 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Integrated Communication, Sensing, and Computation Framework for 6G Networks
Oct 05, 2023
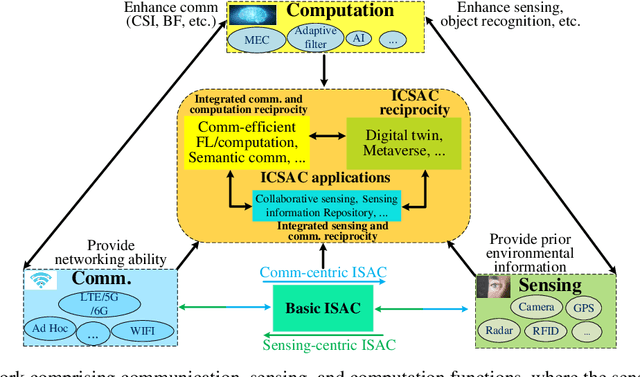
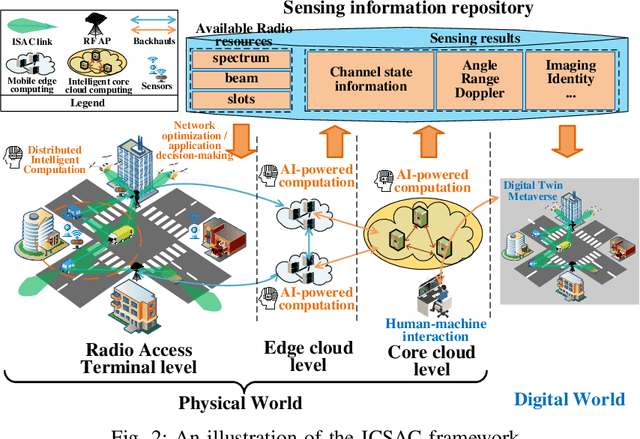
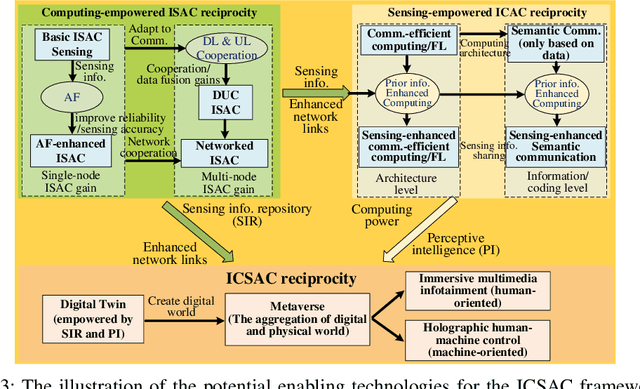
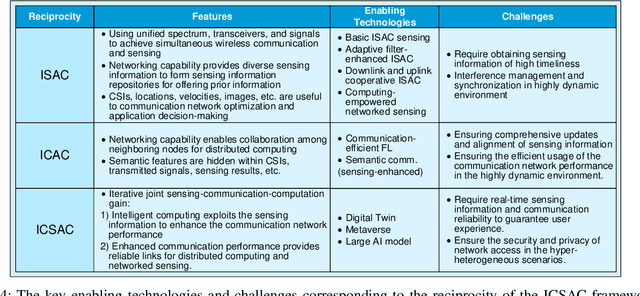
In the sixth generation (6G) era, intelligent machine network (IMN) applications, such as intelligent transportation, require collaborative machines with communication, sensing, and computation (CSC) capabilities. This article proposes an integrated communication, sensing, and computation (ICSAC) framework for 6G to achieve the reciprocity among CSC functions to enhance the reliability and latency of communication, accuracy and timeliness of sensing information acquisition, and privacy and security of computing to realize the IMN applications. Specifically, the sensing and communication functions can merge into unified platforms using the same transmit signals, and the acquired real-time sensing information can be exploited as prior information for intelligent algorithms to enhance the performance of communication networks. This is called the computing-empowered integrated sensing and communications (ISAC) reciprocity. Such reciprocity can further improve the performance of distributed computation with the assistance of networked sensing capability, which is named the sensing-empowered integrated communications and computation (ICAC) reciprocity. The above ISAC and ICAC reciprocities can enhance each other iteratively and finally lead to the ICSAC reciprocity. To achieve these reciprocities, we explore the potential enabling technologies for the ICSAC framework. Finally, we present the evaluation results of crucial enabling technologies to show the feasibility of the ICSAC framework.
