 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Multimodal Approach to Device-Directed Speech Detection with Large Language Models
Mar 26, 2024
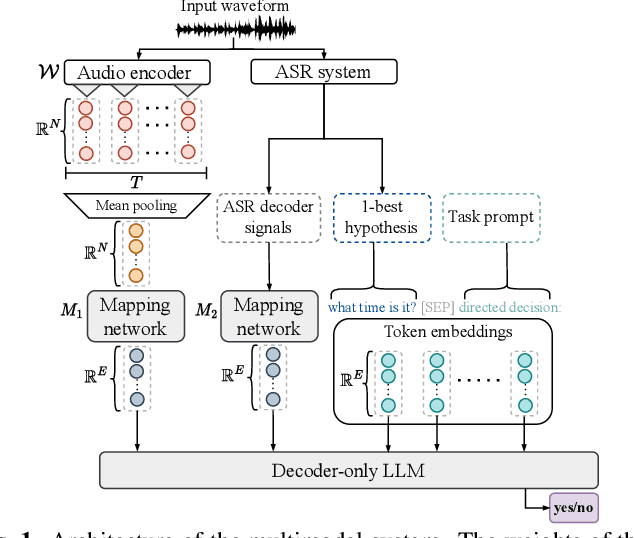
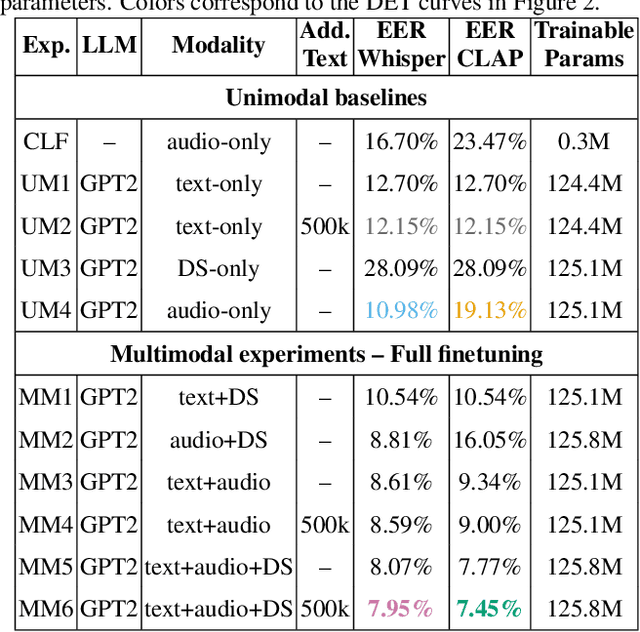
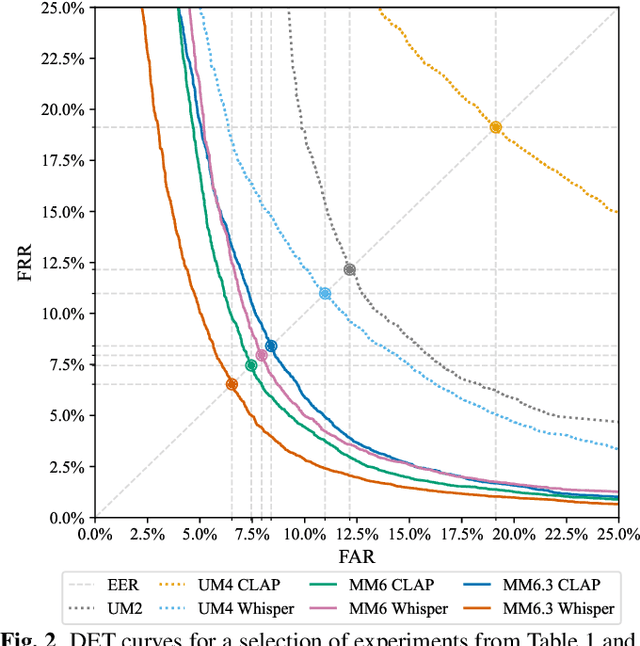

Interactions with virtual assistants typically start with a predefined trigger phrase followed by the user command. To make interactions with the assistant more intuitive, we explore whether it is feasible to drop the requirement that users must begin each command with a trigger phrase. We explore this task in three ways: First, we train classifiers using only acoustic information obtained from the audio waveform. Second, we take the decoder outputs of an automatic speech recognition (ASR) system, such as 1-best hypotheses, as input features to a large language model (LLM). Finally, we explore a multimodal system that combines acoustic and lexical features, as well as ASR decoder signals in an LLM. Using multimodal information yields relative equal-error-rate improvements over text-only and audio-only models of up to 39% and 61%. Increasing the size of the LLM and training with low-rank adaption leads to further relative EER reductions of up to 18% on our dataset.
