 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DepWiGNN: A Depth-wise Graph Neural Network for Multi-hop Spatial Reasoning in Text
Oct 19, 2023
Spatial reasoning in text plays a crucial role in various real-world applications. Existing approaches for spatial reasoning typically infer spatial relations from pure text, which overlook the gap between natural language and symbolic structures. Graph neural networks (GNNs) have showcased exceptional proficiency in inducing and aggregating symbolic structures. However, classical GNNs face challenges in handling multi-hop spatial reasoning due to the over-smoothing issue, \textit{i.e.}, the performance decreases substantially as the number of graph layers increases. To cope with these challenges, we propose a novel \textbf{Dep}th-\textbf{Wi}se \textbf{G}raph \textbf{N}eural \textbf{N}etwork (\textbf{DepWiGNN}). Specifically, we design a novel node memory scheme and aggregate the information over the depth dimension instead of the breadth dimension of the graph, which empowers the ability to collect long dependencies without stacking multiple layers. Experimental results on two challenging multi-hop spatial reasoning datasets show that DepWiGNN outperforms existing spatial reasoning methods. The comparisons with the other three GNNs further demonstrate its superiority in capturing long dependency in the graph.
Burning the Adversarial Bridges: Robust Windows Malware Detection Against Binary-level Mutations
Oct 05, 2023Toward robust malware detection, we explore the attack surface of existing malware detection systems. We conduct root-cause analyses of the practical binary-level black-box adversarial malware examples. Additionally, we uncover the sensitivity of volatile features within the detection engines and exhibit their exploitability. Highlighting