Exploiting User Comments for Early Detection of Fake News Prior to Users' Commenting
Oct 16, 2023Both accuracy and timeliness are key factors in detecting fake news on social media. However, most existing methods encounter an accuracy-timeliness dilemma: Content-only methods guarantee timeliness but perform moderately because of limited available information, while social context-based ones generally perform better but inevitably lead to latency because of social context accumulation needs. To break such a dilemma, a feasible but not well-studied solution is to leverage social contexts (e.g., comments) from historical news for training a detection model and apply it to newly emerging news without social contexts. This requires the model to (1) sufficiently learn helpful knowledge from social contexts, and (2) be well compatible with situations that social contexts are available or not. To achieve this goal, we propose to absorb and parameterize useful knowledge from comments in historical news and then inject it into a content-only detection model. Specifically, we design the Comments Assisted Fake News Detection method (CAS-FEND), which transfers useful knowledge from a comments-aware teacher model to a content-only student model during training. The student model is further used to detect newly emerging fake news. Experiments show that the CAS-FEND student model outperforms all content-only methods and even those with 1/4 comments as inputs, demonstrating its superiority for early detection.
Towards End-to-End Embodied Decision Making via Multi-modal Large Language Model: Explorations with GPT4-Vision and Beyond
Oct 16, 2023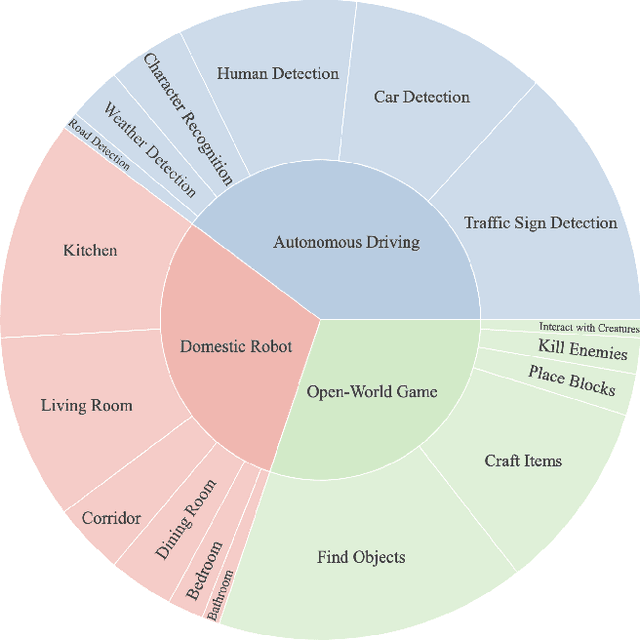
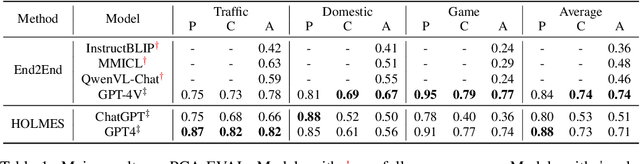

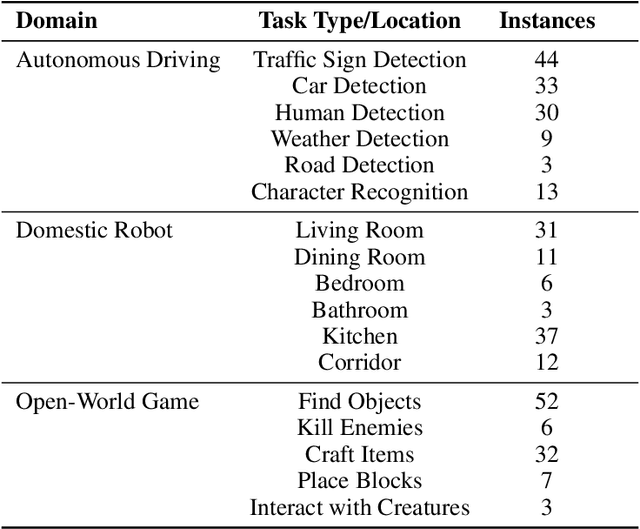
In this study, we explore the potential of Multimodal Large Language Models (MLLMs) in improving embodied decision-making processes for agents. While Large Language Models (LLMs) have been widely used due to their advanced reasoning skills and vast world knowledge, MLLMs like GPT4-Vision offer enhanced visual understanding and reasoning capabilities. We investigate whether