Benchmarking the Robustness of Temporal Action Detection Models Against Temporal Corruptions
Mar 29, 2024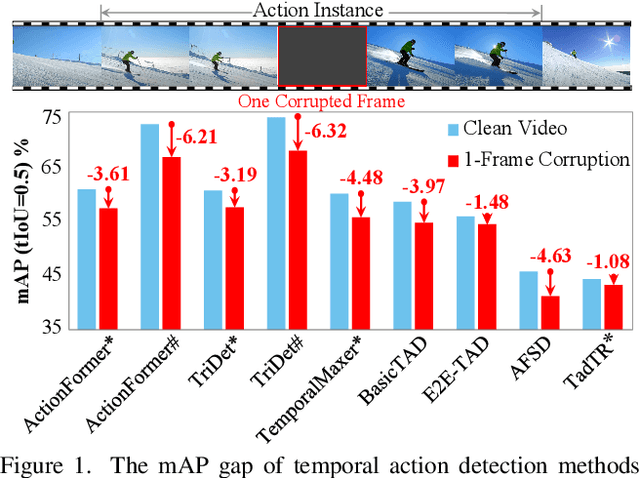
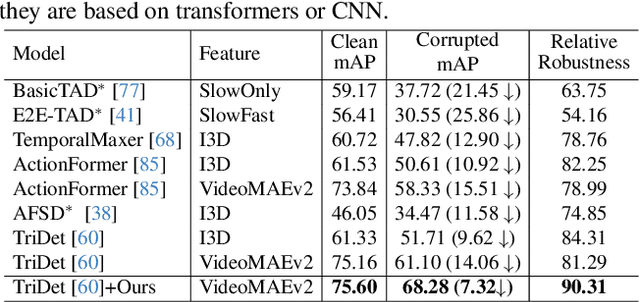
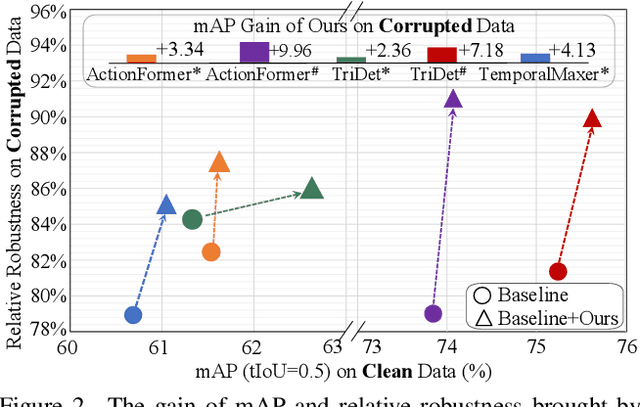
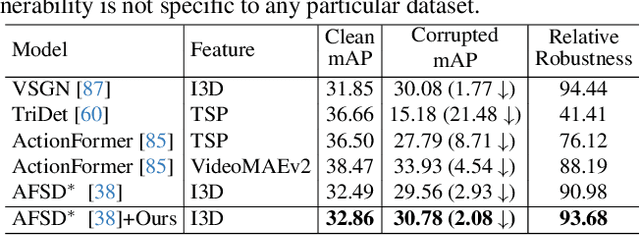
Temporal action detection (TAD) aims to locate action positions and recognize action categories in long-term untrimmed videos. Although many methods have achieved promising results, their robustness has not been thoroughly studied. In practice, we observe that temporal information in videos can be occasionally corrupted, such as missing or blurred frames. Interestingly, existing methods often incur a significant performance drop even if only one frame is affected. To formally evaluate the robustness, we establish two temporal corruption robustness benchmarks, namely THUMOS14-C and ActivityNet-v1.3-C. In this paper, we extensively analyze the robustness of seven leading TAD methods and obtain some interesting findings: 1) Existing methods are particularly vulnerable to temporal corruptions, and end-to-end methods are often more susceptible than those with a pre-trained feature extractor; 2) Vulnerability mainly comes from localization error rather than classification error; 3) When corruptions occur in the middle of an action instance, TAD models tend to yield the largest performance drop. Besides building a benchmark, we further develop a simple but effective robust training method to defend against temporal corruptions, through the FrameDrop augmentation and Temporal-Robust Consistency loss. Remarkably, our approach not only improves robustness but also yields promising improvements on clean data. We believe that this study will serve as a benchmark for future research in robust video analysis. Source code and models are available at https://github.com/Alvin-Zeng/temporal-robustness-benchmark.
