and leads to novel bounds under other bounding distributions.
Bayesian Filtering for Homography Estimation
Oct 16, 2023This paper considers homography estimation in a Bayesian filtering framework using rate gyro and camera measurements. The use of rate gyro measurements facilitates a more reliable estimate of homography in the presence of occlusions, while a Bayesian filtering approach generates both a homography estimate along with an uncertainty. Uncertainty information opens the door to adaptive filtering approaches, post-processing procedures, and safety protocols. In particular, herein an iterative extended Kalman filter and an interacting multiple model (IMM) filter are tested using both simulated and experimental datasets. The IMM is shown to have good consistency properties and better overall performance when compared to the state-of-the-art homography nonlinear deterministic observer in both simulations and experiments.
Partially Observable Multi-agent RL with (Quasi-)Efficiency: The Blessing of Information Sharing
Aug 16, 2023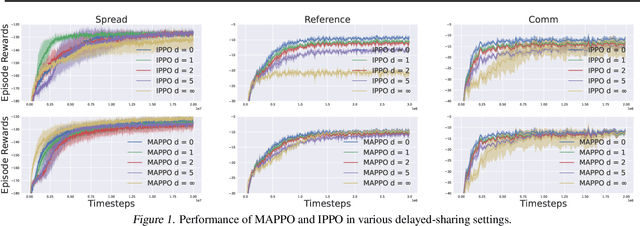
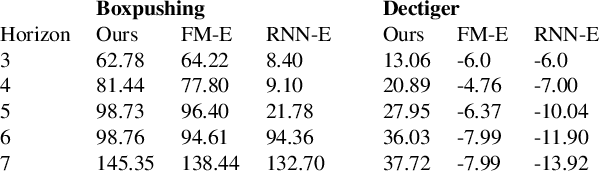
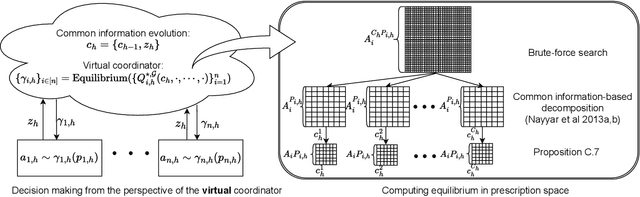
We study provable multi-agent reinforcement learning (MARL) in the general framework of partially observable stochastic games (POSGs). To circumvent the known hardness results and the use of computationally intractable oracles, we advocate leveraging the potential \emph{information-sharing} among agents, a common practice in empirical MARL, and a standard model for multi-agent control systems with communications. We first establish several computation complexity results to justify the necessity of information-sharing, as well as the observability assumption that has enabled quasi-efficient single-agent RL with partial observations, for computational efficiency in solving POSGs. We then propose to further \emph{approximate} the shared common information to construct an {approximate model} of the POSG, in which planning an approximate equilibrium (in terms of solving the original POSG) can be quasi-efficient, i.e., of quasi-polynomial-time, under the aforementioned assumptions. Furthermore, we develop a partially observable MARL algorithm that is both statistically and computationally quasi-efficient. We hope our study may open up the possibilities of leveraging and even designing different \emph{information structures}, for developing both sample- and computation-efficient partially observable MARL.
Interpretable Spectral Variational AutoEncoder (ISVAE) for time series clustering
Oct 18, 2023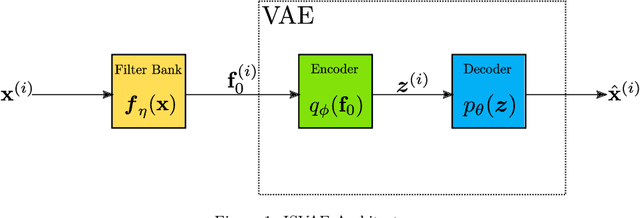

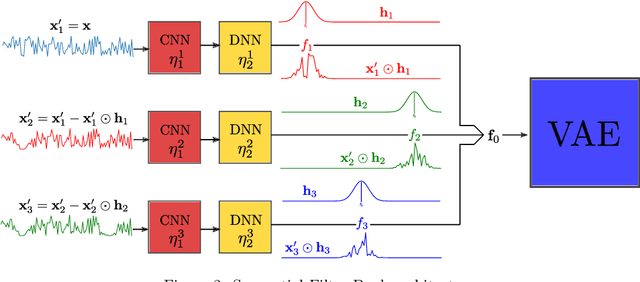
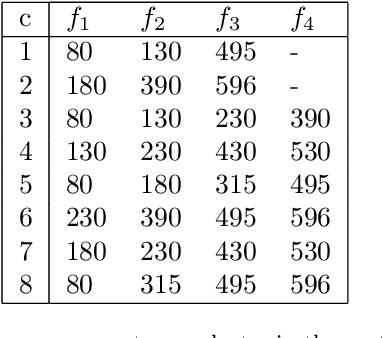
The best encoding is the one that is interpretable in nature. In this work, we introduce a novel model that incorporates an interpretable bottleneck-termed the Filter Bank (FB)-at the outset of a Variational Autoencoder (VAE). This arrangement compels the VAE to attend on the most informative segments of the input signal, fostering the learning of a novel encoding ${f_0}$ which boasts enhanced interpretability and clusterability over traditional latent spaces. By deliberately constraining the VAE with this FB, we intentionally constrict its capacity to access broad input domain information, promoting the development of an encoding that is discernible, separable, and of reduced dimensionality. The evolutionary learning trajectory of ${f_0}$ further manifests as a dynamic hierarchical tree, offering profound insights into cluster similarities. Additionally, for handling intricate data configurations, we propose a tailored decoder structure that is symmetrically aligned with FB's architecture. Empirical evaluations highlight the superior efficacy of ISVAE, which compares favorably to state-of-the-art results in clustering metrics across real-world datasets.