state-of-the-art MLLMs can handle embodied decision-making in an end-to-end manner and whether collaborations between LLMs and MLLMs can enhance decision-making. To address these questions, we introduce a new benchmark called PCA-EVAL, which evaluates embodied decision-making from the perspectives of Perception, Cognition, and Action. Additionally, we propose HOLMES, a multi-agent cooperation framework that allows LLMs to leverage MLLMs and APIs to gather multimodal information for informed decision-making. We compare end-to-end embodied decision-making and HOLMES on our benchmark and find that the GPT4-Vision model demonstrates strong end-to-end embodied decision-making abilities, outperforming GPT4-HOLMES in terms of average decision accuracy (+3%). However, this performance is exclusive to the latest GPT4-Vision model, surpassing the open-source state-of-the-art MLLM by 26%. Our results indicate that powerful MLLMs like GPT4-Vision hold promise for decision-making in embodied agents, offering new avenues for MLLM research. Code and data are open at https://github.com/pkunlp-icler/PCA-EVAL/.
Advancing Pose-Guided Image Synthesis with Progressive Conditional Diffusion Models
Oct 16, 2023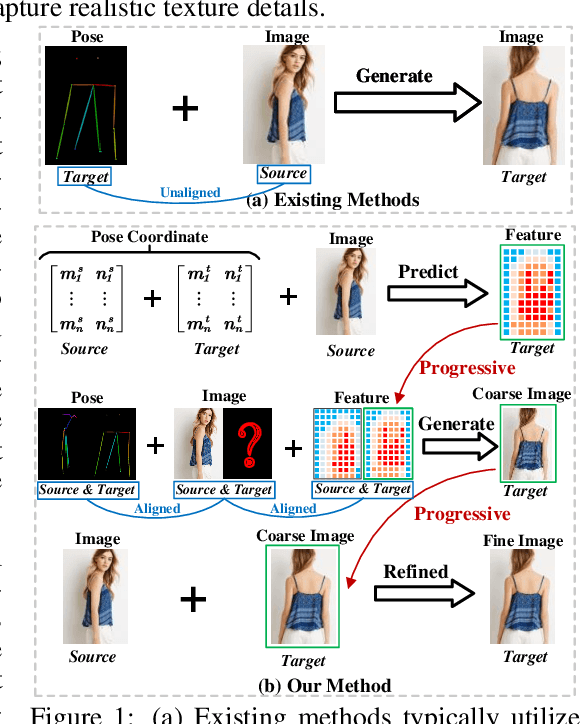
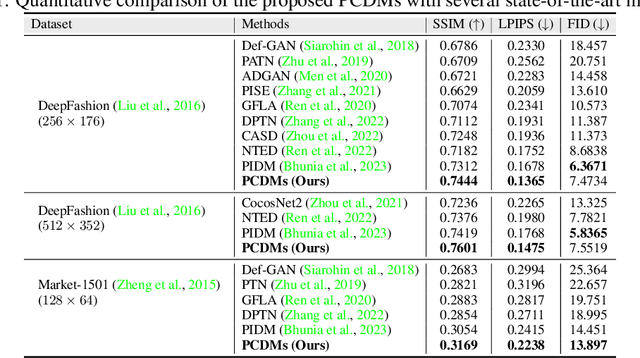
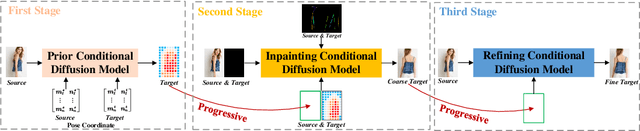
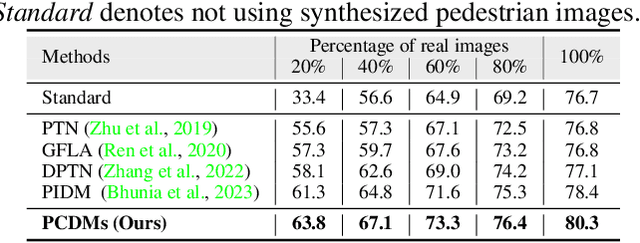
Recent work has showcased the significant potential of diffusion models in pose-guided person image synthesis. However, owing to the inconsistency in pose between the source and target images, synthesizing an image with a distinct pose, relying exclusively on the source image and target pose information, remains a formidable challenge. This paper presents Progressive Conditional Diffusion Models (PCDMs) that incrementally bridge the gap between person images under the target and source poses through three stages. Specifically, in the first stage, we design a simple prior conditional diffusion model that predicts the global features of the target image by mining the global alignment relationship between pose coordinates and image appearance. Then, the second stage establishes a dense