Dia-LLaMA: Towards Large Language Model-driven CT Report Generation
Mar 25, 2024Medical report generation has achieved remarkable advancements yet has still been faced with several challenges. First, the inherent imbalance in the distribution of normal and abnormal cases may lead models to exhibit a biased focus on normal samples, resulting in unreliable diagnoses. Second, the frequent occurrence of common template sentences in the reports may overwhelm the critical abnormal information. Moreover, existing works focus on 2D chest X-rays, leaving CT report generation underexplored due to the high-dimensional nature of CT images and the limited availability of CT-report pairs. Recently, LLM has shown a great ability to generate reliable answers with appropriate prompts, which shed light on addressing the aforementioned challenges. In this paper, we propose Dia-LLaMA, a framework to adapt the LLaMA2-7B for CT report generation by incorporating diagnostic information as guidance prompts. Considering the high dimension of CT, we leverage a pre-trained ViT3D with perceiver to extract the visual information. To tailor the LLM for report generation and emphasize abnormality, we extract additional diagnostic information by referring to a disease prototype memory bank, which is updated during training to capture common disease representations. Furthermore, we introduce disease-aware attention to enable the model to adjust attention for different diseases. Experiments on the chest CT dataset demonstrated that our proposed method outperformed previous methods and achieved state-of-the-art on both clinical efficacy performance and natural language generation metrics. The code will be made publically available.
Fisher-Rao Gradient Flows of Linear Programs and State-Action Natural Policy Gradients
Mar 28, 2024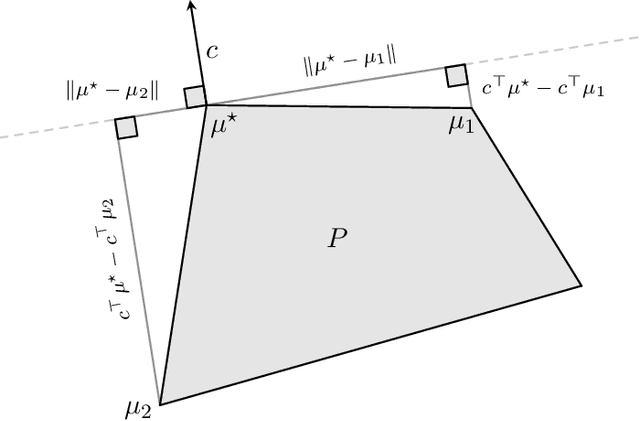

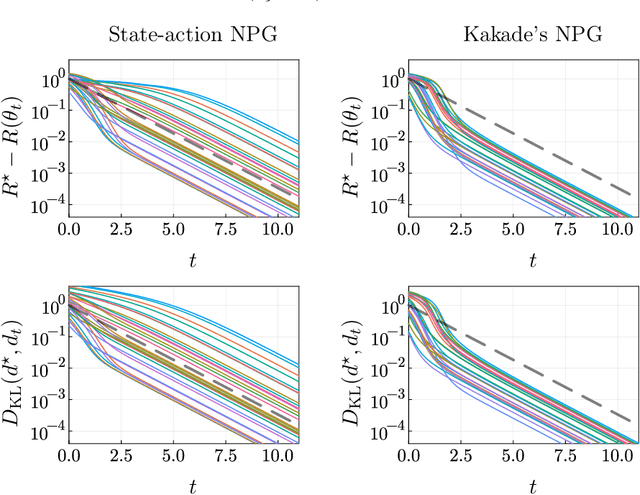
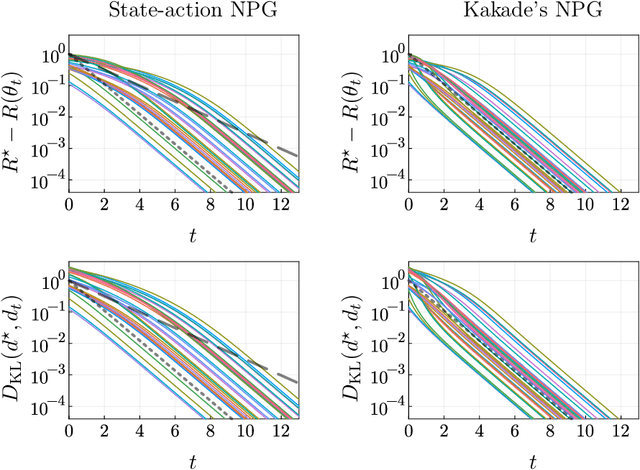