volatile information channels within the software, we introduce three software pre-processing steps to eliminate the attack surface, namely, padding removal, software stripping, and inter-section information resetting. Further, to counter the emerging section injection attacks, we propose a graph-based section-dependent information extraction scheme for software representation. The proposed scheme leverages aggregated information within various sections in the software to enable robust malware detection and mitigate adversarial settings. Our experimental results show that traditional malware detection models are ineffective against adversarial threats. However, the attack surface can be largely reduced by eliminating the volatile information. Therefore, we propose simple-yet-effective methods to mitigate the impacts of binary manipulation attacks. Overall, our graph-based malware detection scheme can accurately detect malware with an area under the curve score of 88.32\% and a score of 88.19% under a combination of binary manipulation attacks, exhibiting the efficiency of our proposed scheme.
BioT5: Enriching Cross-modal Integration in Biology with Chemical Knowledge and Natural Language Associations
Oct 11, 2023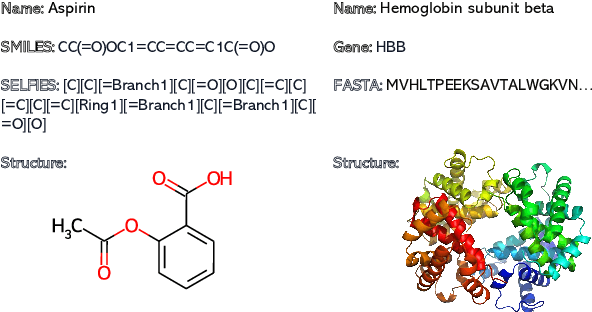
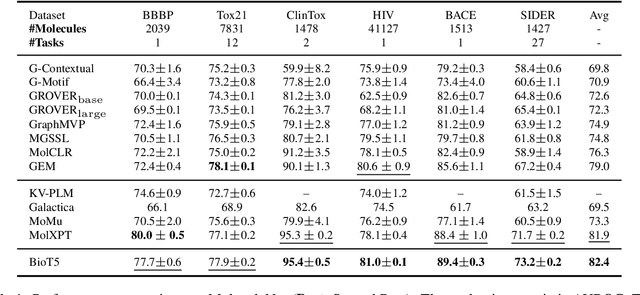
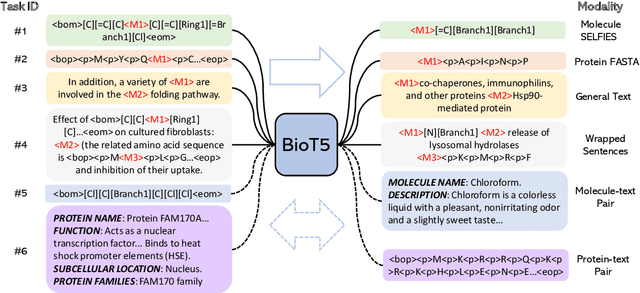
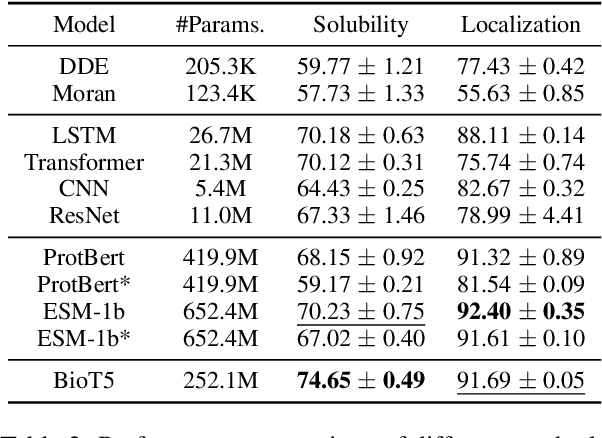
Recent advancements in biological research leverage the integration of molecules, proteins, and natural language to enhance drug discovery. However, current models exhibit several limitations, such as the generation of invalid molecular SMILES, underutilization of contextual information, and equal treatment of structured and unstructured knowledge. To address these issues, we propose $\mathbf{BioT5}$, a comprehensive pre-training