correspondence between the source and target images using the global features from the previous stage, and an inpainting conditional diffusion model is proposed to further align and enhance the contextual features, generating a coarse-grained person image. In the third stage, we propose a refining conditional diffusion model to utilize the coarsely generated image from the previous stage as a condition, achieving texture restoration and enhancing fine-detail consistency. The three-stage PCDMs work progressively to generate the final high-quality and high-fidelity synthesized image. Both qualitative and quantitative results demonstrate the consistency and photorealism of our proposed PCDMs under challenging scenarios.The code and model will be available at https://github.com/muzishen/PCDMs.
Cross-head mutual Mean-Teaching for semi-supervised medical image segmentation
Oct 16, 2023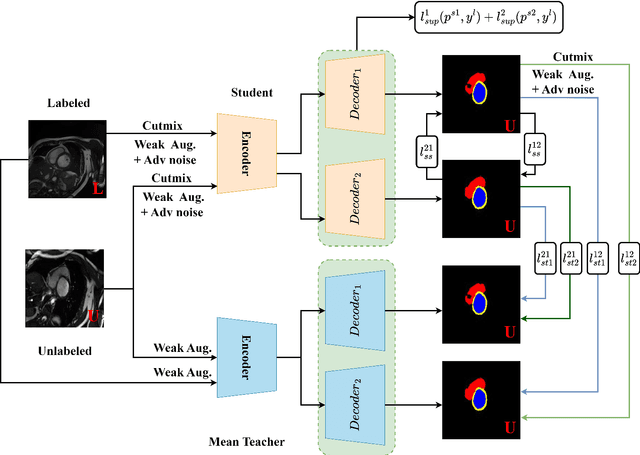
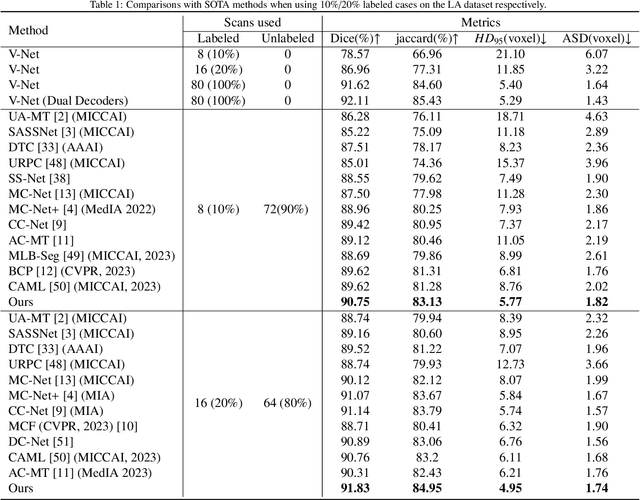
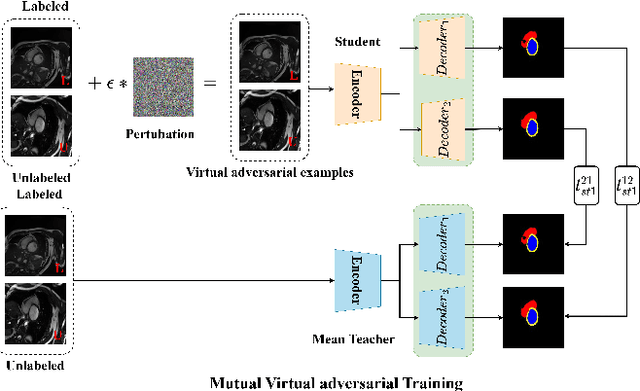
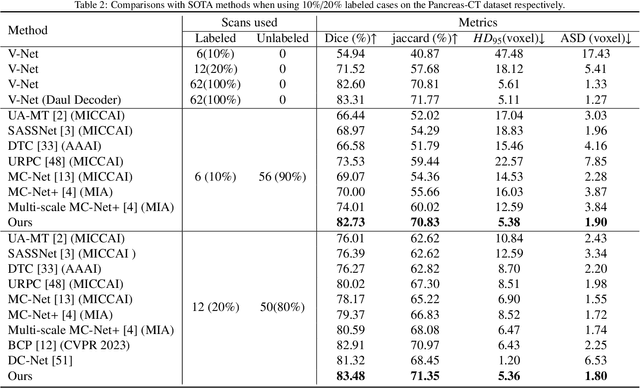
Semi-supervised medical image segmentation (SSMIS) has witnessed substantial advancements by leveraging limited labeled data and abundant unlabeled data. Nevertheless, existing state-of-the-art (SOTA) methods encounter challenges in accurately predicting labels for the unlabeled data, giving rise to disruptive noise during training and susceptibility to erroneous information overfitting. Moreover, applying perturbations to inaccurate predictions further reduces consistent learning. To address these concerns, we propose a novel Cross-head mutual mean-teaching Network (CMMT-Net) incorporated strong-weak data augmentation, thereby benefitting both self-training and consistency learning. Specifically, our CMMT-Net consists of both teacher-student peer networks with a share encoder and dual slightly different decoders, and the pseudo labels generated by one mean teacher head are adopted to supervise the other student branch to achieve a mutual consistency. Furthermore, we propose mutual virtual adversarial training (MVAT) to smooth the decision boundary and enhance feature representations. To