Kakade's natural policy gradient method has been studied extensively in the last years showing linear convergence with and without regularization. We study another natural gradient method which is based on the Fisher information matrix of the state-action distributions and has received little attention from the theoretical side. Here, the state-action distributions follow the Fisher-Rao gradient flow inside the state-action polytope with respect to a linear potential. Therefore, we study Fisher-Rao gradient flows of linear programs more generally and show linear convergence with a rate that depends on the geometry of the linear program. Equivalently, this yields an estimate on the error induced by entropic regularization of the linear program which improves existing results. We extend these results and show sublinear convergence for perturbed Fisher-Rao gradient flows and natural gradient flows up to an approximation error. In particular, these general results cover the case of state-action natural policy gradients.
Detecting Image Attribution for Text-to-Image Diffusion Models in RGB and Beyond
Mar 28, 2024Modern text-to-image (T2I) diffusion models can generate images with remarkable realism and creativity. These advancements have sparked research in fake image detection and attribution, yet prior studies have not fully explored the practical and scientific dimensions of this task. In addition to attributing images to 12 state-of-the-art T2I generators, we provide extensive analyses on what inference stage hyperparameters and image modifications are discernible. Our experiments reveal that initialization seeds are highly detectable, along with other subtle variations in the image generation process to some extent. We further investigate what visual traces are leveraged in image attribution by perturbing high-frequency details and employing mid-level representations of image style and structure. Notably, altering high-frequency information causes only slight reductions in accuracy, and training an attributor on style representations outperforms training on RGB images. Our analyses underscore that fake images are detectable and attributable at various levels of visual granularity than previously explored.