framework that enriches cross-modal integration in biology with chemical knowledge and natural language associations. $\mathbf{BioT5}$ utilizes SELFIES for $100%$ robust molecular representations and extracts knowledge from the surrounding context of bio-entities in unstructured biological literature. Furthermore, $\mathbf{BioT5}$ distinguishes between structured and unstructured knowledge, leading to more effective utilization of information. After fine-tuning, BioT5 shows superior performance across a wide range of tasks, demonstrating its strong capability of capturing underlying relations and properties of bio-entities. Our code is available at $\href{https://github.com/QizhiPei/BioT5}{Github}$.
3D Force and Contact Estimation for a Soft-Bubble Visuotactile Sensor Using FEM
Oct 17, 2023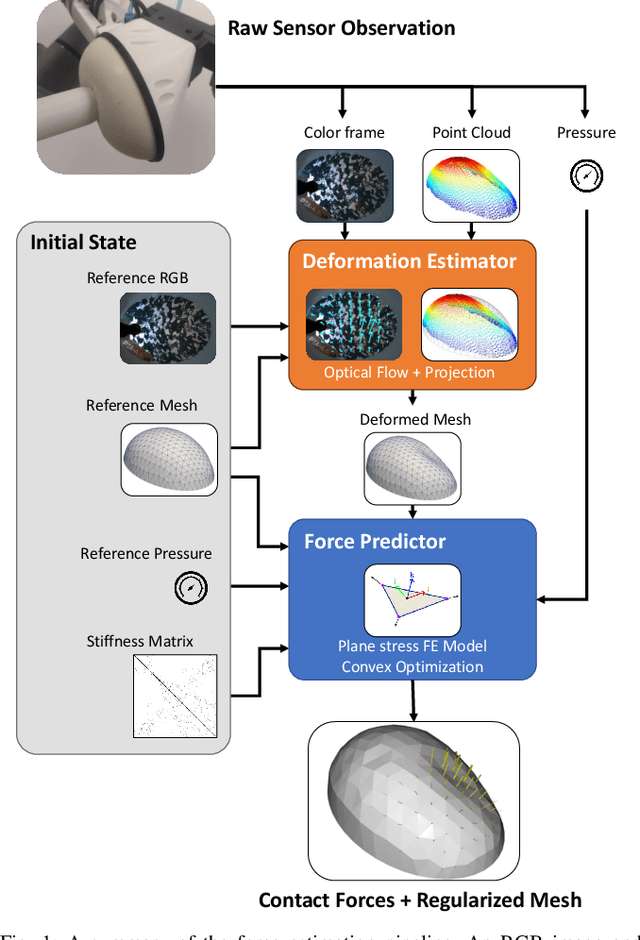
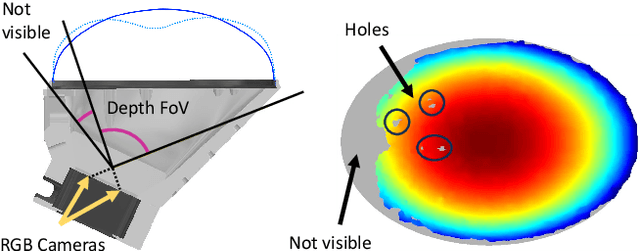
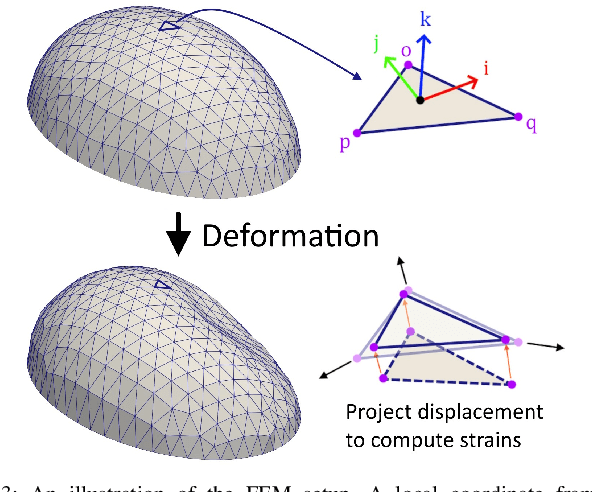
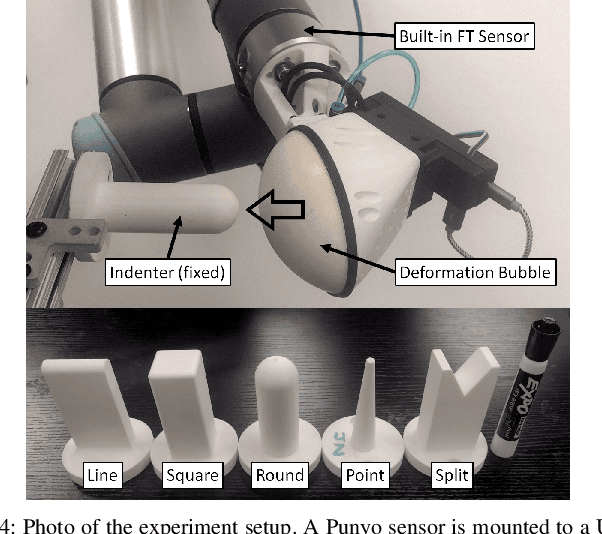
Soft-bubble tactile sensors have the potential to capture dense contact and force information across a large contact surface. However, it is difficult to extract contact forces directly from observing the bubble surface because local contacts change the global surface shape significantly due to membrane mechanics and air pressure. This paper presents a model-based method of reconstructing dense contact forces from the bubble sensor's internal RGBD camera and air pressure sensor. We present a finite element model of the force response of the bubble sensor that uses a linear plane stress approximation that only requires calibrating 3 variables. Our method is shown to reconstruct normal and shear forces significantly more accurately than the state-of-the-art, with comparable accuracy for detecting the contact patch, and with very little calibration data.