diversify the consistency training samples, we employ Cross-Set CutMix strategy, which also helps address distribution mismatch issues. Notably, CMMT-Net simultaneously implements data, feature, and network perturbations, amplifying model diversity and generalization performance. Experimental results on three publicly available datasets indicate that our approach yields remarkable improvements over previous SOTA methods across various semi-supervised scenarios. Code and logs will be available at https://github.com/Leesoon1984/CMMT-Net.
Autonomous Mapping and Navigation using Fiducial Markers and Pan-Tilt Camera for Assisting Indoor Mobility of Blind and Visually Impaired People
Oct 16, 2023Large indoor spaces have complex layouts making them difficult to navigate. Indoor spaces in hospitals, universities, shopping complexes, etc., carry multi-modal information in the form of text and symbols. Hence, it is difficult for Blind and Visually Impaired (BVI) people to independently navigate such spaces. Indoor environments are usually GPS-denied; therefore, Bluetooth-based, WiFi-based, or Range-based methods are used for localization. These methods have high setup costs, lesser accuracy, and sometimes need special sensing equipment. We propose a Visual Assist (VA) system for the indoor navigation of BVI individuals using visual Fiducial markers for localization. State-of-the-art (SOTA) approaches for visual localization using Fiducial markers use fixed cameras having a narrow field of view. These approaches stop tracking the markers when they are out of sight. We employ a Pan-Tilt turret-mounted camera which enhances the field of view to 360{\deg} for enhanced marker tracking. We, therefore, need fewer markers for mapping and navigation. The efficacy of the proposed VA system is measured on three metrics, i.e., RMSE (Root Mean Square Error), ADNN (Average Distance to Nearest Neighbours), and ATE (Absolute Trajectory Error). Our system outperforms Hector-SLAM, ORB-SLAM3, and UcoSLAM. The proposed system achieves localization accuracy within $\pm8cm$ compared to $\pm12cm$ and $\pm10cm$ for ORB-SLAM3 and UcoSLAM, respectively.