Geometry-Guided Ray Augmentation for Neural Surface Reconstruction with Sparse Views
Oct 18, 2023
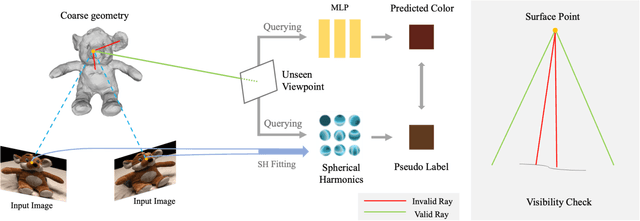
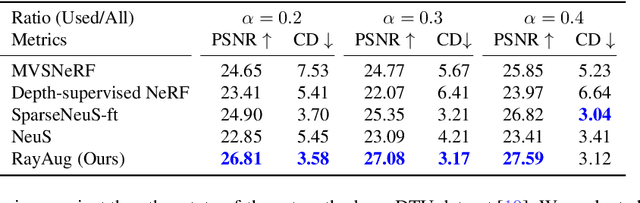

In this paper, we propose a novel method for 3D scene and object reconstruction from sparse multi-view images. Different from previous methods that leverage extra information such as depth or generalizable features across scenes, our approach leverages the scene properties embedded in the multi-view inputs to create precise pseudo-labels for optimization without any prior training. Specifically, we introduce a geometry-guided approach that improves surface reconstruction accuracy from sparse views by leveraging spherical harmonics to predict the novel radiance while holistically considering all color observations for a point in the scene. Also, our pipeline exploits proxy geometry and correctly handles the occlusion in generating the pseudo-labels of radiance, which previous image-warping methods fail to avoid. Our method, dubbed Ray Augmentation (RayAug), achieves superior results on DTU and Blender datasets without requiring prior training, demonstrating its effectiveness in addressing the problem of sparse view reconstruction. Our pipeline is flexible and can be integrated into other implicit neural reconstruction methods for sparse views.
CIR at the NTCIR-17 ULTRE-2 Task
Oct 18, 2023
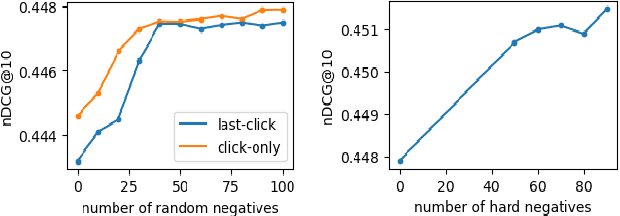
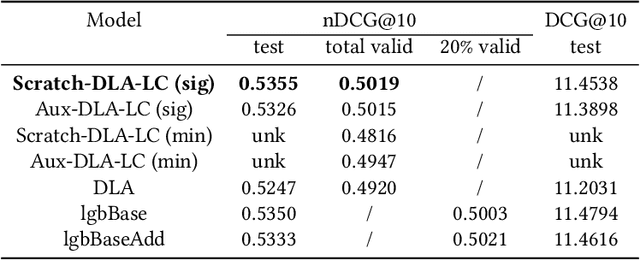
The Chinese academy of sciences Information Retrieval team (CIR) has participated in the NTCIR-17 ULTRE-2 task. This paper describes our approaches and reports our results on the ULTRE-2 task. We recognize the issue of false negatives in the Baidu search data in this competition is very severe, much more severe than position bias. Hence, we adopt the Dual Learning Algorithm (DLA) to address the position bias and use it as an auxiliary model to study how to alleviate the false negative issue. We approach the problem from two perspectives: 1) correcting the labels for non-clicked items by a relevance judgment model trained from DLA, and learn a new ranker that is initialized from DLA; 2) including random documents as true negatives and documents that have partial matching as hard negatives. Both methods can enhance the model performance and our best method has achieved nDCG@10 of 0.5355, which is 2.66% better than the best score from the organizer.