Progressive Evidence Refinement for Open-domain Multimodal Retrieval Question Answering
Oct 15, 2023Pre-trained multimodal models have achieved significant success in retrieval-based question answering. However, current multimodal retrieval question-answering models face two main challenges. Firstly, utilizing compressed evidence features as input to the model results in the loss of fine-grained information within the evidence. Secondly, a gap exists between the feature extraction of evidence and the question, which hinders the model from effectively extracting critical features from the evidence based on the given question. We propose a two-stage framework for evidence retrieval and question-answering to alleviate these issues. First and foremost, we propose a progressive evidence refinement strategy for selecting crucial evidence. This strategy employs an iterative evidence retrieval approach to uncover the logical sequence among the evidence pieces. It incorporates two rounds of filtering to optimize the solution space, thus further ensuring temporal efficiency. Subsequently, we introduce a semi-supervised contrastive learning training strategy based on negative samples to expand the scope of the question domain, allowing for a more thorough exploration of latent knowledge within known samples. Finally, in order to mitigate the loss of fine-grained information, we devise a multi-turn retrieval and question-answering strategy to handle multimodal inputs. This strategy involves incorporating multimodal evidence directly into the model as part of the historical dialogue and question. Meanwhile, we leverage a cross-modal attention mechanism to capture the underlying connections between the evidence and the question, and the answer is generated through a decoding generation approach. We validate the model's effectiveness through extensive experiments, achieving outstanding performance on WebQA and MultimodelQA benchmark tests.
A Partially Supervised Reinforcement Learning Framework for Visual Active Search
Oct 15, 2023Visual active search (VAS) has been proposed as a modeling framework in which visual cues are used to guide exploration, with the goal of identifying regions of interest in a large geospatial area. Its potential applications include identifying hot spots of rare wildlife poaching activity, search-and-rescue scenarios, identifying illegal trafficking of weapons, drugs, or people, and many others. State of the art approaches to VAS include applications of deep reinforcement learning (DRL), which yield end-to-end search policies, and traditional active search, which combines predictions with custom algorithmic approaches. While the DRL framework has been shown to greatly outperform traditional active search in such domains, its end-to-end nature does not make full use of supervised information attained either during training, or during actual search, a significant limitation if search tasks differ significantly from those in the training distribution. We propose an approach that combines the strength of both DRL and conventional active search by decomposing the search policy into a prediction module, which produces a geospatial distribution of regions of interest based on task embedding and search