Semantic Map-based Generation of Navigation Instructions
Mar 28, 2024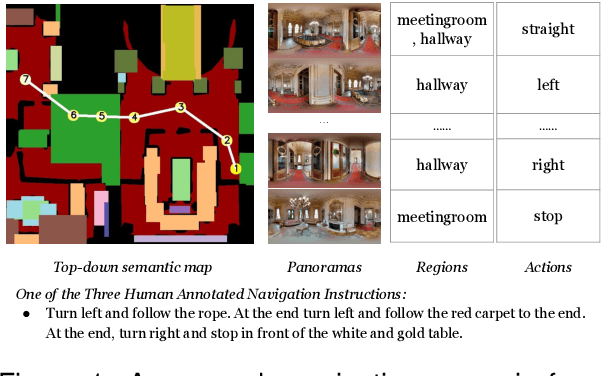
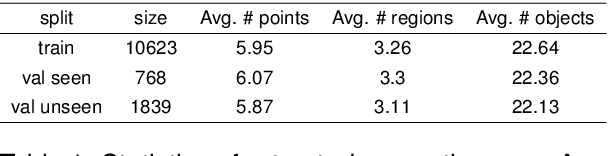
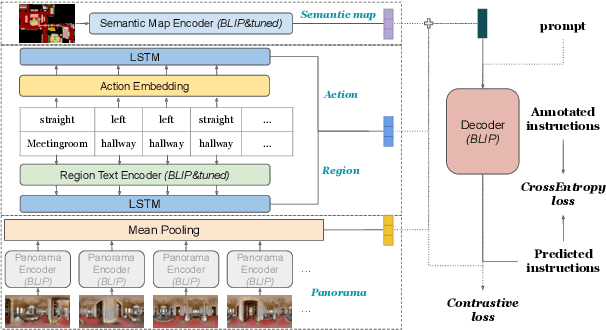
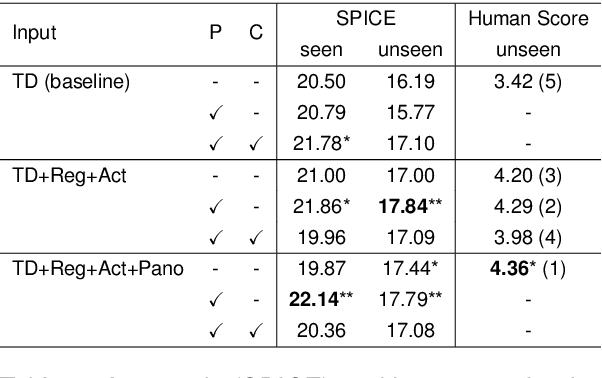
We are interested in the generation of navigation instructions, either in their own right or as training material for robotic navigation task. In this paper, we propose a new approach to navigation instruction generation by framing the problem as an image captioning task using semantic maps as visual input. Conventional approaches employ a sequence of panorama images to generate navigation instructions. Semantic maps abstract away from visual details and fuse the information in multiple panorama images into a single top-down representation, thereby reducing computational complexity to process the input. We present a benchmark dataset for instruction generation using semantic maps, propose an initial model and ask human subjects to manually assess the quality of generated instructions. Our initial investigations show promise in using semantic maps for instruction generation instead of a sequence of panorama images, but there is vast scope for improvement. We release the code for data preparation and model training at https://github.com/chengzu-li/VLGen.
Ungrammatical-syntax-based In-context Example Selection for Grammatical Error Correction
Mar 28, 2024In the era of large language models (LLMs), in-context learning (ICL) stands out as an effective prompting strategy that explores LLMs' potency across various tasks. However, applying LLMs to grammatical error correction (GEC) is still a challenging task. In this paper, we propose a novel ungrammatical-syntax-based in-context example selection strategy for GEC. Specifically, we measure similarity of sentences based on their syntactic structures with diverse algorithms, and identify optimal ICL examples sharing the most similar ill-formed syntax to the test input. Additionally, we carry out a two-stage process to further improve the quality of selection results. On benchmark English GEC datasets, empirical results show that our proposed ungrammatical-syntax-based strategies outperform commonly-used word-matching or semantics-based methods with multiple LLMs. This indicates that for a syntax-oriented task like GEC, paying more attention to syntactic information can effectively boost LLMs' performance. Our code will be publicly available after the publication of this paper.