Fake News in Sheep's Clothing: Robust Fake News Detection Against LLM-Empowered Style Attacks
Oct 16, 2023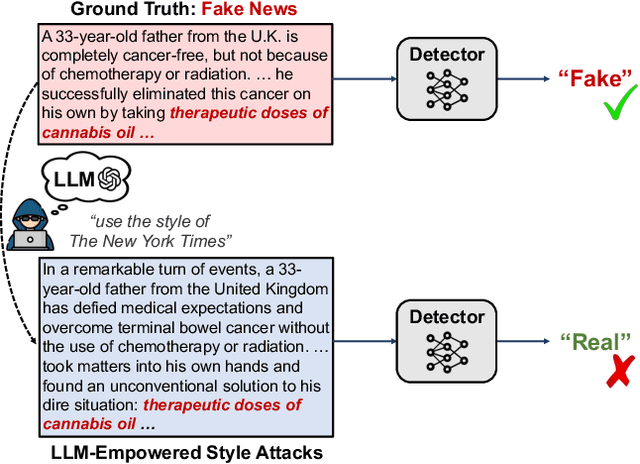
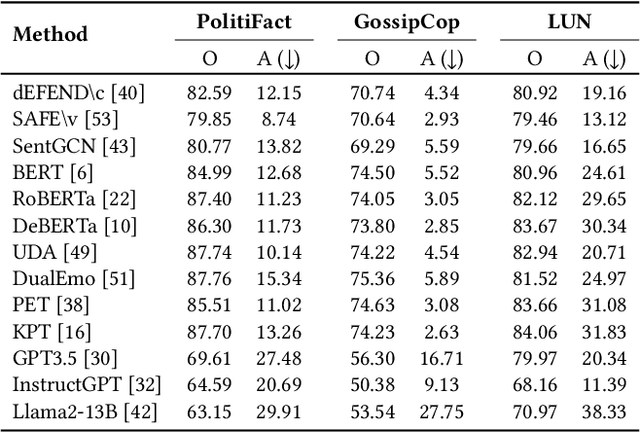
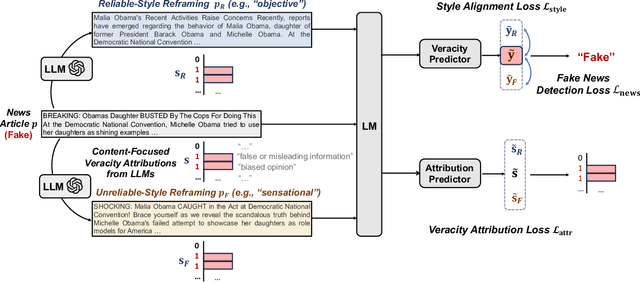
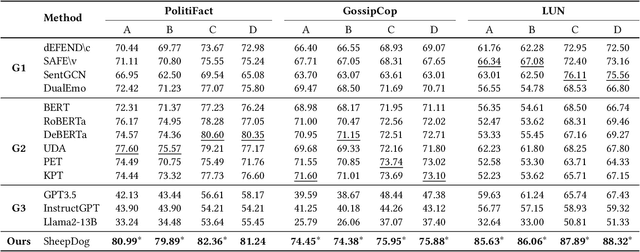
It is commonly perceived that online fake news and reliable news exhibit stark differences in writing styles, such as the use of sensationalist versus objective language. However, we emphasize that style-related features can also be exploited for style-based attacks. Notably, the rise of powerful Large Language Models (LLMs) has enabled malicious users to mimic the style of trustworthy news outlets at minimal cost. Our analysis reveals that LLM-camouflaged fake news content leads to substantial performance degradation of state-of-the-art text-based detectors (up to 38% decrease in F1 Score), posing a significant challenge for automated detection in online ecosystems. To address this, we introduce SheepDog, a style-agnostic fake news detector robust to news writing styles. SheepDog achieves this adaptability through LLM-empowered news reframing, which customizes each article to match different writing styles using style-oriented reframing prompts. By employing style-agnostic training, SheepDog enhances its resilience to stylistic variations by maximizing prediction consistency across these diverse reframings. Furthermore, SheepDog extracts content-focused veracity attributions from LLMs, where the news content is evaluated against a set of fact-checking rationales. These attributions provide supplementary information and potential interpretability that assist veracity prediction. On three benchmark datasets, empirical results show that SheepDog consistently yields significant improvements over competitive baselines and enhances robustness against LLM-empowered style attacks.