Retrieve-Cluster-Summarize: An Alternative to End-to-End Training for Query-specific Article Generation
Oct 18, 2023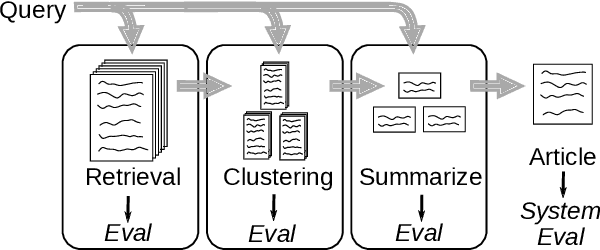

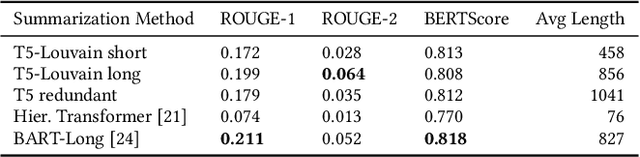
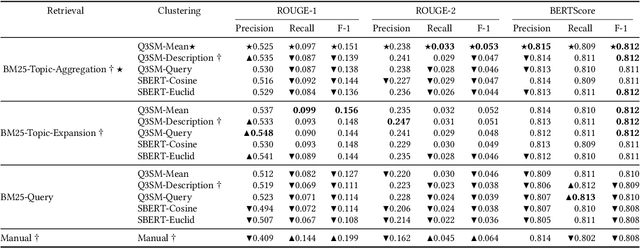
Query-specific article generation is the task of, given a search query, generate a single article that gives an overview of the topic. We envision such articles as an alternative to presenting a ranking of search results. While generative Large Language Models (LLMs) like chatGPT also address this task, they are known to hallucinate new information, their models are secret, hard to analyze and control. Some generative LLMs provide supporting references, yet these are often unrelated to the generated content. As an alternative, we propose to study article generation systems that integrate document retrieval, query-specific clustering, and summarization. By design, such models can provide actual citations as provenance for their generated text. In particular, we contribute an evaluation framework that allows to separately trains and evaluate each of these three components before combining them into one system. We experimentally demonstrate that a system comprised of the best-performing individual components also obtains the best F-1 overall system quality.
DPF-Nutrition: Food Nutrition Estimation via Depth Prediction and Fusion
Oct 18, 2023A reasonable and balanced diet is essential for maintaining good health. With the advancements in deep learning, automated nutrition estimation method based on food images offers a promising solution for monitoring daily nutritional intake and promoting dietary health. While monocular image-based nutrition estimation is convenient, efficient, and economical, the challenge of limited accuracy remains a significant concern. To tackle this issue, we proposed DPF-Nutrition, an end-to-end nutrition estimation method using monocular images. In DPF-Nutrition, we introduced a depth prediction module to generate depth maps, thereby improving the accuracy of food portion estimation. Additionally, we designed an RGB-D fusion module that combined monocular images with the predicted depth information, resulting in better performance for nutrition estimation. To the best of our knowledge, this was the pioneering effort that integrated depth prediction and RGB-D fusion techniques in food nutrition estimation. Comprehensive experiments performed on Nutrition5k evaluated the effectiveness and efficiency of DPF-Nutrition.