Hierarchical Deep Learning for Intention Estimation of Teleoperation Manipulation in Assembly Tasks
Mar 28, 2024
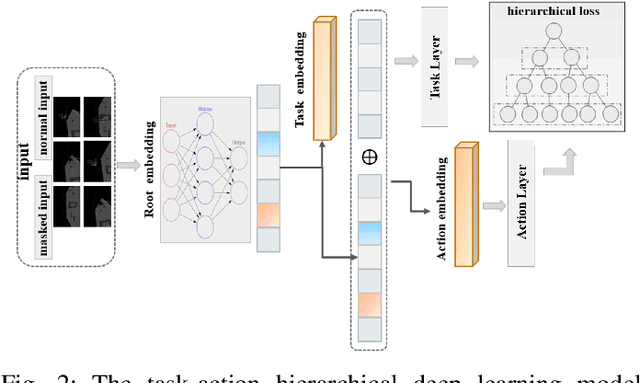
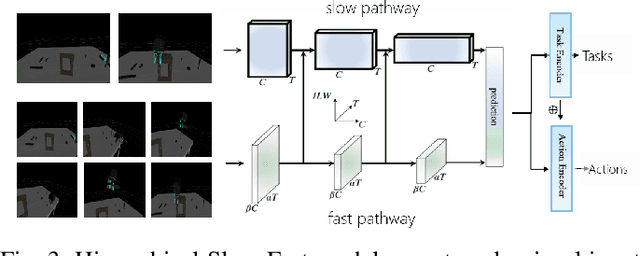

In human-robot collaboration, shared control presents an opportunity to teleoperate robotic manipulation to improve the efficiency of manufacturing and assembly processes. Robots are expected to assist in executing the user's intentions. To this end, robust and prompt intention estimation is needed, relying on behavioral observations. The framework presents an intention estimation technique at hierarchical levels i.e., low-level actions and high-level tasks, by incorporating multi-scale hierarchical information in neural networks. Technically, we employ hierarchical dependency loss to boost overall accuracy. Furthermore, we propose a multi-window method that assigns proper hierarchical prediction windows of input data. An analysis of the predictive power with various inputs demonstrates the predominance of the deep hierarchical model in the sense of prediction accuracy and early intention identification. We implement the algorithm on a virtual reality (VR) setup to teleoperate robotic hands in a simulation with various assembly tasks to show the effectiveness of online estimation.
Towards Unified Multi-Modal Personalization: Large Vision-Language Models for Generative Recommendation and Beyond
Mar 27, 2024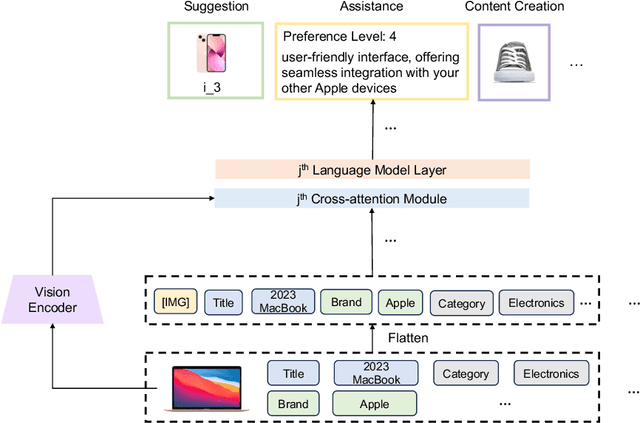
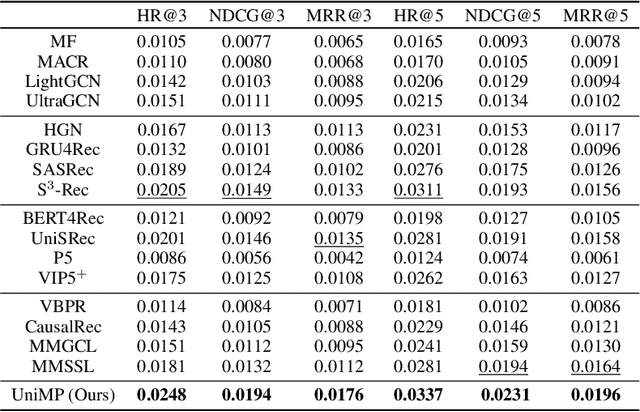
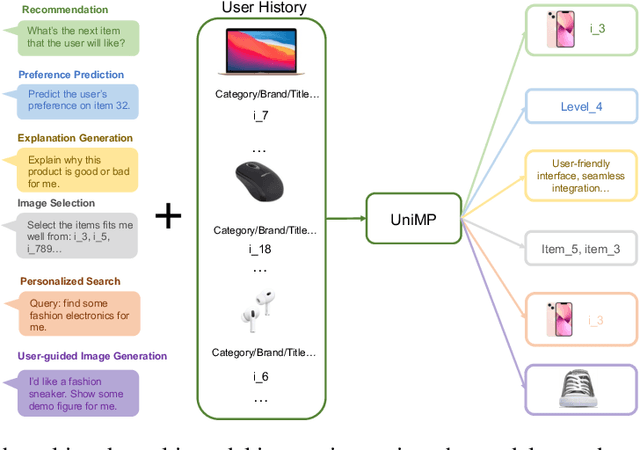
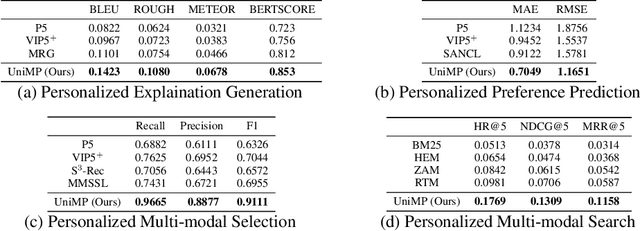
Developing a universal model that can effectively harness heterogeneous resources and respond to a wide range of personalized needs has been a longstanding community aspiration. Our daily choices, especially in domains like fashion and retail, are substantially shaped by multi-modal data, such as pictures and textual descriptions. These modalities not only offer intuitive guidance but also cater to personalized user preferences. However, the predominant personalization approaches mainly focus on the ID or text-based recommendation problem, failing to comprehend the information spanning various tasks or modalities. In this paper, our goal is to establish a Unified paradigm for Multi-modal Personalization systems (UniMP), which effectively leverages multi-modal data while eliminating the complexities associated with task- and modality-specific customization. We argue that the advancements in foundational generative modeling have provided the flexibility and effectiveness necessary to achieve the objective. In light of this, we develop a generic and extensible personalization