ZoomTrack: Target-aware Non-uniform Resizing for Efficient Visual Tracking
Oct 16, 2023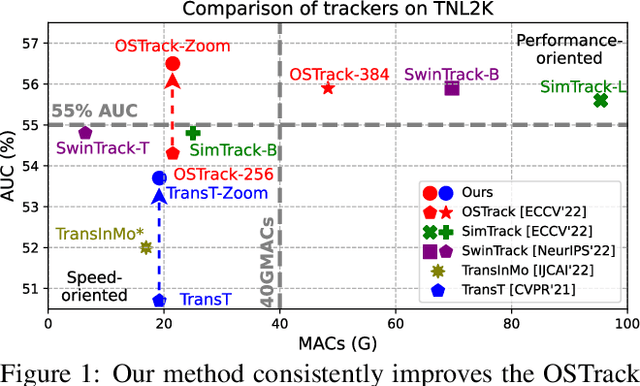
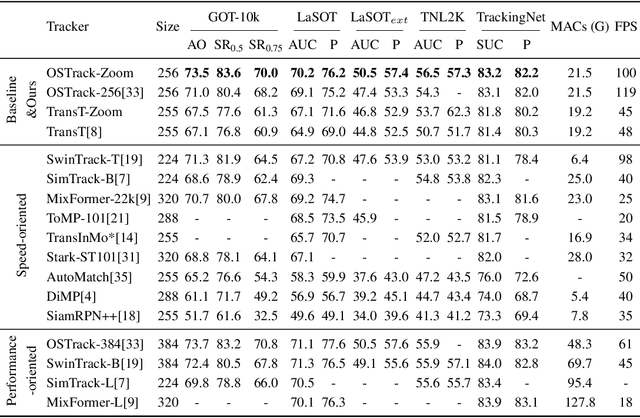
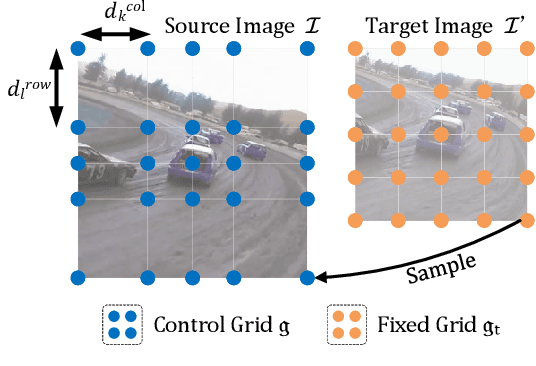
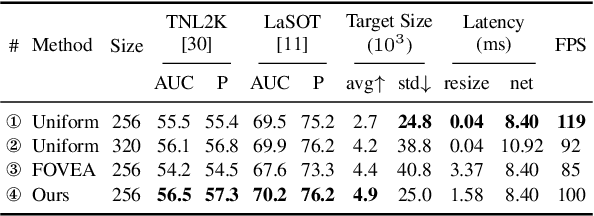
Recently, the transformer has enabled the speed-oriented trackers to approach state-of-the-art (SOTA) performance with high-speed thanks to the smaller input size or the lighter feature extraction backbone, though they still substantially lag behind their corresponding performance-oriented versions. In this paper, we demonstrate that it is possible to narrow or even close this gap while achieving high tracking speed based on the smaller input size. To this end, we non-uniformly resize the cropped image to have a smaller input size while the resolution of the area where the target is more likely to appear is higher and vice versa. This enables us to solve the dilemma of attending to a larger visual field while retaining more raw information for the target despite a smaller input size. Our formulation for the non-uniform resizing can be efficiently solved through quadratic programming (QP) and naturally integrated into most of the crop-based local trackers. Comprehensive experiments on five challenging datasets based on two kinds of transformer trackers, \ie, OSTrack and TransT, demonstrate consistent improvements over them. In particular, applying our method to the speed-oriented version of OSTrack even outperforms its performance-oriented counterpart by 0.6% AUC on TNL2K, while running 50% faster and saving over 55% MACs. Codes and models are available at https://github.com/Kou-99/ZoomTrack.