Core Building Blocks: Next Gen Geo Spatial GPT Application
Oct 18, 2023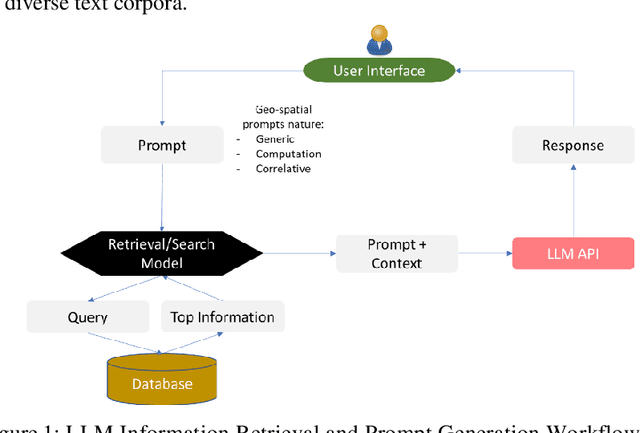
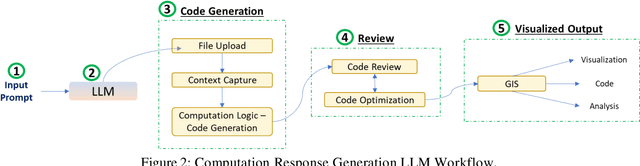
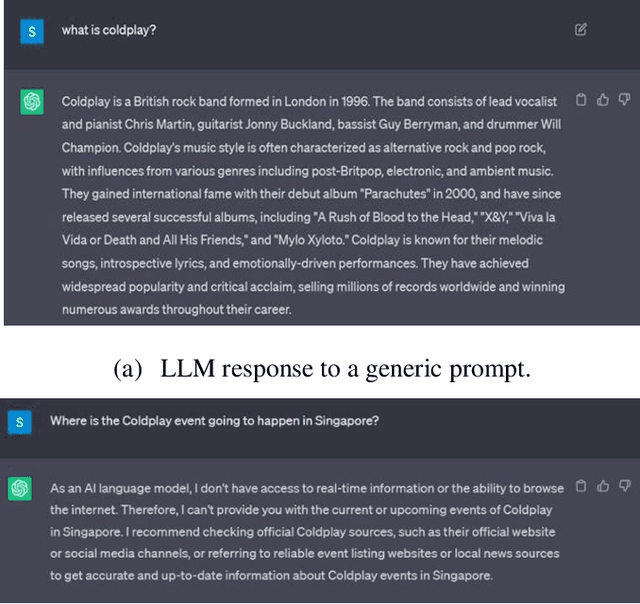
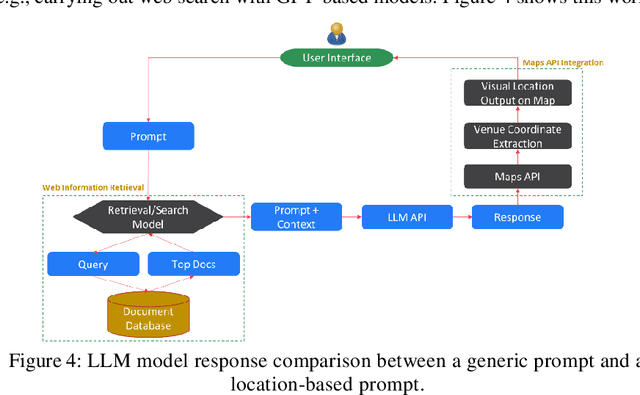
This paper proposes MapGPT which is a novel approach that integrates the capabilities of language models, specifically large language models (LLMs), with spatial data processing techniques. This paper introduces MapGPT, which aims to bridge the gap between natural language understanding and spatial data analysis by highlighting the relevant core building blocks. By combining the strengths of LLMs and geospatial analysis, MapGPT enables more accurate and contextually aware responses to location-based queries. The proposed methodology highlights building LLMs on spatial and textual data, utilizing tokenization and vector representations specific to spatial information. The paper also explores the challenges associated with generating spatial vector representations. Furthermore, the study discusses the potential of computational capabilities within MapGPT, allowing users to perform geospatial computations and obtain visualized outputs. Overall, this research paper presents the building blocks and methodology of MapGPT, highlighting its potential to enhance spatial data understanding and generation in natural language processing applications.
Learning Co-Speech Gesture for Multimodal Aphasia Type Detection
Oct 18, 2023Aphasia, a language disorder resulting from brain damage, requires accurate identification of specific aphasia types, such as Broca's and Wernicke's aphasia, for effective treatment. However, little attention has been paid to developing methods to detect different types of aphasia. Recognizing the importance of analyzing co-speech gestures for distinguish aphasia types, we propose a multimodal graph neural network for aphasia type detection using speech and corresponding gesture patterns. By learning the correlation between the speech and gesture modalities for each aphasia type, our model can generate textual representations sensitive to gesture information, leading to accurate aphasia type detection. Extensive experiments demonstrate the superiority of our approach over existing methods, achieving state-of-the-art results (F1 84.2\%). We also show that gesture features outperform acoustic features, highlighting the significance of gesture expression in detecting aphasia types. We provide the codes for reproducibility purposes\footnote{Code: \url{https://github.com/DSAIL-SKKU/Multimodal-Aphasia-Type-Detection_EMNLP_2023}}.