generative framework, that can handle a wide range of personalized needs including item recommendation, product search, preference prediction, explanation generation, and further user-guided image generation. Our methodology enhances the capabilities of foundational language models for personalized tasks by seamlessly ingesting interleaved cross-modal user history information, ensuring a more precise and customized experience for users. To train and evaluate the proposed multi-modal personalized tasks, we also introduce a novel and comprehensive benchmark covering a variety of user requirements. Our experiments on the real-world benchmark showcase the model's potential, outperforming competitive methods specialized for each task.
TAFormer: A Unified Target-Aware Transformer for Video and Motion Joint Prediction in Aerial Scenes
Mar 27, 2024As drone technology advances, using unmanned aerial vehicles for aerial surveys has become the dominant trend in modern low-altitude remote sensing. The surge in aerial video data necessitates accurate prediction for future scenarios and motion states of the interested target, particularly in applications like traffic management and disaster response. Existing video prediction methods focus solely on predicting future scenes (video frames), suffering from the neglect of explicitly modeling target's motion states, which is crucial for aerial video interpretation. To address this issue, we introduce a novel task called Target-Aware Aerial Video Prediction, aiming to simultaneously predict future scenes and motion states of the target. Further, we design a model specifically for this task, named TAFormer, which provides a unified modeling approach for both video and target motion states. Specifically, we introduce Spatiotemporal Attention (STA), which decouples the learning of video dynamics into spatial static attention and temporal dynamic attention, effectively modeling the scene appearance and motion. Additionally, we design an Information Sharing Mechanism (ISM), which elegantly unifies the modeling of video and target motion by facilitating information interaction through two sets of messenger tokens. Moreover, to alleviate the difficulty of distinguishing targets in blurry predictions, we introduce Target-Sensitive Gaussian Loss (TSGL), enhancing the model's sensitivity to both target's position and content. Extensive experiments on UAV123VP and VisDroneVP (derived from single-object tracking datasets) demonstrate the exceptional performance of TAFormer in target-aware video prediction, showcasing its adaptability to the additional requirements of aerial video interpretation for target awareness.