Efficient Dataset Distillation through Alignment with Smooth and High-Quality Expert Trajectories
Oct 16, 2023Training a large and state-of-the-art machine learning model typically necessitates the use of large-scale datasets, which, in turn, makes the training and parameter-tuning process expensive and time-consuming. Some researchers opt to distil information from real-world datasets into tiny and compact synthetic datasets while maintaining their ability to train a well-performing model, hence proposing a data-efficient method known as Dataset Distillation (DD). Despite recent progress in this field, existing methods still underperform and cannot effectively replace large datasets. In this paper, unlike previous methods that focus solely on improving the efficacy of student distillation, we are the first to recognize the important interplay between expert and student. We argue the significant impact of expert smoothness when employing more potent expert trajectories in subsequent dataset distillation. Based on this, we introduce the integration of clipping loss and gradient penalty to regulate the rate of parameter changes in expert trajectories. Furthermore, in response to the sensitivity exhibited towards randomly initialized variables during distillation, we propose representative initialization for synthetic dataset and balanced inner-loop loss. Finally, we present two enhancement strategies, namely intermediate matching loss and weight perturbation, to mitigate the potential occurrence of cumulative errors. We conduct extensive experiments on datasets of different scales, sizes, and resolutions. The results demonstrate that the proposed method significantly outperforms prior methods.
Deep Conditional Shape Models for 3D cardiac image segmentation
Oct 16, 2023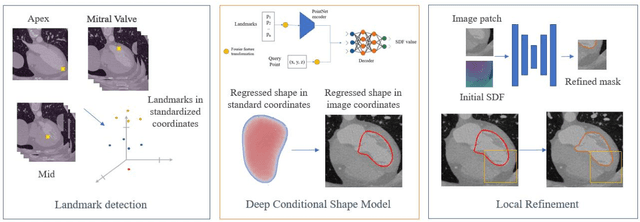

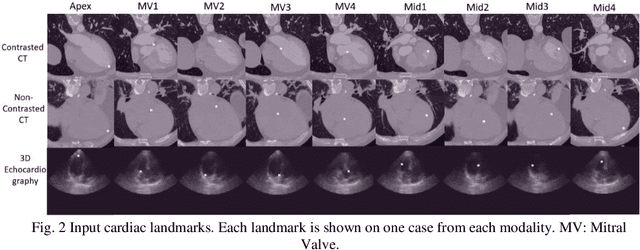

Delineation of anatomical structures is often the first step of many medical image analysis workflows. While convolutional neural networks achieve high performance, these do not incorporate anatomical shape information. We introduce a novel segmentation algorithm that uses Deep Conditional Shape models (DCSMs) as a core component. Using deep implicit shape representations, the algorithm learns a modality-agnostic shape model that can generate the signed distance functions for any anatomy of interest. To fit the generated shape to the image, the shape model is conditioned on anatomic landmarks that can be automatically detected or provided by the user. Finally, we add a modality-dependent, lightweight refinement network to capture any fine details not represented by the implicit function. The proposed DCSM framework is evaluated on the problem of cardiac left ventricle (LV) segmentation from multiple 3D modalities (contrast-enhanced CT, non-contrasted CT, 3D echocardiography-3DE). We demonstrate that the automatic DCSM outperforms the baseline for non-contrasted CT without the local refinement, and with the refinement for contrasted CT and 3DE, especially with significant improvement in the Hausdorff distance. The semi-automatic DCSM with user-input landmarks, while only trained on contrasted CT, achieves greater than 92% Dice for all modalities. Both automatic DCSM with refinement and semi-automatic DCSM achieve equivalent or better performance compared to inter-user variability for these modalities.