history, and a search module, which takes the predictions and search history as input and outputs the search distribution. We develop a novel meta-learning approach for jointly learning the resulting combined policy that can make effective use of supervised information obtained both at training and decision time. Our extensive experiments demonstrate that the proposed representation and meta-learning frameworks significantly outperform state of the art in visual active search on several problem domains.
Loose lips sink ships: Mitigating Length Bias in Reinforcement Learning from Human Feedback
Oct 12, 2023
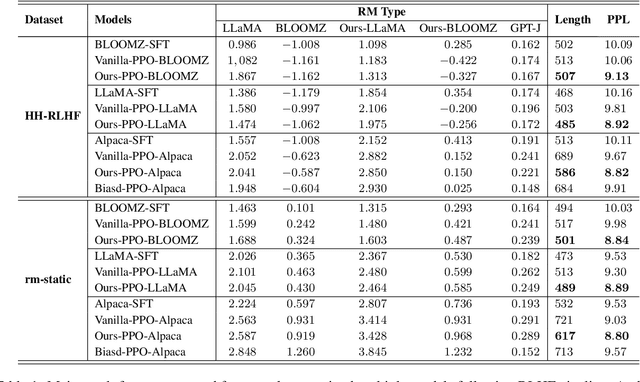
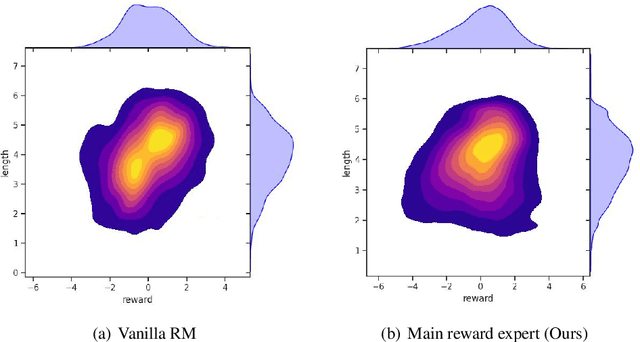

Reinforcement learning from human feedback serves as a crucial bridge, aligning large language models with human and societal values. This alignment requires a vast corpus of human feedback to learn a reward model, which is subsequently used to finetune language models. However, we have identified that the reward model often finds shortcuts to bypass its intended objectives, misleadingly assuming that humans prefer longer responses. The emergence of length bias often induces the model to favor longer outputs, yet it doesn't equate to an increase in helpful information within these outputs. In this paper, we propose an innovative solution, applying the Product-of-Experts (PoE) technique to separate reward modeling from the influence of sequence length. In our framework, the main expert concentrates on understanding human intents, while the biased expert targets the identification and capture of length bias. To further enhance the learning of bias, we introduce perturbations into the bias-focused expert, disrupting the flow of semantic information. Experimental results validate the effectiveness of our approach, indicating that language model performance is improved, irrespective of sequence length.
A Benchmarking Protocol for SAR Colorization: From Regression to Deep Learning Approaches
Oct 12, 2023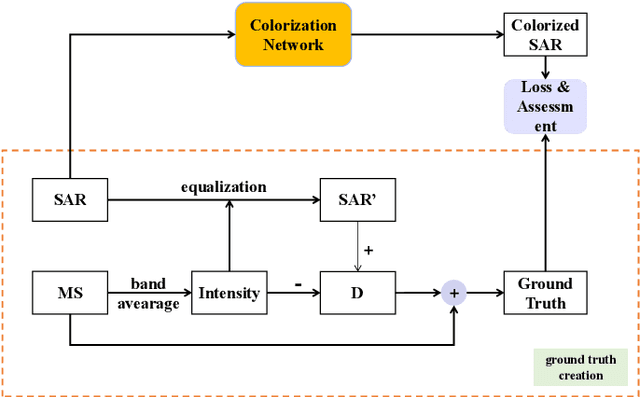


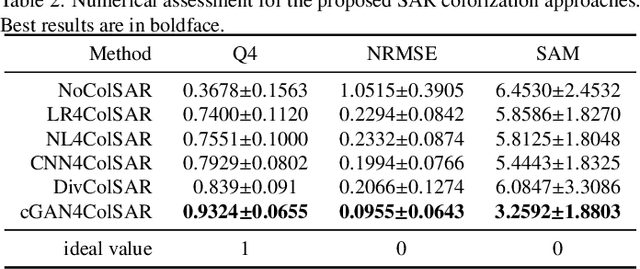
Synthetic aperture radar (SAR) images are widely used in remote sensing. Interpreting SAR images can be challenging due to their intrinsic speckle noise and grayscale nature. To address this issue, SAR colorization has emerged as a research direction to colorize gray scale SAR images while preserving the original spatial information and radiometric information. However, this research field is still in its early stages, and many limitations can be highlighted. In this paper, we propose a full research line for supervised learning-based approaches to SAR colorization. Our approach includes a protocol for generating synthetic color SAR images, several baselines, and an effective method based on the conditional generative adversarial network (cGAN) for SAR colorization. We also propose numerical assessment metrics for the problem at hand. To our knowledge, this is the first attempt to propose a research line for SAR colorization that includes a protocol, a benchmark, and a complete performance evaluation. Our extensive tests demonstrate the effectiveness of our proposed cGAN-based network for SAR colorization. The code will be made publicly available.
GDL-DS: A Benchmark for Geometric Deep Learning under Distribution Shifts
Oct 12, 2023Geometric deep learning (GDL) has gained significant attention in various scientific fields, chiefly for its proficiency in modeling data with intricate geometric structures. Yet, very few works have delved into its capability of tackling the distribution shift problem, a prevalent challenge in many relevant applications. To bridge this gap, we propose GDL-DS, a comprehensive benchmark designed for evaluating the performance of GDL models in scenarios with distribution shifts. Our evaluation datasets cover diverse scientific domains from particle physics and materials science to biochemistry, and encapsulate a broad spectrum of distribution shifts including conditional, covariate, and concept shifts. Furthermore, we study three levels of information access from the out-of-distribution (OOD) testing data, including no OOD information, only OOD features without labels, and OOD features with a few labels. Overall, our benchmark results in 30 different experiment settings, and evaluates 3 GDL backbones and 11 learning algorithms in each setting. A thorough analysis of the evaluation results is provided, poised to illuminate insights for DGL researchers and domain practitioners who are to use DGL in their applications.
Robust Unsupervised Domain Adaptation by Retaining Confident Entropy via Edge Concatenation
Oct 11, 2023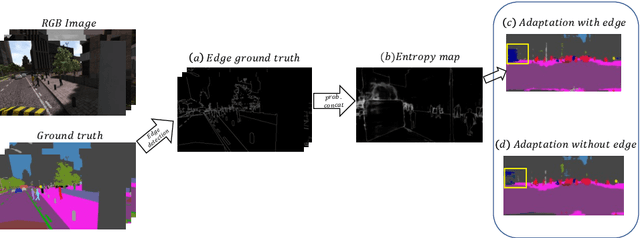
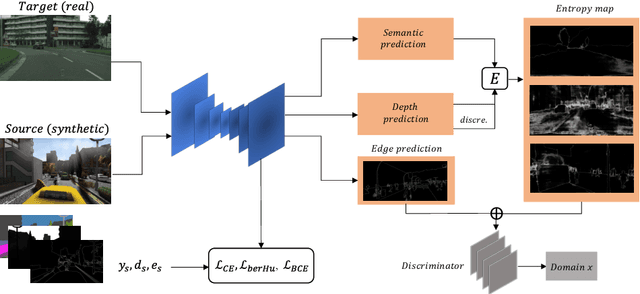
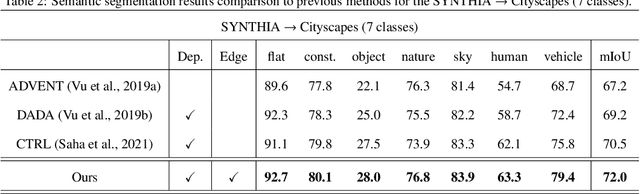

The generalization capability of unsupervised domain adaptation can mitigate the need for extensive pixel-level annotations to train semantic segmentation networks by training models on synthetic data as a source with computer-generated annotations. Entropy-based adversarial networks are proposed to improve source domain prediction; however, they disregard significant external information, such as edges, which have the potential to identify and distinguish various objects within an image accurately. To address this issue, we introduce a novel approach to domain adaptation, leveraging the synergy of internal and external information within entropy-based adversarial networks. In this approach, we enrich the discriminator network with edge-predicted probability values within this innovative framework to enhance the clarity of class boundaries. Furthermore, we devised a probability-sharing network that integrates diverse information for more effective segmentation. Incorporating object edges addresses a pivotal aspect of unsupervised domain adaptation that has frequently been neglected in the past -- the precise delineation of object boundaries. Conventional unsupervised domain adaptation methods usually center around aligning feature distributions and may not explicitly model object boundaries. Our approach effectively bridges this gap by offering clear guidance on object boundaries, thereby elevating the quality of domain adaptation. Our approach undergoes rigorous evaluation on the established unsupervised domain adaptation benchmarks, specifically in adapting SYNTHIA $\rightarrow$ Cityscapes and SYNTHIA $\rightarrow$ Mapillary. Experimental results show that the proposed model attains better performance than state-of-the-art methods. The superior performance across different unsupervised domain adaptation scenarios highlights the versatility and robustness of the proposed method.